
人工智能在新药研发领域中的应用
2019-12-26 00:27:44孙雅婧李春漾曾筱茜
中国医药导报 2019年33期
孙雅婧 李春漾 曾筱茜
四川大学华西医院华西生物医学大数据中心,四川成都 610041
新药的研发基本可分为药物发现、临床前开发、临床研究和审批与上市四个阶段。随着产业革命第四次浪潮的来临,人工智能已经渗透至科学生活的各个方面,包括新药研发领域。研究者们希望通过人工智能技术的应用解决新药研发中研发周期漫长、研发成本高昂等常见问题。本文旨在综述人工智能多种技术在新药研发各阶段不同的应用,为人工智能在新药研发场景应用的前景做出分析,为该领域的科研技术人员开展相关研究提供参考。
1 新药研发的基本流程
随着现代生物医学理论的不断演进,现代生物技术的不断发展,药物发现在技术上又可以分为几个步骤:选择和确定药物作用的靶点、生物标记、确定先导化合物以及候选药物的确定等。临床前开发阶段以筛选活性化合物和研究构效关系为主,涵盖了药物的成药性分析、安全性评价和药物的吸收、分配、代谢、排泄和毒性等药物动力学指标评价等。临床研究阶段则以药物重定向、患者招募和临床试验为主,包含遴选用药方案、优化改进药效试验等。审批与上市阶段是政府药品主管机构和制药企业研发部门共同配合完成的最后阶段[1-2]。
通常情况下,制药公司会在药物开发上花费数千万到数亿美元[3-4],经历前述四个阶段共耗费超过10 年时间。然而能够通过漫长周期和重重考验并成功上市的药物,有研究者统计了2006~2015 年的新药研发数据,成功率仅为9.6%[5]。
虽然各大制药企业的销售额都在不同程度的增长,但远远赶不上研发成本的增长速度,在投资回报率下降的同时新药研发技术的成功率也在持续走低。不过随着智能研发新药等突破性技术的发展和成熟,这种下降趋势或将减缓。本文旨在关注新一代人工智能技术在药物研发过程的应用。
2 人工智能技术多环节介入新药研发
按照研发产业链的不同阶段进行划分,药物研发中人工智能应用有以下几类场景:
2.1 药物发现阶段
2.1.1 人工智能缩短科学发现药物靶点周期 在制药工业中,对许多不同的性能进行复合优化时,会收集大量的数据集。应用人工智能技术访问这种针对目标和非目标的大型数据集,系统地用于训练机器学习模型从而驱动数据集的预测属性,可以帮助研究者充分理解疾病机制,缩短靶点发现周期。利用不同方法预测激酶活性的研究就是一组很好的应用实例。在不同的激酶项目中,选择性分析可以生成更大的数据集,这些数据集再被系统地用于算法模型生成。研究者们从一个大而稀疏的数据矩阵中产生模块分析QSAR[6]、二元贝叶斯QSAR 模型,该矩阵包含作用于92 个不同激酶的13 万个化合物的数据。这些经过训练的模型被应用到新的化合物上,生成可以在较少的数据点上预测新激酶的生物活性亲和指纹图谱,再用新的实验数据迭代地改进模型,从而实现利用机器学习迭代的方法来发现新的激酶抑制剂。另外,有研究表明,随机森林模型可以成功地结合公开可用的数据集和内部数据集[7],为200 种以上不同的激酶推导出随机森林模型。DeepMind 近日研发的AlphaFold 工具能够成功预测43 种蛋白质中25 种3D 结构。人工智能应用于预测蛋白质折叠方式,将解决科学界最棘手的问题之一[8]。晶泰科技开发的“药物固相筛选与分析系统”基于人工智能技术的深度学习和认知计算能力,能够在短时间内通过对医学文献、临床试验数据等非结构化数据进行处理、学习和计算,预测各种晶型在稳定性、熔点、溶解度、溶出速率等方面的差异,以及由此而导致在临床过程中出现的副作用与安全性问题,在短时间内筛选出稳定性和溶解度最佳的晶型结构[9]。普林斯顿大学化学系和默克公司化学能力与筛选部的研究者们证明了机器学习可以利用高通量实验获得的数据来预测多维化学空间中合成反应的性能和化学反应的产率,有望在新药开发上得到广泛应用[10]。
2.1.2 候选分子的多维度复合优化选择 在药物发现中,临床候选分子必须满足一系列不同的标准:该化合物需要对生物靶标具有合适的潜力;具有较强的选择性用于对抗非预期靶标;表现出良好的理化性质和吸收、分布、代谢、排泄和毒性性质。为了有效地进行化合物设计,在模型的优化过程中应用了大量的计算机方法,特别是一些机器学习技术,如支持向量机[11]、随机森林[12-13]或贝叶斯学习[14]已经被成功应用。Cyclica开发并验证了一个名为“Ligand Express”的云计算蛋白质组学筛选平台(图1)。该平台发挥了生物物理学、生物数据和人工智能技术的组合效力,制药科学家正在积极利用它来更有效地探索药物发现的新途径。平台允许用户提交感兴趣的小分子,在人工智能、基于结构的分子模拟等技术辅助下通过使用云计算,不需要现场庞大的基础设施,只需要一台笔记本电脑、互联网接入和浏览器便可完成蛋白质组筛选[15]。中国科学院上海生命科学研究院陈洛南教授团队利用人工智能的方法确定了一套基于多维数据的复杂疾病的网络标志物及动态网络标志物筛选方法[16-17]。
2.2 临床前开发阶段
除了前文所述的一些潜在药物分子发现的过程外,临床前开发还关注药物的分子特性、水溶性、毒性、口服吸收潜力等方面的问题,人工智能技术也有部分应用。
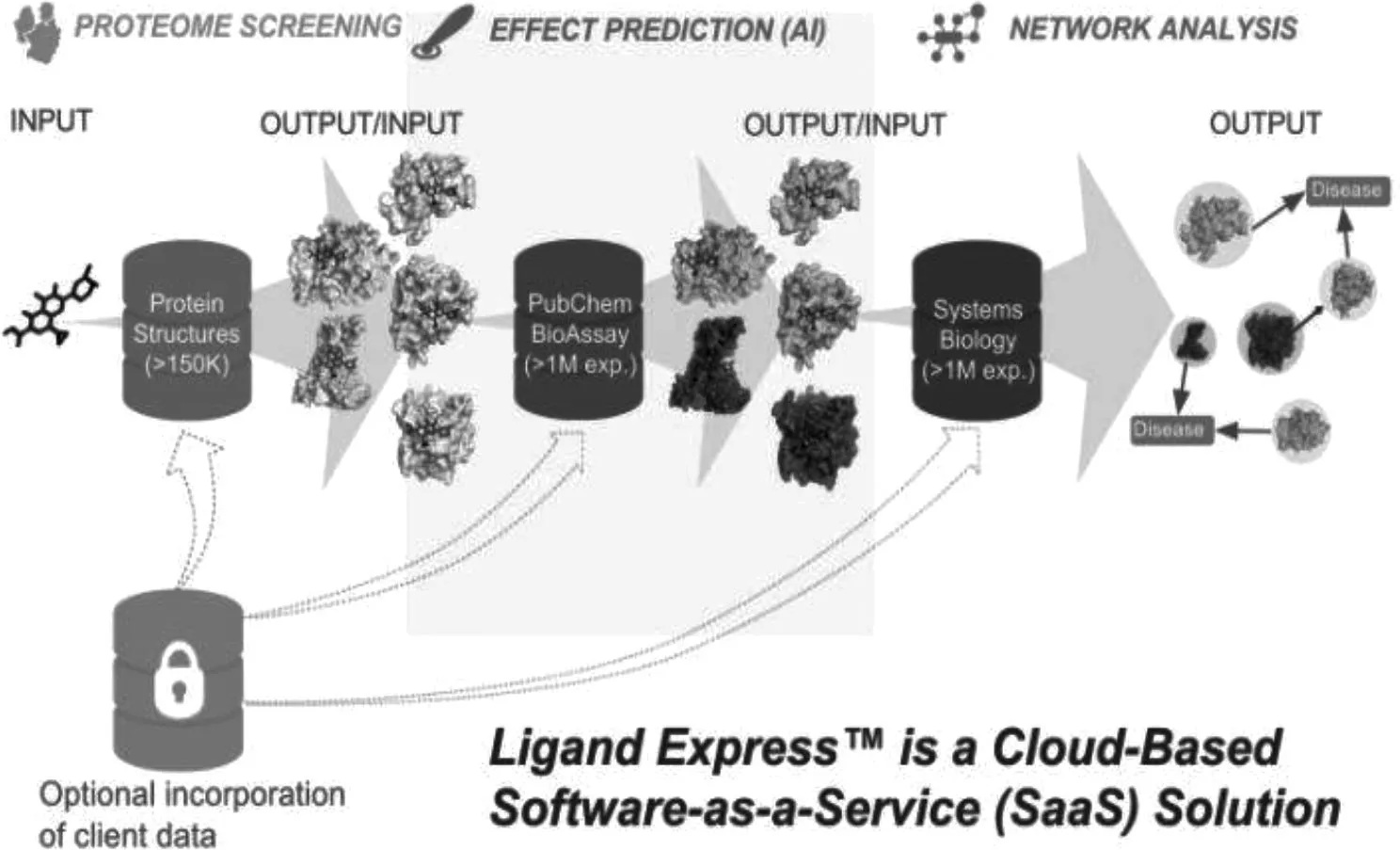
图1 Ligand Express 云计算平台(Cyclica 公司)
都柏林大学计算机科学与信息学院的研究者将浅层机器学习方法应用于化学信息学问题,并取得了一定的成功。研究利用深度学习方法,特别展示了递归神经网络方法如何应用于预测分子性质的问题。深度学习方法的应用在预测药物的水溶性,预测分子的作用位点,基因表达数据等方面发挥着作用[18]。
奥地利林茨大学生物信息学的研究发现深度学习在毒性预测方面优于其他许多计算方法,如朴素贝叶斯、支持向量机和随机森林。通过对包括1.2 万种环境化学品和药物专门设计检测方法来对12 种不同的毒性作用进行测量,结果评估了深度学习在计算毒性预测方面的表现。深度学习自然能够实现多任务学习,即在一个神经网络中学习所有的有毒效应,从而学习高信息量的化学特征[19]。
人结直肠癌细胞系(Caco-2)是一种常用的研究药物小肠吸收的体外模型,用于预测口服药物的吸收潜力。基于Caco-2 测定数据的计算机预测方法可以提高新药筛选的高通量有效性。然而,以前开发的预测化合物Caco-2 细胞渗透性的计算模型使用了手工制作的特征,这些特征可能是数据集特有的,并会导致过拟合问题。韩国研究者用深度神经网络(DNN)方法对原始特征进行非线性变换,生成高级特征,具有较高的判别能力,从而建立了良好的广义模型,设计出了一种基于DNN 的二进制Caco-2 渗透率分类器,纠正了过拟合问题和非线性激活问题。在预测Caco-2细胞系中不同结构化合物的细胞通透性时DNN 产生的高级特征发挥了更好的作用[20]。
2.3 临床研究阶段
2.3.1 药物重定向 老药新用是目前寻找药物的常用方式,它的实现方式是将市面上已曝光的药物及人身上的1 万多个靶点进行交叉研究及匹配。在公共领域,大数据集可以用来推导出预测跨目标活动的机器学习模型[21-24]。例如利用相似性集成方法,将与药物靶点已知配体二维结构相似性较高的化合物筛选后再做深入研究。这些模型可以应用于药物的再利用,为现有药物识别新的靶点。还有研究者利用电子病历数据检验了二甲双胍降低肿瘤患者的死亡率[25]。
2.3.2 患者招募 新药审批的必经之路是进行3 个阶段的临床试验,而临床试验顺利开展的基础是找到合适的临床患者。传统的试验管理人员通常是在海量的病例中逐一筛选并通知符合药物试验的受试者,费时费力。而依靠深度学习能力,人工智能技术能够从海量的病历中自动配对符合条件的患者,提高精准匹配效率,在短时内完成试验招募入组的基础工作[26]。
2.3.3 优化临床试验 临床试验阶段在药品研发过程中属于后期,一旦失败引起的成本损失巨大。最主要的失败原因是药物治疗靶点和疾病关联不佳引起。运用随机森林、支持向量机、梯度迭代增强、k 近邻算法等机器学习方法,对临床试验、动物模型、基因关联分析、通路分析、文本分析等数据进行挖掘,预测治疗靶点,有望提高后期临床试验的成功率。
同时试验方案设计、试验流程管理、试验数据管理统计分析等药物临床研究工作是繁琐而重要的环节。利用人工智能技术常用的机器学习和认知计算能力,应用到研究设计、流程管理、数据统计分析等诸多方面,可全面提升临床试验的效率[26]。
2.4 审批与上市阶段
主要集中在药物研发情报汇总领域,通过自然语言处理技术等完成海量文献和大型数据集的信息综合和汇总,为新药研发人员持续提供药物研发情报的药物研发信息数据库。汤森路透旗下的汤森路透知识产权与科技事业部开发的Thomson Reuters Integrity,PJB Publications LTD.旗下的Pharmaprojects,Venture Valuation VV AG(Swiss)开发的biotechgate 全球性生命科学数据库等等,国内包括药智、咸达、丁香园、米内、医药魔方、医药地理等纷纷在药品研发、生产检验、合理用药、市场信息方面建立综合数据库。例如北京大学医学部药品上市后安全性研究中心主要通过对国内主要类型电子医疗数据结构特点调查后使用医疗数据开展药物流行病学方法学研究,构建主动监测的数据通用模型,以糖尿病治疗药物安全性评价等具体临床项目为抓手制订相关药品上市后研究方法学指南,为药品上市后安全评价提供理论基础与科学依据[27]。
3 讨论与小结
人工智能技术的应用虽然在缩短研发周期、缩减新药研发成本上表现卓越,但与此同时也有许多局限性。
3.1 数据质量带来挑战
人工智能能够促进药物研发的某些阶段,但治疗靶点验证、药物测试和临床实验等,均需常规方法完成,仍然面临难度大、成本高、所需时间长等挑战。新药研发规则无法统一,数据结构性差,质量参差不齐。现有数据不明晰,甚至含有错误信息,而且充满了高度不确定性,尤其给以数据集为基础的深度学习技术的应用带来巨大挑战。
3.2 数据学习导致结果不确定性
人工智能模型基于数据学习,而非因果/规则推理。因此,相比人工智能应用的其他产业,药物研发不确定性大、试错成本高、周期长,因此国内涉足企业较少。新药研发是一个系统工程,生物系统也非常复杂,双重的不确定性导致人工智能在新药研发的各个阶段表现可能增加新药研发结果的不确定性。
3.3 数据信噪比不定
人工智能通过学习海量数据,找出非常多的相关性信息,但是数据信噪比不能确定。新知识新技术的产生,来源于人类的经验和实践对知识的创造性运用和判断处理,而不单单是全部知识的聚合连接。盲目追寻技术热点导致给相关性加分的实验数据和结论质量不明确,有可能产生误导性的结果。
3.4 缺乏优质数据库资源
将人工智能应用于药物研发,需要健康医疗、生物信息和药物化合物等优质数据支持,但国内缺乏整合的相关数据库,尤其是少见病、罕见病;药物结构数据库也有待进一步研究建设。人工智能技术的应用面临的困难和挑战虽然不少,但总体来看,在药物研发的未来世界中,利用经过验证的、相对可靠的虚拟化、人工智能化方法来评估药物成药性的各项指标,有望极大程度地降低失败率。人工智能在利用生物信息学方法开展疾病分子网络研究、发现治疗新靶点;人工智能运用对抗生成网络、强化网络等人工智能算法筛选先导物,并开发新的药物分子;结合计算机模拟,预测蛋白质特性和蛋白质—配体的相互作用,加速研发过程,降低研发成本;从海量论文中摄取所需的分子结构等信息,并且可以自主学习,建立其中的关联,提供新的思路和想法;结合生物数据库和个体数据,利用人工智能算法仿真,有助于发现已有药物的新适应证,促进老药新用;开发新型有效药物组合疗法,预测药物在不同亚组人群中的药代动力学、药效动力学指标及临床应用的安全性、有效性,提高现有药物的使用质效,实现个体化、精准化治疗等方面均有进展。
通过前述方法,人工智能应用于新药研发可以大大缩短筛选候选药物分子的时间,节约研发成本。目前仍处在人工智能辅助新药开发的验证阶段,让人工智能技术驱动对接整个药物研发始终,至少需要5 年的时间。但是那些较早开始采用人工智能的制药公司有可能随时间发展获得更大的收益。
猜你喜欢
中老年保健(2021年3期)2021-12-03 02:32:25
中国生殖健康(2020年7期)2020-12-10 07:48:51
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南风窗(2016年19期)2016-09-21 16:51:29
转化医学电子杂志(2015年4期)2015-12-27 12:17:04
医学研究杂志(2015年7期)2015-06-22 11:01:36
创业家(2015年9期)2015-02-27 07:54:33
创业家(2015年9期)2015-02-27 07:54:27
