
模板匹配识别算法和神经网络识别算法的比较及MATLAB实现
2020-01-26 05:49陶鹏朱华
电脑知识与技术 2020年34期
关键词:BP神经网络
陶鹏 朱华


摘要:现有的车牌识别系统(LPR)已经诞生了许多关键技术。常用的关键技术有:基于数学形态学定位汽车车牌、基于Hough变换的车牌图像倾斜校正算法。而识别算法中,主要有模板匹配和BP神经网络算法。模板匹配算法是数字图像处理组成的重要部分之一。把不同的传感器在不同时间和成像条件下对景物获取到的图像在空间上对齐,或在模式到一幅图中寻找对应的处理方法。BP神经网络算法是一种“误差逆传播算法训练”:利用输出的误差估计前一层的误差,以此类推,获取各层次估计的误差。本次实验通过比较识别算法的两种关键技术得出以下结论:模板匹配实现过程简单,速度快,要求字符比较规整,并且对车牌图片质量要求很高,图像被其他因素干扰时,比如光线、清晰度等,会导致识别率低;而神经网络算法可以在不同的复杂环境下、不明确推理规则等识别问题,具有自适应性好、识别率高的自学习和自调整能力,但在识别前需要进行网络训练,速度慢,依赖大量的学习样本。
关键词:识别算法;模板匹配;BP神经网络
中图分类号: TP181 文献标识码:A
文章编号:1009-3044(2020)34-0187-04
Abstract: Existing license plate recognition (LPR) system has created the key technology of many key techniques are commonly used are: car license plate based on mathematical morphology on the license plate image tilt correction algorithm based on Hough transform and the recognition algorithm, there are mainly template matching template matching algorithm and the BP neural network algorithm is one of an important part of digital image processing of the different sensors in different time and imaging condition of scenery get image alignment on the space, or in the model to a figure in search the corresponding treatment method the BP neural network training algorithm is a kind of error back propagation algorithm : using the output error of the estimation error of the previous layer, and so on, for all levels estimated error this experiment by comparing the recognition algorithm of two kinds of key technology in the following conclusions: template matching process is simple, fast, character is neat, and the license plate image quality requirement is high, the image interference by other factors, such as the light of clarity, leads to the recognition rate is low; However, neural network algorithm can identify problems such as unclear inference rules in different complex environments, and has self-learning and self-adjustment abilities with good adaptability and high recognition rate. However, network training is needed before recognition, which is slow and relies on a large number of learning samples.
Key words: Recognition algorithm; Template matching; The neural network
隨着我国经济水平的不断提升,人们对生活质量的要求也源源不断提高。为了满足自我和家庭的需求,越来越多人购买了汽车,据公安部报道:自2019年6月,我国汽车保有量突破3.4亿辆。因此,交通智能化管理在人们的生活中的比例越来越重要。车牌识别系统(lPR)是智能交通系统(ITS)的核心组成部分,也是智慧城市的关键一步。通过IPR,可以对车辆进行监控,交通流量控制指标标量,车辆定位,监管,登记等。在实现交通自动化管理有着现实意义的作用。
一个完整的车牌识别系统是基于图像分割和图像识别理论:通过图像的采集对含有车牌的图像进行车牌定位和提取,从而确定车牌的位置,并且进一步识别出文本字符。而车牌倾斜校正,字符分割,字符识别,是识别工作的相辅相成。由于,本次实验是比较字符识别的关键技术,所以采用控制变量法:车牌定位采用数学形态学定位法:膨胀、腐蚀、开启和闭合。图像倾斜校正采用Hough变换法:找出变换域中的峰值数据(相交直线最多的点),根据峰值数据的空域坐标绘出对应直线。
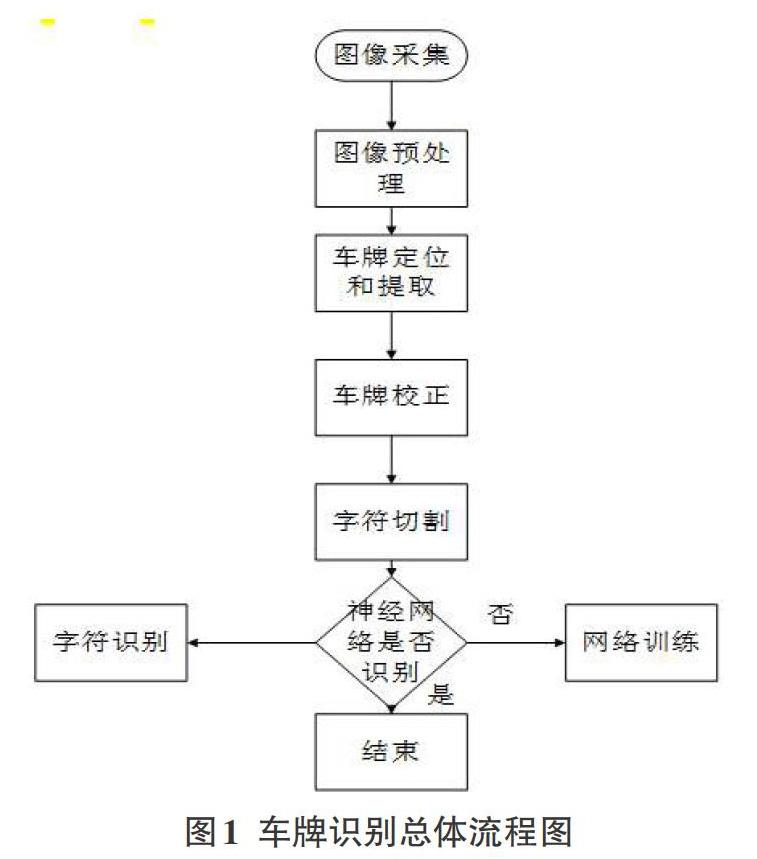
1车牌识别系统总体流程
图1是车牌识别系统的总体流程:图像采集->图像预处理->车牌定位和提取->车牌校正->字符分割->字符识别->训练模型。
1.1首先通过设备获取原始图像后,车牌识别系统利用MATLAB技术将原始图像数据化
1.1.1读入图像文件
[filename pathname]=uigetfile({'*.jpg';'*.bmp'}, 'File Selector');
I=imread([pathname '\' filename]);
handles.I=I;
guidata(hObject, handles);
axes(handles.axes1);
1.1.2灰度化
因为外界的光线条件多变光照不均匀,容易得到的图像出现偏光,因此可以通过rgb2gray函数以实现对比度的变换及扩大,以减少光线对图形的影响。
I=handles.I;
I1=rgb2gray(I);
axes(handles.axes2);
imshow(I1);title('灰度化');
1.1.3边缘检测
由于在自然背景中准确确定牌照区域是整个识别过程的关键,为了准确获得车牌信息,利用Roberts算子进行边缘检测。
I2=edge(I1,'roberts',0.18,'both');
1.1.4平滑图像轮廓处理
由于噪声以及数字化误差导致角点不理想。自动白平衡、自动曝光以及伽马校正,采用腐蚀函数imerode()求图像区域空间的平均值,以使图像更为清晰。
se=[1;1;1];
I3=imerode(I2,se);%?腐蚀操作
1.1.5滤波处理
为除去小图像,利用bwareaopen()函数删除小面積对象。
se=strel('rectangles',[30,30]);
I5=imclose(I4,se);%图像聚类,填充图像
I6=bwareaopen(I5,2000);%除去聚团灰度值小于2000的部分
figure(2),imshow(I6);
1.1.6数学形态学定位车牌
经过图像预处理之后的灰度图进行行列扫描,确定车牌区域。
Btemp1_y=zeros(y temp1,1);
for m=1:y temp1
for n=1:x temp1
if(myI(m,n,1)==1)
B temp1_y(i,1)=Blue_y(i,1)+1;
end
end
end
[temp MaxY]=max(B_y);
%Y方向车牌区域确定
Ytemp1=Maxtemp1Y;
while((Bs temp1_y(PY1 temp1,1)>=5)&&(Y1 temp1>1))
Y1PY temp11-1;
end
Y2=Max temp1 Y;
while((B temp1_y(Y2 temp1,1)>=5)&&(Y2 temp1 Y2 temp1 =Y2 temp1+1; End IY temp1 =I(Y1 temp1PY temp12,:,:); %X·方向的区域确定 B temp1_x=zeros(1,x); while((Bs_x(1,PX1)<3)&&(X1 X1=X1+1; end X1=X1-1;%对车牌区域的校正 X2=X2+1; dw=I(Y1:Y2-8,X1:X2,:); t=tocs; axes(handles.axes5);imshow(dw),title('定位车牌'); 1.1.7字符切割 校正车牌区域得到剪切后的字符并去噪; Word2=[]; while f==0 [m,n]=size(d); left=1.0; wides=0; while sum(d(:,wides+1))~=0 wides=wides+1; end if wides d1(:,[1:wide])=0; d=qiege(d1); else temp=qiege(imcrop(d,[1 1 wide m])); [m,n]=size(tp); all=sum(sum(tp)); twos_thirds=sum(sum(temp([round(m/3):2*round(m/3.0)],:))); if twos_thirds/all>y21 f=1;word1=tp;%word1 end d(:,[1:wide])=0;d=qieges(d); end end 2模板匹配算法原理 模板匹配原理用于車牌识别算法是OCR,是先将待识别的字符进行二值化操作,并将大小缩放到字符数据库模板大小,然后逐一匹配,从待识别的图像区域F(i,j)中提取大量特征量与模板的T(i,j)逐一匹配,计算他们之间规格化的互相关量,最大的互相关量就是相识度最高的,然后依次相减,选出最佳结果。流程如图9所示: 3 BP神经网络原理 神经网络的基本原理是通过输入向量和权的向量的加权求和,成为下一个神经元的输入,再加上偏置,经过激活函数计算作为下一层的神经元的输出,多用于函数逼近,模型识别分类,数据压缩和时间序列预测。 BP神经网络具有较强的泛化能力和高度非线性能力,但也存在收敛速度慢,迭代步数多,易陷入局部极小和全局搜索能力等缺点,可以先用遗传算法对“BP神经网络”进行优化在解析空间找出比较好的搜索空间。 Sigmoid可微函数和线性函数常作为BP神经网络的激励函数。本次实验选择tansing作为神经元的激励函数。 Sigmoid函数是神经网络的激励函数。激励函数会把输出的信号压缩在一个可控的范围内,让其成为一个有限值。 4实验结果与分析 为了充分比较匹配算法和神经网络的优缺点,对500张汽车车牌进行了测试,测试结果如下: 通过实验发现:匹配算法识别准确率和神经网络识别准确率都随着光照强度的减弱而增加,其原因是图像的二值化进行定位的算法鲁棒性与适应性比较差,阈值会受到图像亮度与图像复杂度的影响。特别是车牌和汽车颜色一致时,即使光线好依旧定位失败。因此,在车牌定位过程中,车牌的提取结果会因光照的影响而出现较大的偏差,从而导致定位失败;在相同的光照强度下,匹配算法识别准确率远远低于神经网络的算法识别率,其原因是:模板匹配时,所设计的模板和它对应的字符图像难以吻合。对于较为复杂的汉字如“赣”、“鲁”和特殊的字母“U”等,这种不吻合所带来的错误会对结果产生不良的影响。而数字的识别能得到较好的效果。神经网络算法识别率也不太高,其原因是:数据量太小,并不能满足本次实验,另一个原因是省份汉字笔画较多同时伴有笔画黏黏的现象,从而造成了误判。 5结论 1)在应用中,由于干扰因素众多,模板匹配算法准确率没有神经网络识别算法高,但是在数字和字母的识别中,两者差别不大,因为数字和字符结构简单,彼此间的相识度较小。 2)在图片模糊,不清晰,背景识别困难(车牌颜色和车身颜色一致)时,神经网络比模板匹配算法更具优越性。 3)模板匹配实现过程简单(只需准备模板库),验证过程速度快;而BP神经网络实现过程复杂,需要提前进行网络训练,但训练后的效优于模板匹配。 总而言之,应用模板匹配时,应当保证车牌的图像质量,解析度不能太低。应用神经网络时,应当使字符能正确独立分割出来,应用神经网络的样本保证充分不偏。 参考文献: [1] 李宇成,杨光明,王目树.车牌识别系统中关键技术的研究[J].计算机工程与应用,2011,47(27):180-184,209. [2] 魏武,黄心汉,张起森,等.基于模板匹配和神经网络的车牌字符识别方法[J].模式识别与人工智能,2001,14(1):123-127. [3] 黄德双.神经网络模式识别系统理论[M].北京:电子工业出版社,1996. 【通联编辑:唐一东】
