
基于Tensorflow对卷积神经网络的优化研究
2020-01-06 02:15郭敏钢
计算机工程与应用 2020年1期
郭敏钢,宫 鹤
1.吉林农业大学 信息技术学院,长春130118
2.吉林农业大学 吉林省智能环境工程研究中心,长春130118
3.吉林农业大学 吉林省农业物联网科技协同创新中心,长春130118
1 引言
随着深度学习[1]的不断发展,目前的机器学习框架也是层出叠见,例如:Tensorflow[2]、Theano、Keras、Caffe、Torch、DeepLearning4J 等等。首选Tensorflow 作为研究机器学习框架的原因,是其在对比同类机器学习框架的可用性、灵活性、效率、支持等方面都有着优异的表现。
卷积神经网络[3-5]作为一种广泛的深度学习方法,在Google 研发的Alphago[6]以及图像分类、视频及声音识别[7]、目标检测[8-9]、医学研究[10]等方面都取得了显著的效果和极高的效率。
卷积神经网络的优秀性能表现不仅需要像Tensorflow这样的良好的深度学习框架支撑,还要依赖较为出色的计算设备支撑。随着深度学习的不断发展,卷积神经网络计算模型的复杂度也随之增加,使得模型训练的难度及耗时呈指数倍增长,单CPU 或单GPU 设备甚至已经无法解决复杂网络模型的训练耗时问题。为此,本文提出了一种异构式CPU+GPU的协同计算模型,根据CPU逻辑运算强及GPU 费逻辑运算强的特点,将网络模型计算任务按模块分配到CPU 与GPU 设备上运行,通过耗时对比分析得出异构式CPU+GPU[11-12]的协同计算模型要明显优于单CPU或单GPU计算模型。有效地提高了卷积神经网络的训练速度。
激活函数在卷积神经网络中扮演着重要的角色,其作用是将神经元的输入映射到输出端,常见的激活函数包括Sigmoid、TanHyperbolic(Tanh)、ReLU、PReLU、Softplus、ELU、Softsign、Swish等。其中,早期的Sigmoid激活函数、TanHyperbolic(Tanh)激活函数、Softsign激活函数均为S型非线性饱和函数,在模型训练中极易造成梯度消失现象。Krizhevsky 等人[4]提出的ReLU 激活函数由于在正向区间为线性函数,加快了模型训练的收敛速度的同时也解决了Softsign、TanHyperbolic(Tanh)、Softsign 激活函数的梯度消失问题,但由于ReLU 激活函数在x <0 时梯度为0,这样就导致负的梯度在这个ReLU被置零,容易造成“坏死”现象。在此之后,一些研究者相继提出了ELU、PReLU、Swish等激活函数用来降低“坏死”现象出现的概率,但与此同时也产生了相应的梯度消失和收敛速度过慢的现象。
本文提出了一种新的激活函数ReLU-Swish。将ReLU激活函数和Swish激活函数的正负x 半轴进行分段组合,使Swish激活函数x 正半轴成为线性函数。在CIFAR-10 和MNIST 数据集上的实验结果表明,ReLUSwish激活函数的准确率及收敛速度上相比Swish激活函数[13]表现更优秀,有效地缓解了“坏死”现象以及收敛速度过慢的问题,起到了优化卷积神经网络的作用。
2 Tensorflow
2.1 Tensorflow架构与原理
Tensorflow 基本系统架构如图1 所示,自下而上分别为设备管理和通信层、API 接口、计算图层、应用层。通信层主要负责设备管理及通讯管理,主要负责卷积神经网络中算法的计算和操作,可以实现CPU 与GPU 异构的特性,并依赖gRPC协议实现设备间的数据更新及传输;API 接口是对Tensorflow 各功能模块的接口进行封装,使其他平台便于调用;计算图层用于构建分布式子图,切割计算任务分别运行在不同的设备(CPU、GPU)上;应用层通过API接口调用Tensorflow各种功能并且实现相关的设计和应用。
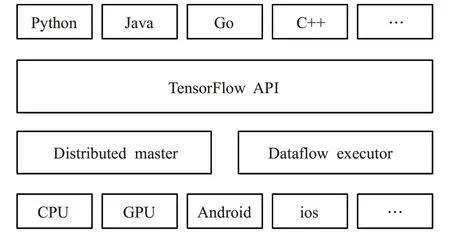
图1 Tensorflow基本系统架构图
2.2 Tensorflow的优势
Tnsorflow是谷歌基于DistBelief研发的第二代人工智能学习系统,2017 年2 月,TensorFlow 1.0 版正式发布,其当年的提交数目就已超过2.1万,其中还有部分外部贡献者。同时,TensorFlow是跨平台的,它几乎可以运行在所有平台上,比如GPU、CPU、移动和嵌入式平台,甚至是张量处理单元(Tensor Processing Units,TPUs)。首选Tensorflow作为研究机器学习框架的原因,是其在对比同类机器学习框架的诸多方面都有着优异的表现。如表1所示为常见常用的4个机器学习开源框架在GitHub上各类属性的评分及对比。

表1 主流深度学习框架评分
其优势在于以下几点。
(1)可用性:Tensorflow 相较于MXNet[14]、Caffe[15]、Theano[16]等框架工作流程相对容易,可直接写Python/C++程序,节省了大量的编译时间且能够更快的测试相应的迭代想法;接口稳定,兼容性较好。
(2)灵活性:Tensorflow 可在各种不同类型的设备上运行,不论是嵌入式系统或者是计算机服务器都能够很好的搭建相关环境。其分布式架构能够降低大量的计算模型所消耗的时间,并且可以同时使用CPU+GPU进行运算。
(3)开源:深度学习是未来的新技术,并且研究方面是全球性的,Tensorflow 的目的是为了形成一个标准化的工具,同时也是最好用的深度学习工具库之一,为用户直接提供了一个更优质的学习环境。
3 异构式CPU+GPU
3.1 CPU、GPU现状
随着计算机科学技术的不断发展和进步,众多先进技术的应用对计算机的计算性能需求也在不断攀升。近几年来,虽然计算机硬件技术也在继续发展,例如,Intel、IBM、AMD 等生产的通用CPU,采用多核集成的方式提高芯片计算能力,而非改善处理器主频率来增强计算机性能的传统概念。即便如此,很多技术采用了多核CPU 也无法满足大多数算力的需求。因此,如何解决突破计算机算力瓶颈这一问题成为了众多研究学者及生产业最为关注的问题。
伴随着GPU 的相关技术架构的构建被提出,从而使得GPU 在计算机计算性能领域被广泛推广及发展。自1999 年到目前为止,GPU 的运算能力得到了飞跃式的提升,并且已经将GPU 的应用范围不断的拓展。例如:从图形领域来看,医学家借助GPU可以观察到更细微的分子;军事作战指挥借助GPU 获得真实度更高的模拟作战演习环境;影视剧借助GPU 使得特效更加逼真。近些年来,更多的科学技术研究发现GPU 由于其硬件结构特点,在大量的高算力浮点吞吐运算环境中能够起到非常重要的作用,因此,众多领域已经逐渐开始使用GPU设备作为辅助设备。
3.2 异构式CPU+GPU协同计算
随着深度学习的不断拓展,卷积神经网络计算模型的复杂度也随之增加,数据计算量伴着卷积神经网络层的增加以及参数的增多而增大,使得模型训练的难度及耗时呈指数倍增长,单CPU 或单GPU 设备甚至已经无法解决复杂网络模型的训练耗时问题。
另一方面,不少研究人员针对耗时的问题也做了很多的工作,较为常见的方法例如:CPU 串行计算、GPU并行计算。值得肯定的是不论CPU串行计算或是GPU并行计算都能够有效地解决复杂卷积神经网络耗时较长的问题,但由于单一计算模型主要是将卷积神经网络模型运算任务调度在CPU 或GPU 设备上进行计算,这样容易使得部分设备(CPU 或GPU)处于空闲状态,造成资源浪费,导致性耗比降低。
针对如何能够使性耗比提升,提出了异构式CPU+GPU协同计算模型如图2所示,在理论上讲CPU与GPU两者的相同点都有总线、缓存体系、数字和逻辑运算单元。但CPU 更适合处理逻辑控制密集的计算任务,例如:分布式计算、物理模拟、人工智能等计算步骤相对复杂的任务;而GPU适合处理数据密集的计算任务,例如:数据分析、数据处理、图像处理等大量吞吐量设计的任务中。另一方面在SIMD Unit(Single Instruction Multiple Data,单指令多数据流,同步同指令)GPU性能要远大于CPU,Threads线程数方面GPU也远大于CPU。

图2 异构式CPU+GPU计算模型
在这个模型中,CPU 与GPU 协同工作,各司其职。CPU 负责进行逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。
实验步骤:编写Tensorflow模型训练应用程序,Client组件创建Session会话并通过序列化技术发送图定义到Distributed Master组件,Distributed Master会根据定义好的三种训练模型(单CPU、单GPU、异构式CPU+GPU)参数进行任务切割,并调度到指定设备。其中/job:worker/task:0负责模型的训练和推理;/job:ps/task:0负责模型参数的存储和更新,如图3所示。
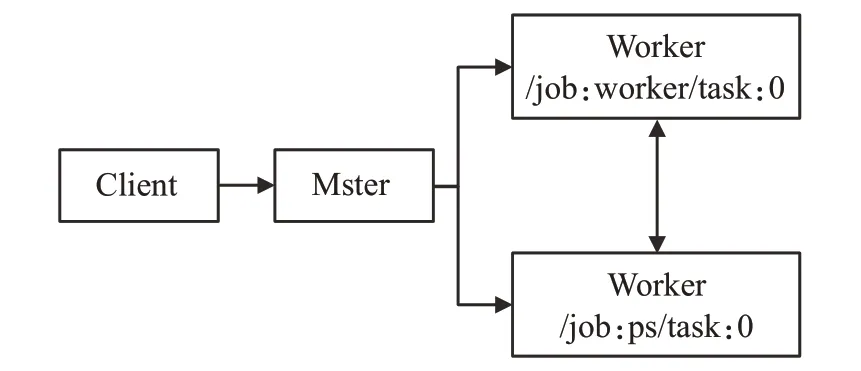
图3 任务切割分配图

图4 异构式CPU+GPU计算模型与单CPU计算模型测试对比

图5 异构式CPU+GPU计算模型与单GPU计算模型测试对比
三种训练模型分配方法如下。单CPU:
with tf.device(’/cpu:0’):
w=tf.get_varibale(…)
b=tf.get_varibale(…)
with tf.device(’/cpu:0’):
ad=w+b mu=w*b
单GPU:
with tf.device(’/gpu:0’):
w=tf.get_varibale(…)
b=tf.get_varibale(…)
with tf.device(’/gpu:0’):
ad=w+b
mu=w*b
异构式CPU+GPU:
with tf.device(’/cpu:0’):
w=tf.get_varibale(…)
b=tf.get_varibale(…)
with tf.device(’/gpu:0’):
ad=w+b
mu=w*b
实验测试:选用三台相同型号及配置的服务器,其中一台做测试服务器task1,另两台做对比测试服务器task2、task3,分别在三台服务器上定义sever,并且在task1 上制定job_model1(异构式CUP+GPU 训练模型),取两次测试结果的平均值做实验对比,在task2、task3上制定job_model2(单CPU、单GPU训练模型),并取task2 与task3 测试结果的平均值做实验对比,所得结果如图4、5 所示。异构式CPU+GPU 计算模型两次对比测试实验结果分别为:133.132 362 883 237 8 s、134.860 072 175 262 76 s,而单CPU计算模型测试结果为:189.031 933 339 740 60 s、189.954 021 626 453 37 s;单GPU计算模型测试实现演过分别为:170.143 887 107 263 25 s、167.609 163 142 034 05 s。测试实验结果的平均值如表2所示。

表2 单CPU、单GPU、异构式CPU+GPU测试实验结果平均值
通过实验结果分析可以看出,卷积神经网络训练模型的准确率几乎并未改变,而在模型训练耗时上异构式CPU+GPU 模型的时耗明显低于单CPU 或单GPU 模型。同时由于改变了模型训练的任务调度,使CPU 和GPU同时作业,有效地避免了设备闲置问题,从而在性耗比上得到了很好的提升,使卷积神经网络在模型计算上得到了很好的优化。
4 ReLU-Swish激活函数
4.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)通俗讲是卷积结构的深度神经网络,并且也是一种结构层级较多的监督型学习的神经网络。在图像分类、目标检测、声音识别等方面表现出了极高的效率,几乎接近人类所能达到的认知标准和抽象的表达。卷积神经网络虽然结构层级较多,但其占用的内存较少,网络参数的个数也相对其他神经网络相对较少,这样便极大的缓解了神经网络中过拟合的问题。
2012年,Krizhevsky等[4]提出的深度卷积神经网络,总共包含8 层,其中有5 个卷积层和3 个全连接层,有60 M 个参数,神经元个数为650 k,分类数目为1 000,LRN层出现在第一个和第二个卷积层后面,最大池化层出现在两个LRN 层及最后一个卷积层后。AlexNet 卷积神经网络极大地减少了模型训练时间,并使用线性ReLU激活函数加快训练速度。
4.2 激活函数
不论是传统的神经网络模型还是当下热门的深度学习,激活函数与神经网络都密不可分,其作用是将神经元的输入映射到输出端。神经网络中的每个神经元节点接受上一层神经元的输出值作为原神经元的输入值,并将输入值传递给下一层,输入层神经元节点将输入属性值直接传递给下一层(隐藏层或输出层)。在上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。常见的激活函数包括Sigmoid、TanHyperbolic(Tanh)、ReLU、PReLU、Softplus、ELU、Softsign、Swish等。
4.2.1 ReLU激活函数
线性整流函数(Rectified Linear Unit,ReLU)[17-18],又称修正线性单元,如图6所示。

图6 ReLU激活函数
ReLU激活函数的优点:
(1)解决了在正区间梯度消失问题。
(2)计算速度非常快,只需要判断输入是否大于0,收敛速度远快于Sigmoid 和Tanh(Sigmoid 和Tanh 的梯度在饱和区域变大非常平缓,接近于0,这就容易造成梯度消失,减缓收敛速度。而ReLU 的梯度是一个常数,有助于解决深度网络的收敛问题)。
ReLU函数的缺点:
坏死,ReLU 强制的稀疏处理会减少模型的有效容量(即特征屏蔽太多,导致模型无法学习到有效特征)。由于ReLU在x <0 时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。
4.2.2 PReLU激活函数
PReLU(Parametric Rectified Linear Unit)如图7所示,顾名思义为带参数的ReLU。
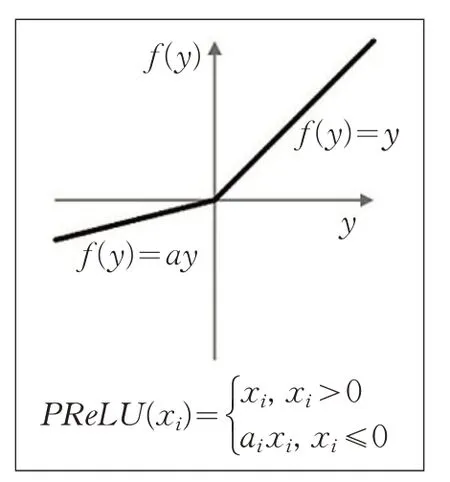
图7 PReLU激活函数
如果ai=0,那么PReLU退化为ReLU。
PReLU函数的优点:
相比ReLU 激活函数PReLU 激活函数只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同channels使用相同的ai时,参数就更少了。
在文献[19]中,对比了PReLUu 激活函数和ReLU激活函数在ImageNet model A 的训练效果,如8 所示,相对ReLU激活函数极大的降低了错误率。
PReLU激活函数的缺点:
PReLU激活函数虽然有负值存在,但是不能确保是一个噪声稳定的去激活状态。

图8 PReLU与ReLU激活函数对比
4.2.3 ELU激活函数
指数线性单元(Exponential Linear Unit,ELU)[20]如图9所示。

图9 ELU激活函数
ELU激活函数函数的优点:
(1)ELU由于其正值特性,可以像ReLU激活函数,PReLU激活函数一样缓解梯度消失问题,如图10所示。

图10 ReLU、ELU、PReLU激活函数
(2)相比ReLU 激活函数,ELU 与PReLU 一样存在负值,可以将激活单元的输出均值往0 推近,减少了计算量(输出均值接近0可以减少偏移效应进而使梯度接近于自然梯度)。
(3)相比PReLU激活函数,ELU在有负值存在的时候是一个指数函数,对于输入来说只定性不定量。
ElU激活函数函数的缺点:
虽然相对ReLU 激活函数降低了坏死率,在x <0时梯度不为0,保证了部分神经元仍然能够被激活,但与PReLU激活函数相似,网络的计算量以及过拟合的危险仍然很大。
4.2.4 Swish激活函数
Swish 也被称为self-gated(自门控)激活函数如图11 所示,由谷歌研究人员发布。Swish 的数学表达为:
图11 Swish激活函数
Swish 函数的优点:自门控的优势是它仅需要一个简单的标量输入,而正常的门控需要多个标量输入。Swish激活函数的表现比ReLU更好,原因在于Swish激活函数在x 轴的负区域内末端的图像形状与ReLU、PReLU、ELU 激活函数是不同的,如图12 所示,这是因为swich 激活函数即使输入的值在增加,它的输出也可以减少。大部分的激活函数都是单调的,即它们的输出值在输入增加的时候是不会减少的。Swish在0点具有单边有界性,平滑且不单调。
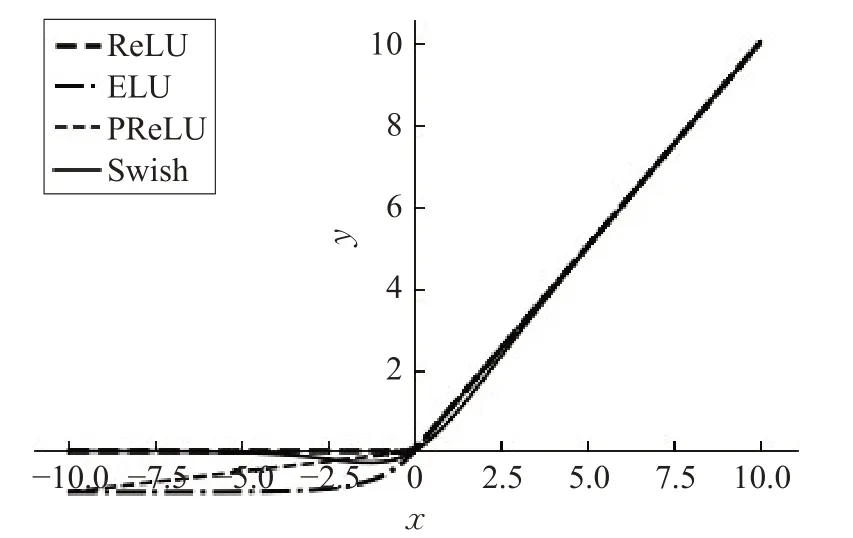
图12 ReLU、ELU、PReLU、Swish激活函数
谷歌测试证明,在AlexNet 上用MNIST 和Fashion-MNIST数据集对ReLU激活函数与Swish激活函数进行对比测试,结果如表3所示。

表3 Swish激活函数谷歌测试结果
在3、10、45 三种不同的全连接层上不断地增加测试集的难度所得结果显示,Swish 激活函数的测试结果明显优于ReLU激活函数的测试结果。
但在收敛性上,Swish 激活函数较ReLU 激活函数却相差很多。
4.2.5 ReLU-Swish激活函数
针对Swish 激活函数的特性提出的ReLU-Swish 激活函数由两个分段函数组成,如图13 所示,表达公式为:f

图13 ReLU-Swish激活函数
ReLU-Swish激活函数与Swish激活函数对比,如图14所示。

图14 ReLU-Swish、Swish激活函数对比
ReLU-Swish在保持Swish原有特性的基础上,一方面,是为了克服Swish激活函数在反向传播求误差梯度时涉及参数较多导致的计算量较大的问题,这样就可以使得输出运算节省大量的时间;另一方面,正是因为网络模型在运算时往往需要大量的时间来处理大量的数据,模型的收敛速度成为了极为关键的因素。由于Swish 激活函数在模型收敛速度上不如ReLU 激活函数,因此将正区间上的这一段Swish 函数用ReLU 激活函数来替代,从而解决了Swish激活函数由于模型训练运算中参数过多而导致的收敛速度过慢的问题。由于ReLU-Swish 激活函数与Swish 激活函数在特征性能方面保持着高度的相近性,并且ReLU激活函数在网络模型结构层数较多时测试准确率较高的优势,所以ReLUSwish激活函数在提高准确率及收敛效率上有着明显的提高。
如图15,16 所示,在测试中可以明显得出ReLUSwish激活函数的收敛速度相较于Swish激活函数的收敛速度更快。在准确率上,在卷积核为10 的小型卷积神经网络测试模型下,取3次CIFAR-10、MNIST训练集训练模型结果的平均accuracy 的结果如表4、5 所示,ReLU-Swish 激活函数的准确率为97.52%,而Swish 激活函数的准确率为96.7%,所以在准确率上ReLU-Swish激活函数也有所提升。

图15 ReLU-Swish、Swish激活函数收敛性对比

图16 ReLU-Swish、Swish激活函数准确率对比
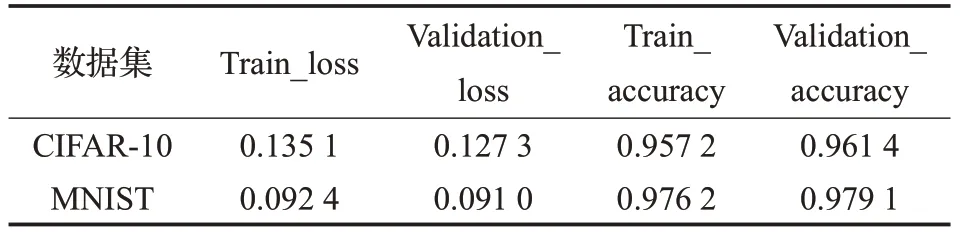
表4 ReLU-Swish激活函数CIFAR-10、MNIST测试

表5 Swish激活函数CIFAR-10、MNIST测试
5 结束语
本文通过分析研究卷积神经网络在性耗比上的不足,提出了一种异构式CPU+GPU 协同计算模型,在性耗比上比单CPU计算或单GPU计算的效果更优异。本文还通过分析研究Swish激活函数以及ReLU在卷积神经网络中存在的问题,提出了一种新的ReLU-Swish 激活函数。经过测试实验验证了ReLU-Swish激活函数在收敛性及准确率上都有所提高,在模型训练中表现的更优异,达到了很好的预期效果,同时也为卷积神经网络的研究提供了一种新的方法及思路。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
数学物理学报(2022年1期)2022-03-16
数学物理学报(2021年6期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
应用数学(2020年2期)2020-06-24
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
商周刊(2019年1期)2019-01-31
北京航空航天大学学报(2018年1期)2018-04-20
