
无线传感网能量约束模糊c-均值聚类算法
2019-12-21 02:58:42姚美琴胡黄水王出航韩优佳
长春工业大学学报 2019年5期
姚美琴, 胡黄水*, 王出航, 韩优佳
(1.长春工业大学 计算机科学与工程学院, 吉林 长春 130012;2.长春师范大学 计算机科学与技术学院, 吉林 长春 130021)
0 引 言
随着互联网和信息技术的快速发展,许多应用领域将产生大量数据,这些数据的规模和容量远远超过了人类的直接处理能力。为了更方便地表达和理解数据,通过计算机对数据进行分类或聚类是非常重要的。无线传感器网络(WSNs)是一种大型无基础设施无线传感器网络,由数千个传感器节点组成,并以自组织形式形成网络。传感器节点之间通过互助进行信息交互和数据采集与处理,在许多领域得到应用[1-4]。网络中存在大量的特征信息,因此特别适合将聚类应用于无线传感器网络中。
LEACH(低能量自适应聚类层次结构)[5-7]是最具代表性的层次聚类路由算法之一。 其核心思想是通过随机周期选择簇头节点,将整个网络的能量负载均匀分布到每个节点,从而降低网络能耗,延长网络生命周期。LEACH-C[8]集中选择簇头以使簇头的分布更加合理,但集中控制使得sink节点需要频繁地与所有节点交换信息,导致能源浪费;文献[9]采用自适应调整机制来控制簇头广播消息的广播半径,平衡节点分布和能耗,但该算法以丢失大量网络信息为代价改善网络生命周期;文献[10]通过减少基站节点的簇半径实现非均匀聚类,然后在整个网络中实现能量平衡;文献[11]提出了一种估算数值数据聚类中心的有效方法,该方法可用于确定簇的数量及其初始值,用于初始化迭代优化的聚类算法,例如模糊聚类算法;文献[12]提出了一种新的基于Renyi信息的聚类算法,该算法和众所周知的模糊聚类算法FCM具有相同的聚类轨迹。 这一事实构成了概率聚类与模糊聚类之间的桥梁,而Renyi entropy measure的研究成果可以帮助我们进一步理解模糊聚类的本质;Bensay[13]提出的有效性函数表明,值越小,聚类效果越好。通过对结果的分析,确定最优聚类数量,大大提高了计算成本。文中提出了一种能量限制模糊c-均值聚类无线传感器网络聚类算法(FCM-E),在聚类过程中引入能量限制项来提高聚类算法对能量的敏感性,通过cos指数确定最佳聚类数。该算法可以自动确定最优聚类数,大大降低计算成本,延长网络寿命。
1 网络模型
提出的FCM-E算法检查了在100 m×100 m监测区域中随机部署的100个传感器节点,基于以下假设:
1)所有传感器节点都是同构的,能量有限,汇聚节点的能量是无限的;
2)汇聚节点和传感器节点在部署后是固定的,汇聚节点远离监控区域;
3)传感器节点之间的无线通信可以是对称的,位置信息可以通过GPS或定位算法确定并传输到汇聚节点。
Heinzelman的无线通信系统模型用于网络能量消耗,自由空间信道模型和多径衰落模型用于通信距离。发送节点的能量消耗包括发送电路的能量消耗和功率放大。 通过该模型将kbit数据发送到距离d的能量消耗为
ETx(k)=ETx-elec(k)+ETx-amp(k,d)=
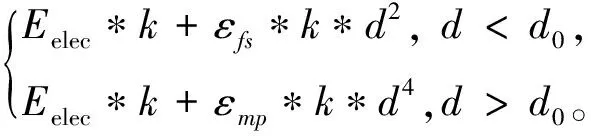
(1)
接收节点接收kbit数据的能量消耗为
ERx(k)=ERx-elec=Eelec*k,
(2)
式中:Eelec----发送或接收电路的能量消耗;
d0----通信距离的阈值。
2 基于FCM-E的聚类路由算法设计
2.1 基于FCM-E的模糊聚类模型
文中提出了一种基于改进模糊c-均值聚类算法的聚类路由协议(FCM-E)。主要思想是将传感器节点作为分类对象并将其划分为C个部分,其中每个部分都有一个聚类中心,最佳聚类数由cos索引确定,这里,FCM-E算法给出了一个目标函数来调整聚类中心。 当目标函数的值小于给定阈值时,停止迭代以获得最终聚类结果X={x1,x2,…,xn},X是节点集,xi表示每个节点。
X={x1,x2,…,xn}是M维数据空间中的有限样本数据集,n是数据集中元素的数量,xj(j=1,2,…,n)是数据集中的样本点。
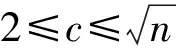
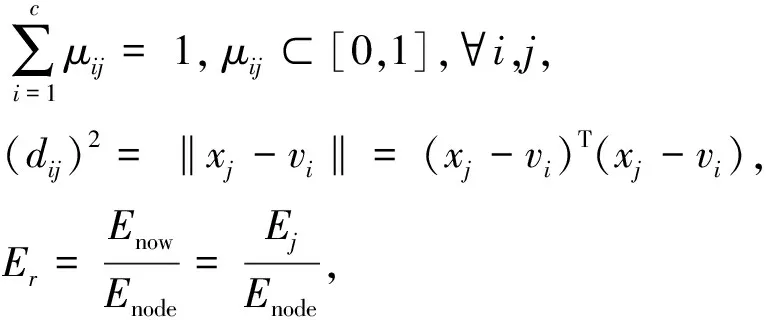
(3)
式中:Enow----节点的当前能量;
Enode----节点的总能量;
m----加权指数,m⊂[0,1)。
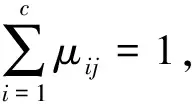
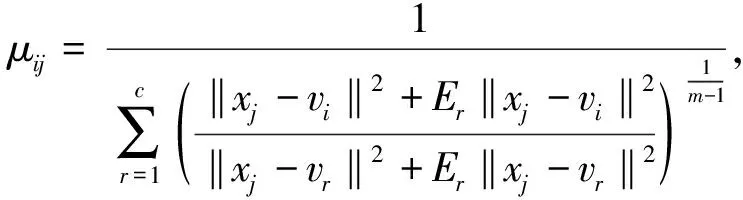
(4)
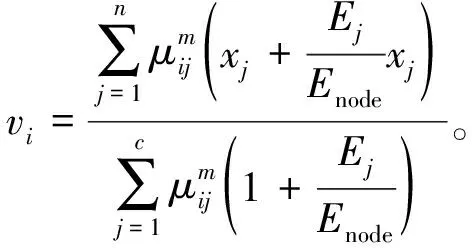
(5)
当目标函数最小化时,需要迭代调整聚类中心。 给定阈值ε(0.001<ε<0.01),如果目标函数值大于阈值,则迭代更新隶属度,否则迭代停止。
2.2 选择最佳聚类数
通过上述聚类方法得到一组聚类数C,然后构造有效函数以确定最优聚类数。聚类结果的质量可以通过聚类内的紧凑程度和聚类之间的分离程度来确定。也就是说,集群内的对象尽可能紧凑,集群外尽可能分开。
首先,选择不同聚类类别的数量。最终的聚类结果由簇内紧凑性、簇间重叠度和簇间分离确定。
紧致率
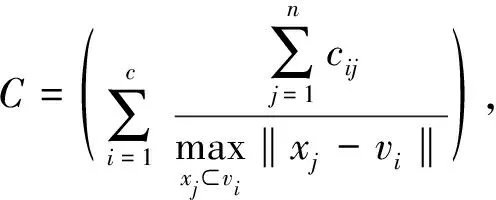
(6)
其中,样本xi到第i类的紧致率定义为
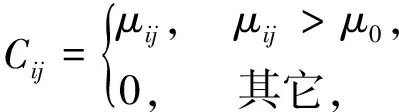
(7)
式中:C----聚类数;
n----样本总数;
μij----属于类i的样本xj的隶属度;
vi----类i的聚类中心;
μ0----紧凑度阈值。
重叠度
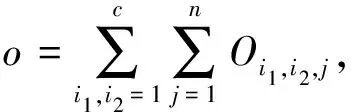
(8)
其中,样本xi在第i1类和第i2类之间的重叠程度为
式中:μ1----重叠阈值。
分离
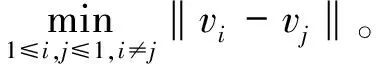
(9)
考虑到数据分布的差异,引入了新度量的cos索引重叠度,两个类之间的重叠程度由属于某一阈值内两个类的样本点的隶属度差异表示,两类之间所有样本的重叠度之和是两类的重叠度。根据紧致度指数,紧凑性值越小,紧凑性越好;根据分离指数,分离度值越高,分离程度越高。因此,构造了以下聚类有效性函数
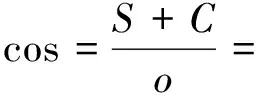
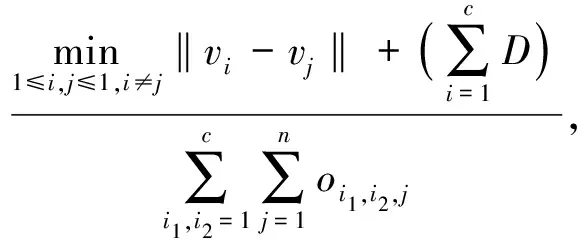
(10)
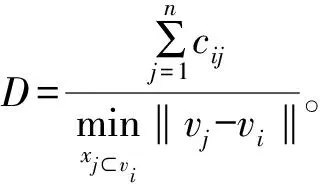
对应于cos索引最大值的聚类数是由该索引确定的最佳聚类数。
2.3 算法描述
1)输入传感器节点和节点特征索引矩阵。
2)根据上述改进算法计算并初始化聚类中心,设置迭代计数器b=0。
3)构造模糊相似度矩阵U=(μij)c×n。
4)根据式(5)更新聚类中心v。
5)根据式(4)更新模糊分类矩阵μ。
6)当迭代操作达到收敛‖vb+1-vb‖<ε时,输出聚类中心v(簇头节点),网络中的每个节点属于不同的聚类,并具有每个聚类的标识。否则,如果b=b+1,则转到3)。
7)计算余弦(cos)函数,选择最大余弦(cos)生成最优聚类数C,使用聚类中心得到聚类簇头,选择最接近聚类中心的节点作为聚类簇头节点,并根据聚类结果形成c簇。
3 模拟分析
在仿真中,主要考虑了传感器节点在数据融合中消耗的能量,计算了网络中幸存节点的数量和总剩余能量,分析算法的能量效率。在相同的仿真条件下,对LEACH和FCM-E进行比较。 LEACH的参数模型仿真参数:发送或接收电路消耗;自由空间模型;多径衰减模型;距离闭合值;数据处理功率;数据包大小为250 bit。FCM-C和FCM-E算法的fuzziness indexm=2, stop parameter=0.1。
设置基站节点(0,0)在100 m×100 m方形区域中,随机设置100个节点以确定参数紧凑性阈值。从式(8)计算重叠阈值,以计算簇头的最佳数量,见表1。
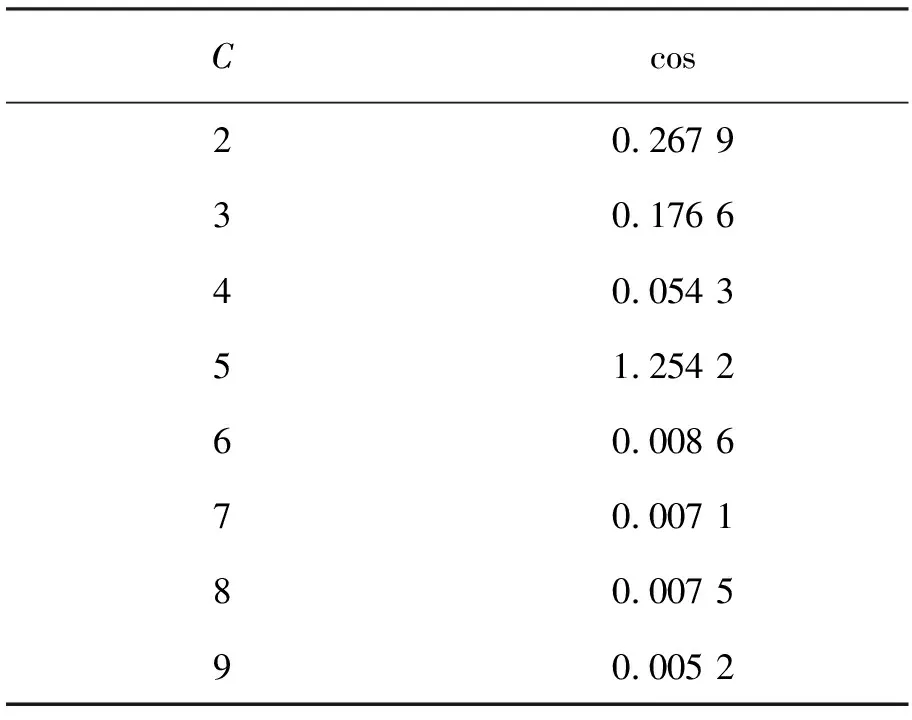
表1 簇头的最佳数量
从表1可以确定,当C=5时,获得cos的最大值,最佳聚类数为5,Lt-1,Lt-2分别是第一个节点死亡时间和30%节点死亡时间。节点的初始能量为0.02j,群内通信采用单跳方式,群集间通信采用多跳方式。
算法的网络生命周期见表2。
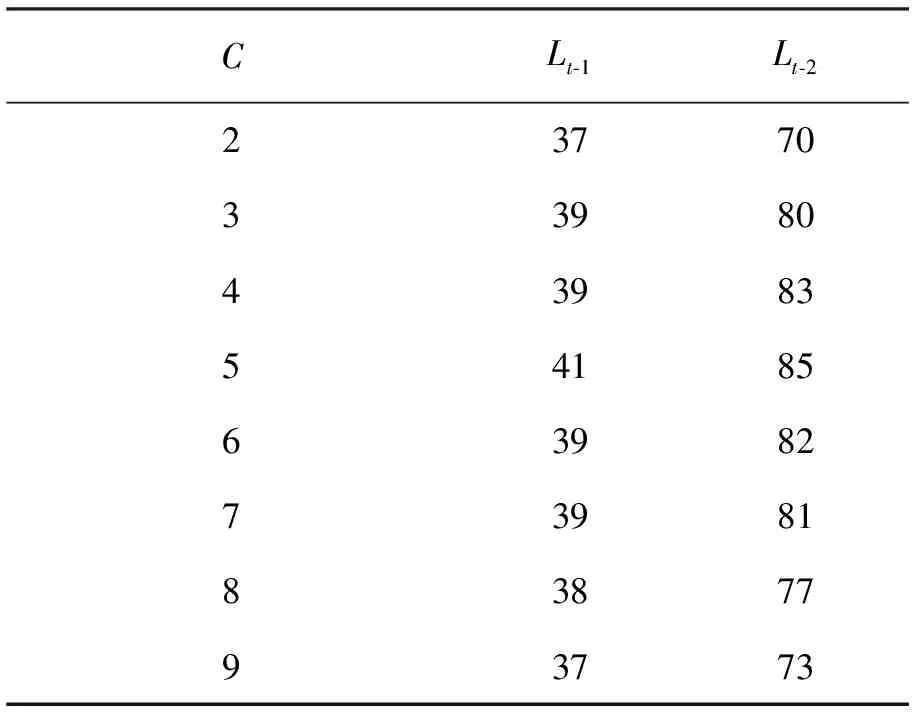
表2 簇头死亡时间
从表2可以看出,当C=5时,无线传感器网络的寿命最长,适合验证cos的最佳数量。当网络中的簇头数量太少时,簇头节点过载,并且簇头节点通常必须将数据传输到相距很远的簇头节点(中继节点),这导致节点消耗更大的能量。当簇头数量较大时,会导致簇中更多的本地数据融合消耗,因此,最佳簇头数量的选择需要在合适的范围内。
比较LEACH和FCM-E在网络生命周期和能耗方面的表现,分别如图1和图2所示。
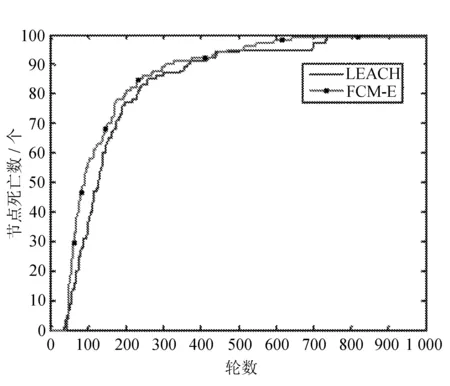
图1 算法生命周期
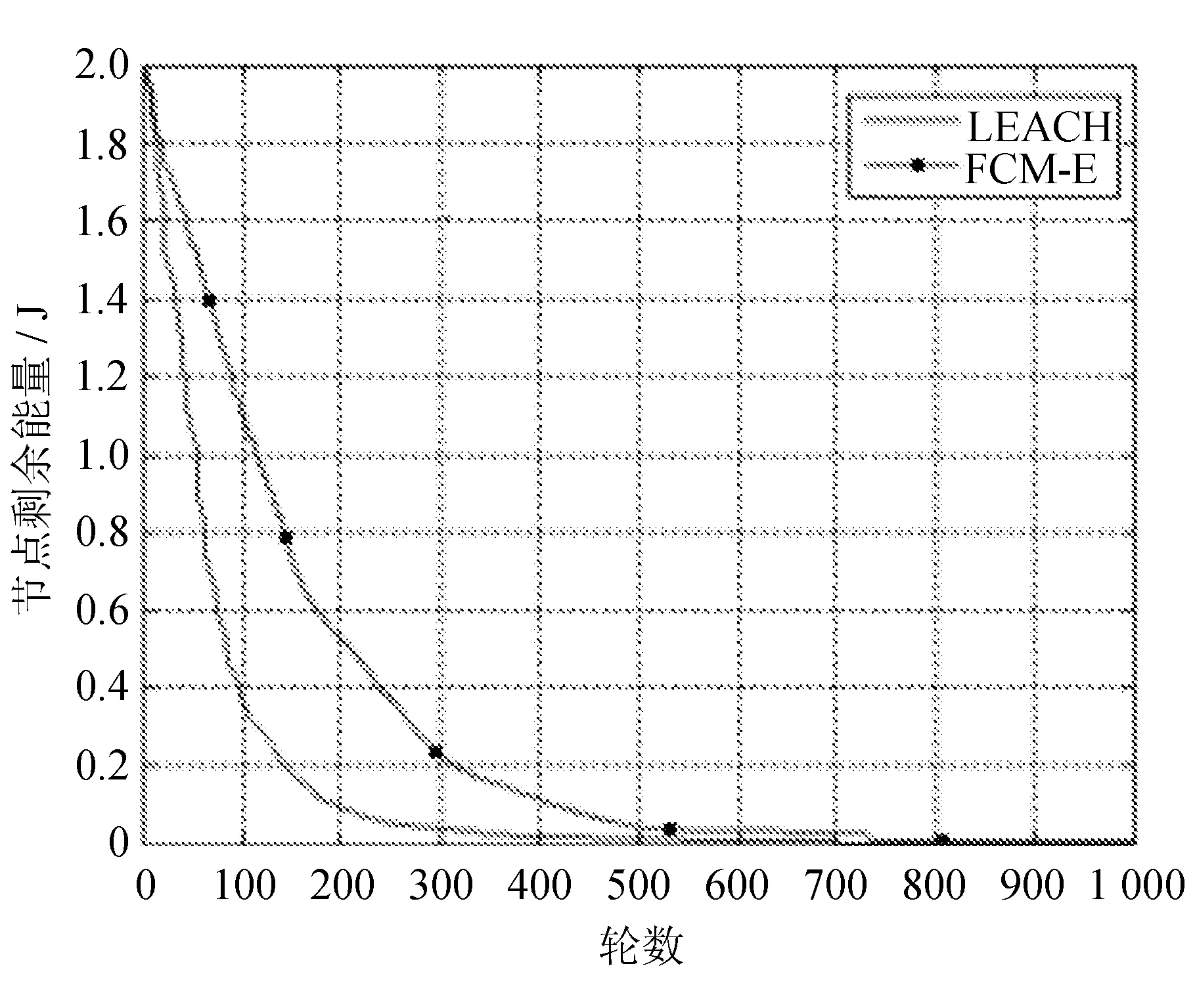
图2 算法能耗
从图1和图2可以看出,FCM-E算法比LEACH算法显著提高了网络生命周期,降低了网络能耗。与LEACH算法相比,FCM-E算法的能耗更加渐进,这使得网络能量消耗更加均匀,提高了网络的性能。FCM-E算法在网络生命周期中具有梯度。FCM-E算法采用固定聚类方法,当集群能量消耗较快时,集群中的节点将一起死亡。 能耗方面,FCM-E算法更加平坦,并且随着轮数的增加,能耗差距更加明显。
4 结 语
提出了一种用于无线传感器网络的能量约束模糊c-均值聚类算法,引入能量限制项来提高聚类算法在聚类过程中对能量的敏感性,确定最优聚类数。 仿真结果表明,与LEACH算法相比,该算法能够获得合理的簇头节点分布,延缓第一个节点的死亡时间,延长网络生命周期,平衡节点的能耗。
猜你喜欢
疯狂英语(双语世界)(2023年3期)2023-11-16 02:24:14
体育科技文献通报(2022年4期)2022-10-21 03:20:00
现代仪器与医疗(2022年2期)2022-08-11 09:51:46
昆钢科技(2022年2期)2022-07-08 06:36:14
体育科技文献通报(2022年3期)2022-05-23 13:46:20
当代水产(2021年10期)2022-01-12 06:20:28
建材发展导向(2021年23期)2021-03-08 01:05:38
作文中学版(2020年1期)2020-11-25 03:46:21
中国外汇(2019年13期)2019-10-10 03:37:46
民用飞机设计与研究(2019年2期)2019-08-05 01:33:20
