
基于相异性空间和多分类器融合的文本分类方法
2020-01-10 01:29徐安德赵亚康张月群
兵器装备工程学报 2019年12期
徐安德,赵亚康,张月群,鲁 杨
(1 南京农业大学 工学院, 南京 210095;2 东南大学 机械工程学院, 南京 211189)
互联网时代的文本数量以指数级增长,面对海量文本信息,文本分类(或文档分类)显得至关重要,文本分类是将文本合并为一个或多个根据文本内容预定义的类别,以提高自动分类的效率[1]。其应用领域广泛,如主题检测[2],垃圾邮件过滤[3]、情感分析[4]等。因此,文本分类的研究具有重大意义和价值。
在分类过程中,文档的表示非常重要。词袋法(BoW)是一种最常用的文档表示法,但词袋法存在高维性、高特征实例比和稀疏性等缺陷[5]。为了解决词袋法的缺陷,一些研究者提出一些优化方法,如文献[6]利用了结构相似性;文献[7]提出了基于损失函数的方法,但这些方法降低维数和特征实例比有限。在众多方法中,多分类器系统较受欢迎,其综合性能较好,如文献[8]提出一种基于语义理解的注意力神经网络、长短期记忆网络与卷积神经网络的多元特征融合中文文本分类模型。文献[9]提出一个最大熵的情感模型,通过组合式方式来进行维数约简,以降低文本数据的高维性和稀疏性。但该方法的主要难题是如何确定聚类数量。文献[10]在文本分类问题中应用多分类器融合方法,利用一个较小的分类器池(2~4个分类器),将多个分类器在管道中组合。文献[11]使用隐性话题和相关词语来丰富BoW表征,这种方式能够增加稀疏文本的话题相关度,同时将朴素贝叶斯和最大熵分类器进行融合。
鉴于多分类器融合的优势,本文也提出了一个类似方法,使用不同的相异性表征,将特征向量转换为新的低维表示[12]。在该表征方式中,每个文档由一个相异性向量表示,相异性向量由该文档到表征集中所有文档的距离组成。由于表征集包含不同类别的文档,相同类别文档之间的相异度应该较小,而不同类别文档之间的距离很大。因此,增加类别间的辨识性,在文本分类中作用重大。
1 相异性表征
目前常用的有3种相异性表征法[13]:预拓扑、相异性空间和嵌入。预拓扑法有k-NN分类器,可视为基于相异性的分类器,嵌入法需要根据使用的度量对每个分类器进行修改。本文使用了相异性空间框架,因为相异性空间框架具有较好的普适性,即,适用于任何度量和任何需要特征向量作为输入的分类器。
相异性表征指的是通过计算一个文档(或文档集)与表征集R={p1,p2, …,pQ}的每个文档相异度而定义的映射。表征集包括使用原型选择方法从更大集合中选出的Q个原型。

(1)
(2)
相异性矩阵可被用作数据矩阵,其中,每行表示一个文档,每列表示一个特征。
值得一提,相异性表征能够缓解BoW的3个缺陷:
1) 高维性。在相异性表征后,特征数量等于表征集中的文档数量(Q),而表征集为训练集的子集(Q≤N)。鉴于大部分文本分类语料库有着较高的特征实例比,即原始特征数(V)大于等于训练集中的文档数(V≥N)。而相异性表征将减少特征数量(Q≤V)。
2) 稀疏数据矩阵。在应用相异性表征后,每个特征表示两个不同集合文档之间的距离(d(xi,pk))。当两个文档的所有特征值均相同时,该距离为零(但较为罕见)。由此显著降低了稀疏性。
3) 高特征实例比。在维数约简后,该比例也会随之降低(Q≤N)。
2 相异性空间的多分类器融合
本文提出的方法是一个多分类器方法。其主要理念是对多个分类器的响应进行合并以分类文档,在不同的相异性空间上训练每个分类器。
2.1 符号描述
所提方法使用了几个不同的集合,每个集合的符号解释如下:

2) 测试集Y由M个文档yj∈Y={y1,y2,…,yM}组成,使用与训练集相同的BoW表征。
3)Xs(s={1,2,…,L}为训练集X的子集,每个训练子集Xs的大小等于原始训练集。
4) 表征集Rs由Q个文档pk∈Rs={p1,p2,…,pQ}所组成。
2.2 训练阶段
本文方法的训练阶段包括4个模块:自举、表征集生成、表征变换和分类器训练,如图1所示。输入参数为训练集(X),分类器数量(L),以及每个表征集Rs的原型数量 (Q={q1,q2,…,qL})。很多情况下每个Rs的原型数量相等,因此q1=q2=…=qL。
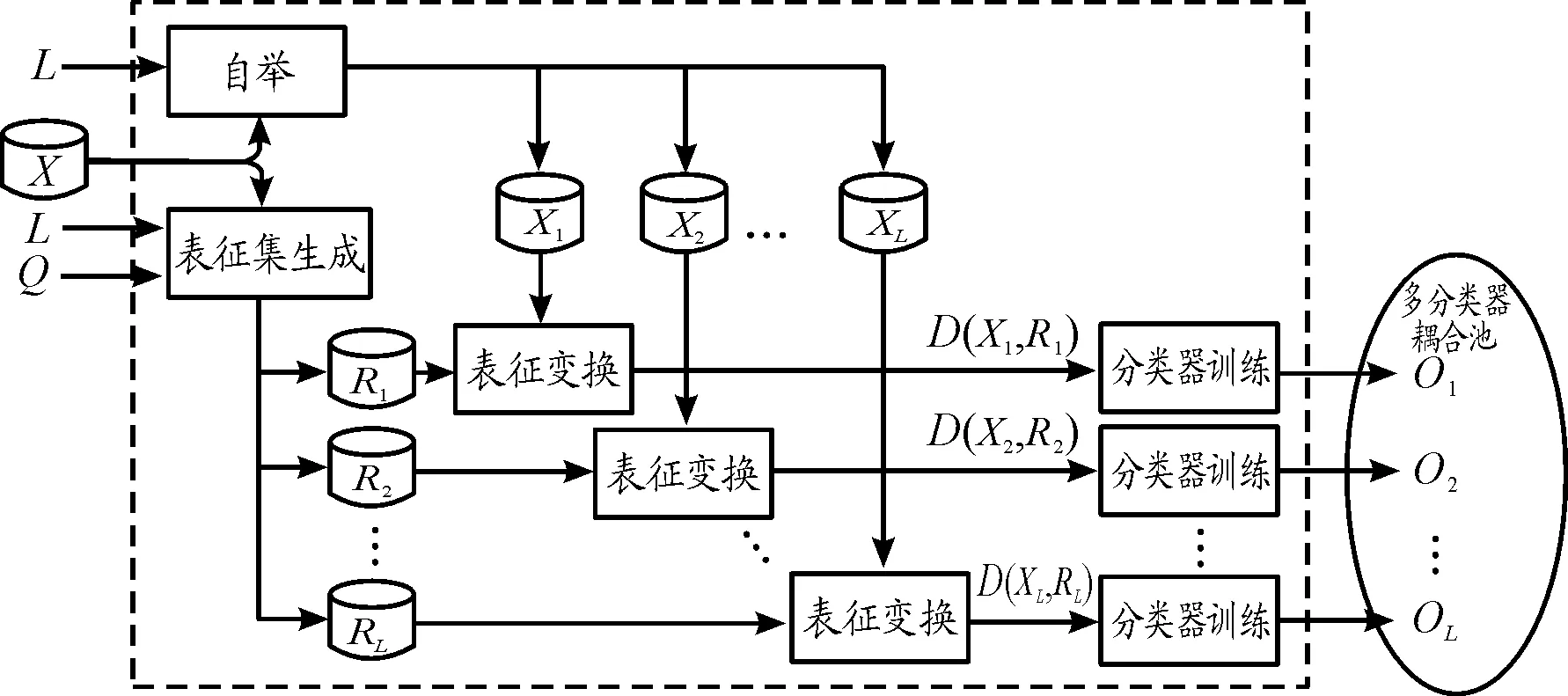
图1 训练阶段示意图
每个表征变换模块的输入集为训练子集Xs和表征集Rs,其中s= 1,2,…,L。鉴于所提方法是一个多分类器系统,多样性非常重要[14],因此,这两个输入集应包含不同文档。在这个前提下,自举模块和表征集生成模块能够创建出具有多样性的多分类器融合池。
自举模块利用采样替换生成训练集的不同子集。该模块将原始训练集X作为输入,并生成L个训练子集(X1,X2,…,XL)作为输出。所有子集的大小均与原始训练集相同(N),一些文档多次出现。
表征集生成模块使用任意原型选择算法来生成不同的训练子集。该模块将原始训练集X作为输入,并生成L个表征集(R1,R2,…,RL) 作为输出。每个表征集包含qs个文档(qs≤N)。有必要指出,对于一个给定的训练集,确定性原型选择算法总是生成同样的子集;为了得到L个不同的表征集,可以使用L种不同的确定性原型选择算法,或使用非确定性原型选择算法(如随机选择)。
此处,提出的方法生成2×L个训练集的子集。其中前一半子集(X1,X2,…,XL)来自于自举法,每个子集包含N个文档;后一半子集 (R1,R2,…,RL)来自于原型选择法。每个表征变换模块接收Xs和Rs,以生成一个相异性矩阵D(Xs,Rs):

(3)
式中:每个函数d(xi,pk)生成文档xi的第k个特征。通过这种方式,每个相异性矩阵D(Xs,Rs)可视为一个变换集,其中包含以qs个特征(矩阵的列)表征的N个文档(矩阵的行)。
训练阶段的输出为L个受训后的分类器(o1,o2,…,oL),其中使用相异性矩阵D(Xs,Rs)对每个分类器os进行了训练。
2.3 测试阶段
所提方法的测试阶段(图2)包含3个模块:表征变换、分类器和融合器。该阶段的输入参数包括1个查询文档(yj∈Y),L个表征集(R1,R2,…,RL)和L个训练后的分类器(o1,o2,…,oL)。

图2 测试阶段示意图
表征变换模块将单个文档yj∈Y和一个表征集RL作为输入,并生成一个变换后的文档如下:
D(yj,Rs)=[d(yj,p1),d(yj,p2),…,d(yj,pqs)]T
(4)
由此,特征向量的每个元素代表着查询文档yj和表征集Rs中的一个文档pk之间的距离。 然后,将每个变换文档D(yj,Rs)提交至各自的分类器os,后者输出classos(yj)。接着,通过融合器模块对L个分类器的每个输出classos(yj)进行合并,给出最终应答class(yj)。合并方法主要分为3种[15]:
1) 类标签融合。即每个分类器响应一个分类,其应答作为投票使用,例如一致表决、简单多数票,或多数票[15];
连续四年,青辰都是滑翔大赛的冠军。也即是说,自从他十二岁生日那天第一次参加滑翔大赛,便再没有人能从他手中夺走冠军的勋章。他似乎对天空有着超过常人的敏锐感知,无论是对风向和风速的判断利用,还是悬空时出色的平衡掌控能力,都让他能够远远领先对手。而这一次,他更是对滑翔翼进行了改良,使它的结构更加接近翅膀的流线型,以便在滑翔时获得更大的升力。
2) 支持函数融合。首先,每个分类器给出每个分类的概率;然后,通过例如后验概率等方式对这些响应进行合并;
3) 可训练融合器。首先,使用所有分类器的应答,对一个分类器进行训练,然后基于验证集或统计方法给出合并后的答案。本文使用多数票[15]作为类标签融合方法。该方法优点是简单高效,既不要求概率计算,也不需要基于验证集对输出进行训练,且性能优于单个分类器。
3 实验分析
本文在7个数据库上使用10折分层交叉验证进行实验,所用数据库的重要属性如表1所示。分类器采用带线性核的SVM分类器,分类器池大小(L)在10到100之间变化(步长为10)。

表1 数据库重要属性
3.1 评价方法
使用微观平均F1得分(micro-F1)和宏观平均F1得分(macro-F1)作为有效性评估指标。F1得分计算方式如下:

(5)
式中:Recall表示召回率,Precision表示精度。但对于micro-F1和macro-F1,Recall和Precision的定义是不同的。对于micro-F1:

(6)
(7)
而macro-F1的Recall和Precision则定义为
(8)
(9)
其中:C表示类别数量,TPk表示正确将文档分入类别ck的数量,FNk表示将文档错误归入ck之外的其他类别的数量,FPk表示将文档错误归入类别ck的数量。
3.2 实验1
本文通过实验1主要解决以下问题:表征集生成模块中应该使用哪种原型选择算法?所提方法中表征集的最优大小是多少?为此,本节将评价所提方法对原型选择和表征集大小这两个参数的敏感性。选择来自5个不同领域(科学、情感、医学、TREC1和Web)的3个数据库(CSTR、ACM和WAP)进行敏感性分析。
对于第一个问题,确定表征集生成模块的原型选择算法。本文应用了3类不同的原型选择算法:凝聚式、编辑式和混合式。为这3类算法分别选择3个原型算法,其中凝聚式采用CNN;编辑式采用kNN;混合式采用ATISA2[16]。另外,还考虑了随机原型选择算法,因为有关相异性表征的研究表明[12],利用随机原型选择得出的表征集能够实现较好的结果。因此,本文评估了两种配置:确定性原型选择算法(PSA),以及非确定性原型选择算法组合,也即随机原型选择(RPS)。
表2分别给出了使用两种度量(余弦相似度和欧氏距离),分类器组合得出的结果。其中,最好结果用粗体字表示,括号中的数据为标准偏差。“PSA”列给出了使用CNN、kNN、和ATISA2算法选出原型后,并对每个分类器进行训练的结果。“RPS”列给出了使用随机原型选择时,3个分类器合并后的结果。为了公平比较,RPS选出的原型数量与每个PSA得出的相等。根据置信度95%的t检验统计,PSA和RPS的性能相似。由于原型选择算法速度慢于随机原型选择,因此本文选用了后者。

表2 使用两种度量得出的结果
对于第2个问题,为了评价表征集的大小,本文考虑性能(micro-F1)和多样性。与准确率相关的多样性度量中,多样性要求的计算量较少。多样性度量的计算方式如下:

(10)
式中:oa和ob为两个分类器,Oab表示给定分类器(a对应oa,b对应ob)对测试集Y中的文档yj的分类结果,正确为1,错误为0。总之,多样性度量是计算两个分类器对同一个文档的误分类概率。
图3给出了使用配对t检验的Q的3个数值。其中,符号由配对t检验定义为:p-value≤0.01∴(>>)/(<<),p-value≤0.05∴(>)/(<)和p-value > 0.05∴(=)。最优配置显示为灰色。从多样性角度考虑,对于3个数据库中的2个,10%是最优值;从性能角度考虑,对于所有数据库,30%均是最优值。然而,10%和30%分别在性能和多样性方面存在缺陷。因此,为了在性能和多样性之间找到最好的平衡,本文将该参数定义为训练集的20%。也就是说,使用训练集的20%组成表征集,Q=N×0.2,其中N为训练集大小。

图3 多样性和性能与Q值关系
3.3 实验2
本文所提方法与文献[11]提出的改进词袋法、文献[10]提出的多分类器融合和文献[9]的最大熵模型进行比较。对于词袋法[11],在生成分类器池之前使用ALOFT算法进行特征选择。ALOFT是专门针对文本分类设计的特征选择算法,能够显著减少变量数,且不会造成性能下降。对于最大熵模型[9],则不需要使用特征选择,因为其会为每个分类器生成降维后的若干个特征子空间。在本文提出的方法中,使用小于训练集的表征集来实现约简,因为最终维数等于表征集中的文档数量。
表3给出了4种方法(本文方法和文献[9-11])的最终结果。词袋法的性能均会受到特征选择算法的影响,根据表3最后一行的结果,文献[11]的改进词袋法是性能第二好的方法。macro-F1和micro-F1的临界差值如图4所示。
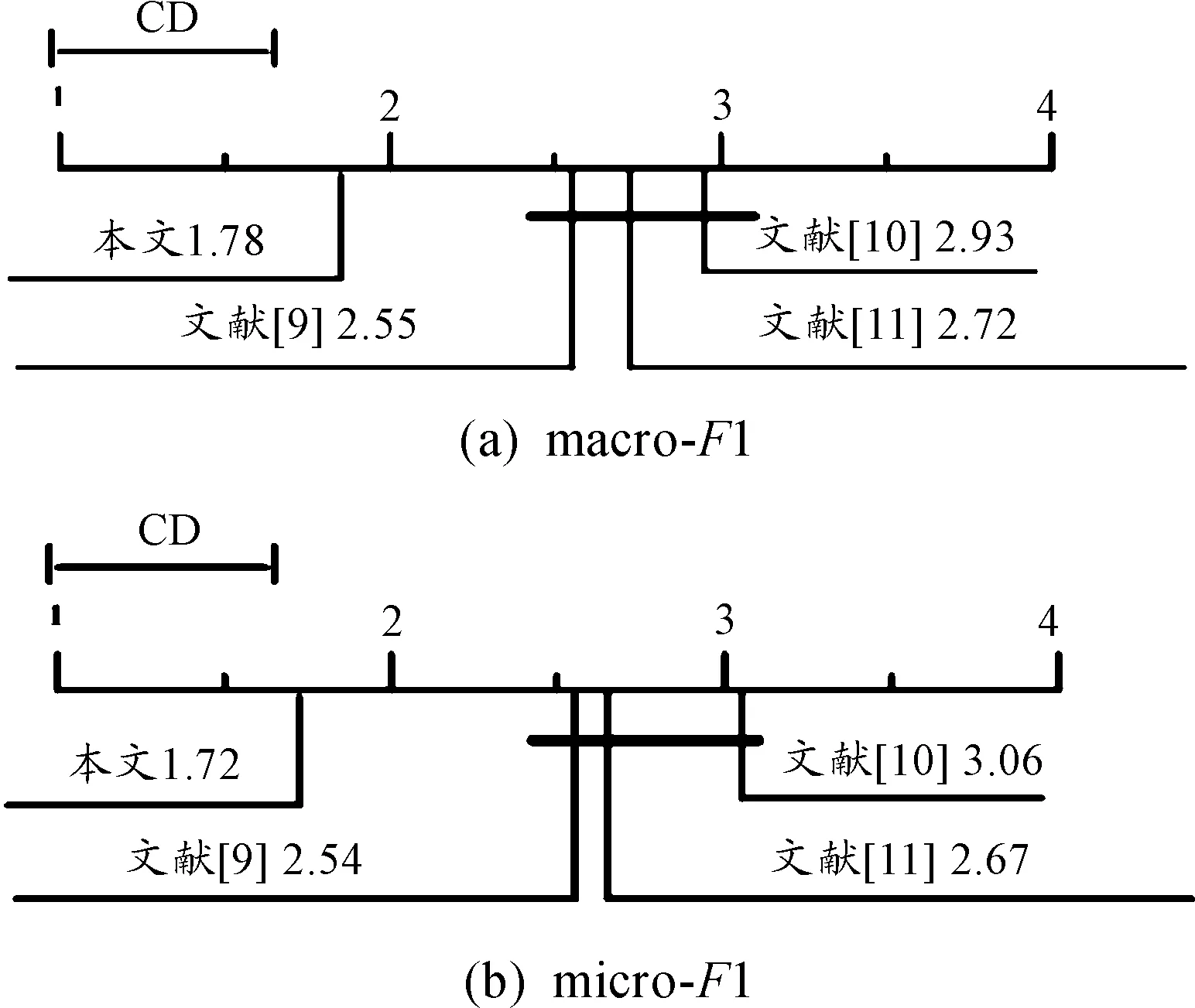
图4 各方法的临界差值
可以看出,所提方法在两个度量中均得到最低均值,性能优于其他方法。与本文方法不同,文献[10]多分类器融合的性能取决于表征变换后得到的特征数量(Q)。由于特征数量由训练集文档数量决定(Q=N×0.2),因此文献[10]的结果与N存在直接关系。当文档数量较少(N<2 000)时文献[10]方法得到最差结果,而在文档数量较多(N>6 000)时则得到最优结果。在原始特征数量大于文档数量的数据库中,文献[10]方法的性能尤其出色。
性能与特征约简率之间的关系如图5所示,图5中评价了7个数据库和4种方法。当约简率低于80%时,文献[10]方法性能较好。ALOFT自动定义特征数量,因此,在所有案例中约简率均等于或高于85%,不受所使用的特征评价函数的影响。可以看出,本文方法出现31次,其后依次为文献[11]改进词袋25次,文献[9]的最大熵模型23次,文献[10]的多分类器融合方法12次。

图5 约简百分比与micro-F1关系
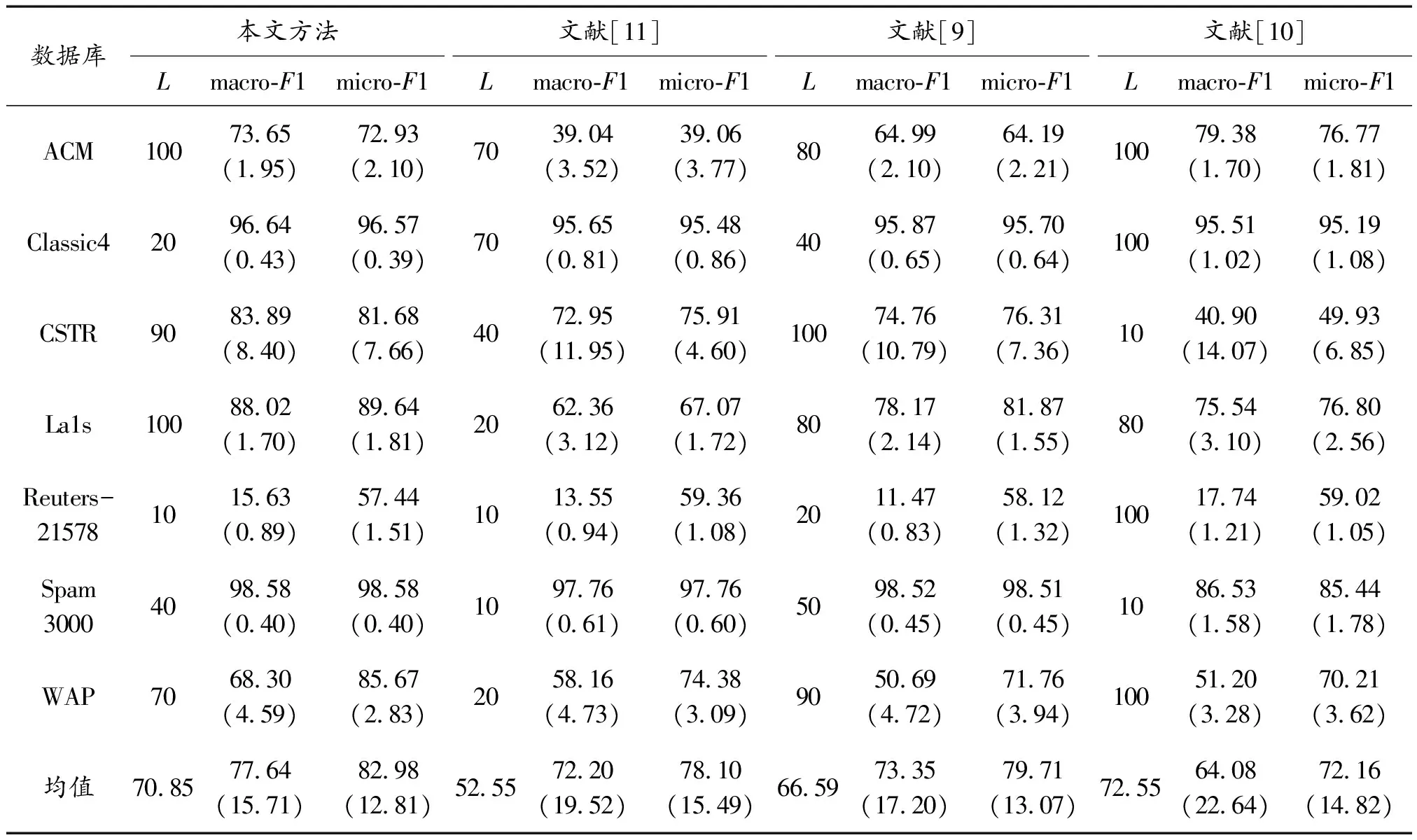
表3 各方法的综合评价结果
4 结论
本文针对词袋法(BoW)的一些缺陷,提出了一个适用性更广的解决方法,所提方法利用相异性表征解决了词袋法的稀疏性和高维性问题。其中,每个特征表征为两个文档之间的距离,该距离仅在两个文档相等时为0,由此减少了稀疏性。由于特征数量等于表征集中的原型数量,高维性同样得到缩减。另外,分类器池的策略有利于创建多样化的多分类器融合池。验证了所提方法具有较好的整体准确率和稳定性。未来作者将对每个分类器的最优表征集进行优化搜索,以获得最优特征。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
计算机系统应用(2021年2期)2021-02-23
小资CHIC!ELEGANCE(2021年45期)2021-01-11
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
英美文学研究论丛(2018年2期)2018-08-27
小天使·二年级语数英综合(2017年12期)2017-12-05
剑南文学(2016年14期)2016-08-22
