
基于改进Simhash的虚拟机镜像去重方法
2020-01-10 03:17:20张灿阳刘晓洁
四川大学学报(自然科学版) 2020年1期
张灿阳, 刘晓洁
(1.四川大学计算机学院, 成都 610065; 2.四川大学网络空间安全学院, 成都 610065)
1 引 言
虚拟化技术历经多年的发展与沉淀,已经成为搭建云环境的关键性技术,虚拟机的部署愈加广泛.研究指出,虚拟机镜像大量存在于企业的生产环境中,大型企业中镜像数量甚至会高达5 000~20 000个,且增长速度极快[1],这导致了云平台需要管理数量庞大的镜像文件.实际上,在应用系统所保存的数据中,高达60%的数据是冗余的,备份归档系统中,重复数据的比例高达80%~90%[2].在针对虚拟机的备份场景中,这一比例甚至更高,主要原因有如下两点:(1) 虚拟机镜像文件通常会包含大量零块(即空白数据块),例如分区格式化产生的未利用空间等,这些零块对于备份系统来说均属于重复数据;(2) 用户在部署虚拟机的过程中,选择通过统一的OVF(Open Virtualization Format)模板创建,或者通过已存在的虚拟机实例进行复制创建,将导致两个虚拟机镜像之间存在很高的数据冗余率,即使用户创建全新的虚拟机,也有可能因为运行了相同的操作系统或者相似的应用而导致数据重复率较高.
大量的实验数据表明,云环境中虚拟机镜像文件的数据冗余率超过50%[3].对于备份中心来说,同一虚拟机可能存在多个备份副本,因此,使用重复数据删除技术减少虚拟机镜像的空间占用率成为降低存储成本的主要技术之一.
虚拟机镜像去重在本质上是文件去重,但是对于海量的虚拟机镜像文件,去重过程中会产生巨大的指纹索引数据(数据块的摘要值和该数据块对应的偏移),当这些指纹索引超出可用内存的大小时,将不得不进行频繁的内外存交换来完成指纹的查找,这会带来巨大的时间与空间开销,增加服务器的响应时间[4],系统的服务质量QOS(Quality Of Service)受到影响.针对上述问题,本文提出了一种基于改进Simhash的镜像聚类去重方法ICDA-IS(Image Clustering Deduplication Algorithm Based on Improved Simhash),该方法使用改进Simhash提取镜像特征值,并利用DBSCAN算法对镜像进行分组去重.实验结果证明,本文的方法牺牲了少量去重率,但是减少了相当可观的时间开销和内存占用.
2 虚拟机镜像去重问题分析
虚拟机镜像去重会产生海量的指纹索引数据,在去重过程中会频繁进行指纹查找.如果将这些数据全部置于可用内存中,将会消耗大量的内存资源,对服务器性能造成巨大影响.反之,如果将这部分数据置于外存中,由于访问一次外存的时间要远远大于一次内存读写时间,因此会大大增加去重的时间开销,Zhu等人将其称为磁盘瓶颈问题[5].
与常规文件相比,虚拟机镜像文件有如下鲜明特点:(1) 占用存储空间较大,一般从若干GB到数百GB不等,特殊情况下会占用数TB的存储资源; (2) 镜像文件中往往会包含较多的零块,如虚拟磁盘中的未分配区域,或者是分区中的未利用空间等,在去重中这些零块均是重复数据.文献指出,零块在镜像文件中的比例高达35%以上[6]; (3) 在镜像文件的内部,包含了大量虚拟机操作系统文件,实验结果表明,具有相同操作系统的虚拟机镜像的重复数据删除率能达到70%以上[7].同样,在运行了相同应用的虚拟机镜像中,也会有类似的现象.
如何提取镜像中的有效数据,避免磁盘读写瓶颈,降低海量虚拟机镜像的去重时间,是虚拟机镜像去重的关键问题.
Jin等人[3]通过实验证明,在虚拟机镜像去重中,选取固定长度分块和可变长分块得到的去重率基本相同.Lillibridge等人[8]采用取样方法,内存中只保留文件分段的指纹样本,虽然降低了内存占用,但是随着镜像文件的增加,其内存开销依然会增大.Zhu等人[5]在LPC(Locality Preserved Caching)技术的基础上提出了SISL(Stream-Informed Segment Layout)技术,优化了传统缓存方案,为数据块和块描述符提供了更好的空间局部性,大幅降减少了去重过程中磁盘的I/O次数.但是在虚拟机镜像去重这样的特殊场景中,该方法无法过滤镜像中的大量零块,仍会有较多的CPU计算开销.
文献[1]提出了一种基于聚类分组的虚拟机镜像去冗余方法VMIDM-BC(Virtual Machine Image Deduplication Method Based on Clustering),将海量虚拟机镜像先分组再去重,每次仅将分组内的指纹数据载入内存,解决了磁盘的读写瓶颈问题,但是同样无法快速剔除镜像中的大量空白数据块,从而使得镜像内部去重时间较长.其次,该方法定义两个镜像A和B的相似度Sim(A,B)为
(1)
其中,M′=(f1,f2,…,fm)表示一个镜像文件内部定长分块去重之后的数据块指纹集合.可见计算两个镜像相似度的时间复杂度与镜像包含数据块的指纹数量成正比,在面对大镜像文件时计算相似度的时间开销较大.此外,VMIDM-BC采用K-means聚类完成分组操作,在去重中需要计算任意两个镜像之间的相似度,而镜像的指纹数据存储在磁盘上,因此聚类过程必定会频繁读写外存去获取某个镜像的指纹集合,即使采用预处理的方法,在聚类之前计算出所有镜像之间的相似度矩阵,也需要多次磁盘I/O才能完成,因此该去重方法的时间开销依然较大.
3 基于改进Simhash算法的聚类去重方法
本文方法旨在消除海量虚拟机镜像去重过程中极易出现的磁盘瓶颈问题,并尽可能在去重之前就过滤掉镜像中的空白数据块,缩短去重时间.其主要思想如下:(1) 挂载虚拟机镜像中的文件系统,获取镜像中的有效数据,避免在去重过程中读取镜像中的大量空白数据块,有效降低I/O次数; (2) 利用DBSCAN聚类算法和镜像段的特征值将全部待去重镜像段分组,从而将一个全局去重问题分解为若干个局部去重的子问题.在每个分组的去重过程中,能够将分组内的指纹索引数据置于内存中,大幅降低了由于频繁访问磁盘而带来的时间开销.
在判断两个镜像是否相似的过程中,存在如下两种情况:(1) 两个虚拟机镜像的操作系统不同,但是包含了大量重复的应用数据,此时镜像之间的重复数据基本存在于保存该应用数据的分区中; (2) 两个镜像的操作系统相同但是运行了不同的应用,在这种情况下,镜像间的冗余数据绝大部分存在于镜像的操作系统分区上.因此,有必要根据虚拟机镜像的内部分区结构,将一个完整的磁盘镜像分割为粒度更小的镜像段,以获得更为精确的相似关系.
在此基础上,我们利用DBSCAN算法将分割后的虚拟机镜像段分组,把重复度高的镜像段归在同一个类中进行去重,基本流程如图1所示.

图1 聚类去重方法的基本流程Fig.1 Basic process of clustering deduplication method
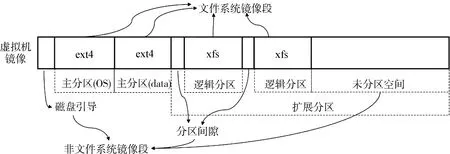
图2 镜像段示意图Fig.2 Schematic diagram of image segment
3.1 虚拟机镜像分段
由于虚拟机镜像文件中通常包含了完整的虚拟磁盘信息,因此可以通过读取镜像的分区表来获得虚拟磁盘内部的分区信息.分割后得到的镜像段本质上是一个虚拟机镜像文件在特定偏移处的一部分,所有镜像段按顺序组成一个完整的虚拟机镜像,如图2所示.这些镜像段大致分为三类:(1)包含操作系统分区的系统镜像段;(2)包含用户数据分区的应用数据镜像段;(3)不包含文件系统的镜像文件头、磁盘引导、分区间隙以及未利用空间等,统称为非文件系统镜像段.
3.2 提取镜像段的特征值
Charikar提出的Simhash算法[9]本质上是一种局部敏感哈希LSH(Locality-Sensitive Hashing)算法[10],相似文本会有相似的Simhash签名,即签名之间的海明距离(Hamming Distance)较小.Manku等人[11]提出了基于Simhash的海量相似网页去重方案,其核心是文本向量化[12],效果显著.
但是,Simhash算法只能用于文本的相似度[13]计算中,而镜像段是虚拟机镜像的一部分,属于二进制文件,不能直接应用该算法获取镜像段的签名,无法进一步完成类似于文本聚类[14]的操作,从而也无法将全局问题分解为局部问题求解.下文给出提取镜像段特征值的改进Simhash算法,计算镜像段S的Simhash签名详细过程如下.
1) 镜像段映射到虚拟块设备.
如果镜像段S包含文件系统,则通过映射至空闲回环设备(loop device)的方式,将其虚拟为只读块设备并识别该文件系统类型,将其挂载到指定目录,获得镜像段S包含的文件集合F={file1,file2,…,filen}.
2) 计算文件的指纹和权重.
使用MD5摘要算法计算文件filei的指纹fingeri=bit0bit1…bitL(L=128,即MD5摘要的比特宽度),镜像段S的文件指纹集合M={finger1,finger2,…,fingern}.在同一个镜像段中,如果一个文件的尺寸越大,出现的次数越多,那么这个文件在该镜像段中占用数据块的比例则越高.据此,利用式(2)计算filei的权重weighti.
(2)
其中,file_sizei是文件filei的大小(单位:KB),file_frequencyi表示文件filei出现的频数,SegSize是镜像段S的大小(单位:KB).式(2)实际上表明了一个文件及其所有副本在一个镜像段中占用存储空间的比例大小.
3) 指纹向量加权.
对于M中的指纹fingeri,初始化其对应的加权向量veci=[01,02,…,0L],遍历指纹中的每一个比特位fingerik.对于一个文件来说,其占用空间越大,则权重越大,同时对镜像段的simhash值产生的影响越大,反之,小文件和少量数据块仅会对最终的simhash值产生微小的影响.因此对于某个文件的指纹来说,若其中某个bit位为1,则将该位扩大为其权重倍,反之则将该位减去其权重,即式(3),利用该公式计算文件的加权向量veci,保证相似的镜像段得到相似的simhash值.在此基础上,将镜像段S表示为一组向量集合V={vec1,vec2,…,vecn}.
(3)

图3 提取Simhash签名示例Fig.3 Example of extracting a Simhash signature
4) 求和降维.
为了得到一个镜像段的Simhash值,我们将其包含的所有文件的加权向量求和,如式(4)所示.为了加速Simhash的查找并降低存储空间,我们遍历求和结果Sum,并将其中的正数置1,负数置0,得到最终长度为L的Simhash签名.图3是改进Simhash算法的过程示例图.
(4)
3.3 镜像段的聚类
对于占用空间达到数TB甚至PB、EB级别的海量虚拟机镜像而言,去重过程中产生的指纹索引表不可能全部放在内存中,因此指纹查询增加了大量额外的磁盘I/O时间,整体去重时间大幅延长.为了避免这些时间开销,我们提出了一种基于DBSCAN的自适应聚类去重方法,算法流程如图4所示.

图4 镜像段聚类去重示意图Fig.4 Flowchart of image segments cluster deduplication
上述流程图的基本思想为:将包含文件系统的镜像段按照系统分区和数据分区两个分支进行处理,含相同的操作系统的镜像段归为同一类,含相似应用数据的镜像段归为同一类,与此同时,我们限制每个分类中所包含镜像段的总大小,使得每个分类在去重中所产生的指纹索引表均小于可用内存的大小,在指纹查找过程中完全避免了因内存未命中而增加的磁盘I/O时间.
对这些镜像段的聚类大致分为以下三种情况.
1) 操作系统镜像段.
实验结果[15]表明,在20个不同的Windows NT(windows new technology)映像的服务器中数据冗余率高达58%,实际上,同一操作系统的同种发行版本之间重复数据所占的比例将会更高.但是在不同类型的操作系统中,其系统文件的冗余率则很低.因此对于包含操作系统分区的镜像段,按照其系统类型进行分类去重,以获得更高的去重率.
2) 应用数据镜像段.
对于不包含操作系统分区的镜像段来说,我们利用3.2节提取的Simhash签名对其进行聚类.对于镜像段A,B来说,如果二者之间的重复数据越多,那么两个镜像段的Simhash签名SA和SB也就越相似,两者的海明距离也会越小.我们用式(5)计算镜像A、B的相似度.
(5)
其中,SigLen表示Simhash签名的长度.根据式(5)可知,两个镜像段之间的相似度取值范围为[0,1],如果相似度超过阈值THRESHOLD,则可认为两个镜像段相似度较高.
在此基础上,我们采用DBSCAN聚类算法对应用数据镜像段进行处理,聚类算法如算法1所示.
算法1 应用数据镜像段聚类算法.
输入:包含n个应用数据镜像段的Simhash签名集合D={S1,S2,…,Sn},阈值THRESHOLD,每个类最少包含的镜像段个数MIN.
Begin:
1) SetC=0 //初始类编号
2) for each unvisitedSinD
3) markSas visited
4)N= RangeQuery(S,THRESHOLD) //找到与S相似度大于THRESHOLD的镜像段
5) if |N| < MIN
6) markSas NOISE //类中元素过少被标记为噪音
7) else
8) SetC=C+ 1 //类编号增加1,即创建新类
9) addSto clusterC//将镜像段S添加到类C中
11) for eachS’ inN//访问N中的每一个镜像段
12) if S’ is unvisited
13) markS’ as visited
14)N’ = RangeQuery(S’, THRESHOLD) //类的扩充
15) if |N’ | ≥ MIN
16)N=N∪N’ //邻域合并
17) end if
18) end if
19) ifS’ is not yet member of any cluster
20) addS’ to clusterC
21) end if
22) end for
23) end if
24) end for
End.
为了减少噪音点对去重结果造成的影响,在聚类完成之后,我们将包含镜像段比较少的类归为一组进行处理,最大限度地利用当前可用内存,减少去重的时间.
3) 非文件系统镜像段.
对于虚拟机镜像而言,除去包含文件系统的镜像段之后,剩余的磁盘空间大致包含了镜像文件头、分区间隙、未格式化的分区以及磁盘的未利用空间等.这些镜像段中,绝大部分扇区均是空白扇区,因此将所有非文件系统镜像段作为一个单独的分组进行处理.如果该分组中镜像段的总大小超出最大限制,将其分裂并确保每个小分组中的镜像段总大小不超出上限.
3.4 二级去重策略
在所有的镜像段分类完成之后,如果一个分组内的镜像段包含文件系统,那么我们采用文件级+块级的二级去重策略进行去重操作,文件级去重能够保证同一个文件只保留一个副本,块级去重能够去除文件内部和文件之间的重复数据块,尽可能提高去重率.如果组内的镜像段不含文件系统,我们直接采用定长分块去重策略.
由于在提取Simhash签名的过程中,我们已经计算了镜像段中所有文件的指纹值,因此,对于一个镜像段集合来说,我们先进行分组范围内的文件级去重,在此基础上,对于较大的文件,进一步实现分组范围内的块级去重,具体过程见算法2.
算法2 文件系统镜像段的二级重删算法
输入:包含m个镜像段的分组C={S1,S2,…,Sm},定长分块大小BLOCK_SIZE.
Begin:
1) SetF= { },B= { } //分组内所有不重复文件的集合、不重复数据块的集合
2) for eachSiinC
3) Mount(Si) //挂载镜像段并进入其文件系统
4) for eachfilejinSi
5) iffilejnot in F //通过filej的指纹判断该文件是否重复
6)F=F∪ {filej} //将不重复的文件filej加入集合F
7) end if
8) end for
9) end for
10) for eachfilekinF//遍历文件集合F
11) if QueryFileSize(filek) ≤ BLOCK_SIZE
12) continue //如果文件小于BLOCK_SIZE,则该文件不进行块级去重
13) else
14)file_block_set=FixedSizeChunk(filek) //固定长度分块
15) for eachblockminfile_block_set
16) ifblockmnot inB//通过blockm的指纹判断该数据块是否重复
17)B=B∪ {blockm} //将不重复的数据块blockm加入集合B
18) end if
19) end for
20)SaveFileMetadata(filek) //保存大文件元数据
21)F=F- {filek} //将进行了块级去重的文件从F中删除
22) end if
23) end for
24)SaveBlockData(B) //保存唯一数据块集合B
25)SaveSmallFile(F) //保存F中剩余的小文件
End.
二级重删的目的是在保证去重速度的同时达到较高的去重率.在第一级的文件重删过程中,我们仅读取了镜像中的文件,从而减少了读取和计算大量空白数据块所消耗的时间.其后的块级去重主要是针对相似的大文件而设计,因为相似文件的指纹不同,却包含了较多的重复数据块,为了提高去重率,我们增加了大文件之间的块级去重.
4 实验验证
我们通过一系列的实验来验证本文提出算法ICDA-IS的有效性.从vSphere云平台和OpenStack云环境中选取100个不同的虚拟机镜像,每个镜像的大小在3~50 GB之间,共计989 GB,其中包括vmdk格式的镜像27个,raw格式镜像73个.实验中,去重服务器的具体配置如表1所示,我们将聚类去重的内存限制为500 MB,采用16字节的MD5值作为文件和数据块的指纹,8字节的地址作为唯一数据块索引,如果我们采用4 KB大小的定长分块全局去重,在最坏的情况下指纹索引数据将达到5.8 GB,远超可用内存的大小.

表1 实验环境
在对比实验中,首先我们实现了基于硬盘哈希表的全局去重算法,该方法将所有的指纹索引数据存放在磁盘中,并在查找过程中进行读写磁盘操作.其次与开源去重工具Deduputil做对比,该工具使用布隆过滤器[16]和集合关联缓存等方案优化关键字的查找,核心是一个轻量级的KeyValue存储系统.经多年市场使用反馈,该去重工具性能稳定,且指纹查找效率与命中率均表现十分优秀.
小规模数据(10个镜像共计120 GB)的情况下,分别采用硬盘哈希表、Deduputil和ICDA-IS算法进行去重操作,为了降低偶然性误差的影响,每组对比实验重复10次,图5给出了去重消耗的时间.在小规模数据集的实验结果中,与基于硬盘哈希表的去重相比,ICDA-IS算法节约了超过50%的去重时间.由于小规模数据集所产生的指纹索引数据相对较小(不足1 GB),对于Deduputil来说相当于全内存去重(指纹索引全部缓存在内存中),但是ICDA-IS仍能够减少约30%的去重时间,原因就在于,ICDA-IS算法仅读取镜像中的有效数据,减少了处理大量空白数据块的时间.三种方法的数据压缩率如表2所示,可以看到,基于硬盘哈希表的去重可以达到18.23%的数据压缩率,Deduputil可以达到18.55%的数据压缩率,本文提出的ICDA-IS算法的实际数据压缩率为19.26%,与前两者的差距不足1%.
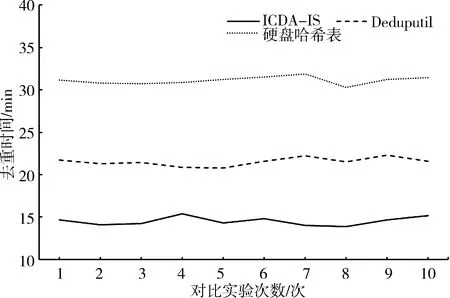
图5 小规模数据下的去重时间Fig.5 Deduplication time under small-scale data
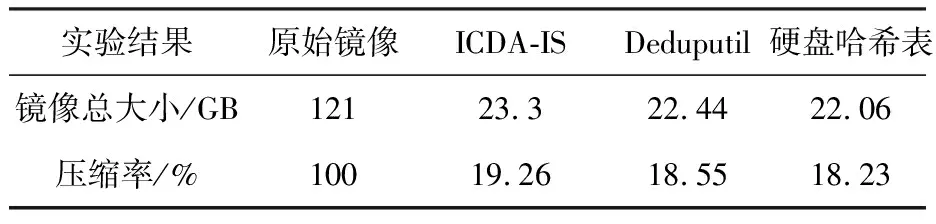
实验结果原始镜像ICDA-ISDeduputil硬盘哈希表镜像总大小/GB12123.322.4422.06压缩率/%10019.26 18.55 18.23
大规模数据集(100个镜像共计989 GB)情况下增加与文献[1]中VMIDM-BC算法的对比,图6和表3记录了4种去重方式的数据压缩率和去重时间.
从实验结果可以看出,在海量镜像去重情况下:
(1) 就去重时间而言,ICDA-IS算法比Deduputil减少了60%~70%的时间开销,这是因为随着读入数据块的增加,Deduputil产生的指纹索引数据在不断增大,内存引作为磁盘中指纹索引数据的缓存,其命中率持续降低,从而导致读写磁盘次数增加,去重效率低下.在与VMIDM-BC算法的对比中,由于ICDA-IS算法在预处理的过程中剔除了大量的无效空白数据块,从而降低了磁盘I/O次数,并利用改进Simhash算法提取了固定长度的镜像段特征值加快了聚类过程,因此比后者节省了约30%的去重时间.
(2) 就压缩率来看,ICDA-IS算法比全局去重(Deduputil和硬盘哈希表)低3%左右,但是从表3可知,对于压缩掉的近90%的重复数据来说,增加微小的存储开销而减少约70%的去重时间开销,是可以接受且值得的.

图6 大规模数据集下的去重时间Fig.6 Deduplication time under large-scale data
表3大规模数据集下的压缩率
Tab.3Datacompressionrateunderbig-scaledata
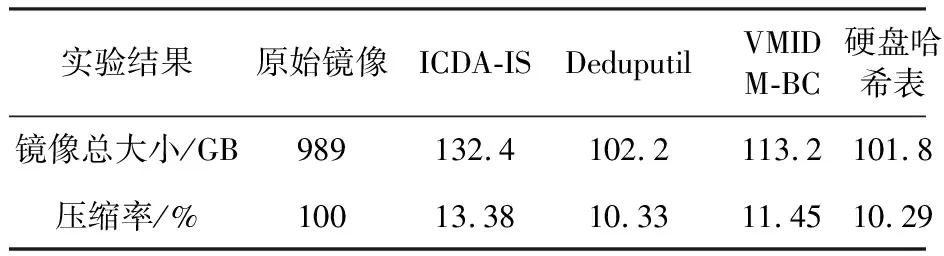
实验结果原始镜像ICDA-ISDeduputilVMIDM-BC硬盘哈希表镜像总大小/GB989132.4102.2113.2101.8压缩率/%10013.3810.3311.4510.29
在大规模数据集的去重测试中,各算法占用的内存情况如图7所示.可以看出,随着去重镜像总量的增加,Deduputil消耗的内存空间也逐渐增大,在完成500 GB的镜像去重时,该算法消耗的内存高达18 GB.本文提出的ICDA-IS算法与文献[1]中的VMIDM-BC算法均是在完成分类的基础上进行多次小规模去重,保证了内存消耗始终在1 GB以下,极大减少了云数据中心的资源开销.
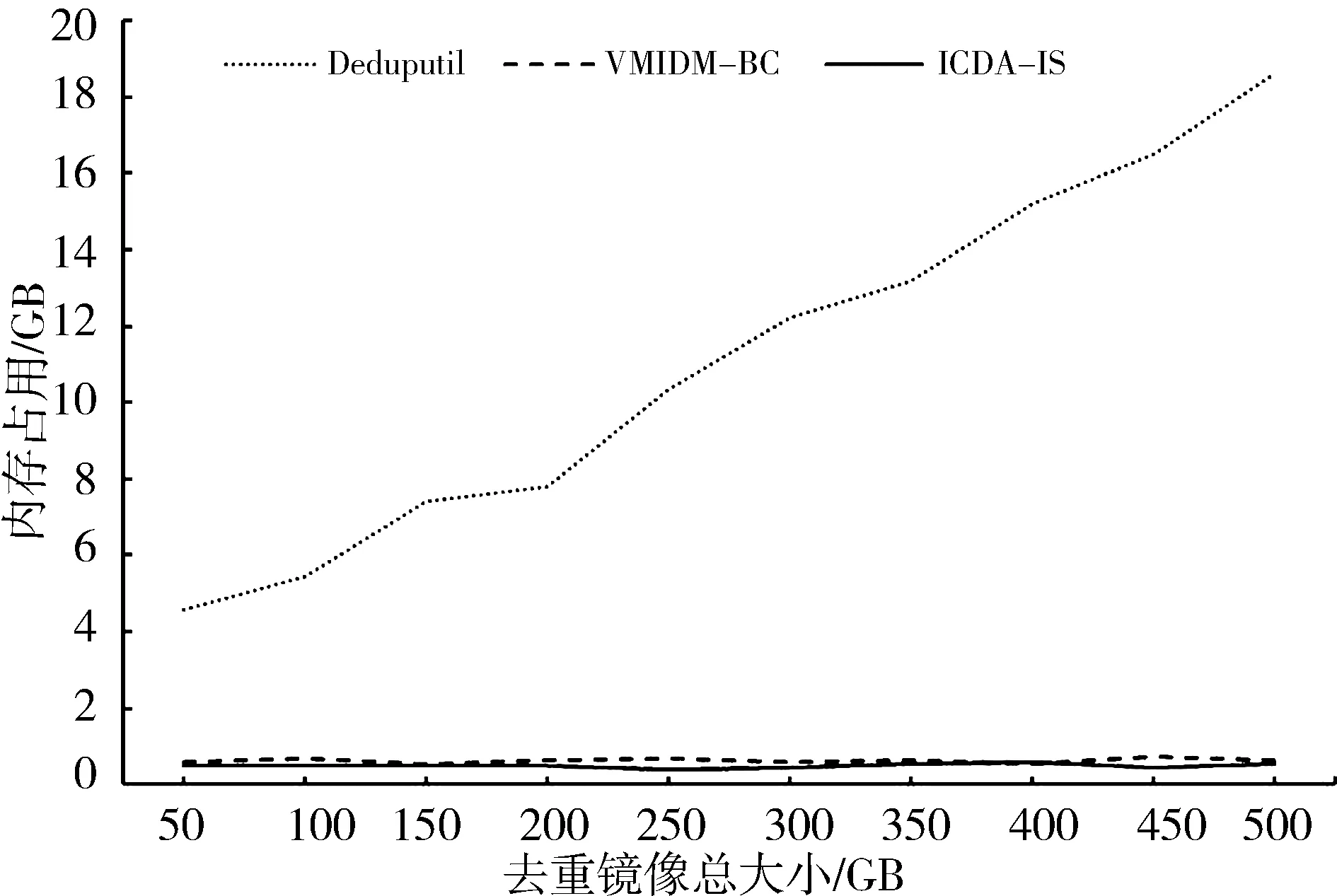
图7 去重过程中内存占用Fig.7 Memory usage during deduplication
云环境中,将重复数据删除技术引入海量虚拟机备份场景可以节省大量的存储资源,但是去重过程中极易出现磁盘瓶颈导致重删效率急剧下降.针对该问题,本文提出了一种基于改进Simhash算法的海量虚拟机镜像聚类去重方法,利用虚拟机镜像的内部结构将完整的镜像分割为若干个较小粒度的镜像段,并针对镜像段的特殊性改进了传统的Simhash算法,将其用来提取二进制镜像段的特征值.利用该特征值和DBSCAN算法实现了对镜像段的聚类,从而将全局去重变成了局部的分组内部去重,避免了磁盘瓶颈,使得去重操作的时间大幅度降低.本文通过实验验证了该方法在海量虚拟机镜像去重的情景中,能够以消耗微小的存储空间为代价,减少相当可观的时间开销.
但是本文仍存在一些不足,在处理自组织格式的虚拟机镜像文件(如qcow2格式)时,由于其内部结构与物理磁盘不同,因此无法按照分区将其分割为镜像段,以及云环境中为了保护用户隐私[17]而存在的大量加密数据[18],如何处理这种类型的镜像文件实现快速去重,也是今后研究的方向.
猜你喜欢
当代党员(2020年20期)2020-11-06 04:17:52
电脑爱好者(2019年2期)2019-10-30 03:45:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
小康(2018年23期)2018-08-23 06:18:52
电脑爱好者(2018年12期)2018-06-26 16:24:30
网络安全和信息化(2017年3期)2017-03-10 07:45:51
科技创新与应用(2017年3期)2017-02-18 16:12:50
网络安全和信息化(2016年8期)2016-11-26 06:42:50
电脑迷(2015年9期)2015-05-30 22:08:35
小康(2015年4期)2015-03-31 14:57:40
