
基于PLOAD 模型的面源污染模拟研究
2020-01-02 05:09刘慧
水科学与工程技术 2020年6期
刘 慧
(西北矿冶研究院,甘肃 白银730900)
对水功能区污染现状的定量分析是限制纳污的前提,而由于现有水文水质监测数据的缺失不全,需要采用理论方法进行计算。引入水文水质模型,能够帮助研究人员了解水文情势的发展变化及影响因素、水体中污染物的扩散迁移特点,并为制定解决水问题的决策提供依据。 通过PLOAD模型进一步模拟流域面源污染,最终得到精度较高的模拟结果。为有效预测、 避免及控制水污染问题提供依据, 如制定BMPs 措施、预测流域未来径流等。
1 研究区概况
青龙河是滦河主要支流之一,发源于燕山山脉,范围包括河北省秦皇岛市至辽宁省凌源市。 引滦济津工程成功为天津调水后, 为解决滦河中下游地区的用水困难问题,修建了桃林口水库,旨在开发滦河中下游水资源。
2 数据来源及模型概况
2.1 数据来源
模型校准和验证需要的水文数据主要包括流域出口的径流量信息。 径流总量数据来自河北省秦皇岛市和辽宁省凌源市水库管理局, 其中包括1929~2012 年实测年径流量。
首先提取气象数据V3.0版本中有用的数据,包括降雨、气温、风速等要素,经过单位换算、异值处理、 公式运算等前处理后, 通过系统内的WDMUtil程序导入为PLOAD模型可用的wdm格式文件,在WDMUtil 程序中, 再利用程序内的公式将每日的气象数据计算为小时数据, 最终形成模型计算可以使用的气象数据的时间序列。
根据研究流域周边气象站点的分布, 选择最近的9个气象站点, 利用ArcGIS 对流域划分泰森多边形[1]。 在结果中发现,由于外围气象站距离过远,流域基本都在一个气象站的控制范围内,ArcGIS对流域划分泰森多边形的结果如图1。 据此,采用点降雨数据进行后续模拟, 范围从1957年1月1日至2012年12月31日。
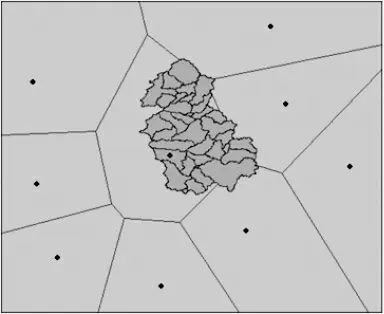
图1 对研究流域划分泰森多边形
2.2 模拟方法
PLOAD(Pollutant Loading Estimator)模型是一个简化的、 基于GIS的计算非点源污染负荷的模型,由美国弗吉尼亚州的CH2M-Hill团队开放发, 并在BASINS系统中为它提供技术支持和功能整合与拓展。 模型以年降水量、土地利用和BMPs 为基础,计算不同子流域和土地利用的非点源污染负荷。 它采用出口系数法或美国环保局的简单方法, 在年平均值的水平上, 估算用户指定的任意非点源污染PLOAD与BASINS系统连接,它根据现有的图层与模型的接口一一对应。与BASINS 系统的嵌合使模型能够更好地估算非点源负荷、相对贡献及BMP 措施产生的负荷削减。 模型的计算结果以图层和表格的形式生成在BASINS 界面中, 包括每个子流域的负荷量,以及该子流域中的每亩负荷量等。当需要估计简单富营养化模型的季节性或年度负荷量时,PLOAD模型是非常有用的工具[2]。
当选择输出系数法时, 模型采用以下公式计算每个流域的指定污染负荷:
LP=∑U(LPU·AU)
式中 LP为污染负荷量(lbs);LPU为土地利用类型u的污染负荷率(lbs/acre/year),来自输出系数表;AU是土地类型u的面积(acres),从土地利用和子流域图层得出。
当选择简单方法时,计算公式包括两个,首先计算每种土地利用类型的径流系数:
RVU=0.05+(0.009·IU)
式中 RVU即土地利用类型u的径流系数(inchesrun/inchesrain);IU是不透水地面百分比, 从径流污染物平均浓度表中提取。
然后计算污染负荷量[3]:
LP=∑U(P·PJ·RVUCUAU·2.72/12)
式中 LP为污染负荷量 (lbs);P是降雨量(inches/year);PJ是为降雨产流率,即产生径流的降雨事件占总降雨事件的比例,默认取值0.9,以上两个值由用户输入;RVU为土地利用类型u的径流系数(inchesrun/inchesrain);CU是土地利用类型的径流污染物平均浓度(milligrams/liter);AU是土地类型u的面积(acres),因为在PLOAD的面积从GIS数据中提取,以平方米为单位,PLOAD 用上式将面积单位换算为英亩。
2.3 模型建立
2.3.1 BASINS模型建立
模型数据库准备完成后,在PLOAD 界面添加所有图层。 主要图层包括地形、土地类型、土壤和河网及子流域数据。叠加气象站点图层后,添加气象数据至模型中[4]。建立BASINS模型后,能够进行系统内嵌多个水文水质模型的运算模拟,如图2。 拓扑结构为子流域示意图,RCHERS 对应BASINS系统中的35个子流域如图3,RCHERS之间的连线表示河段间的连通关系。
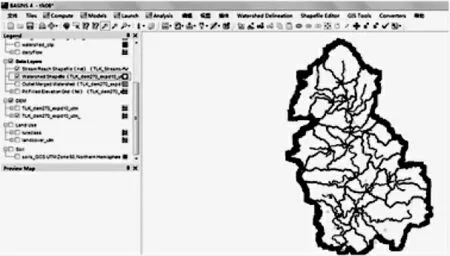
图2 软件建模
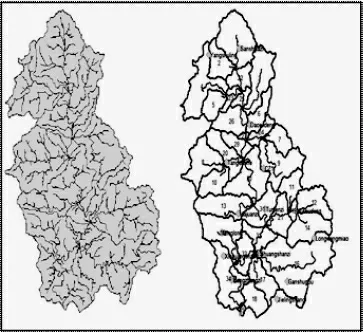
图3 流域划分
2.3.2 模型验证
将2012年作为模型率定期, 分别进行年径流总量、月径流总量及日径流量的校准。
根据实测径流量, 率定得到2012年的Nash系数为0.81。 研究流域全年降水分布不均匀,汛期7、8月份降雨量最为明显,与此相对应,径流量的分布也集中在这两个月。 为分析模型对径流量变化明显时间段的模拟效果,再对7、8月的实测流量与模拟流量进行对比, 计算得出Nash系数为0.74。 这一结果说明,排除非汛期的数据后, 模型对特征时间段的模拟仍然有较好的精度。
取2012年作为验证期, 对模型模拟与参数组合进行验证,经计算,验证期Nash系数为0.79,这表明总体而言,模型建模效果良好,模型模拟结果具有较高的可信度。
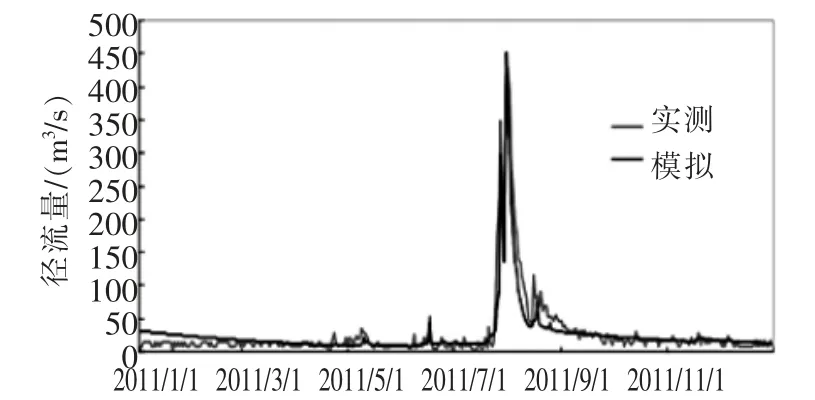
图4 2012年模拟与实测流量对比图
根据以上参数校准与验证的过程及模拟结果,认为参数取值在合理范围内。
2.3.3 模拟结果分析
校准与验证过程中, 采用Nash系数作为评估标准,基于现有条件,认为模型总体精度较为理想,为进一步分析模拟结果,分别从相关性、灵敏度两个方面对2011年和2012年的实测流量与模拟流量进行了计算与分析。
在GenScn中输出校准期与验证期的散点图如图5, 得到2012年模拟流量与实测流量的相关系数为0.880,相关程度较好,且验证期相关性优于校准期。
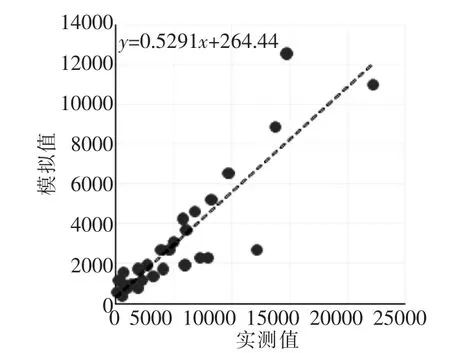
图5 2012年流量散点图
分析参数灵敏度排序情况, 如图6~图7, 参数INTFW、IRC和UZSN在3个目标下的灵敏度程度相同,均为相对影响较小的参数, 参数AGWRC在日流量偏差目标函数和月流量目标函数中影响最大,而对超流量天数偏差目标函数影响最大的参数为AGWETP。在总目标函数的参数灵敏度排序中,可以看出有关地下水的参数AGWRC、AGWETP和DEEPFR的影响同样非常显著,说明研究流域的径流量产生量受地下水影响程度明显,下渗系数的灵敏度排序紧随其后。 根据以上结果,分析原因,首先是该流域透水地面占比较大, 降雨的下渗和截留等从地面进入土壤的过程较多;其次,该流域常年降雨量分布不均,因此非汛期的径流量主要受地下水变化过程的影响[5]。

图6 PEST按3个目标函数计算参数灵敏度
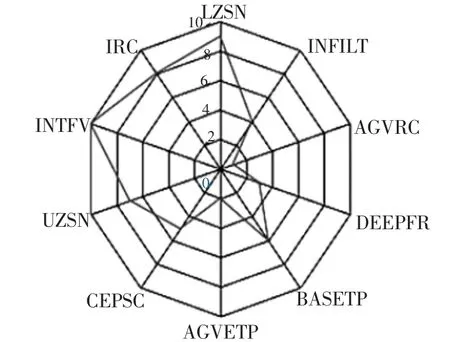
图7 PEST参数灵敏度总排序
3 结果分析
3.1 空间分布
采用PLOAD模型输出总氮、 总磷和BOD在35个子流域内的非点源污染负荷量, 以评判不同子流域内污染情况,图8~图10即PLOAD模型的输出图像,根据子流域污染负荷的数值分为七类, 颜色的深浅代表了污染负荷量的大小。从3张图综合分析来看,3种水质成分负荷量较大的子流域大致相同, 最严重的分别为子流域16和34。这两个流域本身面积较大,并且耕地是产污量最大的土地类型, 与其他子流域相比较, 在这两个子流域中耕地类型的面积所占比例较大。 污染程度较轻的子流域分别为6和7。
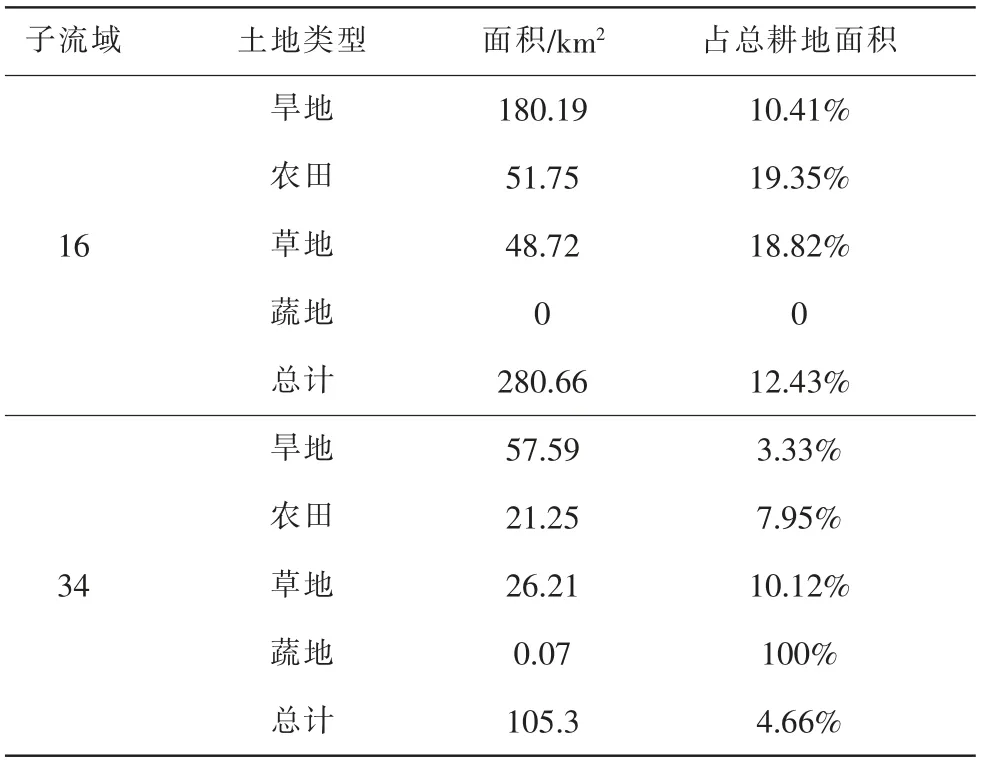
表1 子流域16和34内耕地类型面积与百分比
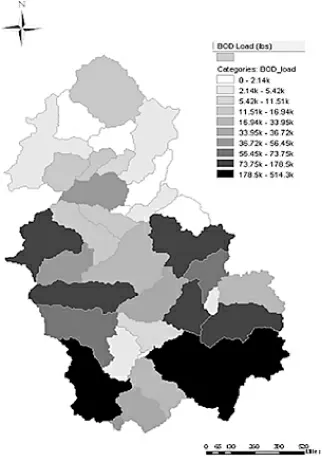
图8 BOD在流域的空间分布
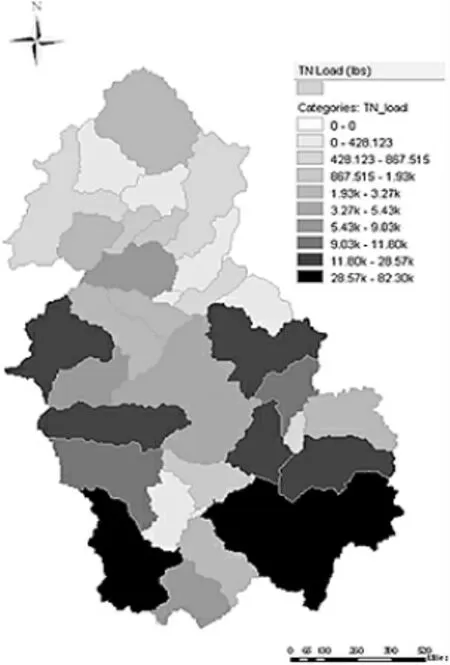
图9 总氮在流域的空间分布
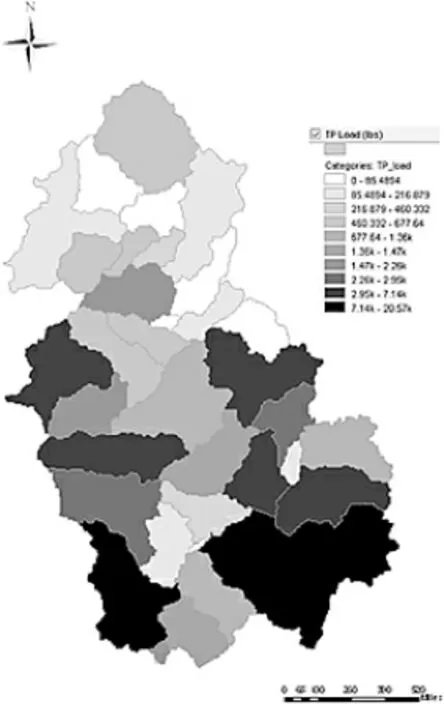
图10 总磷在流域的空间分布
3.2 农药化肥施用量变化的影响分析
研究流域的面源污染主要来源为化肥和农药,模拟化肥施用量减少后的污染负荷输出, 通过调整参数表格中与农药化肥累积、迁移有关的参数,对比调整前后水质成分的变化。 对于氨氮、总氮和总磷,将水质组分浓度表中每月的参数调为现状值的60%;BOD现状模拟结果较为接近地表Ⅰ类水标准,故调整为现状值的80%,运行模型后,输出结果显示水质满足地表Ⅰ类水标准,比水库现状的Ⅱ类水标准有所改善,因此,对应实际措施,施肥量减少为现状的60%能够对流域非点源污染的控制起一定作用。
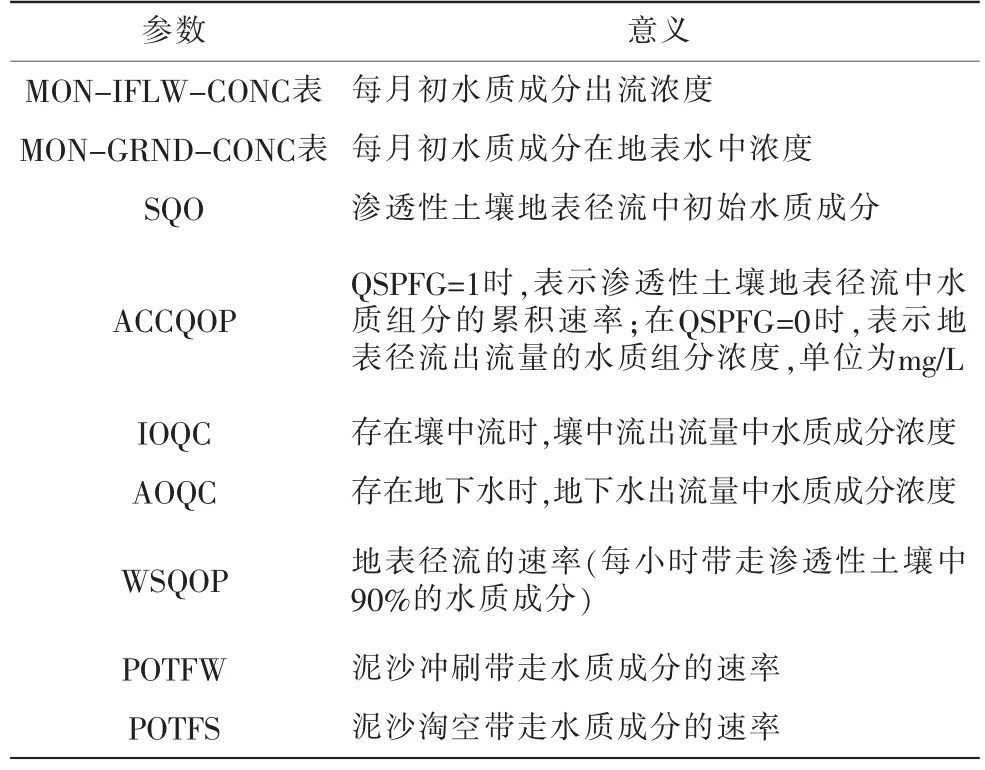
表2 可调整的水质参数及意义
综合以上研究过程,通过模型中参数的调整,不同情景下的水质过程模拟, 可以为流域管理规划提供决策依据、技术支撑与保障,在实际应用中制定限制纳污方案,从而削减流域内的非点源污染。
4 结语
采用BASINS系统下的PLOAD构建青龙河流域面源污染模型,在自动率定的基础上,通过人工调整关键参数,获得较为理想的模拟结果。 得出BOD、总氮、总磷在子流域中的分布情况,最严重的分别为子流域16和34, 污染程度较轻的子流域分别为6 和7。 并探讨了农药化肥施用量变化的影响,施肥量减少为现状的60%能够对流域非点源污染的控制起一定作用,使桃林口水库水质类别提升一级。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
中国水土保持(2022年6期)2022-06-08
环境工程技术学报(2022年3期)2022-06-05
资源信息与工程(2021年5期)2022-01-15
成都信息工程大学学报(2021年3期)2021-11-22
农业资源与环境学报(2021年4期)2021-07-30
建材发展导向(2021年10期)2021-07-16
林业科学研究(2021年3期)2021-07-11
当代体育科技(2020年26期)2020-11-17
上海医药(2020年19期)2020-10-30
