
采用注意力门控卷积网络模型的目标情感分析
2019-12-24 06:23曹卫东李嘉琪王怀超
西安电子科技大学学报 2019年6期
曹卫东,李嘉琪,王怀超
(中国民航大学计算机科学与技术学院,天津300300)
目标情感分析[1-3]是对给定文本中每个目标实体提及的情感极性进行分类,是目前的研究热点。该目标实体存在于给定的文本中,一个文本可以有多个目标实体。目标情感分析是一种细粒度的情感分类任务,当文本中的多个实体有不同的情感极性时,它能够针对文本中的某一实体进行情感极性的分类。例如,“我买了一个手机,外观漂亮,但电池寿命较短”。这里有两个目标实体,外观和电池。目标实体“外观”对应的情感极性是积极的,而“电池”是消极的。如果不考虑特定实体,则难以得出文本对应的正确语义。
目标情感分析通常采用基于循环神经网络的模型,即长短期记忆网络和注意力机制相结合的模型。这类模型分类效果较好,受广大学者欢迎。文献[4]中提出的循环注意力网络(RAM)模型将多跳注意力的结果与双向长短期记忆网络非线性组合,增强了模型的表示性,以此更好地捕捉情感特征。文献[5]中提出的深度记忆网络(MemNet)模型引入了深度存储器网络,捕获关于给定目标词的每个上下文单词,建立了更高的语义信息。这类循环神经网络模型将复杂的循环神经网络作为序列编码来计算文本的隐藏语义,具有很强的表示性。但是循环神经网络模型难以并行化,导致模型收敛时间长。
除了循环神经网络模型可用于解决情感分析外,还存在很多优异的可替代循环神经网络模型的方法[6-8]。这类方法大多可并行计算,缩短收敛时间。文献[9]中提出的带有方面词嵌入的门控卷积网络(GCAE)模型采用卷积神经网络和门控机制,有效地选择给定目标词的文本特征,且该模型可并行计算,提升了训练速度,同时也获得了比较好的分类效果。文献[10]中将目标词通过双向循环神经网络后,利用卷积神经网络提取显著的特征。然而,这些模型通常未考虑上下文和目标词之间的交互,无法充分利用目标词和上下文词之间的关系。因此,该类模型未能很好地提取目标词关于上下文词的情感特征。
基于此,笔者提出了一种既能提高准确率,又能缩短收敛时间的注意力门控卷积网络(Attention Gated Convolutional Network,AGCN)模型。该模型将上下文和目标词通过多头注意力交互,以充分提取特征,利用门控卷积机制进一步捕获与目标词有关的情感特征,在一定程度上提升了准确率,降低了收敛时间。
1 注意力门控卷积网络模型
1.1 模型定义

图1 注意力门控卷积网络模型框架图
对于长度为n的句子s={x1,x2,…,xn},xi为句子的第i个词向量。给定的上下文词序列Xc={xc1,xc2,…,xcn},目标词序列Xt={xt1,xt2,…,xtm}。基于目标的情感分析任务是根据给定的目标词,得出上下文对应的情感极性。
为了更好地提取关于目标的情感特征,实现细粒度的情感分类,笔者提出了一种用于目标情感分析的注意力门控卷积网络模型。该模型由5层构成,分别为输入层、注意力层、门控卷积层、最大池化层和输出层。模型框架如图1所示。
1.2 输入层
文中的输入为上下文词向量和对应的目标词向量。将两者分别作为输入,提取上下文词关于目标词的情感特征。
GloVe是一个基于全局词频统计的词表示模型[11],将单词转化为词向量。利用预训练好的GloVe,得出词向量矩阵MRd×|V|。其中,d是词向量维度,|V|是词典大小。
1.3 注意力层
笔者将交互式的上下文和目标词通过多头注意力机制[12],充分提取情感特征和基于目标的情感特征。
将键序列k={k1,k2,…,kn}映射到查询序列q={q1,q2,…,qm},得到一次输出,通过多次计算,将多次结果拼接得到最终输出。
各个单词加权平均后得到的一次注意力函数如下:
fatt=S(s)·k,
(1)
其中,S表示softmax函数,s表示ki和qj的语义相似度。s的公式如下:
s=tanh([ki;qj]·Ws) ,
(2)
其中,WsR2d,Ws是模型的训练参数。
将h次的注意力表示进行拼接,输出为
fmha=[fatt1;fatt2;…;fatth]·Wmha,
(3)
其中,WmhaRd×d。
上下文间感知词嵌入建模(Intra-MHA)是将相同的上下文词序列作为输入,即k=q。由上下文词向量xc可得出上下文间感知词嵌入建模表示c=[c1,c2,…,cn]:
c=fmha(xc,xc)。
(4)
上下文交互目标词建模(Inter-MHA)是将上下文词序列和目标词序列分别作为输入,即k≠q。由上下文词向量xc和对应的目标词向量xt可得出上下文交互目标词建模表示t=[t1,t2,…,tm]:
t=fmha(xc,xt) 。
(5)
1.4 门控卷积层
卷积神经网络已被广泛应用于图像[13]和情感分析领域[14]。将卷积神经网络和门控机制用于情感分类,可以并行计算且选择性地输出情感特征,获得良好的分类效果。该层的输入为c和t,输入的最大长度为n。将nk个尺寸不同的卷积核k与词向量进行卷积,经过门控机制得出情感特征oi,以实现对文本的局部感知,从而更好地提取局部特征。
卷积过程包含两部分,带有目标词的上下文词表示ai和上下文词表示ui。公式如下:
ai=frelu(ci:i+k*Wa+vaVa+ba) ,
(6)
其中,frelu是relu激活函数,WaRd×k,ba是偏置。ai用于生成带有目标词的情感特征,控制情感特征的传播。
vj=frelu(tj:j+k*Wv+bv) ,
(7)
其中,WvRd×k,bv是偏置。vj通过最大池化得到va。
ui=ftanh(ci:i+k*Wu+bu) ,
(8)
其中,ftanh是tanh激活函数,WuRd×k,bu是偏置。ui用于生成情感特征。
在t位置处,计算的情感特征oi为
oi=ui*ai。
(9)
1.5 模型训练
笔者利用反向传播算法,通过最小化交叉熵损失函数来训练和更新注意力门控卷积网络模型,以此选择最优的模型参数,得出关于目标的情感分类。采用的交叉熵损失函数为
(10)
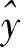
2 实验与分析
2.1 实验环境及配置
文中实验环境如下:操作系统为Windows 10,处理器为i7-6700,内存大小为16 GB,显存为GTX1060 6 GB,开发语言是Python 3.6,采用的深度学习框架为Pytorch。
2.2 实验数据
文中的数据来源于SemEval 2014任务四的餐厅和笔记本电脑评论。每条数据包括评论、目标词和目标词对应的情感极性。其中,情感极性有积极、中性和消极3种标签。数据集和数据信息统计如表1所示。

表1 数据集统计
2.3 实验参数设置
在本实验中,为了保证两个数据集能得出好的实验效果,分别对其采用不同的参数设置。为了得到相对稳定的实验结果,本组实验分别重复进行了50次。具体参数设置如表2所示。

表2 参数设置
2.4 实验结果与分析
为了验证文中提出的注意力门控卷积网络模型对目标情感分析的有效性,在SemEval 2014任务四的餐厅和笔记本电脑数据集上进行实验,与循环神经网络模型和非循环神经网络模型进行对比。其中,循环神经网络模型有目标依赖的长短期记忆网络(TD-LSTM)、基于注意力的长短期记忆网络(ATAE-LSTM)、交互注意力网络(IAN)和循环注意力网络模型,非循环神经网络模型有深度记忆网络、带有方面词嵌入的门控卷积网络和注意力编码网络(AEN-GloVe)模型。
2.4.1 与基准方法的准确率对比实验
本组实验是为了验证注意力门控卷积网络模型在提高准确率方面的有效性。为了保证实验结果的准确性,在本组实验中,带有方面词嵌入的门控卷积网络模型和注意力门控卷积网络模型的准确率值由文中的实验环境运行得出,其他的实验结果均来自于对应的论文。各模型准确率的实验结果如表3所示。

表3 准确率结果对比
从实验结果可以看出,相比于其他基线模型,笔者提出的注意力门控卷积网络模型在两个数据集上均得到了最高的准确率。其中,在餐厅评论数据集上,注意力门控卷积网络模型的准确率有明显的提高,准确率约高达81.52%;在笔记本电脑评论数据集上的准确率也有一定的提升,准确率约达到了74.61%。
在循环神经网络模型中,TD-LSTM模型表现最差,因为该神经网络模型只对目标词进行粗略处理,未能实现良好的情感分类,因此准确率较低。ATAE-LSTM、IAN和RAM模型分别都在长短期记忆网络后增加了注意力机制,在餐厅评论数据集上的准确率分别约比TD-LSTM模型高了1.57%、2.97%和4.60%。加入了注意力机制的模型可以更好地提取重要的特征,从而验证了注意力机制的有效性。IAN模型表现一般,因为它只是将文本和目标词交互学习注意力。而文中的注意力门控卷积网络模型在交互注意力后,通过了门控卷积机制,进一步提取有效的情感特征,比IAN模型在餐厅数据上的准确率约提高了2.92%,从而验证了门控卷积机制的有效性。RAM模型比其他循环神经网络模型表现优异,它利用长短期记忆网络和多跳注意力机制捕捉情感特征,增强了模型的表示能力,文中的注意力门控卷积网络模型的准确率在餐厅数据上比RAM模型约高了1.29%,验证了文中模型的有效性。
在非循环神经网络模型中,MemNet模型表现一般,因为它没有模拟嵌入的隐藏语义,最后一次关注的结果本质上是单词嵌入的线性组合,弱化了模型的表示能力。而文中的注意力门控卷积网络模型中的门控卷积机制将多头注意力的结果非线性地结合起来,能够进一步加强模型的表示能力,同时还可以生成和选择性地输出情感特征,从而获得更好的分类效果,进一步验证了门控卷积机制的有效性。AEN-GloVe模型在餐厅数据上表现优异,准确率约达到了80.98%,但是在笔记本电脑数据上表现一般,准确率约为73.51%。相较于文中模型,GCAE模型没有交互式的上下文和目标词,未能获得较好的情感特征。文中的注意力门控卷积网络模型比GCAE模型在餐厅评论数据集上的准确率约提高了2.06%,由此验证了笔者将上下文词向量和对应的目标词向量作为输入进行多头注意力交互的有效性。
2.4.2 与基准方法的收敛时间对比实验
本组实验是为了验证注意力门控卷积网络模型在缩短收敛时间方面的有效性。为了保证收敛时间的一致性,本组的实验数据均由文中实验环境运行得出。本组实验在餐厅评论数据集上进行,通过实验,记录各自模型的收敛时间。其中,收敛时间是各模型的测试集在准确率得到最高时的迭代次数所消耗的时间。各模型收敛时间的实验结果如表4所示。
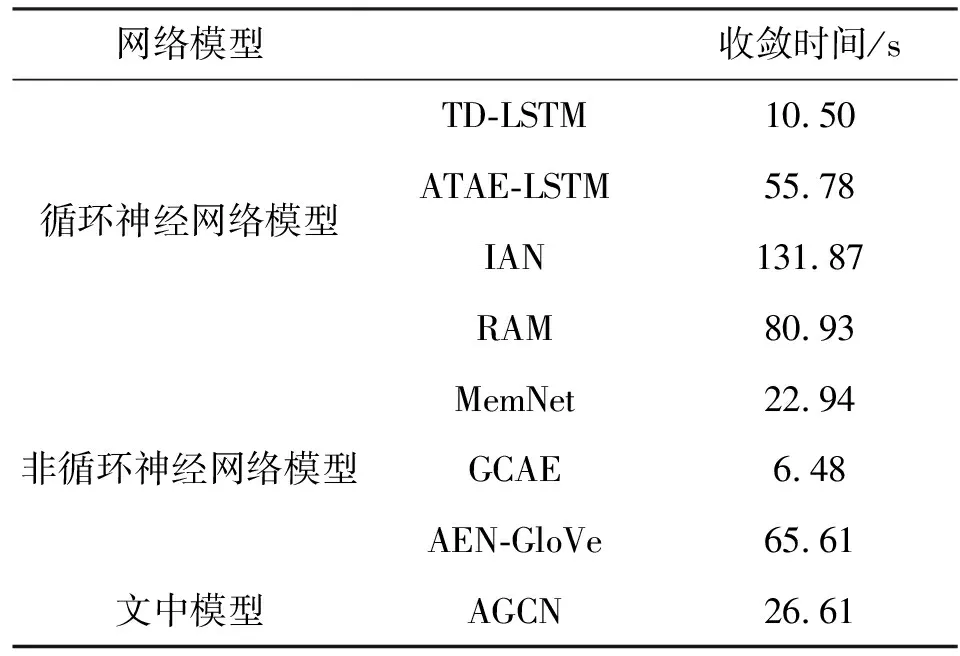
表4 收敛时间结果对比
从表4中容易看出,文中的注意力门控卷积网络模型与循环神经网络模型相比,在很大程度上缩短了收敛时间;与非循环神经网络模型相比,比AEN-GloVe模型的收敛时间短,但是比MemNet和GCAE模型的收敛时间长。
在循环神经网络模型中,TD-LSTM模型的收敛时间最短,该模型虽然收敛时间短,但准确率相对较低。其他基于长短期记忆网络和注意力机制模型的收敛时间较长,因为长短期记忆网络不能并行化,且注意力机制中计算权重时消耗较多时间。与其他循环神经网络模型收敛时间相比,文中的注意力门控卷积网络模型收敛速度最快,分别比ATAE-LSTM、IAN和RAM模型的收敛时间降低了29.17 s、105.26 s和54.32 s。在注意力门控卷积网络模型中,卷积门控机制可以并行计算,大大缩短了收敛时间,从而验证了门控卷积机制的有效性。
在非循环神经网络模型中,AEN-GloVe模型的收敛时间最长,该模型利用了两层注意力机制,而注意力机制在计算权重时需要消耗大量时间,因此收敛时间长。注意力门控卷积网络模型比MemNet和GCAE模型的收敛时间长,GCAE模型的收敛时间最短。MemNet和注意力门控卷积网络模型的收敛时间相差不大。与GCAE模型相比,注意力门控卷积网络模型比GCAE模型多增加了交互式的注意力机制层,该层延长了模型的收敛时间,虽然收敛时间增加了,但是交互注意力机制使得注意力门控卷积网络模型的准确率得到了提升,总体效果表现良好。
2.4.3 网络参数对情感分类的影响

图2 不同优化器对比实验结果
网络参数对模型的分类效果有很大的影响,因此对不同的数据集采用合适的网络参数是非常必要的。为了验证网络参数对实验的影响,本组进行了一组实验,针对餐厅和笔记本电脑数据,在优化函数上进行对比实验,观察优化函数对注意力门控卷积网络模型的影响。本组实验各重复了20次,每次实验迭代20次。不同的数据集适用的优化函数不同,本组实验采用的优化函数分别为自适应矩估计(Adam)、自适应梯度下降(AdaGrad)和随机梯度下降(SGD)。实验结果如图2所示。
由图2可知,当自适应梯度下降为优化器时,文中的注意力门控卷积网络模型在餐厅数据上可以实现最高的准确率;当自适应矩估计为优化器时,在笔记本电脑数据上有最好的分类效果;随机梯度下降优化器在两个数据集上没有表现出良好的效果。自适应梯度下降和自适应矩估计优化器可以自适应学习,都较适用于稀疏数据。两者相比,自适应矩估计优化器更适合较为稀疏的数据。笔记本电脑数据集比餐厅数据集稀疏,因此在笔记本电脑数据集上,自适应矩估计优化器有优异的表现,而在餐厅数据集上,自适应梯度下降优化器表现良好。随机梯度下降优化器不能自适应学习,在稀疏数据中的表现不如自适应梯度下降和自适应矩估计优化器。
3 结束语
笔者提出了一种注意力门控卷积网络模型,用于解决目标情感分析。该模型将上下文和目标词嵌入作为输入进行多头注意力交互,利用上下文和目标词之间的交互来充分提取关于目标词的情感特征,提升了模型的准确率。并采用门控卷积机制提取与目标词有关的情感特征,不仅进一步提高了准确率,还解决了循环神经网络模型收敛时间长的问题。采用SemEval 2014任务四数据的实验结果验证了该模型在目标情感分析领域不仅能够提高目标情感分类的准确率,而且还能缩短收敛时间,在目标情感分析领域方面有重要的应用价值。值得注意的是,在收敛时间上,笔者提出的模型比非循环神经网络模型中的深度记忆网络模型和带有方面词嵌入的门控卷积网络模型的收敛时间长。因此,未来的研究方向将致力于建立一个准确率高且收敛时间快的模型。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
