
DVE中一种实时任务容错调度方法
2019-12-23 07:13:06刘述田
中国电子科学研究院学报 2019年7期
刘述田
(大连东软信息学院,大连 116023)
0 引 言
分布式虚拟环境(DVE)中有很多人与环境或者人与人的交互活动,这些活动可以抽象为非周期性的实时任务。在实际应用开发过程中,可以在分布式实时仿真系统中按照HLA规则开发RTI,以提高效率。然而HLA至今已经发展到IEEE 1516-2010[1],并没有把实时性作为一项要求放在规则当中,按照其开发的系统并不能满足实时性要求。例如,DVE中有大量的互操作以及人在回路中的情形,因此当一个操作发生之后,系统需要给出可预测的响应,如果不能在交互活动的截止期限前完成通信并进行响应,那么系统就会给人以严重失真的感觉,甚至会因此做出错误判断与动作,所以需要保证互操作活动的实时性。
正如HLA并没有把实时性作为一项要求放在规则当中一样,容错性能也没有作为规则在HLA中体现出来,一般的应用如果需要系统或任务容错,必须在应用内进行容错开发。对于一些重要的实时性任务,系统必须能够保证它们在截止期限内完成,如果不能完成,则会带来比较严重的后果。如果任务出现异常或故障,也会造成任务不能实时响应。本文研究在非周期任务出现暂态异常时的调度方法。
1 非周期任务容错模型
在HLA扩展中,“故障”定义为,发生在联邦内部或者运行环境中,能够阻止整个联邦以HLA兼容的方式交互的问题[2]。上述这些故障从系统体系结构这一层次提出来的,而没有涉及到底层故障模型及容错模型和调度算法。
文献[3]已经论述过,周期性任务是易于预测的,非周期任务给系统实时性带来较大的不确定性,然而其却在较大程度上影响了对系统实时性的判断,因为非周期性的任务往往是人机交互或者联邦成员之间交互的请求,因此非周期任务的实时性以及可靠性就提高到了很重要的地位。
当错误检测手段检测到了任务产生的故障之后,容错机制就需要处理这个故障以提高系统的可靠性。最简单的容错技术就是重复执行该任务,其在功能上与主副版本技术[4]类似,不过重运行技术可以重复执行多次而不受副版本数量的限制。
由于非周期任务在较大程度上影响了对系统实时性的判断,因此必须给非周期任务以较高的优先权运行,在文献[3]内,有足够的处理器时间运行所有的任务,可以采用EDF算法,但是当非周期任务出现错误的时候,就需要提高该任务的优先权,尽量减少由于其它非周期任务高于该任务的优先权而抢占,造成过多不必要的抢占开销,使它不仅能够在截止期限前完成,更需要它尽快完成。在这里,由于周期性任务周期性更新,因此不予考虑容错。
给定非周期任务集合X={J1,…,Jn}的一个任务Ji可以用一个三元组来描述:
Ji=

本文研究的调度策略前提条件如下:
(1)仅考虑非周期任务的暂时性软件错误,如果任务Ji出现错误,则系统立即启用容错策略,进行容错处理;
(2)非周期任务是相互独立的,即没有由于时序优先约束、同步或者因为共享资源而产生的阻塞;
(3)在故障模型中,假设两个连续出现的故障之间有最小间隔,用PF表示.它是系统容错能力的一个标准,PF的值越小就表示系统的容错能力越强。
文献[4]研究了硬实时系统中周期性任务的主版本和替代版本容错方式下,采用了容错优先级可提升的双重优先级分配策略,不仅提高了系统的容错能力,也能够减少任务之间的抢占开销。本文借鉴了其优先权可提升的思想,在非周期任务的实时系统中对其进行基于任务重运行的调度算法研究。
对于优先权继承协议,一个任务被阻止的次数是有限的,但不能阻止死锁。相比之下,优先权上限协议(Priority-Ceiling Protocol)[5]阻止一个任务至多一次,并能够防止死锁。每个共享资源都有优先权上限,它的值等于所有可能使用这个资源的任务的优先权最大值。但是只有当一个任务的优先权高于所有锁定该资源的任务的优先权的情况下,该任务才可以锁定这个共享资源。
当任务Ji发生故障的时候,因为EDF是根据最早的截止期限来确定任务的优先权,而发生故障之后重复运行时其截止期限并没有发生改变,所以会继承之前的优先级,这样,任务已经运行了一段时间之后出现故障,耽误了一段时间,要重新运行,在原来的优先级上就不一定能保证任务在截止期限前完成了。虽然继承优先级策略相对简单,但却不一定能适合于我们这种情形。
针对这种情形,文献[6]提出了提升优先级的调度策略,文献[4]在此基础上完善了当故障任务重新运行时提升它的优先级的策略,这种策略可以在任务不能满足截止期限的情况下提升容错任务的可调度性,在一定程度上缓解了系统的容错压力。从这个角度来说优先级提升的策略要优于优先级继承的策略。
2 WCRT的计算
任务Ji的最坏情形响应时间(WCRT)会受到是否发生故障影响,在容错调度算法下,发生故障的任务要重复运行,因此会被本身和比它优先权高的任务影响到,因此WCRT的计算方法如下[7]:
(1)
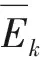
如果发生故障情形下WCRT小于截止期限di,那么这个任务集合就可以在第二次错误到来之前被调度运行。
从公式(1)可以看出,任务的响应时间的变化受第三项影响比较明显,如果此时有任务发生故障,并且优先权高于任务Ji,那么其等待时间会比较长,而且因为过多的抢占也消耗系统处理能力,有可能最后错过截止期限。所以,容错的任务在故障后要提升优先权,尽量少的被其它任务抢占,以保证在截止期限前完成。
WCRT的计算分以下两种情况进行:
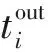

由于本文重点考虑非周期任务的实时性,周期性任务每隔固定时间更新,因此,不考虑对周期任务进行容错。
(2)
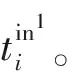
(3)

(4)
(5)
这是一个迭代计算的式子,具体方法可以参见下式:
(6)
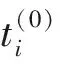
容错任务的调度不仅要能保证自己能在截止期限完成,也要保证其他任务在截止期限前完成,不能因为故障而打乱其它任务的调度。
由文献[3]可知,在时间步进式联邦中,所有的任务实例要么在一个步长内完成,要么在下一个步长内完成,不能跨越两个步长,那么
ti≤Δt
(7)
同时
ti≤di
(8)
根据周期性任务在每一个步长的运行情况,事先确定每个步长内非周期任务可以占用的最大比率UA,故第m个步长可以调度的非周期任务集合F(m)必须满足如下条件:
(9)
若要满足非周期任务的实时性,必须同时满足式(7)、式(8)和式(9)。
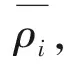

表1 优先级提升的方法
在能保证所有的任务都能满足时间约束的条件下,为每一个任务找到最大的优先级,以防止优先级较低的任务抢占到优先级较高的任务的容错,这样就能减少抢占的处理器开销,从而提高效率。
3 仿真测试与分析
仿真为了测试容错调度算法的容错能力,设计一个测试环境,能够测试两个连续出现的故障之间的最小间隔PF是系统容错能力的一个标准,PF的值越小就表示系统的容错能力越强。
仿真实验的测试系统采用如图1的系统,以federate1作为研究对象:
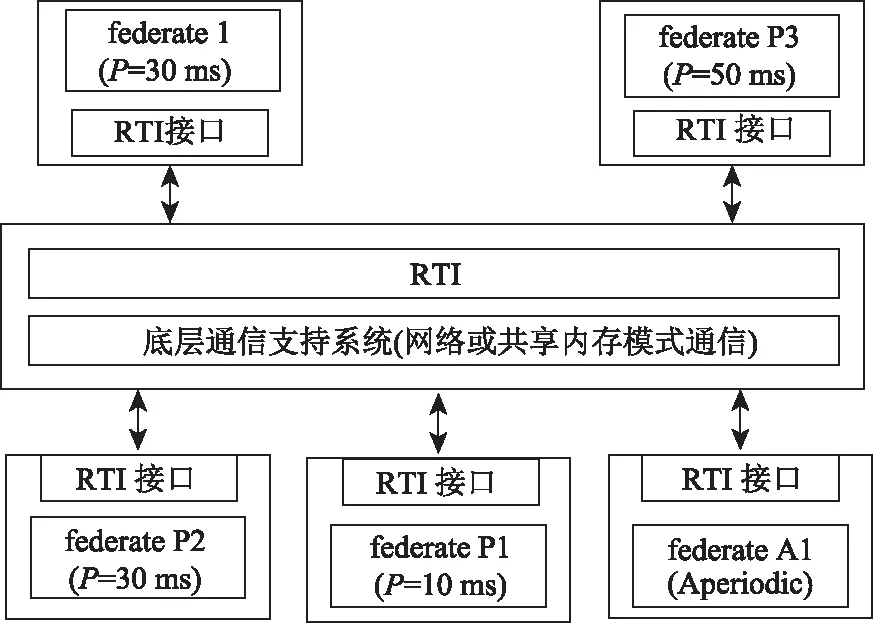
图1 仿真测试系统组织结构
仿真实验除了运行周期性任务和邦员1内部的其它任务之外,还为产生非周期任务的federateA1模拟了非周期任务,每个任务的占用的处理器时间在[1, 5]ms内均匀分布,随机选出,释放时间在仿真时间段内服从参数为每个步长2个的泊松分布,UA设为15%。每个任务的截止期限设为从其释放开始之后50 ms,如果在一个步长30 ms内不能完成就安排到下一个步长内运行。仿真时间长度为1000个步长,即30000 ms。
仿真共进行50次,每次仿真都安排间隔为PF、处理时间3 ms的周期任务模拟发生故障的非周期任务,测试其响应时间,每个任务的截止期限也设为从其释放开始之后50 ms以计算优先级。PF的值分别取处理时间3 ms的正整数倍,每次仿真增加1倍,从1倍增加至50倍,即150 ms。把每次仿真中所有模拟任务的响应时间取算术取平均值作为仿真结果。
算法用C++语言在Visual Studio 2010环境下实现,在Core i5 2.50 GHz CPU硬件平台上运行。
仿真结果如图2所示,横轴为实验组编号,同时也是PF与任务处理时间的比值,纵轴为任务平均响应时间(ms)和丢失的任务的比例(%)。
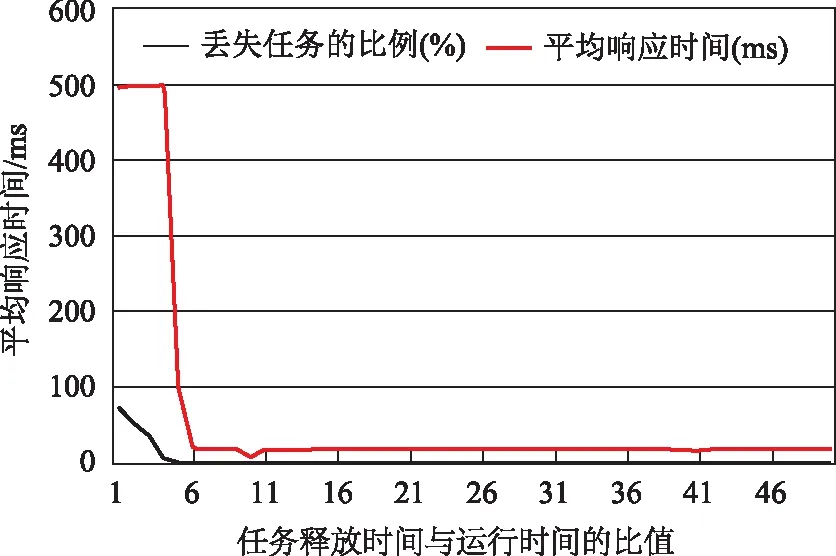
图2 容错任务的平均响应时间
从图中可以看出来,当PF在6倍处理时间以下的时候,任务的响应时间非常长,最高达到500 ms,远远超过预定的截止期限50 ms,这是因为假定的任务出错频率太高,处理器根本没有时间来处理这么多容错任务,因而丢失了约70%的任务,当PF增大的时候响应时间仍然没有减小,但是丢失任务的比例却在下降。当PF过了一个临界点(这里是6倍平均任务处理时间),容错任务的响应时间与非周期任务的平均响应时间基本持平,这说明只要有足够的处理器时间,容错调度算法是能达到容错需求的。事实上,任务的故障间隔应该比6倍处理时间高很多,所以在本系统内基于任务重运行的容错调度算法可以达到容错性能要求。
4 结 语
HLA并没有把实时性和容错性能作为一项要求放在规则当中,因此RTI中任务的容错需要开发者根据应用的具体情况开发适合的容错方法。
本文主要研究了在HLA/RTI系统中,实时性要求较强的互操作或人与机器的交互的时候产生的非周期任务的容错调度方法。基于重运行的容错调度算法,在考虑了所有的非周期任务的最坏情形响应时间的前提下,把故障任务的优先级和其它任务修改到最优的程度,减少了任务之间的抢占,因而能够增加任务容错的可调度性。
猜你喜欢
高技术通讯(2021年3期)2021-06-09 06:57:24
西部论丛(2019年25期)2019-10-21 05:42:40
电测与仪表(2017年24期)2017-12-19 05:15:16
北京航空航天大学学报(2017年12期)2017-04-23 08:31:39
中国知识产权(2017年2期)2017-03-13 19:24:40
幸福(2016年6期)2016-12-01 03:08:35
世界海运(2015年8期)2015-03-11 16:39:09
现代企业(2015年6期)2015-02-28 18:52:37
河北传媒研究(2014年2期)2014-07-12 14:33:21
乡村科技(2014年21期)2014-03-04 16:17:59
