
一种基于群体智慧的智能服务聚类方法
2019-12-19 06:24:28陈彦萍高宇坤张恒山王忠民
郑州大学学报(理学版) 2019年4期
陈彦萍, 高宇坤, 张恒山, 夏 虹, 王忠民,王 鑫, 高 慧
(1. 西安邮电大学 计算机学院 陕西 西安 710121; 2. 陕西省网络数据分析与智能处理重点实验室 陕西 西安 710121)
0 引言
近年来,面向个人、家庭、集团用户的各种创新应用急速增长,各行各业的“智能服务”应运而生[1-3].智能服务以用户需求为中心,进行服务模式和商业模式的创新[1],能够自动辨识用户的显性和隐性需求,并且主动、高效地满足其需求的服务[3].智能服务种类繁多,数量庞大,因此海量智能服务的供需匹配是一个复杂的过程,需要通过智能服务的聚类、选择与评价等几个阶段来解决.因此,在实现智能服务供需匹配的初始阶段,如何对海量的智能服务进行聚类处理,快速、准确和高效地选出能够满足用户请求所需的智能服务集合成为一个亟待解决的问题.
聚类目前已经被大量地应用在服务的研究当中,服务聚类是指按照服务与服务之间的相似程度,把性质类似的服务划分到同一个簇中,相同簇的服务具有相似特性.为了解决不同的问题,满足不同的需求,很多学者研究并实现了各种各样的聚类算法.文献[4-7]将机器学习算法运用到服务发现中,可以降低服务的搜索范围,进而提高服务发现的效率.文献[5]基于功能相似性进行服务的聚类,可以提高服务的检索效率.文献[6]在服务描述文档中运用特征选择工程,选择相关的能体现服务功能的关键特征,量化关键特征,计算服务相似度,最后聚类成簇.文献[7]统计每个词在每个服务文本中出现的次数,构建词与文档的矩阵,将每个词转化成数字,然后通过生成的数字化矩阵计算服务间相似度,从而聚类成簇.文献[8]基于猫群优化算法提出一种按照功能相似性进行服务聚类的方法.文献[9]在确定聚类数的前提下,实现对服务的聚类预处理.文献[10]通过不同的相似度阈值,获得不同的聚类结果.文献[11]提出基于属性的网格资源动态聚类法.文献[12]为确定最佳分类,通过构造F-统计量的方法进行评价选取.文献[13]提出了一种面向主题的领域服务聚类方法,该方法在对服务进行领域分类的基础上,结合概率、融合领域特性的领域服务聚类模型DSCM,并基于该模型提出了一种面向主题的聚类方法.文献[14]提出了面向领域的标签辅助的服务聚类方法,该方法在建立DT-WSC服务聚类模型的基础上提高了聚类效果.文献[15]从服务描述文档中提取内容、上下文、主机名和服务名称4个特征,以便使用树遍历算法对服务进行聚类,通过归一化Google距离来测量内容和上下文之间的相似性.上述文献所述的服务聚类大多都只使用了一种聚类方法(如k-means聚类),这存在很大的局限性,因为没有一种聚类算法能准确揭示各种数据集所呈现出来的多种多样的簇结构.
为了解决这一问题,本文提出了一种基于群体智慧的智能服务聚类方法(service cluster based on wisdom of crowds,SCWoC).该方法将基于群体智慧的聚类集成方法应用到智能服务中,使其满足智能服务的特点.先将服务数据集进行转化,得到一个满足群体智慧准则的可使用数据集,然后利用不同聚类算法进行集成.该方法利用满足智能服务特征的群体智慧理论,使基聚类结果互相学习,实现了基聚类算法的集成,提高了服务聚类结果的准确性.
1 相关概念
1.1 群体智慧与聚类集成
文献[16]首先提出了群体智慧的概念. 群体智慧又称作集体智慧,可以理解为共享的或者群体的智能,它可以在细菌、动物群体、人类社会、计算机网络中出现,表现为集体协作的创作方式、协商一致的决策方式等群体合作形式.文献[17]提出一种基于群体智慧优化决策框架.文献[18-19]提出“聚类集成”的概念:聚类集成是指将关于一个对象集合的多个划分组合成一个统一聚类结果的方法.文献[20]提出聚类集成(cluster ensembles)的目标就是要寻找一个聚类,相对于所有的输入聚类结果来说,尽可能多的符合(或一致).
聚类集成的过程为:假设数据集X有n个数据对象X={x1,x2,…,xn},首先对数据集使用N次聚类算法,得到N个聚类结果,其中pi(i=1,2,…,N)为第i个聚类算法得到的聚类结果;然后利用一致性函数T对P中的聚类结果进行集成,得到一个新的数据划分P′,将此作为最终的聚类结果.
1.2 基于群体智慧的聚类集成
文献[21]最先将群体智慧概念应用到聚类问题上,给出了一种基于群体智慧框架的聚类模型,将群体智慧框架在聚类集成问题中转化为如下内容:
1) 独立性. 即数据间的特征必须满足最小关联性.
2) 分散性. 基聚类算法生成的基聚类结果必须只使用自己的方法.
3) 多样性. 每一个聚类算法都有聚类结果,即使与事实相差很多.
4) 聚集性. 将各自的聚类结果转化成为集成结果的机制.

图1 基于群体智慧框架的聚类模型Fig.1 Clustering model based on wisdom of crowds framework
文献[22]将这种模型进行了详细的说明和论证,通过大量实验验证了基于群体智慧框架的聚类模型的可行性与优越性.模型如图1所示,数据集通过映射函数得到映射集,此时,实现了群体智慧的独立性标准;映射集通过转换函数得到转换集,此时,实现了群体智慧的分散性标准;转换集通过不同的聚类算法得到参考集,此时,实现了群体智慧的多样性标准;参考集通过学习算法得到结果集,此时,实现了群体智慧的聚集性标准.
2 基于群体智慧的服务聚类方法
智能服务的供需匹配是一个复杂的问题,需要分为智能服务的聚类、选择与评价等多个阶段.首先使用服务聚类算法对数据进行预处理,为服务匹配做准备,把类似的服务聚成类簇.其次,通过服务发现机制,将用户的搜索请求定位到相应的服务类簇,从而降低服务的搜索数量和匹配计算量,提高服务发现效率.本文提出一种包含群体智慧理论的聚类集成方法(SCWoC),在群体智慧的框架下有效地提高了基聚类结果的准确性、聚类集成结果的稳定性及准确性.
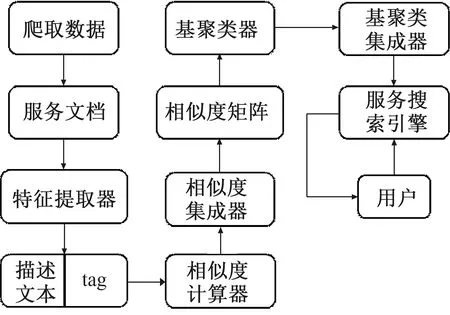
图2 SCWoC算法流程图Fig.2 SCWoC algorithm flow chart
2.1 SCWoC方法
SCWoC方法的整体框架如图2所示,该框架包含用户和服务搜索引擎2个查询角色;5个组间,分别是特征提取器、相似度计算器、相似度集成器、基聚类器、聚类集成器.
具体实现过程为:首先用R语言工具从programmableWeb上爬取相应的服务数据,包括服务名称、服务类别、服务描述文本、以及tag标注信息;然后,通过特征提取器提取每个服务描述文本和tag标注信息,并将其作为服务聚类的输入文本,采用相似度计算器分别计算出服务描述文本和tag标注信息相似度,通过相似度集成器将服务描述文本相似度和tag标注相似度进行融合,得到服务之间的相似度,并将其作为基聚类器的输入矩阵;接下来,由基聚类器进行聚类,得到基聚类结果,利用聚类集成器对聚类结果进行集成,得到最终的聚类结果后,用户通过服务搜索引擎进行服务搜索与查询,系统返回搜索结果给用户.
2.2 服务相似性计算
本文主要是在聚类方法上进行了优化,由于Web服务数据集一般都是文本数据集,不能直接使用,所以服务相似度计算是用来处理这些不能直接使用的文本数据,将其转化为数值数据,这样就可以进行聚类操作.
2.2.1文本相似性计算 服务描述文本描述了服务的功能,由一段文本组成,先对服务描述文本进行预处理,提取有意义的内容词汇形成一个服务描述文本的权值向量,然后,再根据权值向量进行相似度计算,主要由以下4个步骤完成[23].
1) 提取词语.将句子划分成词语,提取名词作为词语特征词.
2) 移除停用词.去掉一些无意义的符号和不能区分主题的词汇,例如:+、*、&、the、and、of等.
3) 处理词干. 将一个词处理为它的词干或者词根的形式,例如 gived、gives,全部处理成give.
4) 选择关键词. 运用tf-idf阈值算法选择文档集的关键词.
其中tf-idf阈值算法主要包括两个步骤.首先计算词频,词频tfij计算公式为
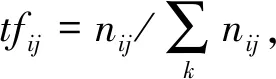
(1)
其中:分子表示词条i在文档j中出现的次数;分母是文档j中所有词条之和.其次计算逆向文件频率idfi,其公式为
idfi=log(N/ni),
(2)
其中:N是文档集总数;ni是包含词条i的文档数目.
标准配送式变电站采用模块化、标准化、工厂化生产,是未来变电站发展的新方向。预制光缆作为实现二次设备间模块化、标准化连接的重要手段,有效提高了标准配送式变电站现场光缆接线的质量与效率,在标准配送式变电站内得以广泛应用,但同时存在工程应用方案众多、工程实施问题较多等情况。本论文结合标准配送式变电站预制光缆的工程应用现状及需求,结合预制光缆的结构型式、光缆类型、预制方式等因素对预制光缆的工程应用方案进行研究并给出标准化应用方案,同时对工程实施中的常见问题进行分析研究并提出解决方案,有助于实现预制光缆的标准化应用与工程推广。
词条i在文档j的tf-idf权值计算公式为
ωij=tfij×idfi.
(3)
权值越大,说明词条越重要,选出权值超出阈值的词汇作为文档的关键词.
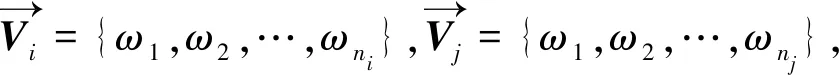
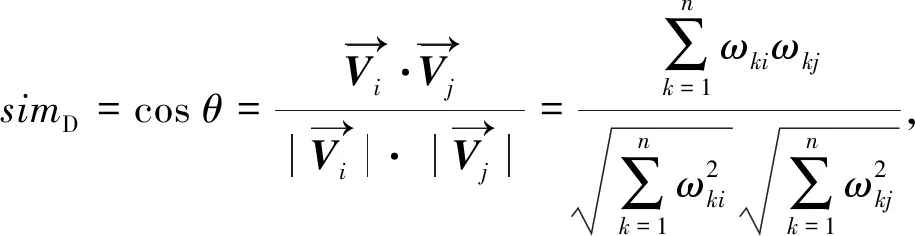
(4)
其中:θ是文档i,j的特征向量的夹角.
2.2.2tag标注相似性计算 tag信息也属于服务功能性描述,使用tag信息能够有效地提高服务聚类精度和查询效率,tag相似性根据Jaccard系数方法进行计算,
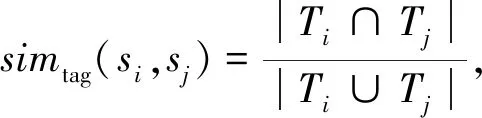
(5)
其中:分子表示同时标注两个服务的标签数;分母表示两个服务的标签集并集.
2.2.3相似性集成 结合服务描述文本相似性和tag标准相似性,获得两个服务之间的集成相似度公式为
sim(si,sj)=simD(si,sj)+simtag(si,sj).
(6)
2.3 基聚类结果的生成
基聚类结果的生成方法主要有3种:1) 使用不同的数据子集;2) 对算法赋予不同的参数;3) 使用不同的聚类算法等.

本文使用均匀性来表示分区P与参考集E中所有分区的多样性为
Uniformity(P,E)=1-(2η2(P))/(3η1(P)+Θ(P,E)),
其中:E是参考集;P是来自参考集E的分区,当lim(Uniformity(P,E))=0,代表区域P的多样性较低;当lim(Uniformity(P,E))=1,代表区域P的多样性较高;0≤Uniformity(P,E)≤1.本文将单个算法的均匀性与所有算法的均匀性的占比作为相似度矩阵WCS权重系数.
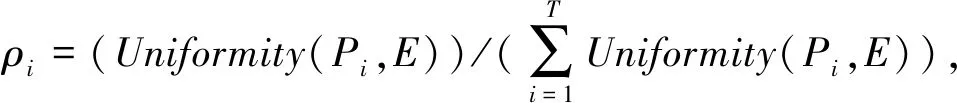
(7)
其中:T代表个体聚类结果的数目;Uniformity(Pi,E)代表第i个区域P与参考集E的均匀性.
2.4 基于权重的聚类集成方法
聚类集成的核心问题之一是如何根据这些由聚类成员得到的聚类结果,构造数据点之间的相似度矩阵.数据点xi,xj之间的相似度为
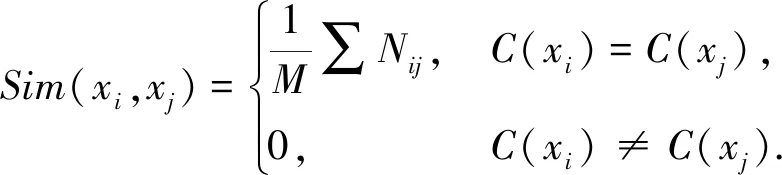
(8)
其中:xi,xj代表不同的数据点;M代表个体聚类结果的个数;Nij代表数据点xi,xj在M种基聚类算法划分中是否属于同一簇,若属于同一簇,Nij=1,否则,Nij=0;C(xi)代表来自簇C中xi数据点;C(xj)代表来自簇C中xj的数据点.
添加权重的相似度矩阵WCS的计算公式为
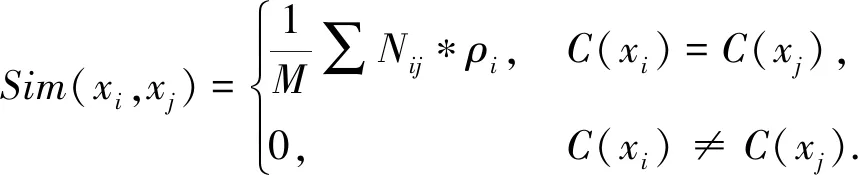
(9)
其中:xi、xj、M、Nij、C(xi)、C(xj)与公式(8)定义一样;ρi代表权重系数.
综上所述,SCWoC算法如下.
输入:服务特征数据集Z.
输出:最终服务聚类结果T.
1) 使用公式(1)~(4)生成文本相似性矩阵.
2) 使用公式(5)生成tag标注相似性矩阵.
3) 使用公式(6)集成服务文本相似性矩阵和tag标注信息相似性矩阵,得到服务相似矩阵Z.
4) 用不同的聚类算法对数据集Z进行聚类,聚类的结果放入一个参考集E中.
5) 使用公式(7)计算权重.
6) 使用式(8)、(9)计算加权相似度矩阵WCS.
7) 对WCS矩阵使用k-means算法进行聚类,得到服务聚类结果T.
3 实验
3.1 数据集
本文从ProgrammableWeb上爬取了4 800个API服务,每一个API服务包括服务名称、描述文本、tag标签、以及分类等信息.由于电脑条件的限制,数据量过大,本文从爬取的API服务中选取3个API类别,分别为Email(173个)、Video(172个)、Tools(255个),API数量总共为600个.同时,把聚类结果与原有分类作比较,验证试验的有效性.
表1为API服务数据的样式.其中desc中文本描述语句太长,文中不予描述,用符号…表示.

表1 API服务数据Tab.1 API service data
3.2 评价标准
本文采用纯度指标[24]和查全率来评价聚类的有效性.
令D为服务集合,C表示D上的聚类结果,ck∈C指的是一个聚类结果中的第k个簇,T为D上原有的标准聚类结果,tk∈T指的是标准聚类结果中的第k个簇,则ck的聚类纯度CP(ck)定义为

查全率=(succ(ck))/(succ(ck)+missed(ck)),其中:succ(ck)是成功聚类到ck中服务的数目;missed(ck)是本应该划分到ck中但是却划分到其他类中服务的数目.
3.3 实验过程及结果分析
使用表1中tags和desc数据分别生成tags相似度矩阵和desc相似度矩阵,然后通过这两个矩阵构建API服务间的相似度矩阵,之后对服务间相似度矩阵使用基聚类算法生成基聚类结果,通过权重集成得到最后的服务分类.在试验中,将本文所提的SCWoC方法与FCluster方法[25](基于服务相似性的k-means方法)和MSCA方法[23](融合k-means与Agnes的服务聚类方法)进行实验比较.本文SCWoC方法服务聚类结果及构成如表2所示.SCWoC方法、FCluster方法和MSCA方法在各类中的纯度和查全率对比如表3所示.

表2 聚类结果及结构构成Tab.2 Clustering results and structure
由表3可知SCWoC方法在各类中的纯度:类1、类2、类3的纯度分别为67.7%、65.9%、63.8%.SCWoC方法与FCluster方法和MSCA方法的平均纯度分别为65.8%、61.8%、63.1%.SCWoC方法相比与其他两种方法在聚类纯度上分别提升了4%和2.7%.

表3 三种方法的对比Tab.3 Comparison of three methods
表3还展示了3种方法查全率的比较,SCWoC方法、MSCA方法、FCluster方法的平均查全率分别为66.6%、62.8%、60.8%,可以得出SCWoC方法的平均查全率最高.
综上所述,SCWoC方法有效地提高了服务聚类的纯度和查全率.
4 结论
本文提出了一种基于群体智慧的服务聚类方法,从服务特征数据集入手利用群体智慧理论的独立性、分散性、多样性引导基聚类结果的生成,利用群体智慧的聚集性,采取基于权重的基聚类集成方法,对基聚类结果进行聚合,实现服务聚类.使用Web服务数据集验证了本文方法的有效性.实验结果表明,相较于传统的k-means服务聚类方法,提高了服务聚类的纯度和查全率.
猜你喜欢
科学大众(2020年10期)2020-07-24 09:14:12
当代陕西(2019年6期)2019-04-17 05:04:02
电子测试(2017年15期)2017-12-18 07:19:27
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
智能系统学报(2015年4期)2015-12-27 09:38:39
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
