
基于协同过滤算法的高校学习资源智能推荐平台研究
2020-01-08 12:14郝杰
宿州教育学院学报 2019年6期
郝 杰
(江苏旅游职业学院 江苏·扬州 225131)
当今社会正处于一个信息爆炸的时代,随着互联网技术的进一步普及,人们能够随时随地在信息的海洋中畅游。信息的数量已不再成为问题,如何能够方便快捷地获取有效信息,乃至得到个性化的信息服务,日益成为各行各业研究的重点,随着计算机技术的不断深入,各类推荐算法应运而生。
近年来,随着国家大力发展高等教育,高校在智慧校园建设方面的投入越来越多,顺应 “互联网+”的时代要求,高校的学习资源平台已经成为促进在校生学习专业知识技能的重要工具。传统的学习资源平台一般对学习资源有两种呈现方式:一是资源分类索引的方式,即采用类似门户网站的资源库界面,学习图书馆资源管理的模式,将学习资源按预设的分类标准进行分组,学习者需要按一定的层级目录查询内容。二是搜索引擎辅助的方式,即采用搜索引擎对学习者给出的关键字进行检索,匹配出目标内容推荐给用户。以上两种方式都较为成熟,但也存在着一些问题,归纳起来主要有:
首先资源获取效率不高。用户获取资源有赖于系统对标签或关键字的认定,对资源内容的优劣无法判定,学习者易获得无效资源或低质资源;其次资源的检索,受用户关键字选取的准确性和自身知识的有限性影响,海量的信息资源无法进入学习者视野。再次个性化程度较低。资源的组织方式严重依赖于资源的管理者,系统无法根据用户的个人学习状况或学习偏好给出推荐。
综上,推荐算法在高校学习资源平台的应用必将成为趋势。本文构建了采用协同过滤算法优化学习资源平台,使其能够主动为广大学习者提供个性化推荐服务。
一、协同过滤算法
协同过滤算法(collaborative filtering)是一种产生较早,应用相对较为广泛的推荐算法。通过对用户历史行为的数据挖掘,进行用户特征分析,归纳出相似性较高的用户集合,从其偏好中计算得出推荐内容的集合。协同过滤算法主要分为两类,分别是基于用户的协同过滤算法 (user-based collaborative filtering),和基于物品的协同过滤算法 (itembased collaborative filtering)。
(一)基于用户协同过滤算法
基于用户的协同过滤算法,是建立在“偏好接近的不同用户对同一资源的评价接近”这一基本思路上的。是通过分析用户的历史操作,以相近偏好作为评价标准划分出相似的邻近用户集合,进一步计算出集合中与目标用户相似度最高的邻近用户,并将其偏好内容推荐给目标用户。如图1所示,对图中用户的历史操作进行分析后,可以看出A 用户与目标用户相似度最高,为最邻近用户,故将学习资源“数据结构”推荐给目标用户。
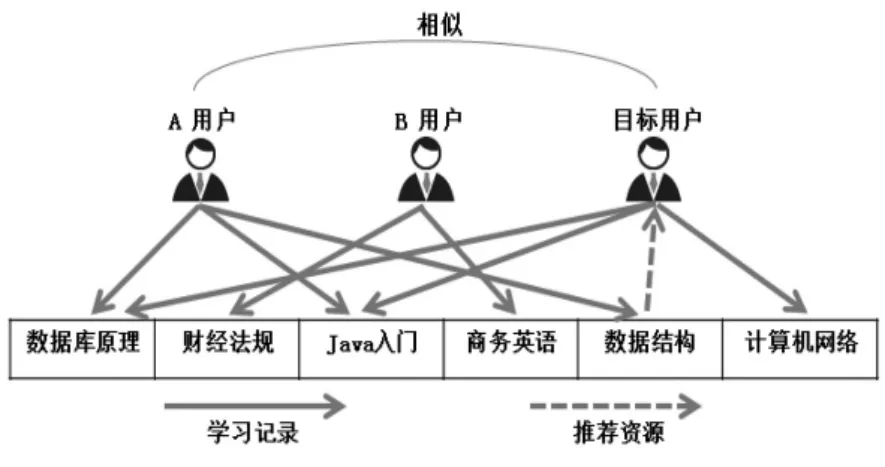
图1:基于用户的协同过滤算法示意图
(二)基于物品的协同过滤算法
基于物品的协同过滤算法,其基本原理和基于用户的协同过滤算法类似,区别在于基于物品的协同过滤算法是从资源的角度寻找推荐资源,是建立在“同一个用户所选择的不同资源之间具有相似特征”这一基本思路上的。如图2所示,凡是选择了“微课2”资源的用户均同样选择了“微课4”,则认为这两个资源具有较高相似度。此时,当目标用户选择了“微课2”资源后,可将“微课4”资源推荐给他。
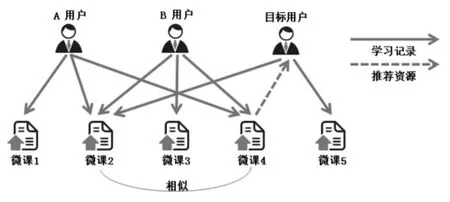
图2:基于物品的协同过滤算法示意图
两种协同过滤算法各有其优缺点,但考虑到高校学习资源智能推荐平台面对的用户群体相对固定,结构单一,用户数据维护较为简单,且多以专业背景聚合,推荐平台更需要解决的是多样性不足的问题,以开拓用户的学习视野,故而偏向以基于用户的协同过滤算法作为平台推荐算法的基础。
二、推荐算法的应用
推荐算法的核心在于构建具有较强相似性的邻近用户集合。为此,首先要做的就是得出每个用户对资源评价的矩阵。
(一)构建资源评价矩阵
用户对资源的评分可以根据平台系统的需要设计评分项目及其所占权重。由于用户在使用资源过程中,对资源的评价存在惰性和随意性,为进一步提高学习资源智能推荐平台所推荐资源的有效性,在构建评价矩阵过程中,设计评分项目既需要有显式评分项目,也需要设置足够的隐式评分项目,以便更加准确的建立用户偏好档案。具体评分项目及权重构成如表1。

表1:用户—资源评分项目表
我们假设平台注册用户集合为U={u1,u2,……,um},平台拥有的资源集合为 R={r1,r2,……,rn},则全部用户对资源的历史评分构成的 “用户—资源”评分矩阵为P,其中Pmn 为用户um 对资源rn 的评分,如图3。

图3:“用户—资源”评分矩阵
(二)构建邻近用户集合
得到“用户—资源”评分矩阵后,即可根据其中的分值构建邻近用户集合。我们以假定的5个用户对2 个资源的评分为例找寻特征相似用户,截取用户历史操作评分表如表2。
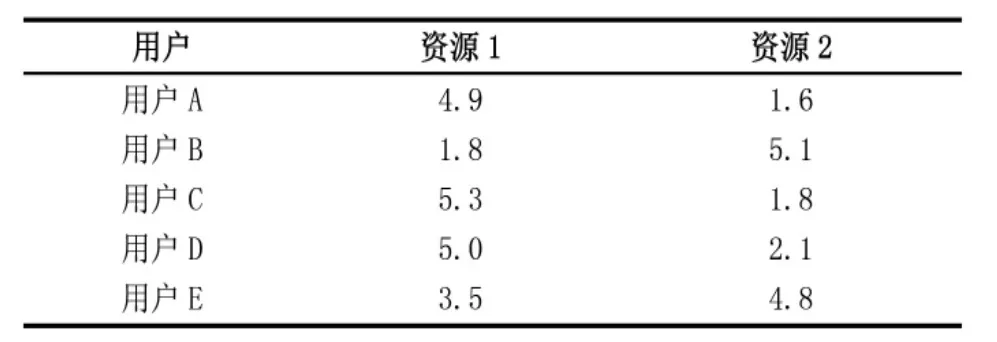
表2:“用户—资源评分表”
将评分数据放入二维坐标内,得到散点图。在图4中可以明显看出用户A、C、D相似性较高。

图4:“用户—资源评分”散点图
根据以上内容,为了能够进一步量化复杂状态下多个用户对多个资源的评价的相似度,我们采用皮尔逊相似度计算方法,其计算公式如下:
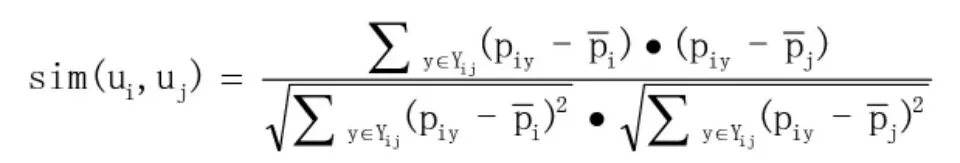
其中Ui表示指定用户的评分向量,即ui={pi1,pi2,……,pin}。Yi表示用户Ui评分制非空的项目集合。i表示用户Ui所有评分的平均值。计算得出的皮尔逊相关性系数,通常认为取值在0.0-0.2为极弱相关或无相关,取值在0.8-1.0为极强相关,取值越偏向1,则正相关性越强。
完成目标用户与其他用户之间的相似度计算之后,可以采用设置相似度系数阈值或者取Top-n最邻近用户等方式,最终形成目标用户的最邻近用户集合。
(三)构建推荐项目列表
推荐算法的最终目的是向目标用户推荐其可能喜好的资源,资源的来源为最邻近用户集合中已评分资源得分均值较高、且为目标用户尚未评分的资源。我们根据以下公式求得最邻近用户对项目评分的均值。
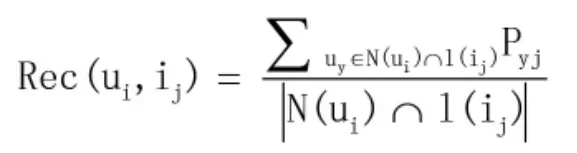
三、学习资源智能推荐平台架构
(一)平台系统模型
本文提出的高校学习资源智能推荐平台如图5所示,主要由资源档案管理模块、用户档案管理模块、网页管理模块、智能推荐模块等方面构成。其中,用户档案管理模块需在记录用户主动提供的注册信息的基础上,记录和整理用户的行为数据,形成完整的用户档案。智能推荐模块匹配资源档案和用户档案中的数据,建立预测评分,并使用协同过滤算法生成推荐列表后提交至网页管理模块。
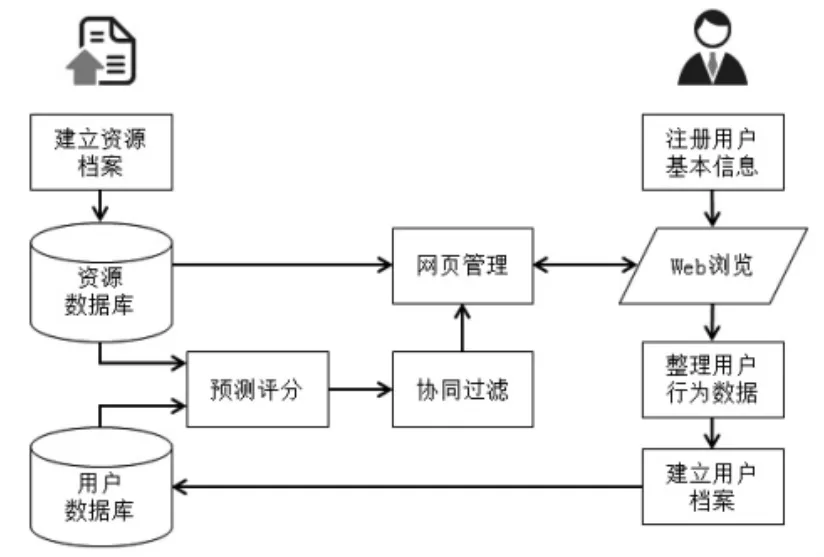
图5:高校学习资源智能推荐平台架构
(二)平台推荐策略的运用
协同过滤算法的使用,提高了资源推荐的有效性,能够为平台用户提供动态更新的个性化推荐服务,但其不能作为整个平台的唯一推荐策略。根据新老用户的不同特性,根据平台不同板块的功能划分,可以采用多种策略分工组合的方式。
平台首页:可以对于新上传资源进行广告式推荐;根据用户专业、年级等基本信息,排序符合基本特征的资源进行直接推荐;根据平台限时活动进行资源推荐等。
商品搜索页:采用关键字匹配;相同关键字优先级排序策略等。
猜你喜欢:用户点击量及时序综合排序推荐;协同过滤算法推荐。
结 语
协同过滤算法的应用非常广泛,但其本身也存在冷启动问题、稀疏性问题、可拓展新问题等不足,可以通过调整预测评分计算的相应指标或改进算法加以优化。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
湘潮(上半月)(2019年3期)2019-05-22
汽车观察(2019年2期)2019-03-15
中国卫生(2016年5期)2016-11-12
成人教育(2015年7期)2015-12-21
