
基于模糊矩阵和神经网络的航空发动机磨损部位故障识别
2020-01-17 05:45:50孙涛,李冬
燃气涡轮试验与研究 2019年6期
孙 涛,李 冬
(1.海军航空大学基础学院,山东烟台 264001;2.91899部队,辽宁葫芦岛 125001)
1 引言
某型发动机结构复杂,其多个部件存在大量的摩擦副[1]。发动机工作过程中,各个摩擦副相互作用,产生大量摩擦,许多金属磨粒进入并悬浮于滑油中。以往单纯的通过孔探检查,虽然能检查出一些问题,但检测范围和程度受限,发现时故障已经损伤到一定程度。由于磨粒的成分及含量往往揭示着发动机磨损部件故障的重要信息,利用这些信息,借助光谱技术就可以判断发动机的性能状态[2]。在表征磨损故障的数据中,如何挖掘表征磨损的有效特征[3-8],是发动机油润部件磨损故障诊断及预测的关键。
神经网络具有很强的非线性映射能力和容错能力,在机械设备故障诊断领域得到了广泛应用[9-10]。本文针对某型航空发动机,通过获取的磨损特征数据,建立了基于神经网络方法的磨损部件故障定位诊断方法,并通过算例证明了该方法的可行性。
2 BP神经网络
采用BP 网络对磨损故障进行诊断。BP 网络是利用误差反向传播算法的多层前向神经网络模型,典型的三层前馈型BP 网络的拓扑结构如图1所示[11-12]。

图1 三层前馈型BP网络Fig.1 Three layer feedforward network
令输入层节点到中间层节点间的连接权为ωir,中间层节点到输出层节点间的连接权为vrj,Tr为中间层节点的阈值,θj为输出层节点的阈值,则中间层中节点的输出函数为:
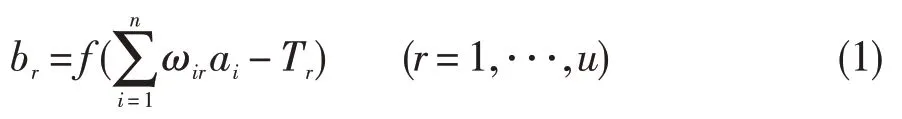
输出层中节点的输出函数为:
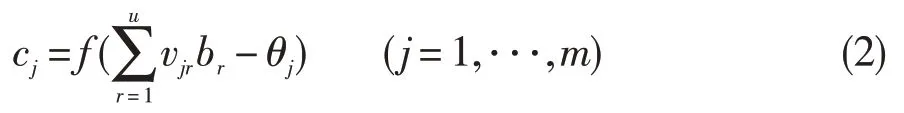
其中,f为S型函数

BP 网络可看成是从输入到输出的高度非线性映射,即

对于样本集合:输入xi∈Rn和输出yi∈Rm,存在某一映射g使得

求出一映射f,使得满足最小二乘的情况下,f是g的最佳近似结果。
3 BP神经网络诊断步骤
采用建立的BP 神经网络对某型航空发动机滑油系统磨损故障进行诊断。根据诊断对象的特点及模式划分故障类型,基于获取的磨损故障信息选取对故障敏感的特征参数作为BP 网络的输入;构造BP网络结构,确定输入个数、隐含层数和输出个数;对BP网络进行优化训练,在训练过程中进一步调整权值矩阵、阈值矢量。如果网络训练不成功,则需要改变结构参数,直至得到优化的训练完的BP 网络。将待检数据输入到训练后的网络中得到输出向量,输出结果最接近哪种故障类型,就认为它属于此类故障。
根据该型发动机转动部件的结构特点,统计发动机在使用过程中出现的磨损部件故障和磨损故障发动机修理情况。结合发动机构造和原理充分分析发动机磨损原因,确定磨损部位主要为:低压压气机支点,中介机匣,高压压气机支点,低压涡轮支点,高压涡轮支点,附件传动装置,滑油泵。磨损部位对应的发动机部件为[9]:低压压气机,中介机匣,高压压气机,低压涡轮,高压涡轮,附件机匣,滑油泵。
根据上述分析和说明,拟定8 种磨损部件对应的故障模式:低压压气机(记为P1),中介机匣(记为P2),高压压气机(记为P3),低压涡轮(记为P4),高压涡轮(记为P5),附件机匣(记为P6),滑油泵(记为P7),系统正常(记为P8)。
4 神经网络构建
建立滑油光谱三层BP 网络诊断模型。其中,Fe、Cr、Ni、Al、Mo、Mg、Cu、Sn 金属元素浓度作为神经网络输入,记为S1,S2,…,S8;P1,P2,…,P8 为神经网络输出,对应于上述8个故障模式。其中,隐含层节点数根据经验公式得到[13]。

式中:nh为隐含层节点数,nl为输入层节点数,n0为输出层节点数,l为1~10 之间的整数。基于此,计算确定隐含层节点数为12。
5 标准故障样本构建
发动机分为8 种磨损故障模式,故可构造8 种标准模式。每种模式都包含金属元素的个数和种类信息,设为Kj(j表示该模式所含金属元素的种类,分别对应Fe、Cr、Ni、Al、Mo、Mg、Cu、Sn)。根据上述信息,构造X1~X8共8 种标准识别模式。同时,用二进制方法表示元素存在性,1 为存在,0 为不存在。则标准模式为:X1={1,1,1,1,1,0,1,0},X2={1,1,0,0,0,1,1,0},X3={1,1,0,1,1,0,1,0},X4={1,1,1,0,1,0,0,0},X5={1,1,1,0,0,0,1,0},X6={1,1,1,0,0,1,0,0},X7={1,1,0,1,0,0,1,1},X8={0,0,0,0,0,0,0,0} 。由此,得到光谱子诊断网络的训练样本,见表1。
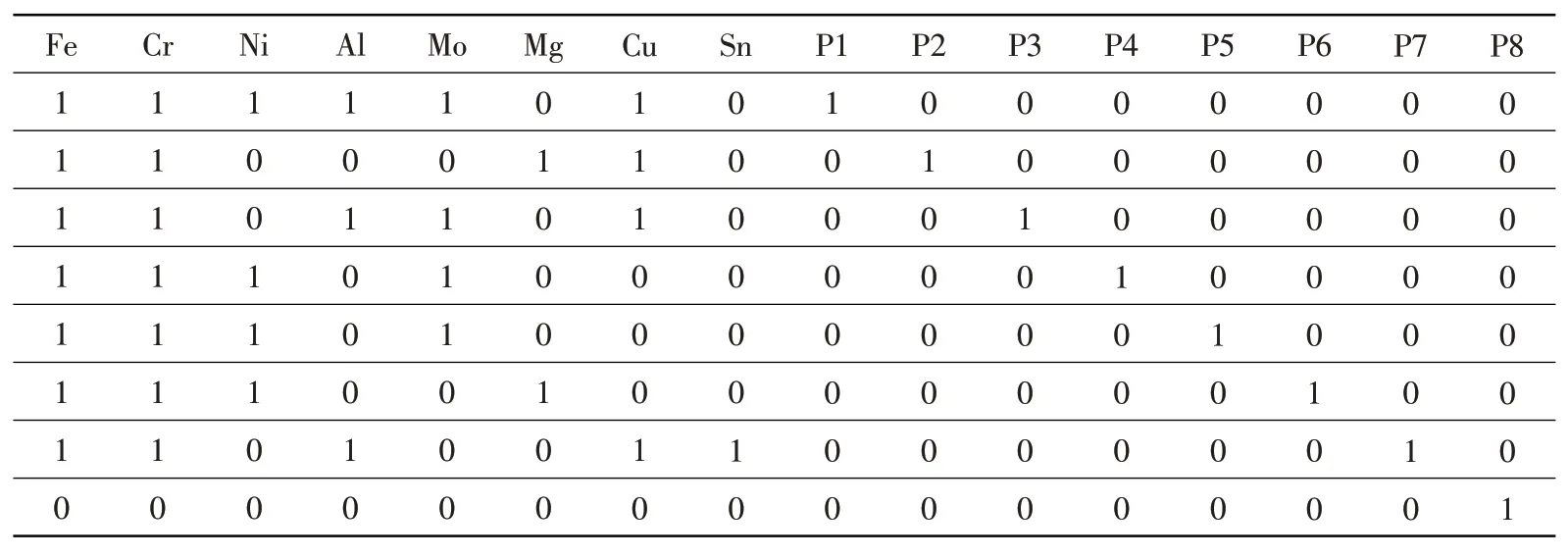
表1 光谱子诊断网络的训练样本Table 1 Training sample of spectral diagnostic network
隐含层传递函数采取S 形正切函数——tansig函数,表达式为:

经确定,输出层传递函数采用S 型对数函数——logsig函数,表达式为:

其中:训练函数采用traingda,学习函数采用learndm,性能函数采用mse。
对网络编程反复进行训练,总误差设定为0.01,经过120次训练后,网络性能达到要求。BP网络训练结果如图2所示。

图2 网络训练图Fig.2 Network training part
6 磨损部位故障识别样本构建
(1)建立样本矩阵
实际工作中,磨损元素的浓度或梯度变化超过设定红线时,依据滑油中金属颗粒的成分及含量,确定哪些部件出现磨损,利用特异金属元素确定故障部位。实际工作中,当部件存在异常磨损,一般维护人员凭经验判断,容易出现不规范、不严谨且误判、漏判。因此有必要结合数学方法对光谱监测数据进行深入分析,进而确定故障部位。
滑油中的颗粒是发动机内部多种零部件磨损产物的混合结果,由于这些零部件表面材料成分各不相同,且具有不同的表面硬度和运行工况,其磨损速率不同,因而实际获得的监测数据是多个零部件磨损叠加的结果。不过每种金属元素的浓度值都不是独立的,元素之间存在相互关联性。采用聚类分析方法,把具有相同或相近性质的元素聚为一类,简化研究对象。如果此时发动机上的某一摩擦副材料对应着这几种元素,则可确认磨损零部件与元素浓度变化的关系。
根据滑油中一组数据的Fe 元素超过浓度异常值,表明异常磨损。设U={u1,u2,⋅⋅⋅,u8},各指标分别对应Fe、Cr、Ni、Al、Mo、Mg、Cu、Sn。选取发生异常磨损时前8个光谱浓度值组成样本矩阵,见表2。
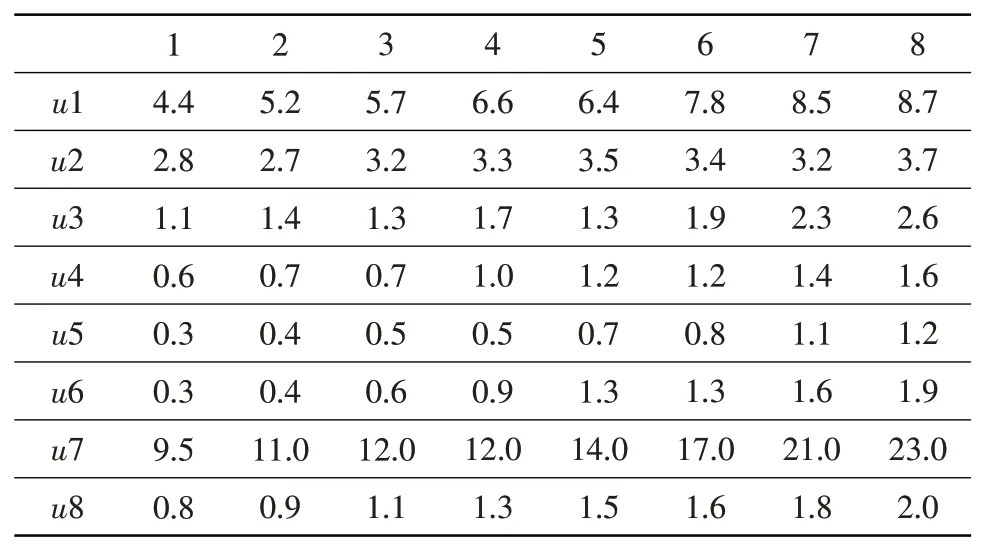
表2 前8个光谱浓度值组成的样本矩阵Table 2 Sample matrix consisting of former 8 spectral concentration
(2)相似关系计算
根据实际情况选取相关系数法建立相似关系矩阵。计算公式为:

根据式(9)得到相似关系矩阵,见表3。
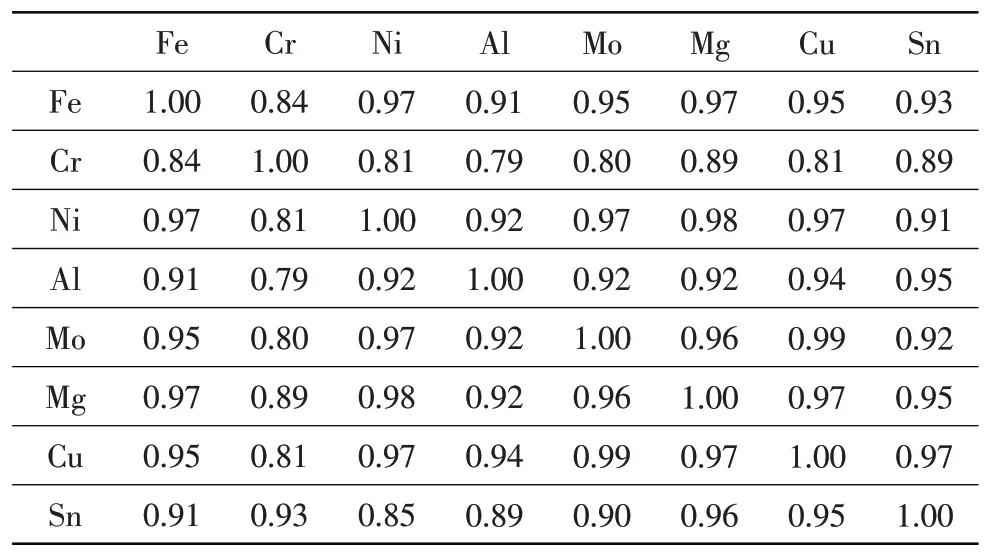
表3 相似关系矩阵Table 3 Similar relationship matrix
(3)传递矩阵
通过求矩阵的传递闭包将模糊相似关系矩阵转化为等价矩阵。采用平方法求解,即从模糊矩阵Rij出发,依次求平方当第一次出现时,就是所求的传递闭包

(4)截矩阵并聚类
求出不同聚类因子λ对应的截矩阵Rλ。根据所求截矩阵进行聚类。因素之间聚为一类的充分条件是:
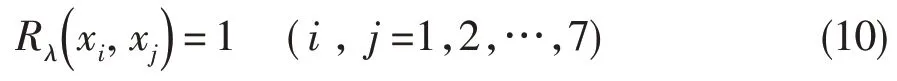
据此,得到在不同λ值下的分类结果:
当0<λ≤0.89 时,将U分为1 类:{u1,u2,u3,u4,u5,u6,u7,u8}。
当0.89<λ≤0.94 时,将U分为2 类:{u2},{u1,u3,u4,u5,u6,u7,u8}。
当0.94<λ≤0.97 时,将U分为3 类:{u2},{u4},{u1,u3,u5,u6,u7,u8}。
当0.97<λ≤0.98 时,将U分为6 类:{u1},{u2},{u4},{u7},{u8},{u3,u5,u6}。
当0.98<λ≤1.00 时,将U分为8 类:{u1},{u2},{u3},{u4},{u5},{u6},{u7},{u8}。
根据上述规则构造磨损部位识别模式,选取λ=0.97,则待识别模式X0={1,1,0,1,0,1,1,0}。
7 诊断结果
综上,本文建立的发动机磨损部位故障识别方法(图3)为:将反映发动机磨损部件故障的原始数据,利用模糊矩阵方法得到特征样本数据,然后经过神经网络方法确定故障模式。其中,模糊矩阵方法对原始数据进行特征处理是故障识别的关键,极大地提高了识别精度。

图3 故障识别流程Fig.3 Flowchart of fault diagnosis
待识别部位对应的元素含有Fe、Al、Cr、Cu、Mg,与低压压气机轴承磨损所含有的元素一致,据此判断低压压气机轴承最有可能发生剧烈磨损。将待识别故障数据输入到训练好的BP神经网络中,输出结果对应发动机低压压气机轴承支座磨损,与前述分析一致。
为进一步增加对比性,将本文方法与磨损样本元素浓度的原始数据+神经网络方法相结合的原始识别方法进行比较。其中,本文方法的训练样本为20,原始识别方法的训练样本为60,测试样本都为60。原始识别方法识别前对数据进行归一化处理。本文方法的识别精度为96.67%,原始方法的识别精度为81.67%,原始识别方法比本文方法的识别精度低很多。主要是因为本文方法神经网络的输入是0和1格式,更突出了故障样本的特征;而原始识别方法神经网络的输入是8 个0~1 的数字,增加识别的难度。同时,原始识别方法的训练样本数更多,增加了神经网络的训练时间,这也体现了本文方法的优越性。
8 结论
针对某型发动机建立了基于BP 神经网络的磨损故障诊断模型,并通过算例分析验证了诊断方法的可行性和准确性。算例分析结果表明,所建立的诊断方法具有很高的诊断精度。相比较磨损样本元素浓度的原始数据+神经网络方法相结合的原始识别方法,本文方法的识别精度为96.67%,且训练样本数更少,减少了样本训练时间。
猜你喜欢
燃气涡轮试验与研究(2021年4期)2022-01-18 07:30:54
航空发动机(2021年1期)2021-05-22 01:20:36
航空发动机(2020年3期)2020-07-24 09:03:14
电子制作(2019年19期)2019-11-23 08:42:00
智富时代(2018年7期)2018-09-03 03:47:26
重型机械(2016年1期)2016-03-01 03:42:04
石油知识(2016年2期)2016-02-28 16:20:21
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
燃气轮机技术(2014年4期)2014-04-16 03:54:04
