
一种利用资源协商的FPGA布局方法
2019-12-24 06:23王德奎
西安电子科技大学学报 2019年6期
王德奎
(西安电子科技大学计算机科学与技术学院,陕西西安710071)
随着现场可编程门阵列(Field Programmable Gate Arrays,FPGA)和电路规模的增大,计算机辅助设计工具在对电路进行编译并配置到芯片时需要耗费更多的时间。对于现代大规模工业电路,现有的计算机辅助设计工具耗时几个小时甚至一到两天[1]。由于电路编译耗时的增大,电路的设计调试周期也随之变长,从而降低电路设计人员的开发效率以及现场可编程门阵列在市场上的竞争力。因此,减少电路编译所需时间,已经成为开发人员当今主要研究方向之一。
现场可编程门阵列电路的设计流程包括行为综合、工艺映射、打包、布局和布线,其中布局是最耗时的步骤之一[2]。目前,学术界权威的多用途布局布线工具(Versatile Place and Route,VPR)[3]在布局阶段采用模拟退火算法,通过搜索大量的布局解空间并以一定的概率接受较差的解,最终找到一个较优布局方案。但模拟退火布局算法运行时间长,随着电路规模的增大,该缺点越来越明显。文献[4]采用并行编程技术将多用途布局布线工具模拟退火布局算法并行化,时间减少37.5%,同时电路延时降低4.2%。文献[5]将遗传算法应用到现场可编程门阵列布局,并用布线器代替目标评价函数;和多用途布局布线工具相比,电路延时降低8.4%,但布局运行时间增加了2 887倍。文献[6]提出了基于划分的布局算法,采用递归划分将电路逻辑单元划分到现场可编程门阵列上不同的区域,直到每个区域中的逻辑单元数量小于设定的阈值。和多用途布局布线工具相比,划分布局方法可以取得较高的加速比,但是布局质量较差。文献[7-9]中提出的解析布局算法将布局优化目标函数近似成连续可导函数,并采用现有的求解器对目标函数求最小值,从而得到全局最优布局方案。解析布局算法耗时远小于模拟退火算法,但在将优化目标函数近似成连续可导函数时会存在误差;另外,解析布局算法往往只能对一个优化目标进行优化,无法同时对多个目标进行优化,目前常见的解析布局算法都是对电路总线长进行优化,而不考虑电路的延时。
为了避免上述方法的不足并提高布局的效率,笔者提出了新的利用资源协商的迭代布局方法,电路单元通过协商确定物理资源的分配使用;同时,利用低温模拟退火算法对布局结果进行局部优化。实验结果表明,所提出的布局方法能够在保证布局质量的前提下显著减少布局所需时间。
1 基础知识
1.1 现场可编程门阵列结构
现场可编程门阵列已经广泛应用于现代数字系统设计[10-12]。根据内部资源结构,目前商用现场可编程门阵列主要分为两类:岛型结构和层次化结构;多用途布局布线工具和赛灵思公司均采用岛型结构[13]。如图1所示,岛型结构由3部分构成:输入输出单元、可配置逻辑单元和可编程连线资源。输入输出单元分布在四周,是芯片和外围电路的接口;目前大多数现场可编程门阵列在内部嵌入数字信号处理器等异构功能单元来扩大芯片的灵活性。

图1 简单岛型现场可编程门阵列结构

图2 打包后的电路网表
1.2 现场可编程门阵列电路布局
用硬件描述语言设计的电路经过行为综合、工艺映射、打包后转化为电路网表〈V,E〉。电路网表由逻辑单元和单元之间的连接构成,其中V表示逻辑单元集合,E表示逻辑单元之间连接的集合。图2为打包后的电路网表,该电路网表中共有9个逻辑单元:V={vi| 0 ≤i< 9}, 其中v5、v6、v7和v8为可配置逻辑单元,其余为输入输出单元。图2中各逻辑单元之间有向连接构成的集合为:E={〈v0,v5〉, 〈v1,v7〉, 〈v1,v6〉, 〈v2,v6〉, 〈v5,v7〉, 〈v6,v8〉, 〈v7,v8〉, 〈v7,v3〉, 〈v8,v4〉},其中〈v0,v5〉表示从v0到v5的连接。
现场可编程门阵列布局就是根据相应的约束条件,确定电路网表中的各逻辑单元在物理芯片上的位置,每个位置坐标都对应唯一的可编程物理逻辑单元。布局是多目标优化问题,优化目标主要包括:(1)使电路中所有连接使用的连线资源总线长尽量短;(2)使电路的延时尽量小。
2 提出的布局方法
所提出的布局方法分为3个阶段:(1)初始布局:为电路逻辑单元计算花费最小且类型相同的物理模块资源,如果一个物理资源被多个逻辑单元同时占用,则称该资源发生拥挤;(2)资源协商布局:迭代地对占用拥挤物理资源的逻辑单元重新布局,直到消除资源拥挤;(3)低温模拟退火优化:采用低温模拟退火算法对布局结果进行优化。下面详细介绍各布局阶段,以及布局过程中用到的资源花费计算函数。
2.1 电路时序分析
通过对电路进行时序分析,可以得到电路的延时和各连接的关键度。电路中延时最长的路径称为关键路径,关键路径延时决定了电路延时。对于连接
(1)
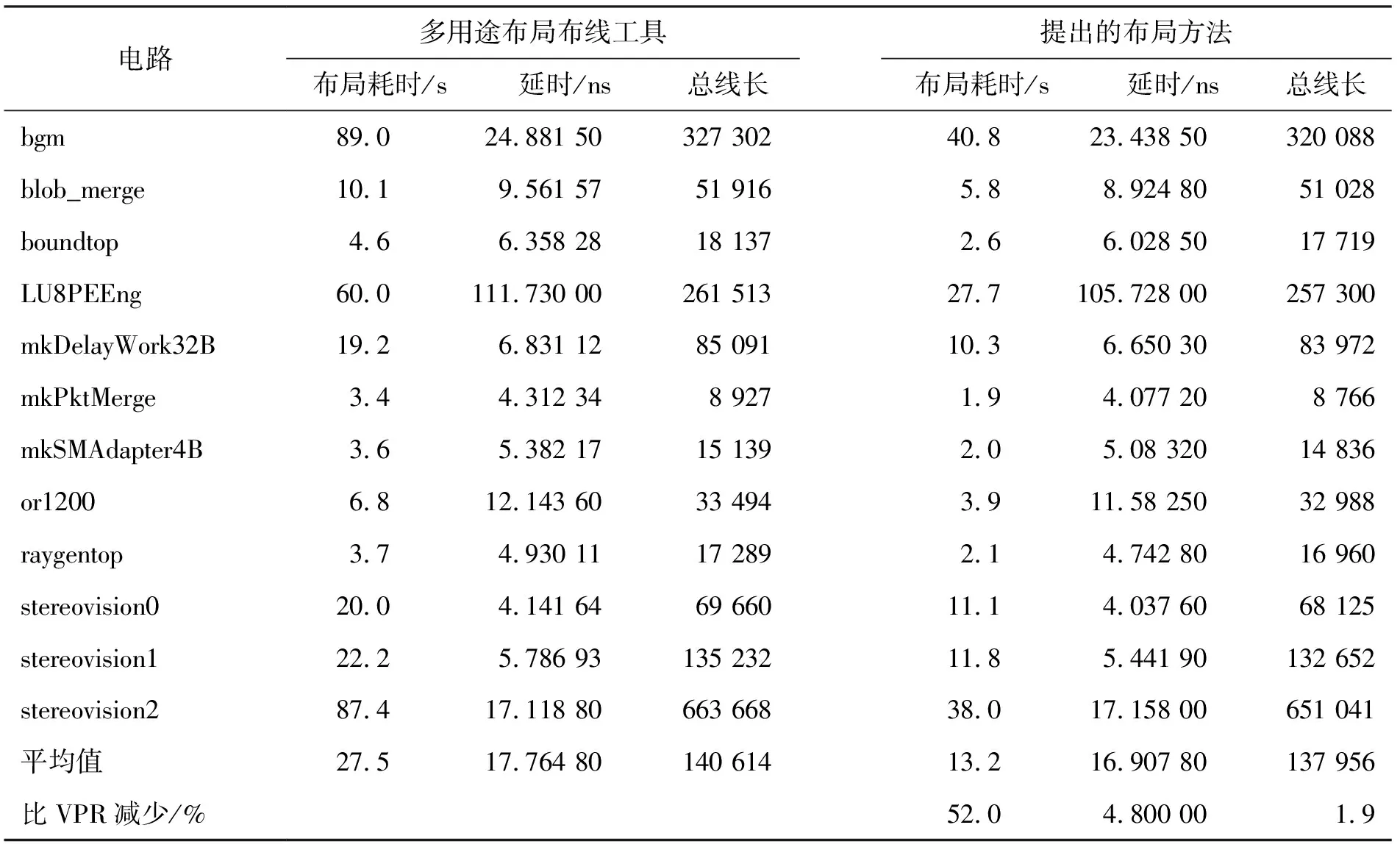
其中,D是关键路径延时,As,t表示在不影响关键路径前提下连接 λb=max{βb,i} , 1≤i≤Nb, (2) 其中,Nb表示连到逻辑单元b的连接的数量,βb,i表示连到b的第i个连接的关键度。 当逻辑单元b使用坐标为(x,y)的资源时,使用花费包括时序花费和资源拥挤花费,计算方式为 C(b,x,y)=λb·Tb+(1-λb)·Gx,y, (3) 其中,Tb表示逻辑单元b占用资源(x,y)的时序花费,Gx, y为资源(x,y)的拥挤花费。λb是逻辑单元b的关键度且0 <λb≤ 1,通过λb来平衡资源拥挤花费和时需花费占总花费的比重;λb值越大,时序花费占总花费的比例越高。逻辑单元b使用资源(x,y)的时序花费Tb计算方法为 (4) 其中,βb,i和db,i分别表示连到逻辑单元b的第i个连接的关键度和延时;zb表示和b相连且已经布局的逻辑单元数目。物理资源(x,y)的拥挤花费包括该资源的当前拥挤和历史拥挤成本,计算方法为 Gx,y=α·px,y·hx,y, (5) 其中px,y和hx,y分别表示资源(x,y)的当前拥挤成本和历史拥挤成本,α为资源基本花费。由于px,y和hx,y均大于或等于1,而延时花费的数量级为10-9;通过将α的值设为1.3×10-9,从而使式(3)中Tb和Gx, y保持在基本相同的数量级上。px,y和hx,y的计算方法为 (6) (7) 其中,ex,y表示资源(x,y)的容量,即该资源可以被多少逻辑单元同时使用;ux,y为占用资源(x,y)的逻辑单元数量;ε和σ分别为当前和历史惩罚因子,初始值均为1。根据式(6)和(7),占用资源(x,y)的逻辑单元越多,px,y的值越大;随着资源(x,y)发生拥挤的次数越多,hx,y的值越大,hx,y初始值为1。 初始布局为电路中每个逻辑单元计算花费最小的物理资源,具体步骤如下: (1)对电路进行时序分析,并根据关键度对逻辑单元降序排序,变量i= 1; (2)随机选择现场可编程门阵列上和第i个逻辑单元bi类型相同的物理资源,该资源的坐标记为(xi,yi); (3)计算以(xi,yi)为中心、向外扩展r个长度单位的边界盒范围,其中一个可配置逻辑单元的长度为一个长度单位;r的值为max{0.25×W, 0.25×H, 2},其中W、H分别表示现场可编程门阵列的长和宽;系数0.25为实验值,可以较好地平衡布局耗时和电路质量; (4)根据式(3)计算边界盒内所有和bi类型相同的物理资源的使用花费,将花费最小的物理资源分配给逻辑单元bi,并根据式(6)更新bi所占资源的当前拥挤成本; (5)如果所有的逻辑单元都完成布局,则根据式(7)更新所有物理资源的历史拥挤花费,以及所有连接的延时,并对电路进行时序分析,初始布局结束;否则,i++,转步骤(2)继续执行。 在资源协商布局阶段,迭代地对占用拥挤资源的电路逻辑单元重新布局,随着迭代次数增加,逐渐增大拥挤物理资源的使用成本,最终消除资源拥挤并得到合法的布局结果。资源协商布局的具体步骤如下: (1)逻辑单元总数记为N,根据关键度对逻辑单元降序排序,变量i= 1,集合M置为空集。 (2)第i个逻辑单元bi所占用的物理资源的坐标记为(xi,yi),判断资源(xi,yi)是否同时被其它逻辑单元占用着,即该资源是否发生拥挤。若资源(xi,yi)发生拥挤,则转步骤(3);否则,转步骤(5)。 (3)将bi添加到集合M,并计算以(xi,yi)为中心、向外扩展r个长度单位的边界盒范围,r的值为max{λ×W,λ×H, 2},为了平衡布局耗时和电路质量,通过实验测试将λ值设为0.25。 (4)根据式(3)计算边界盒内所有和bi类型相同的物理资源的使用花费,并将花费最小的物理资源分配给逻辑单元bi,并更新资源(xi,yi)和bi当前所占资源的当前拥挤成本。 (5)如果i等于N,则完成对所有逻辑单元的遍历,转步骤(6);否则,i++,转步骤(2)执行。 (6)更新所有和集合M中逻辑单元相连的连接的延时,并对布局后的电路进行时序分析。 (7)如果布局结果中存在拥挤的物理资源,则更新资源的历史拥挤花费,当前拥挤惩罚因子乘以f,转步骤(1)继续执行;否则,布局结果合法,资源协商布局结束。通过实验发现,f的值越大,所需布局迭代次数越少,电路布局质量质量越差。当f> 1.3时,电路平均布局迭代次数下降速度逐渐变慢;当f> 1.55时,电路延时随f的增大而逐渐恶化。为了平衡布局时间和电路布局质量,将f的值设为1.3。 资源协商布局后,调用低温模拟退火算法对所得到的布局结果进行局部优化,具体步骤如下: (1)逻辑单元总数记为N,变量i= 1; (2)随机选择一个逻辑单元,记为bi;变量j= 1; (3)随机选择和bi类型相同的物理单元,坐标记为(xj,yj);如果该物理单元已被别的逻辑单元占用,则交换该逻辑单元和bi的位置;否则,将bi移动到(xj,yj)位置; (4)计算移动逻辑单元bi后的布局质量,如果移动bi后的布局结果质量更好,则接受移动bi后的布局结果;否则将bi移动到之前的位置; (5)如果变量j (6)如果i 为了验证新的布局方法在运行时间和布局质量方面的性能,用多用途布局布线工具标准测试电路进行测试,并和现有布局方法进行比较。实验环境为一台惠普工作站,硬件包括一颗Xeon X5550处理器、12 G内存和1 TB硬盘;系统为64位Ubuntu操作系统。分别使用工艺映射工具ABC和VPR对测试电路进行工艺映射和打包;芯片模型使用多用途布局布线工具自带的结构描述文件k6_N10_mem32K_40nm.xml。 使用多用途布局布线工具标准电路分别对提出的布局方法和多用途布局布线工具进行测试,每组数据测试10遍取平均值。从布局耗时、电路的延时和总线长三方面对提出的布局方法和多用途布局布线工具进行比较。电路测试结果如表1所示。 表1 提出的布局方法与多用途布局布线工具的比较 根据表1中的数据,多用途布局布线工具布局耗时的平均值为27.5 s,所提出的布局方法平均只需要13.2 s;相比于多用途布局布线工具,提出的布局方法所需时间平均减少52%。对于规模最大的3个电路bgm、LU8PEEng和stereovision2,多用途布局布线工具布局时间均大于50 s,提出的布局方法的布局时间分别减少54.2%、53.8%和56.5%;对于多用途布局布线工具布局时间小于10 s的电路boundtop、mkPktMerge、mkSMAdapter4B、or1200和raygentop,所提出的布局算法将布局时间分别减少了43.5%、44.1%、44.4%、42.6%和43.2%,均小于平均值52%。可以看到,电路规模越大,和多用途布局布线工具相比所提出的布局方法布局效率越高。接下来比较布局的质量:多用途布局布线工具布局后电路平均延时和总线长分别为17.764 8 ns和140 614;和多用途布局布线工具相比,提出的布局方法的延时和总线长分别优化了4.8%和1.9%。表1的数据表明,提出的布局方法布局所需时间少于多用途布局布线工具,同时布局结果质量优于多用途布局布线工具。 由于文献[4-5]中的工具均未开放源代码,无法对文献[4-5]中的算法进行测试。而文献[4-5]均通过和多用途布局布线工具进行比较来验证算法的性能。因此,可以将新的布局方法与多用途布局布线工具的比较结果和文献[4-5]与多用途布局布线工具的比较结果进行比较,结果如表2所示。 表2 提出的布局方法和现有方法的比较 文献[4]采用并行化布局算法,和多用途布局布线工具相比布局时间减少37.5%,延时减小4.2%。文献[5]将遗传算法应用到现场可编程门阵列布局,电路延时减小8.4%,但布局时间增加了2 887倍。另外,文献[4-5]都没有比较电路的总线长。比较表2中数据可得:所提的布局方法的时间成本和布局质量均优于文献[4]中的算法;虽然文献[5]的延时优于所提的布局方法,但耗时远大于所提的布局方法,而且没有比较布局电路的总线长。 在初始布局阶段,在允许资源重用的情况下为每个电路逻辑单元选择最优的布局,得到一个质量较优的布局结果;在资源协商布局阶段,迭代地对占用拥挤资源的逻辑单元重新布局;随着迭代次数增加,拥挤资源逐渐减少,避免了传统模拟退火布局算法在每次布局迭代中陷入海量搜索空间的局限性。实验结果表明,提出的布局方法的耗时和布局结果质量优于同类工具,有助于提高现场可编程门阵列电路开发效率。2.2 花费计算函数
2.3 初始布局
2.4 资源协商布局
2.5 低温模拟退火布局
3 实验与比较
3.1 所提出的布局方法和多用途布局布线工具的比较
3.2 与现有布局方法的比较

4 结束语
猜你喜欢
影像视觉(2021年3期)2021-03-24小学生学习指导(中年级)(2020年12期)2020-12-04家庭影院技术(2020年2期)2020-03-25船舶标准化工程师(2019年4期)2019-07-24通信电源技术(2018年3期)2018-06-26太空探索(2016年7期)2016-07-10足球周刊(2014年20期)2014-07-03智能建筑与智慧城市(2012年12期)2012-08-15中学英语园地·教学指导版(2008年3期)2008-07-15航空知识(2000年8期)2000-06-07
