
面向后5G 的非正交多址技术综述
2020-01-15 06:19杨一夫李欣然付靖微
无线电通信技术 2020年1期
杨一夫,武 刚∗,李欣然,付靖微,胡 苏
(1.电子科技大学 通信抗干扰技术国家级重点实验室,四川 成都 611731 ;2.成都欧珀通信科技有限公司,四川 成都 610041 )
0 引言
在传统的蜂窝通信系统中,主要用的是正交多址接入技术(Orthogonal Multiple Access,OMA),使用OMA 可以在低复杂度的情况下轻松分离出不同用户信号所携带的信息。 但是,OMA 的一个缺陷是支持的用户数量受到可用正交资源数量的限制。 此外,尽管使用了正交的时频码资源,信号经历信道时,由于时延、频偏和多普勒频移,其正交性总是不可避免地被破坏。 因此,如果仍然局限于OMA 技术,无法在有限的资源内接入更多的用户,就无法达到5G 的频谱效率和大规模连接要求。
非正交多址接入(Non -Orthogonal Multiple Access,NOMA)是达到5G 要求的重要技术,该技术可以实现有限频谱资源的复用,在接收端通过先进的接收机技术来分离每个用户的数据[1]。 仿真结果表明[2],与OMA 技术相比,使用NOMA 技术可以显著提高传输速率和系统容量,因此,该技术非常符合5G 时代的海量数据增长和接入需求。 文献[3]最早给出了多址接入系统的容量界。 NTT DOCOMO 公司和第三代合作伙伴组织(Third Generation Partnership Project,3GPP)[4]在长期演进(Long Term Evolution,LTE)的Release-13[5]里以多用户叠加编码(Multi-User Superposition Transmission,MUST)的方式对NOMA 进行了研究。 文献[6]研究了NOMA用于蜂窝下行链路的情况,证明了在遍历总和率方面,NOMA 具有良好的性能。 文献[7]研究了协作NOMA,分析了协作NOMA 的中断概率和分级顺序。文献[8]研究了NOMA 在多输入多输出(Multiple-Input Multiple-Output,MIMO)系统中的应用,提出了一种用于MIMO-NOMA 的预编码和检测矩阵的新设计,并针对具有固定功率分配系数集的情况分析了其性能。
目前为止,关于上行链路的NOMA 方案标准尚未冻结,各通信公司提出了许多NOMA 上行方案,主要包括LG 公司提出的非正交编码多址接入(Non-Orthogonal Coded Multiple Access,NCMA)[9]、IDCC公司提出的交织域多址接入(Interleave Division Multiple Access,IDMA)[10]、SAMSUNG 公司提出的交织网多址接入(Interleave-Grid Multiple Access,IGMA)[11]、中兴公司提出的多用户共享接入(Multi-User Shared Access,MUSA)[12]、Ericsson 提出的韦尔奇界扩展多址接入(Welch-bound Spreading Multiple Access,WSMA)[13]、Qualcomm 公司提出的资源扩展多址接入(Resource Spread Multiple Access, RSMA)[14]、NTT DOCOMO 公司提出的用户特定广义韦尔奇界多址接入(User-specific Generalized Welchbound Multiple Access,UGMA)[15]、Nokia 公司提的非正交编码接入NOCA(Non-Orthogonal Coded Access,NOCA)[16]、华为公司提出的稀疏码多址接入技术(Sparse Code Multiple Access,SCMA)[17]、大唐公司提出的图样分割多址接入技术(Pattern Division Multiple Access,PDMA)[18]及Intel 公司提出的低码率扩频非正交多址(Low Code Rate Spreading,LCRS)[19]等。 此外,文献[20]提出了一种增量正交多址技术。
1 非正交多址的优势
从上文的容量分析结果可以看出,相比于OMA技术,NOMA 技术可以提供更高的传输速率。 具体来说,NOMA 的优势体现在以下几个方面:
(1) 信道容量
通过加标签的方法,NOMA 技术可以区分不同的用户,使得不同的用户可以在时间域和频率域上复用资源。 相对于OMA 技术,NOMA 技术可以更接近多用户系统的容量界[21]。 此外,在用户之间的公平性、调度的灵活性以及传输速率总和上,NOMA技术都具有更明显的优势。
(2) 提升频谱效率和小区边缘吞吐量
在NOMA 中,用户分享非正交的时频资源。 如上所述,在AWGN 信道中,虽然OMA 和NOMA 都可以达到容量界,但是NOMA 可以保证更大的用户公平性[22-23]。
(3) 大连接
在NOMA 中,支持的用户数量不受正交时频资源的严格限制。 因此,在资源不足的情况下,NOMA能够显著增加同时连接的用户数量,所以可以支持大规模连接[24-25]。
(4) 更低的延迟和更少的信令开销
在传统的依赖于访问授权请求的OMA 中,用户发起连接必须先向基站发送调度请求,基站在收到请求之后,通过下行链路发送信号来调度响应用户的接入请求。 因此这将极大增加传输延迟和信令开销,在5G 的大规模连接情况下这是不可接受的。LET 的访问授权过程大约需要15.5 ms[26],这无法满足5G 中用户延时保持在1 ms 以下的要求[27]。而在一些NOMA 的上行链路中,不需要动态调度[28]。 例如,在SCMA 的上行链路中,可以为与时域和频域中定义的预配置资源(例如码本)相关联的用户实现无授权的多址访问。 此外,在接收机处,使用盲检测和压缩感知(Compressive Sensing,CS)可以用于数据检测,实现了无授权的上行链路传输,显著减少了传输的延迟和信令开销。
(5) 不需要准确的信道状态信息
在功率域NOMA 中,对信道状态信息的准确性要求降低,因为信道状态信息仅仅用于功率分配。只要信道不快速改变,不准确的信道状态信息将不会严重影响系统性能[29]。
2 非正交多址技术方案
签名方案的设计是区分不同用户的重要手段。通过在链路上进行替换或增加模块,是现有NOMA技术签名设计的方法。 图1 给出了NOMA 发射机的通用结构[30]。 3GPP 目前仍在讨论5G 中使用的NOMA 方案,各通信公司都提出了基于不同签名设计方案的NOMA 方案,如表1 所示。 常用的签名方案包括比特级加扰器、比特级交织器、符号级加扰序列、符号级扩频序列、调制方式、映射方式以及功率分配等。
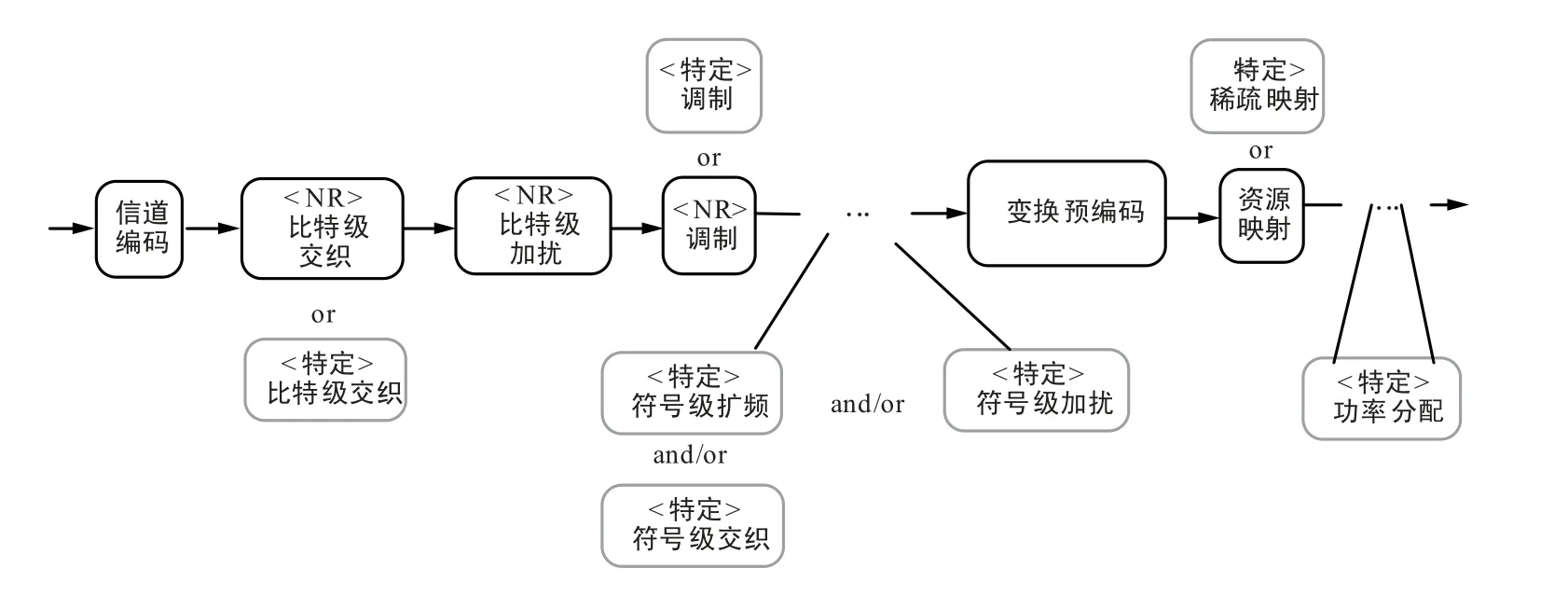
图1 NOMA 发射机的通用结构Fig.1 General structure of NOMA transmitter
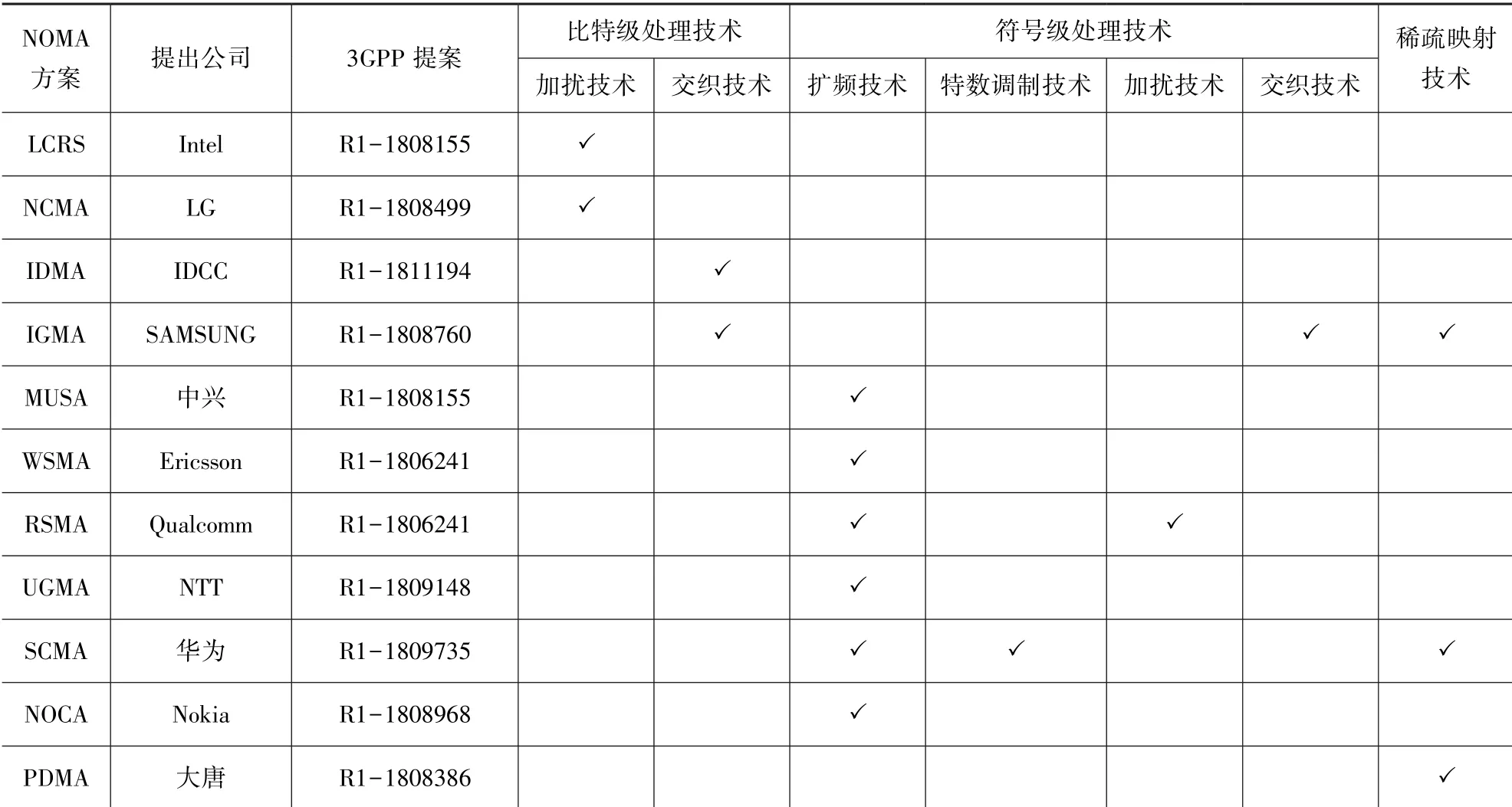
表1 各公司NOMA 方案总结 Tab.1 Summary of each company’s NOMA schemes
2.1 比特级技术
比特级技术的主要原理是通过随机化其他用户的信号,实现用户间的分离,根据加标签的不同方式,可以分为加扰技术和交织技术。
LCRS 和NCMA 都使用了比特级加扰技术,这2 种方案使用与现有NR 物理层标准相同的扰码生成方式[31]。 不同的用户使用的扰码不同,因此接收端可以根据扰码来分用户。
IDMA 和IGMA 使用比特级交织技术,用户随机选择交织方式。 不同的用户使用不同的交织方式,接收端根据交织方式区分用户。
此外,不同的用户也可以使用同样的交织方式,通过在起始位置改变循环移位偏移量来区分用户。
2.2 符号级技术
符号级技术主要包括扩频技术、特殊调制技术、加扰技术以及交织技术。 对于使用符号级扩频技术的方案,用户从扩频池中随机地选择扩频序列作为标签,该序列具有低互相关性的特点,接收端根据不同的扩频序列来区分用户。 在NOMA 技术中主要使用的扩频序列有以下几种:
① 韦尔奇界相等(Welch -Bound Equality,WBE)序列。 WSMA 和RSMA 使用了这种扩频序列,该序列的总平方互相关值可以通过式(1)计算:
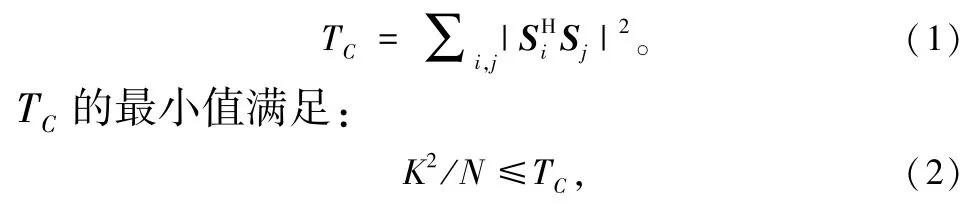
设计WBE 序列的基本原则是使式(2)中的等号成立。
② 格拉斯曼序列。 NCMA 使用了格拉斯曼序列,它是一种特殊的韦尔奇界相等序列,要使2 个序列间的互相关值最大值尽可能小。
③ 广义韦尔奇界相等(Generalized WBE,GWBE)序列。 UGMA 使用了该扩频序列,它是韦尔奇界相等序列的一种扩展,在计算互相关值时,考虑了发射功率的影响。
④ 量化复值序列。 MUSA 主要使用了该序列。每个用户随机选择一个扩频序列扩频,扩频之后的符号在相同的资源块上进行传输。
⑤ QPSK 序列。 NOCA 使用该序列进行扩频。通过对某个序列进行循环移位可以得到其他的序列,生成该序列的表达式如式(3)所示:
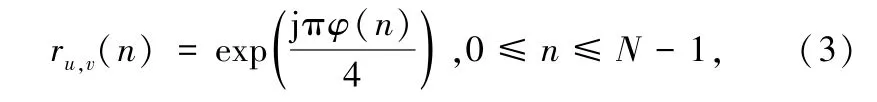
式中,u 表示根值,v 表示循环移位量,N 表示扩频倍数。 对于具有不同循环移位量和相同根值的2 个序列,互相关值为0;对于具有不同根值的序列,互相关性很低,这样在接收端就能区分不同用户。
⑥ 稀疏扩频序列:SCMA 和PDMA 使用了该序列。 根据扩频码本中0 的个数是否相等,稀疏扩频序列可以分成等权重和非等权重序列。 若0 的个数相等为等权重序列,0 的个数可变则为非等权重序列。
SCMA 定义了与传统的QAM 调制方式不同的一种高维调制方式,该调制方式增大了星座点之间的欧式距离,降低了用户间干扰,并提高了多用户解调的成功率。
RSMA 使用了符号级加扰方案,首先用短码进行扩频,然后用长扰码加扰,在接收端根据扰码区分出不同的用户。
IGMA 使用了符号级交织方案,首先使用0 元素填充将符号稀疏映射到对应的RB 上,接着对映射后的符号进行符号级交织,接收端根据映射方式和交织方式的不同来区别不同的用户。
3 NOMA 的性能评价与仿真实验
以上理论分析表明NOMA 比传统的OMA 技术具有更好的性能,为了验证分析结果,以下对NOMA进行一些性能评估和仿真实验。
3.1 来自技术报告的结果
3GPP 组织在技术报告TR 38.812[2]中,在大规模机器类通信(massive Machine-Type Communication,mMTC)、增强移动宽带(enhanced Mobile Broad-Band,eMBB)和高可靠低时延(Ultra Reliable Low Latency Communication,URLLC)3 种场景下,从链路级和系统级的层面对不同的NOMA 方案进行了性能比较。
3.1.1 链路级仿真结果
① 对于不同的传输块(Transport Block Set,TBS)大小,只要仿真配置合适(比如合适的码率),即使用不同的接收机,各种NOMA 方案之间的性能差异很小。
② 与理想信道估计相比,使用真实信道估计的NOMA 方案在mMTC 和eMBB 场景下有2 ~4 dB 的性能下降,在URLLC 场景下,有5 dB 的性能下降。
③ 对于每种情况,在相同的信道条件和相同的TBS 下,数量较多的用户设备(User Equipment,UE)比数量较少的UE 具有更大的性能下降。
3.1.2 系统级仿真结果
在系统级仿真中,设置了一个基准实验参数,在改变接收机类型、传输块大小和扩频码长度等参数的情况下,对不同的NOMA 方案进行了多种实验。结果表明,在mMTC 场景下,各种NOMA 方案的资源利用率可以达到基准方案的3 ~5 倍,在URLLC和eMBB 场景下,NOMA 方案的资源利用率和基准方案基本相等。
3.2 以MUSA 为例的仿真实验
在文献[31]中,以MUSA 为例,在mMTC 场景仿真参数下,仿真MUSA 与OMA 系统的用户过载率与系统吞吐量。 实验数值设置如表2 所示。

表2 MUSA 仿真数值设置Tab.2 Simulation parameter setting
图2 为传输包大小为10 Byte 时,MUSA 系统过载性能以及系统吞吐量仿真的结果。
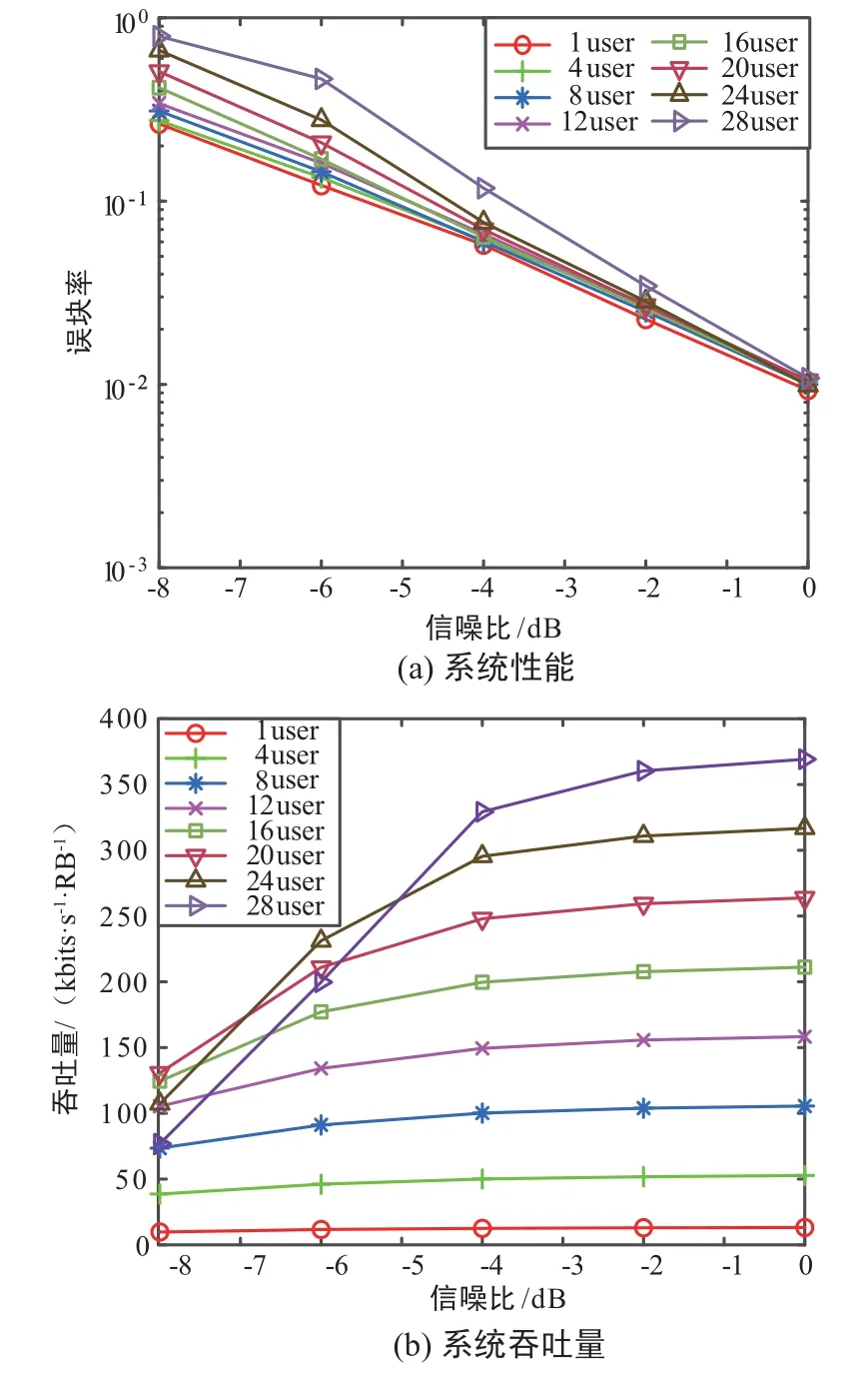
图2 传输包大小为10 Byte 时系统性能仿真结果Fig.2 System performance simulation results when the transfer packet size is 10 Byte
从图2 可以看出,在使用传统MMSE-SIC 接收机、1 发2 收的天线配置下,MUSA 系统最高能支持700%的用户过载量。 当信噪比(Signal to Noise Ratio,SNR)较低时,600%和700%过载量对应的系统性能相较于单用户情况下有大约2 ~2.5 dB 的性能损失,但SNR 慢慢变大时,高过载量时的系统性能逐步逼近单用户时的性能。 同时,在传输包大小为10 Byte 时,在每个RB 上,系统能支持的最大吞吐量可以达到370 kB/s,相较于单用户的情况时的13 kB/s,系统的吞吐量提高了约14.47 dB。
3.3 以SCMA 为例的仿真实验
3.3.1 基于稀疏贝叶斯学习的激活用户盲检测
在文献[32] 中,作者研究了在上行免许可SCMA 接收端中的激活用户盲检测算法,对用于用户盲检测激活的稀疏贝叶斯学习(Sparse Bayesian Learning,SBL)算法模型进行了推导和分析,该算法可以在没有激活用户先验信息情况下实现激活用户检测和信道响应估计。 作者还给出了实验结果,并进行了性能分析。
仿真环境设置:竞争接入区域中一共包含Q 个衰落子块(Fading Blocks,FB),每个FB 包含L 个子载波;每个激活用户在Q 个FBs 上同时进行导频序列的传输;在同一个传输时隙中,一个FB 所经历的信道是相同的,即信道响应也相同,且不同的FB 经历的信道不一样;假设接收端接收到各个用户的信号功率一致。 假设有30 个用户,每个用户都分配到一个竞争传输单元(Contention Transmission Units,CTU)上,即每个用户有一个特定的导频,总共有30 个导频。 具体仿真参数设置情况如表3 所示。

表3 SBL 激活用户检测算法仿真参数Tab.3 SBL activates user detection algorithm simulation parameters
图3(a)给出了SBL 激活用户检测算法在4 个FB、导频序列长度为12 的情况下,取不同信噪比时,多种用户激活数情况下的用户信道估计性能。图3(b)给出了SBL 激活用户检测算法在4 个FB、导频序列长度为24 的情况下,取不同信噪比时,多种用户激活数情况下的用户信道估计性能。 其中,均方误差(Mean-Square Error,MSE)为信道响应估计值与实际信道响应间的误差。
根据上文的仿真结果,随着激活用户数量增加,信道响应向量的稀疏度下降时,SBL 算法的性能也会出现一定程度的下降。 当导频序列长度增加时,SBL 算法在激活用户检测和信道估计上的性能都有显著提升。 此外,只要激活用户的数量在24 以下,可以保证所得出的检测结果仍然是稀疏的,所提出的算法依然可以很好地工作。
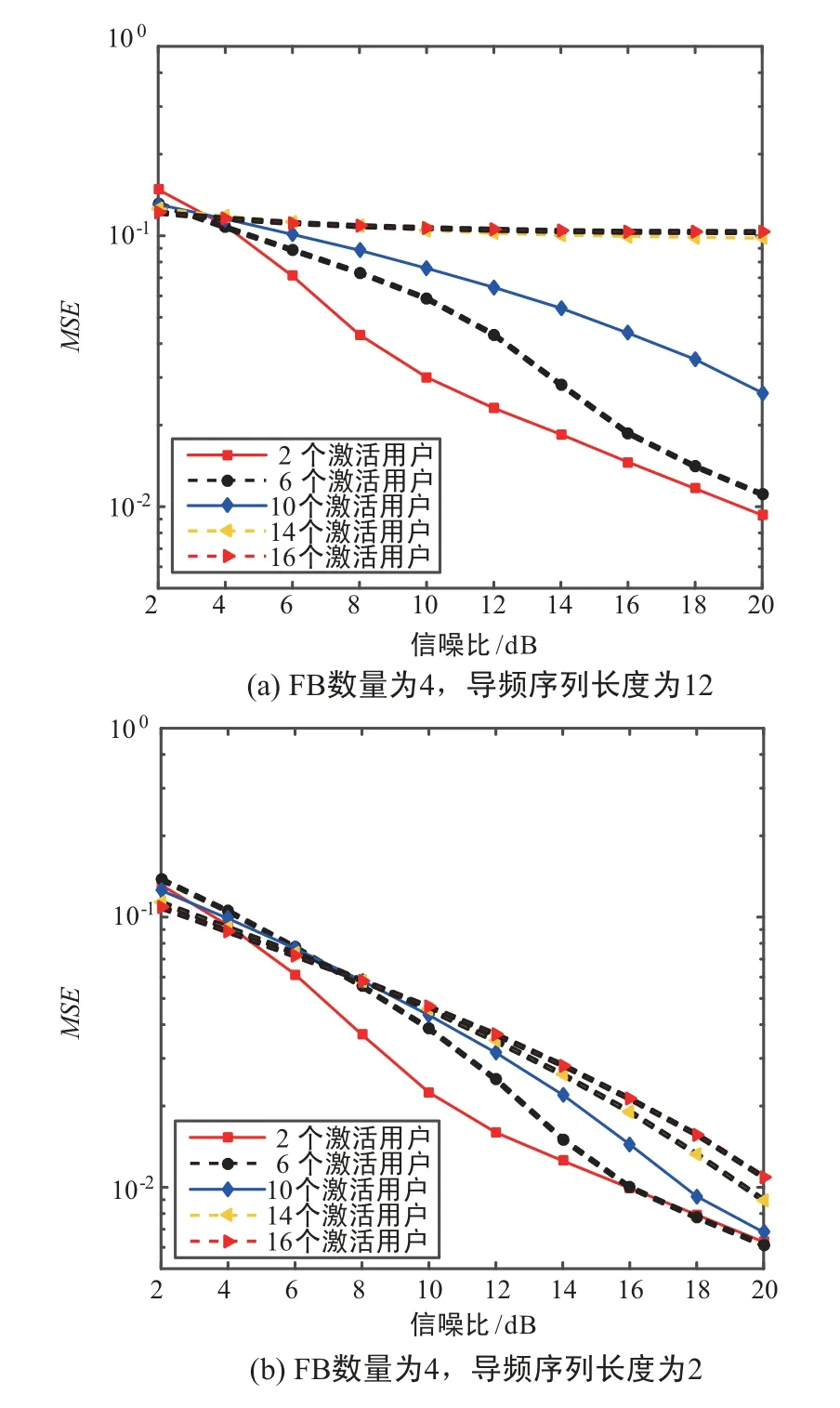
图3 不同激活用户数下SBL 检测算法信道估计性能Fig.3 Channel estimation performance of SBL detection algorithm under different activation users
3.3.2 基于稀疏贝叶斯学习和支持向量机联合的激活检测
文献[33]提出一种用户异步接入场景下的联合信道估计和激活用户检测算法,利用异步稀疏贝叶斯学习(Asynchronous Sparse Bayesian Learning,ASBL)算法根据导频信号在时域上进行信道估计,并利用支持向量机(Support Vector Machine,SVM)算法对信道估计结果进行分类,得到激活用户列表,实验参数设置如表4 所示。

表4 SCMA 实验参数Tab.4 Simulation parameter
图4 给出了具有4 个激活用户的漏检概率和SNR 之间的关系。 漏检概率是激活用户被标识为非激活用户的概率。 由图4 可以看出,与其他基于CS 的算法相比,所提出的ASBL 算法可以获得更低的漏检概率。 此外,当SNR 低时,使用SVM 分类器对漏检概率的影响可以忽略不计。 但是,对于激活用户检测问题,系统需要较低的漏检概率,因为如果将激活用户标识为非激活用户,则信道估计和后续数据解码都无法检测到该用户的存在,并恢复其发送的数据。 因此,基于ASBL 的接收器具有比CS 接收器更好的检测性能。
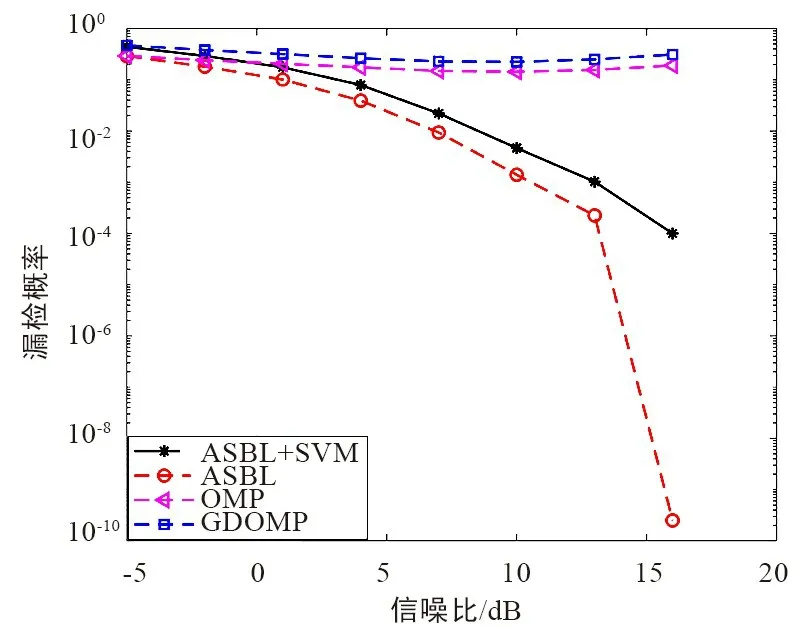
图4 4 个激活用户时的漏检率性能比较Fig.4 Comparison of missed detection performance when 4 users are activated
3.3. 3 未知用户稀疏度的上行免授权SCMA 的盲检测
文献[34]提出一种不需要上行授权的SCMA的盲检测器,它不需要用户稀疏性的先验知识。 具体来说是提出了有源用户检测器,以解决上行免授权SCMA 系统中用户未知问题;修改了联合消息传递算法(Joint Message Passing Algorithm,JMPA)解码器以用于错误检测概率低的情况。 仿真结果表明,改进的JMPA 解码器可以很好地识别错误检测。
4 未来的研究方向
NOMA 在未来一些有希望的研究方向,如下:
(1) 扩频序列或码本设计[35]
在低密度扩展(Low-Density Spreading,LDS)多址系统中,由于资源分配的非正交性,用户之间存在相互干扰。 在每个正交资源处叠加符号的最大数目是不确定的,用户的特定扩频序列或码字对接收机的干扰抵消能力有直接影响。 因此,应该优化消息传递算法,以便在接收机复杂度和支持的用户负载之间达成折衷。
(2) 与MIMO 相结合[8,36-37]
将NOMA 与MIMO 结合可以利用MIMO 系统的空间分集增益或复用增益来进一步提高频谱效率。 但是,这也存在技术难题,以功率域NOMA 为例,其关键思想是根据不同用户的信道增益分配不同的发送功率。 对于单天线系统来说,因为信道增益是标量,所以可以比较不同用户的信道增益。 但是,在MIMO 的场景中,信道增益由矩阵表示,因此,很难确定哪个用户的信道状态更好,这种情况导致了NOMA 实现的困难。
(3) 接收机设计[38-40]
对于5G 中的mMTC 场景,基于最大后验概率(Maximum A posteriori Probability,MAP)的接收器的复杂性可能会变得过高。 因此,MPA 的一些近似解决方案可用于降低接收机的复杂性。 例如干扰的高斯近似,它将干扰加噪声建模为高斯分布。 当连接数量变多时,这种近似变得更加精确。 对于基于串行干扰抵消(Successive Interference Cancellation,SIC)的接收机,传播错误会造成系统性能的下降,因此,良好的接收机设计是有必要的。
(4) 与认知无线电相结合[41-43]
通过认知无线电网络的概念,可以体现出NOMA技术的优势,将NOMA 系统中信道条件较差的用户视为认知无线电网络中的主要用户。 如果使用传统的OMA,则分配给该主要用户的带宽资源仅由该用户独占,即使该用户与基站的连接较差,也没有其他用户可以使用这些带宽资源。 使用NOMA 的好处在于认知无线电网络中,可以允许其他用户使用主要用户占用的频带资源。 尽管这些用户可能会对主要用户造成干扰,但可以显著提高总体系统吞吐量。
(5) 信道估计[44-46]
在大多数研究NOMA 的论文中,都假定使用完美的信道状态信息(Channel State Information,CSI)进行资源分配或多用户检测。 然而,在真实系统中获得完美的CSI 是不切实际的,因此在NOMA 中存在信道估计误差。 随着未来5G 系统中用户数量的增加,将导致更大的用户间干扰,进而可能导致严重的信道估计误差。 因此,需要更高级的信道估计算法以在NOMA 系统中实现准确的信道估计。
(6) 全双工NOMA[47-49]
全双工NOMA(Full-Duplex NOMA,FD-NOMA)在上下行同时使用NOMA 传输,有效地确保了上行和下行链路用户之间的频谱共享,并避免了信道条件差的下行链路(或上行链路)用户占用稀缺带宽的情况,相比于半双工NOMA(Half-Duplex NOMA,HD-NOMA),能够增加系统的容量。 然而,FD-NOMA 可能会在上行链路和下行链路传输中引起强烈的同频道干扰。 例如,对于上行链路传输,由FD-NOMA 引起的残留自干扰会降低基站的接收可靠性,而对于下行链路传输,来自上行用户的信号会对下行用户造成强烈干扰。 因此,如何有效地抑制同频干扰是使用FD-NOMA 的一个难点。
5 结束语
NOMA 是实现5G 性能要求(如大规模连接和高吞吐量等)的重要支持技术。 本文讨论了NOMA技术的发展、原理以及相比于OMA 技术的优势。从多址签名设计的层面介绍了各个NOMA 技术提案的主要原理和关键特性。 此外,在理论分析基础上,本文还介绍了以MUSA 和SCMA 为例的仿真实验,进一步展现了NOMA 的性能优势。 最后,本文给出了NOMA 技术一些有潜力的研究方向。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
今日农业(2022年14期)2022-09-15
移动通信(2021年5期)2021-10-25
纺织科技进展(2021年5期)2021-07-22
火控雷达技术(2021年2期)2021-07-21
电子制作(2019年20期)2019-12-04
家庭影院技术(2019年8期)2019-08-27
雷达与对抗(2018年3期)2018-10-12
北京航空航天大学学报(2017年3期)2017-11-23
科技创新导报(2016年27期)2017-03-14
