
WSNs中基于分布式学习机的稳定路由
2019-12-23 08:34:14宋海军
中国电子科学研究院学报 2019年10期
宋海军
(中国民航飞行学院,四川 广汉 618307)
0 引 言
无线传感网络(Wireless Sensor Networks, WSNs)由微型、具有感知和通信能力的节点组成。通过这些节点监测兴趣区域环境数据,如温度、湿度,或检测区域内异常事件,再将这感知数据传输至信宿,进而实现对环境监测目的,如森林防火监测。
WSNs内的节点不仅感知数据,还需传输或协助其他节点向信宿传输数据[2]。而传输数据消耗了节点的大部分能量。然而,节点通常由电池供电,属于有限资源,一旦电池耗尽,节点就无法继续工作。此外,多数基于WSNs的监测应用对数据传输时延有一定的要求,即需在限定的时间内完成数据传输。
路由协议承担了网络内数据传输的责任。高质量的可靠路由协议能减少节点传输的数据量,缩短数据传输时延[3-4],减少节点能耗。然而,由于WSNs路由受多方面因素影响,实现服务质量(Quality of Service, QoS)路由存在挑战。
QoS路由需考虑多项因素,如端到端可靠性、时延、能效。而这些因素往往又是相互矛盾的。因此,在实际情况下,采用准QoS路由。准QoS路由是指路由以一定概率满足QoS要求[5]。
文献[6]利用多路径满足QoS要求。确实,通过多条路径传输数据能够实现QoS要求,但是多路径也存在不足:多条路径需要多个节点构成路由,这就增加了参与路由的节点数,必然就增加网络能耗。同时,多个节点传输数据,可能会形成彼此干扰。因此,需要单条路径完成QoS要求。而选择一条满足多项因素的路径是多约束路径优化问题,这是一个NP问题。
为此,提出基于分布式学习机的稳定路由(Reliable Routing with Distributed Learning Automation, RRDLA)路由。RRDLA路由将选择单一端到端可靠性和时延要求的路径问题看成多约束优化问题,再利用学习机求解优化问题。仿真结果表明,提出的RRDLA路由有效地提高路由的稳定性,增加了数据包传递率,并减少了能耗。
1 预备知识
1.1 约束条件
n个节点随机分布于监测区域,它们形成节点集V={υ0,υ1,υ2,…,υn},其中υ0表示信宿。令Rs、Rc表示节点感测范围、通信范围。如图1所示。如图2所示。通常,Rs≥Rc。

图1 节点的感测和通信模型
假定媒体接入控制协议(Medium Access Control, MAC)提供估计链路质量的数据,即数据包接收率(Packet Reception Ratio, PRR)。且每个节点知晓其一跳邻居节点的PRR。本文将利用PRR估计链路的可靠性。
令P(u,υ)表示节点u与节点υ链路的PRR。若一条路径由m条链路构成,则该条路径的数据包传递率(Packet Delivery Ratio, PDR)等于这m条链路的PRR的乘积。
类似地,令P(u,υ)表示节点u与节点υ链路的数据传输时延,若一条路径由m条链路构成,则该条路径的数据传输时延等于这m条链路的时延之和。
1.2 学习机概述
学习自动机(Learning Automata, LA)是解决优化问题的有效技术。每个LA均保持有限的动作集,且每个动作均对应一个概率[7]。最初,LA随机地选择动作,然后外界环境针对此动作产生反馈信号(奖励或惩罚),进而修正选择此动作的概率,如图2所示。通过不断迭代,最终,LA能够从动作集中学习一个最优的动作。

图2 LA模型
可用E={α,β,c}表示LA模型,其中α={α1,α2,…,αn}为动作集,而β={β1,β2,…,βn}表示反馈信号。c={c1,c2,…,cn}为惩罚概率,其元素值与α={α1,α2,…,αn}内值一一对应。
引用T表示LA的学习算法,其定义如式(1)所示:
p(n+1)=T[p(n),α(n),β(n)]
(1)
其中p(n)动作概率矢量。
LA依据动作概率集p,学习机随机地选择一个动作αi,再将此动作作用于环境。收到环境反馈的信号后,学习机就依式(2)或式(3)更新动作概率。
若收到的是奖励信号(β(n)=0),就依式(2)更新:
(2)
若收到的是惩罚信号(β(n)=1),就依式(3)更新:
(3)
其中λ、γ分别表示奖励、惩罚因子。而r为动作集数。
2 RRDLA路由
2.1 初始阶段
为了形成动作集,每个节点(假定是节点υi)先向邻居节点传输请求建立动作集(Request Form Action, RFA)消息。一旦收到RFA消息,节点就回复请求建立动作集(Reply Form Action, P-RFA)消息。节点υi收集来自邻居节点的P-RFA消息后,就可建立自己的动作集[8]。
实质上,动作集可以理解为节点的邻居节点数。原因在于:节点需要传输数据,它需要从邻居节点中选择一个节点作为下一跳的转发节点。若有m个一跳邻居节点,则它就有m个可能的动作。此处的动作可理解为选择节点作为下一跳转发节点。
每个动作对应一个概率。学习机就是依据概率选择动作的。最初,节点就依据动作集内动作数,即节点数的倒数为动作概率。因此,最初,同一个动作集内的所有动作具有相同概率。

图3 构建初始动作集示例
以图3为例,假定节点A为源节点,它需要向信宿(节点J)传输数据,如图3(a)所示。依据图3(a)的拓扑结构所示,节点A有二个邻居节点{B,C}。相对应的,它具有两个动作{α1,α2}。它们的初始概率为{0.5,0.5}。
2.2 学习阶段
当节点需要传输数据(假定是节点υi)时,它就随机选择一个动作,即从邻居节点集中随机选择一个节点(假定是节点υj),并向节点υj传输一个激活数据包。一旦收该激活包,节点υj也随机选择一个动作,直到数据遍历信宿。最终,将这些被选择的节点加入至路由节点集Node_Rout。Node_Rout集是指构建从源节点至信宿的路由的节点集合。
LA对每个动作进行反馈,从而选择最优路由节点集,进而构建稳定的路径。将已选的动作作用于环境,环境再对动作进行反馈,再对所选择的动作进行奖励或惩罚,最终更新每个动作的概率。
具体而言,若已选的路径的时延小于当前迭代的路径时延,并且路径的PDR高于当前,则就需对当前的动作进行奖励。否则,就是对当前的动作进行惩罚。
即当β(n)=0时,信宿就对该动作奖励。并依据式(2)更新概率。若β(n)=1,信宿就对动作惩罚,并依据式(3)更新概率。
仍以图3为例,分析动作更新过程。最初,节点A随机地选择一个动作(假定选择了动作α1)。然后,节点A就向节点C传输数据,并激活节点C的学习机。
节点C再随机地选择一个动作(假定选择了动作α2),并传输数据包激活它。当节点A选择节点C后,节点A就修改它的动作集,即禁用(disabled)节点B。
当节点G的LA被激活后,它就需要选择一个动作,最终,就能到达信宿(节点J)。则本次迭代,就构成了Node_Rout={A,C,G,J}。即形成了路径A→C→G→J。整个过程如图4所示。表1显示动作集的概率。

表1 动作集的最终概率
2.3 数据传输阶段
学习阶段后,就进入数据传输阶段。在数据传输阶段,将Node_Rout内的节点,并传输数据包。如图4所示。

图4 选择节点示例
3 性能仿真
利用NS-2.34软件建立仿真平台[9],分析RRDLA路由性能。N个传感节点分布于150 m×150 m区域。具体的仿真参数如表2所示。

表2 仿真参数
同时,选择文献[10]提出的可靠的能效路由(Reliable Energy-Efficient Routing, REER)和文献[11]提出的时延-能量权衡的可靠通信(Delay-Energy tradeoff with reliable communication, DETR)路由作为参照,并分析它们的端到端时延、数据包传递率、网络寿命和数据包传输次数。
3.1 数据分析
3.1.1端到端传输时延
首先,分析传输数据的端到端传输时延。从图5可知,RRDLA路由的端到端传输时延最低。原因在于:学习机考虑了数据传输时延因素,并通过时延决策是否对动作进行奖励或惩罚。此外,相比于DETR和REER路由,RRDLA路由的时延随节点数的增加而保持稳定。

图5 端到端传输时延
3.1.2数据包传递率
图6显示了RRDLA、DETR和REER路由的数据包传递率随节点数的变化情况。

图6 数据包传递率
从图6可知,数据包传递率随节点数的增加而呈上升趋势。这主要是因为:网络内节点数越多,可选的路径数就越多,建立稳定路径的可能性越高。相比于DETR和REER,提出的RRDLA路由保持高的数据包传递率。
3.1.3网络寿命
接下来,分析网络寿命随节点数的变化情况。引用文献[12]的能量模型计算网络寿命。网络寿命是指从部署节点至网络内第一个节点因能量消耗殆尽的时间差。

图7 网络寿命
从图7可知,相比于DETR和REER,RRDLA路由在网络寿命方面获取良好的性能。原因在于:RRDLA路由通过减少参与路由的节点,减少网络能耗,进而提高了网络寿命。
3.1.4数据包的平均传输次数
最后,分析节点数对传输数据包的次数的影响。数据包的平均传输次数反映了从源节点至目的节点的跳数。从图8可知,RRDLA路由以少的传输次数完成数据包的传输。这也说明:RRDLA路由能够选择最优路径,并能够稳定地传输数据包。
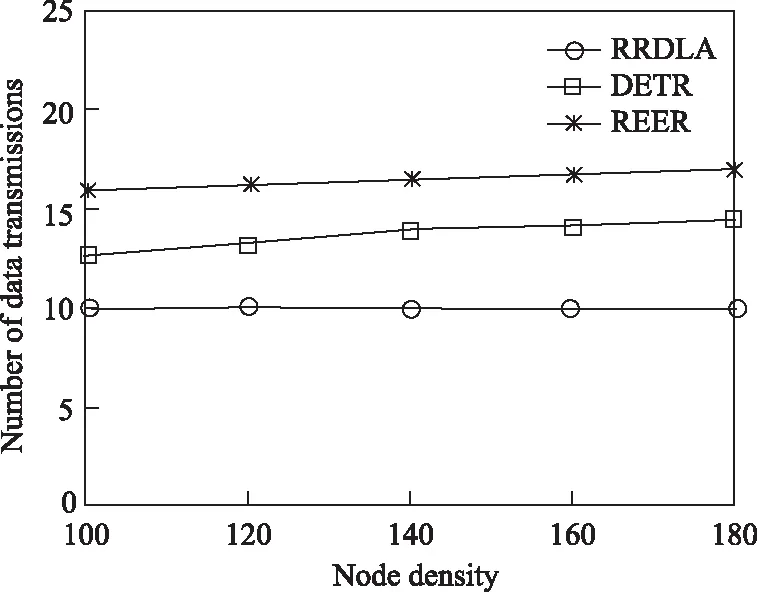
图8 数据包的平均传输次数
4 总 结
针对WSNs的QoS服务质量路由,提出基于分布式学习机的稳定路由RRDLA。RRDLA路由利用学习机解决寻找多路径优化问题。通过学习机找到最优的路径,进而提高路由的稳定性,并减少网络能耗。仿真结果表明,提出的RRDLA路由有效地提高路由稳定性,提高了数据包传递率,并控制了能效。
猜你喜欢
河北北方学院学报(自然科学版)(2021年11期)2021-12-28 04:31:26
通信电源技术(2021年3期)2021-06-02 23:46:02
导航定位学报(2020年2期)2020-04-13 08:41:10
传感器与微系统(2019年7期)2019-06-25 05:47:22
汽车实用技术(2019年6期)2019-04-11 02:53:30
测控技术(2018年10期)2018-11-25 09:35:26
自动化学报(2018年2期)2018-04-12 05:46:21
作文·初中版(2017年12期)2017-12-23 17:33:20
制造技术与机床(2017年4期)2017-06-22 11:17:32
作文中学版(2017年12期)2017-02-15 22:13:28
