
基于改进型加性余弦间隔损失函数的深度学习人脸识别*
2020-01-02 06:21章东平陈思瑶李建超周志洪孙水发
传感技术学报 2019年12期
章东平,陈思瑶,李建超,周志洪,孙水发
(1.中国计量大学信息工程学院,浙江省电磁波信息技术与计量检测重点实验室,杭州 310018;2.上海市信息安全综合管理技术研究重点实验室,上海 200000;3.三峡大学计算机与信息学院,湖北 宜昌 443002)
近年来,深度学习不断发展,研究者们提出许多新方法为人脸识别技术提供了新的理论依据,翻开了人脸识别领域的新篇章。Facebook提出的DeepFace方法[1],使用4 000个人200万的大规模训练数据训练深度卷积神经网络,在著名的人脸测试数据集LFW(Labeled Faces in the Wild)[2]上第一次取得了逼近人类的识别精度。香港中文大学的汤晓鸥团队提出的DeepID系列[3-5],使用25个网络模型,并在网络结构上同时考虑分类损失和验证损失等,显著提升了人脸识别效果,在LFW上超过了人类的识别精度。Google提出了FaceNet网络结构[6],该网络结构拥有更深的网络层,共27层,其次使用800万人共2亿的超大规模人脸数据库训练该网络结构,且引入Triplet损失函数,使得模型的学习能力更高效,在LFW等人脸测试集上都取得了当时最好的效果。微软亚洲研究院视觉计算团队提出ResNet[7],解决了网络过深而导致的网络退化问题,从而能够通过单纯地增加网络深度,来提高网络性能。在Resnet网络表现力十分优秀的情况下,要提高人脸识别模型的性能,除了优化网络结构,修改损失函数是另一种选择,优化损失函数可以使模型从现有数据中学习到更多有价值的信息。
人脸识别根据训练数据与测试数据之间有无身份重叠可分为:闭集人脸识别和开集人脸识别。闭集人脸识别相对于开集人脸识别更容易一些,仅需要对人脸图像进行分类,而开集人脸识别存在人脸比对问题,需要使用度量学习方法,要求类间距离大于类内距离[8]。针对闭集人脸识别和开集人脸识别,人脸识别损失函数分为两大类,一类是基于分类的损失函数,一类是基于度量学习的损失函数。基于度量学习的损失函数又分为两类,一类是基于欧式距离的损失函数,例如Contrastive损失函数[9],中心损失函数[10]、Normface[11],Triplet损失函数等等;另一类是基于余弦距离的损失函数,例如乘性角度间隔损失函数[12]、加性余弦间隔损失函数[13]、加性角度间隔损失函数[14]等。加性余弦间隔损失函数仅通过将特征与目标权重夹角的余弦值减去一个值,来达到减小类内距离的目的,并没有直接对类间距离进行操作来拉大类间距离。
为了解决上述问题,本文在加性余弦间隔损失函数的基础上提出改进型加性余弦间隔损失函数,通过在特征与目标权重夹角的余弦值减去一个值,在特征与非目标权重夹角的余弦值加一个值,达到减小类内距离,拉大类间距离的目的。
1 改进型加性余弦间隔损失函数
1.1 SoftMax损失函数
SoftMax损失函数常用于图像分类,如式(1)所示:
(1)
式中:xi表示第i个样本的特征,该样本属于第yi类;Wj表示权重矩阵的第j列;b表示偏置项;n表示一个批次的样本数目;C表示样本类别数。SoftMax损失函数仅考虑到样本是否能正确分类,在增大类间距离和缩小类内距离的问题上有很大的优化空间。
1.2 改进型加性余弦间隔损失函数
1.2.1 权重归一化
提出的改进型加性余弦间隔损失函数,在SoftMax损失函数基础上,将SoftMax损失函数中的偏置项置为0;再将权重与特征的内积操作WTx分解为‖W‖‖x‖cos(θ),可以看出,对于一个给定的特征x,则SoftMax损失函数是根据权重的模及权重与特征间夹角的余弦值进行优化,若强制将权重进行归一化,则类别判断仅依赖于权重与特征间的夹角,进行权重归一化操作的SoftMax损失函数为:
(2)
Guo Y D(2017)提出每个人脸身份对应的权重的模和人脸身份的人脸图片数量成正比[15],因此,权重归一化操作,能够一定程度上解决类别不平衡问题。
1.2.2 特征归一化
将进行权重归一化操作的SoftMax损失函数再进行特征归一化操作得到如式(3)所示的损失函数:
(3)
由于,特征的模与人脸图像质量有关,高质量人脸图像特征的模大,低质量人脸图像特征的模小。在进行特征归一化操作后,特征模小的比特征模大的会有更大的梯度,所以在反向传播过程中,网络会对低质量人脸图片更大的关注。因此,特征归一化操作适用于图片质量低的人脸识别任务。
1.2.3 改进型加性余弦角度间隔损失函数
本文定义的间隔是使用在余弦值上,即在归一化后的目标分数cosθyi上减去m/2,在归一化后的非目标分数cosθj上加上m/2,得到:
(4)
(5)
改进型加性余弦角度间隔损失函数如式(6)所示:
(6)
式中:n表示一个批次的样本数目,C表示样本类别数,s表示余弦系数,m表示余弦间隔,θyi表示特征与目标权重的夹角,θj表示特征与非目标权重的夹角。
增加s的作用是为了网络能够集中表达能力区分困难样本。s越小,网络会倾向于区分简单样本,当s=1时,在反向传播过程中,简单样本和困难样本的梯度几乎没有差别。
改进型加性余弦角度间隔损失函数与加性余弦角度间隔损失函数相比,不同之处在于,加性余弦角度间隔损失函数仅通过将特征与目标权重夹角的余弦值减去一个值,来达到减小类内距离的目的,并没有直接对类间距离进行操作来拉大类间距离。而改进型加性余弦角度间隔损失函数不仅通过将特征与目标权重夹角的余弦值减去一个值,还通过将特征与非目标权重夹角的余弦值加上一个值,从而达到增大类间距离,减小类内距离的目的。
特征和权重夹角示意图如图1所示,加性余弦角度间隔损失函数只是令特征向量x1和权重矩阵第一列W1的夹角θ1尽量小,而改进型加性余弦角度间隔损失函数不仅令θ1尽量小,还需要令特征向量x1和权重矩阵第二列W2的夹角θ2及特征向量x1和权重矩阵第三列W3的夹角θ3都尽量大。
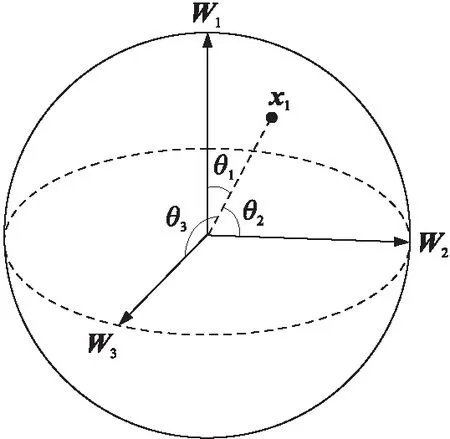
图1 特征与权重夹角示意图
2 网络结构
在SphereFace中,作者采用网络层数分别为4、10、20、36、64的残差网络结构进行人脸识别实验,实验表明随着网络层数增加人脸识别性能越好,但是网络层数越深耗费越多的资源,所以本文采用20层的残差网络结构,如图2所示,包括20个卷积层,2个全连接层,其中,每个卷积层后接Relu激活函数[16],每两个卷积层构成一个残差模块,倒数第二个全连接层为特征层,维度为512维,最后一个全连接层维度为训练人脸数据的类别数。
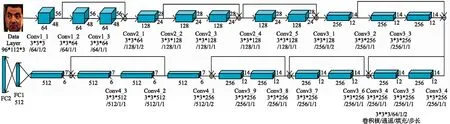
图2 Resnet-20网络结构
3 实验
3.1 实验细节
采用CASIA数据集作为训练集,包含10575身份的439 456张图片,对该数据集采用Mtcnn[17]进行人脸检测及关键点检测再进行校正成96×112的人脸图像,将校正好的人脸图像的RGB三个通道每个像素进行归一化处理,即减去127.5再除128。训练过程中,采用随机梯度下降策略,batch size为128,weight_decay为0.000 5,学习率设为0.1,采用多分步策略,步长分别为18 000,30 000,48 000,最大迭代次数为 50 000。采用深度学习框架Caffe[18]在NVIDIA Titan X 显存12GB设备上进行人脸识别模型训练。
3.2 实验数据集介绍
3.2.1 CASIA-WebFace数据集[19]
CASIA-WebFace数据集是国内人脸识别届颇具盛名的人脸训练集,2014年,由中科院自动化研究所李子青团队借用了IMDb网站,通过半自动的方式完成了图像收集和标记,经过数据清洗,最终包含10 575个人的494 414张人脸图像,在当时是人脸数据集中数据量最大的公开数据集,为人脸识别技术的发展做出了很大贡献。

图3 CASIA-WebFace数据集人脸图像示意图
3.2.2 LFW(Labeled Faces in the Wild)数据集
LFW是专门用于研究非限定条件下人脸识别的数据集,该数据集包含从网络上收集的13 000多张人脸图像,每张人脸图像都有确定的身份,其中,1 680 人在数据集中有两张或更多不同的人脸图像。LFW数据集主要测试人脸识别的准确率,从数据库中随机选择人脸图像,组成了6 000对人脸辨识图片对,其中3 000对为正样本对,即由相同人的2张不同人脸图像组成,3 000对为负样本对,即由不同人的每人1张人脸图像组成。

图4 LFW数据集人脸图像示意图
3.2.3 YTF(YouTube Faces)数据集[20]
YTF数据集是一个人脸视频数据库,都是从YouTube上下载的,旨在研究视频中非限定条件下的人脸识别问题,包含3 425个视频,共1 595人,平均一个人大概有2段视频,最短的视频帧为48帧,最长的视频帧为6 070帧,平均视频帧为181.3帧。YTF数据集主要测试人脸识别的准确率,从数据库中随机选择5 000对视频,被分成10个部分,每个部分包含250个同一个人的视频对和250个不同的人的视频对。

图5 YTF数据集人脸图像示意图
3.2.4 SVF(Surveillance Video Faces)数据集
SVF数据集是自行采集的500个人在监控场景下的人脸照片,包括遮挡、多姿态、不同光照的人脸图像,其中,每人两张人脸图像,构成500个正样本对,499 000个负样本对,即相同人的两张人脸图像构成正样本对,共500对,每个人的人脸图像与其他人的人脸图像构成负样本对,共499 000对。

图6 SVF数据集人脸图像示意图
3.3 改进型加性余弦间隔参数调节比对实验
Normface提出让网络自动学习参数s。加性余弦间隔损失函数指出在损失函数中加入间隔之后,发现若让网络自动学习参数s,网络的收敛速度很慢且s不会增加,只需固定参数s为一个足够大的值能够使网络快速且稳定的收敛,但是,若参数s取值较大时则几乎不具备间隔,不能减小类内距离。因此本实验分别选取s=20,s=30进行比对实验。
参数m的作用是增加分类边界的间隔,如图7所示为改进型加性余弦间隔在参数m取不同值时ψ(θyi)的曲线图。
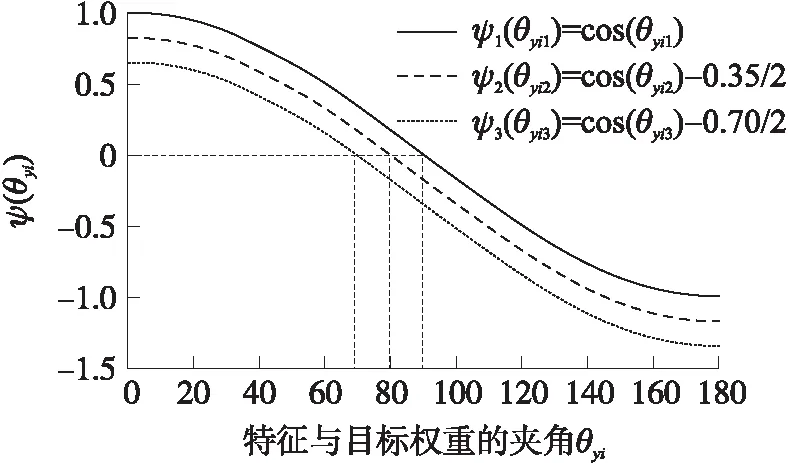
图7 参数m取不同值时ψ(θyi)的曲线图
如图8所示为改进型加性余弦间隔在参数m取不同值时ψ(θj)的曲线图,其中m的取值范围为[0,1]。当ψ1(θyi1)、ψ2(θyi2)、ψ3(θyi3)取相同值时,θyi3<θyi2<θyi1,例如当ψ1(θyi1)=0时,θyi1等于90°;当ψ2(θyi2)=0时,θyi2约等于80°;当ψ3(θyi3)=0时,θyi3约等于70°,因此参数m可减小特征与目标权重的夹角,即缩小类内距离。当ψ1(θj1)、ψ2(θyi2)、ψ3(θyi3)取相同值时,θj3>θj2>θj1,例如当ψ1(θj1)=0 时,θj1等于90°;当ψ2(θyi2)=0时,θj2约等于100°;当ψ3(θyi3)=0时,θj3约等于110°,因此参数m可增加特征与非目标权重的夹角,即增大类间距离。但m值越大训练难度越大,因此选取m=0.35,m=0.70进行比对实验。
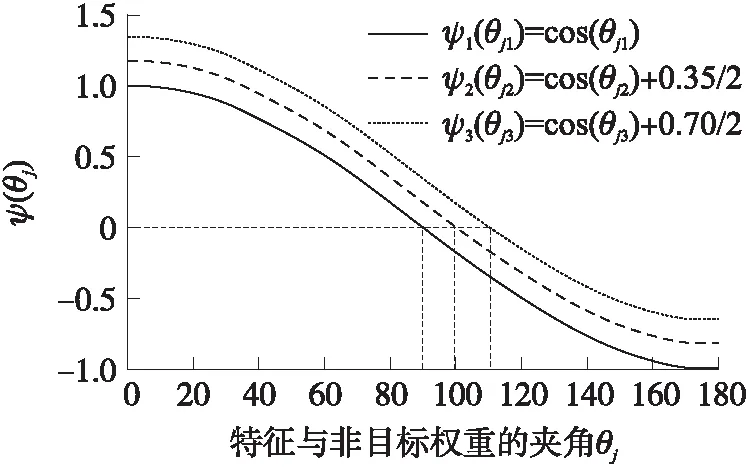
图8 参数m取不同值时ψ(θj)的曲线图
如图9所示,当改进型加性余弦间隔损失函数参数m、s取不同值时训练出的人脸识别模型,在SVF数据集上的ROC曲线图,横坐标表示误识率,纵坐标表示召回率。当m=0.35,s=30时训练出的人脸识别模型比当m=0.35,s=20时训练出的人脸模型在SVF数据集上效果好。当m=0.70,s=30时,训练出的人脸识别模型比当m=0.35,s=30时训练出的人脸模型在SVF数据集上效果好,所以,本文令改进型加性余弦间隔损失函数参数m=0.70,s=30进行人脸识别模型的训练。
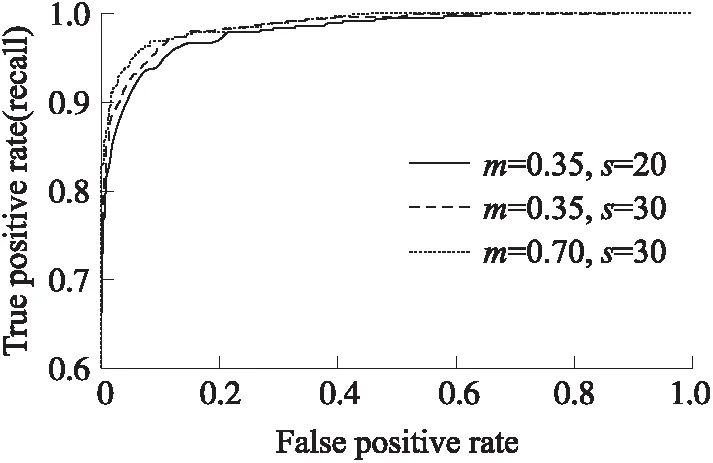
图9 改进型加性余弦间隔损失函数取不同参数值时训练出的人脸识别模型在SVF数据集上ROC曲线图
3.3 在LFW和YTF数据集上实验结果分析
不同损失函数采用相同的网络结构训练出的人脸识别模型,在LFW数据集上及YTF数据集上测试结果如表1所示,在LFW数据集上,乘性角度间隔损失函数训练出的人脸识别模型准确率最高;在YTF数据集上,乘性角度间隔损失函数训练出的人脸识别模型准确率最高。在LFW数据集上改进型加性余弦间隔损失函数训练出的人脸识别模型比性能第1的模型相比准确率低了0.3%;在YTF数据集上改进型加性余弦间隔损失函数训练出的人脸识别模型比性能第1的模型相比准确率低了1.08%。在YTF数据集上加性余弦间隔损失函数训练出的人脸识别模型与乘性角度间隔损失函数训练出的人脸识别模型相比准确率提升0.22%,说明针对低质量人脸图像识别任务,在训练过程中进行特征归一化操作是有效的。
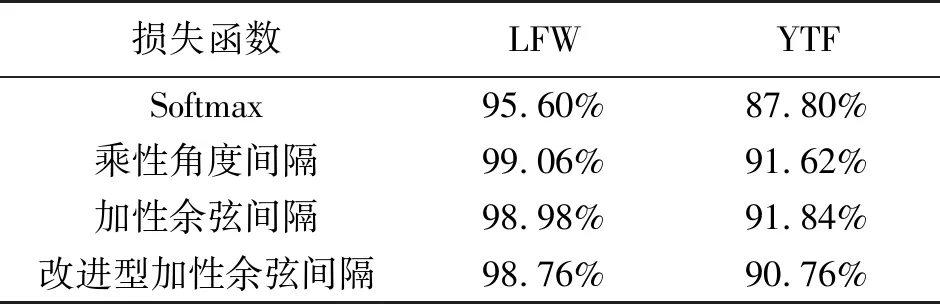
表1 不同算法在LFW和YTF数据集上的测试结果
3.4 在SVF数据集上实验结果分析
不同损失函数采用相同网络结构训练出的人脸识别模型,在SVF数据集上的测试结果如表2所示,①表示采用Softmax损失函数训练出的人脸识别模型,②表示乘性角度间隔损失函数训练出的人脸识别模型,③表示加性余弦间隔损失函数训练出的人脸识别模型,④表示改进型加性余弦间隔损失函数训练出的人脸识别模型。改进型加性余弦间隔损失函数训练出的人脸识别模型与性能第2的加性余弦间隔损失函数训练出的人脸识别模型相比,在10-2的误识率下的召回率提升了4.6%,在10-3的误识率下的召回率提升了5.4%,在10-4的误识率下的召回率提升了2.8%,在10-5的误识率下的召回率提升了0.2%。
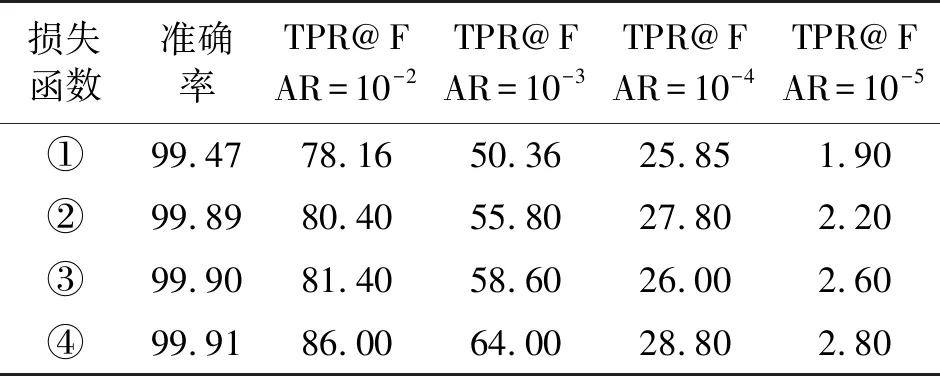
表2 不同算法在SVF数据集上的测试结果
改进型余弦间隔损失函数训练出的人脸识别模型与加性余弦间隔损失函数训练出的人脸识别模型相比,在LFW数据集、YTF数据集上效果没有加性余弦间隔损失函数训练出的人脸识别模型效果好,而在SVF数据集上比加性余弦间隔损失函数训练出的人脸识别模型效果好,是由于改进型余弦间隔损失函数训练出的人脸识别模型与加性余弦间隔损失函数训练出的人脸识别模型的训练数据采用的CASIA-WebFace数据集,与测试集LFW数据集及YTF数据集均是名人人脸图像,而SVF数据集是监控人脸图像,可以看出改进型余弦间隔损失函数训练出的人脸识别模型具有更好的泛化性能。
4 结论
人脸识别分为闭集人脸识别和开集人脸识别,在开集人脸识别中存在人脸比对问题,需要使用度量学习方法,要求类间距离大于类内距离。从该角度出发,设计出许多损失函数,例如乘性角度间隔损失函数、加性余弦间隔损失函数、加性角度间隔损失函数等。但这些损失函数仅通过将特征与目标权重的夹角乘上或加上一个值,来达到减小类内距离的目的,并没有直接对类间距离进行操作来拉大类间距离。本文对加性余弦间隔损失函数进行改进,将特征与目标权重夹角的余弦值减去一个值,在训练过程中,使得人脸特征向目标权重靠拢,从而达到减小类内距离的目的;将特征与非目标权重夹角的余弦值加上一个值,在训练过程中,使得人脸特征远离非目标权重,从而达到增大类间距离的目的。
本文采集了500个人每人2张人脸图像,组成了SVF(Surveillance Video Faces)数据集,包括500个正样本对,499 000个负样本对。可测试训练的人脸识别模型在实际监控场景的性能。发现目前开源的一些较为先进的人脸识别方法及本文提出的人脸识别方法,在公开人脸数据集有着优秀的表现,提出的人脸识别方法在实际监控场景中与Softmax损失函数、乘性角度间隔损失函数及加性余弦间隔损失函数训练的人脸识别模型相比人脸识别准确率更高,且与加性余弦间隔损失函数训练的人脸识别模型相比在10-3的误识率下的召回率提升了5.4%。
猜你喜欢
阜阳师范大学学报(自然科学版)(2022年1期)2022-04-02
网络与信息安全学报(2021年6期)2022-01-18
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
动漫星空(2018年9期)2018-10-26
系统管理学报(2018年3期)2018-08-13
系统管理学报(2018年2期)2018-08-13
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
