
东莞轨道交通2 号线站点聚类分析1
2020-01-08 03:29崔志涛
惠州学院学报 2019年6期
崔志涛,蹇 柯,方 勇
(东莞理工学院城市学院 计算机与信息学院,广东 东莞 523419)
2016年5月27日东莞轨道交通2号线正式投入运营,这是TOD(Transit-Oriented Development,公共交通导向城市发展)理论在东莞实践的开始.TOD理论中以居住区、工作场所、零售业中心置于公共交通沿线的城市空间布局,辅之于公共交通良好步行环境设计,鼓励市民优先选择公共交通出行[1],从而缓解大中城市的交通出行压力.TOD 引导下的土地使用模式以交通站点为核心,强调站点周边的土地使用和优良出行环境[2].因此,轨道交通2 号线沿线及站点周边将是未来东莞城市建设的重要地区.
对于站点的分类,日本的东京、大阪等城市根据站点的区位特征将轨道交通站点分为都市圈中心站、都市圈郊外站[3].美国旧金山、洛杉矶使用判别分析的方法将站点类型分为6类[3].我国住房与城乡建设部2015年11月公布的《城乡轨道沿线地区规划设计导则》(以下简称导则)中,明确鼓励建立多功能、立体化轨道站点综合开发模式,导则按照站点服务范围和服务水平将站点分为6类.在文献[4]、[5]中致力于轨道交通评价体系指标的建立,文献[6]-[8]采用了统计分析中的数据处理技术对站点进行了分类.导则与文献[3]-[8]中对站点分类的方法体系可以总结为定性分类的方法与定量分类的方法.东莞是一个不断发展中的城市,在城市地域不变的情况下,城市人口和站点周边环境在不断的发生变化,使用定性分析的方法对站点进行分类,是对站点的未来发展的定位,缺乏对站点现状的认识.而对站点现状指标量化之后,采用数据分析方法得出的分类结果是对站点现状的客观认识和归纳.文章结合《导则》规划导引目标,选取了东莞轨道交通2 号线站点的9 个指标,采用了聚类分析的方法对站点进行了分类,并结合实地考查对各个类别的特征进行了归纳.
1 系统聚类算法原理描述
系统聚类算法首先要建立样品的分类指标数据库,N 个样品的m 个分类指标数据组成了包含N 个点的m 维空间的一个子集.之后进行分类,N 个初始样品独自成类,由定义好的样本距离与类间距离对类别进行逐次合并,类别数量逐次减一,直至将N 个样品合并为一类为止.样本间距的定义有闵氏距离、马氏距离等;类间距离定义有最短距离、最长距离、中间距离等8 种[9].对个案的分类称为Q 型聚类,对变量的分类称为R 型聚类.
2 站点数据指标的描述
出入口数量:《地铁设计规范》中规定应根据吸引与疏散客流的要求设置,不能少于2个.同时受到车站规模、埋深、平面布置、地形地貌、道路、环境、城市规划及车站远期预测高峰小时分向客流量计算的影响[10].
站点与市中心的距离:站点和城市中心耦合程度的大小[11].文中选择了东莞南城的环球经贸大厦作为市中心.
站点间的平均间距:受到城市规划、道路交通设计优化的影响[12].
某天进出站乘客数:站点客流量的大小.
是否换乘:是否交通枢纽车站[13].2号线的端点站、鸿福路站、西平站为换乘车站.
站点接驳公交线路:站点接驳公交线路的多少,体现轨道交通与城市公交系统的衔接程度[14].由《导则》的引导方向,文中选取了站点500 米范围内的公交站点线路总数.
步行环境:以站点为圆心的500 米范围内的道路平整程度、站点卫生情况、站点的开阔程度为准则[15],下桥站为相对最差等级,赋值为4,鸿福路站点为相对最优程度,赋值为1.其余站点对比赋值.
站点周边建筑密度:以站点为中心的500 米范围内的建筑覆盖率,体现站点周边土地开发强度的大小[16].
站点周边建筑容积率:站点500 米范围内的建筑容积率指标[16].
3 站点数据指标的标准化
为了剔除量纲在聚类过程中的影响,进行聚类之前需要对站点数据进行标准化处理(见表1).

为第j 列样本数据的标准差:


表1 站点标准化数据
4 站点数据的因子分析
对站点的标准化数据进行因子分析(表2-表4,图1),KMO 和Bartlett 的检验结果,KMO 值为0.589,Bartlett 检验概率为0.039<0.05,适合做因子分析.结合图1因子分析碎石图与表2因子贡献率表,前3个因子的特征值大于1,累计贡献率为75.397%,提取前3个因子作为主因子.由表3 的旋转因子载荷矩阵可以看到建筑密度、建筑容积率在因子1上的得分较高,所以因子1可以命名为土地开发强度因子;是否换乘车站、某日进出站客流量、站点步行环境在因子2 上的得分较高,所以因子2可以命名为站点枢纽因子;站点与市中心距离、出口数量、站点间的平均间距在因子3上取值较大,因此,因子3可以命名为站点耦合因子.

表2 因子贡献率表
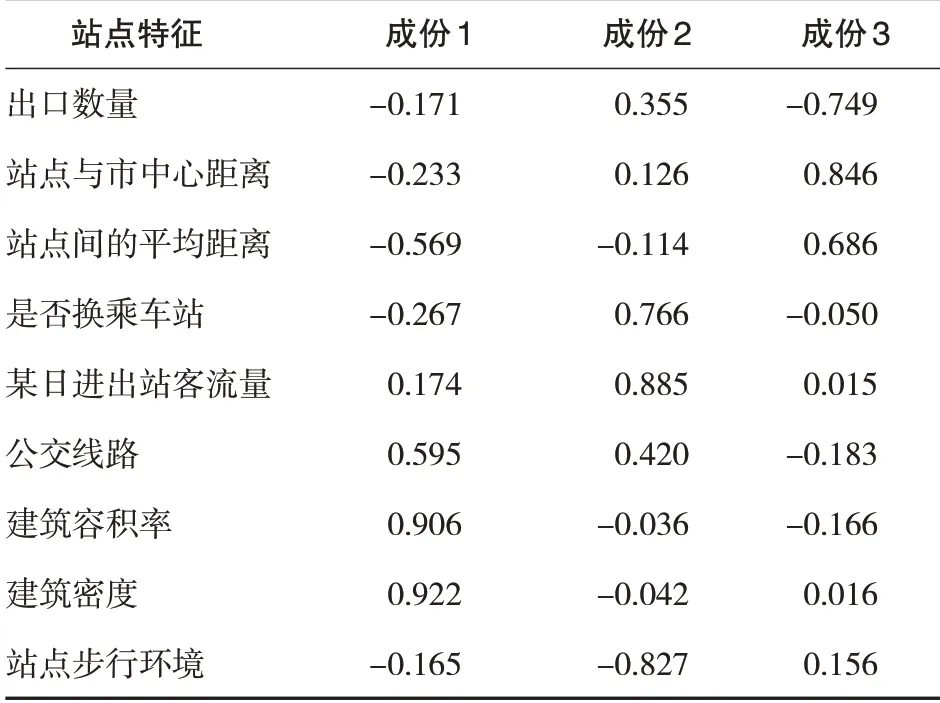
表3 旋转因子载荷表

表4 因子得分数据
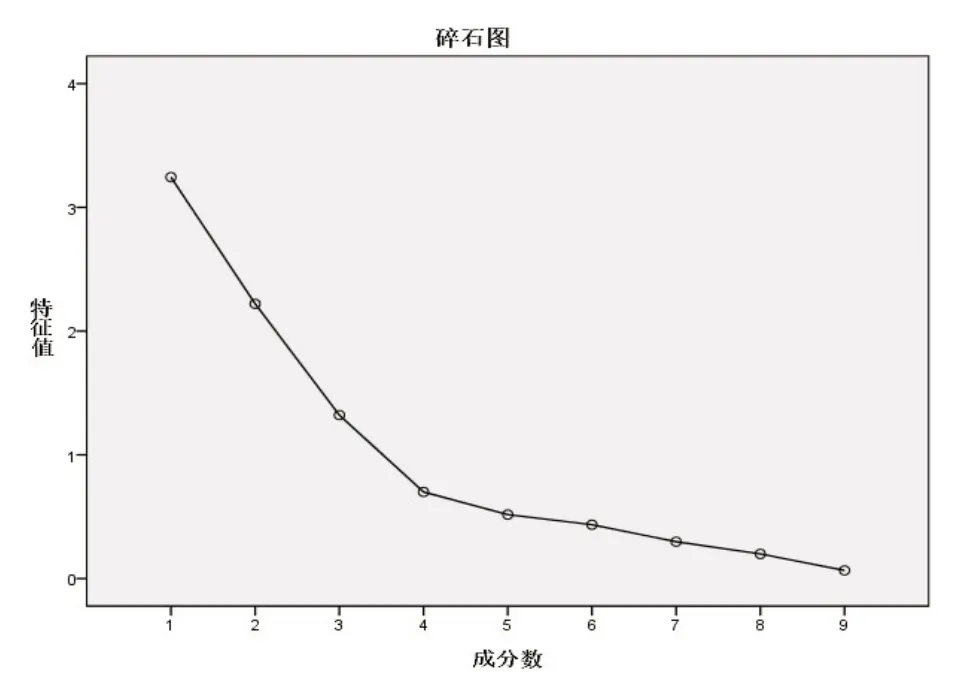
图1 因子分析碎石图
5 站点的系统分类
由系统聚类法使用站点因子得分数据(表5)对站点进行分类,得到站点分类图(图2).

图2 站点分类树状图
6 站点的K-均值聚类
K-均值聚类需要预先设定聚类数目,为了得到合适的分类数目,对站点分类过程中的聚合系数进行分析(图3).
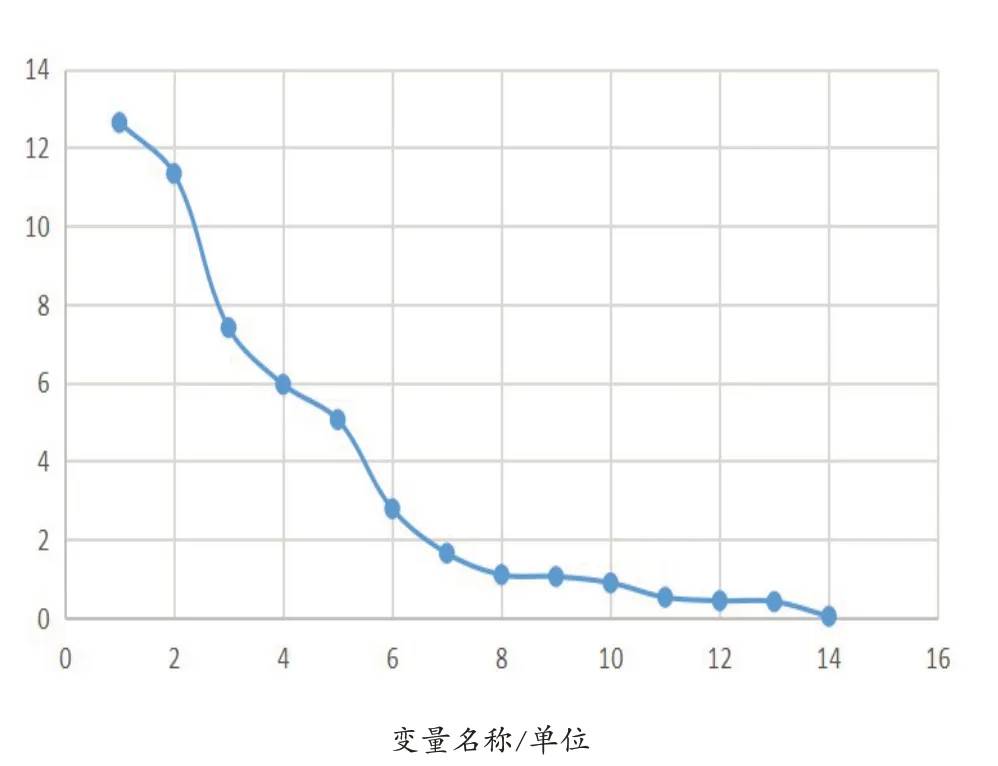
图3 聚合系数变化图
由聚合系数随分类数的变化曲线图[17],可以认为对站点分为8~10 类之间是合适的.K-均值聚类结果(表5):

表5 K-均值聚类成员表
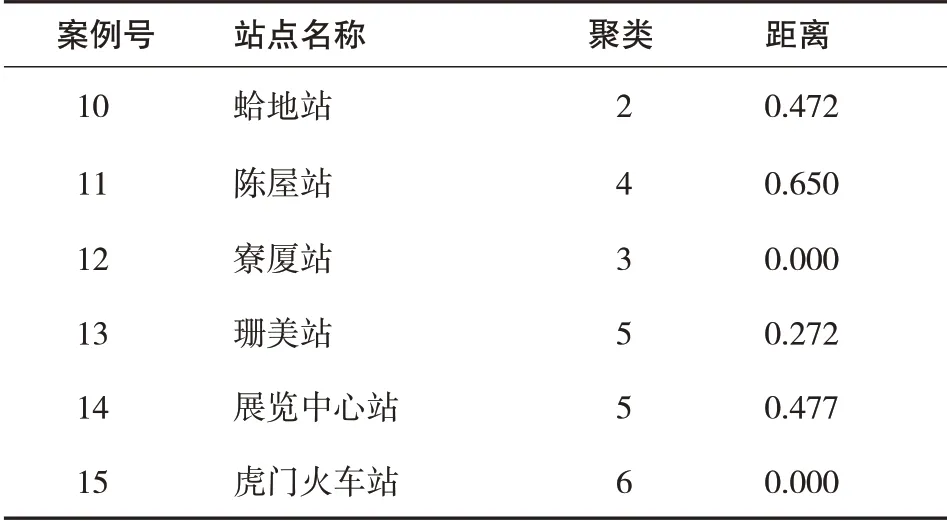
(续表5)
结合站点的实际考查,对分类结果描述如下:
类1{东莞火车站}:同时为广深铁路站点,站点客流量大,站点周边土地开发强度一般.
类2{茶山站、蛤地站}:毗邻站点皆为换乘车站;
类3{寮厦站}距离市中心较远,郊区站点,站点周边土地开发强度非常低;
类4{下桥站、西平站、陈屋站}站点周边土地开发强度较低;
类5{榴花公园站、珊美站、展览中心站}站点周边都有较大型的公共活动中心;
类6{虎门火车站}枢纽车站,同时为广深港高铁站点,未来接驳深圳地铁站点,站点规模大,但站点周边土地开发强度非常小;
类7{天宝站、东城站、旗峰公园站}:城区3 个相邻站点,站点规模相当,站点周边建筑密度较大;
类8{鸿福路站}:市区中心枢纽车站,规模最大,毗邻市政府,站点周边商圈、岗位、居住[3]密集,未来市内轨道交通换乘的枢纽车站.
7 结语
文章选取了东莞轨道交通2 号线站点的9 个分类指标,并给出了指标选取的依据.从量化的角度对站点进行了分类.为了克服量纲的差别对数据进行了标准化,并使用因子分析对数据进行了降维,结合聚类树状图与聚合系数变化图明确了分类的数目,得出了站点的分类结果,最后描述了各类站点的特点.
猜你喜欢
现代城市轨道交通(2020年1期)2020-02-14
铁道通信信号(2020年11期)2020-02-07
模具制造(2020年12期)2020-02-06
模具制造(2020年12期)2020-02-06
文化遗产(2017年2期)2017-04-22
中国工程咨询(2012年4期)2012-02-14
中国工程咨询(2012年5期)2012-02-13
中国工程咨询(2012年1期)2012-02-13
中国工程咨询(2012年3期)2012-02-13
凤凰周刊(2009年18期)2009-06-14
