
基于多尺度残差网络的压缩感知重构算法
2019-12-12 06:53练秋生富利鹏陈书贞石保顺
自动化学报 2019年11期
练秋生 富利鹏 陈书贞 石保顺
传统的奈奎斯特采样速率必须达到信号带宽的两倍以上才能精确重构出原始信号.然而随着科技的不断进步,所处理信号的带宽也在不断地增加,这对传统的采样系统提出了挑战.近年来,由Donoho 和Candes 等提出的压缩感知理论[1−4],突破了这一限制,其主要思想是利用随机测量矩阵ΦRm×n对信号Rn×1进行采样,将x投影到m维的低维空间,并证明这样随机投影的测量值Rm×1(yΦx)中包含了重构信号的足够信息,通过求解一个稀疏优化问题,利用投影在低维空间的测量信号可重构出原始信号.
在图像压缩感知问题中,测量值y的维度m远小于原始信号x的维度n,图像压缩感知重构本质上是求解一个欠定方程,如何从这个欠定方程中寻找出最优解是重构的关键.近年来众多学者提出了基于图像在某种变换域具有稀疏性的图像重构算法,该类算法利用lp(0≤p ≤1)范数衡量稀疏系数的稀疏性,通常使用正交匹配追踪(Orthogonal matching pursuit,OMP)算法[5],迭代硬阈值(Iterative hard-thresholding)算法[6]等求解对应的稀疏编码问题.还有学者提出利用梯度稀疏性[7]、非局部稀疏性[8]和块稀疏性[9]作为先验知识对原始信号进行重构,基于混合基稀疏图像表示[10],基于非局部相似性[11]的压缩感知图像重构算法也被提出.然而这些重构算法都需要进行复杂的迭代运算,重构时间较长,并且在较低的采样率下,重构图像质量较差.
深度学习自提出以来,在计算机视觉和图像处理方面,受到广泛关注,如,图像超分辨率重建[12]、图像语义分割[13]、图像去噪[14]等,并且在这些方面都呈现出较好的效果.最近,有学者将深度学习应用在压缩感知上,利用堆降噪自编码模型[15](Stacked denoiseing auto-encoders,SDA)和卷积神经网络(Convolutional neural network,CNN)[16]学习一个端到端的映射,利用测量值,通过网络直接重构图像.在文献[15]中,Mousavi 等利用SDA 训练得到测量值与重构图像的映射,使用该映射利用测量值进行图像重构.Kulkarni 等在文献[16]中提出的ReconNet 网络将两个SRCNN (11-1-7)模型[12]堆叠,在卷积网络前级联一个全连接层,实现了非迭代图像压缩感知重构,但重构质量相对较差.Yao 等将ReconNet 网络与残差网络[17]结构相结合提出了DR2-Net[18],网络由全连接层和四个残差块(12层卷积层)组成.DR2-Net 相对于ReconNet 网络提高了重构质量,但是由于含有较多的卷积层需要花费较长的重构时间.
本文在ReconNet 和DR2-Net 的基础上提出多尺度残差重构网络,使用不同尺寸的卷积核组合成多种感受野,捕捉图像中不同尺度的特征,进而重构出高质量的图像.在重构网络中,引入扩张卷积(Dilate convolution)[19],仅使用7 层卷积层,重构图像的质量优于DR2-Net,且重构时间比其短.
1 图像压缩感知重构
图像压缩感知重构主要是对图像进行随机投影采样,并利用图像在某种变换域的稀疏性作为先验知识,从少量测量数据中重构出原始图像.对于nW ×H的图像,将其向量化为Rn×1,取m×n维的测量矩阵Φ 对原始图像x进行采样得:

当时,式(1)是一个病态问题,存在无穷多个解.利用图像在变换域具有稀疏性的先验知识:

其中,Ψ 中的每一列是变换域的一个基向量,s是x在变换域Ψ 的稀疏系数组成的向量.对于式(2)可以通过求解下式的非凸优化问题:
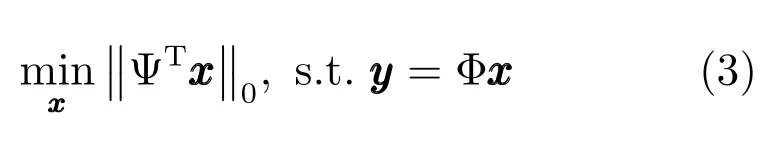
式(3)是一个典型的NP-Hard 问题,一般常用l1范数代替l0范数转化为凸优化问题即式(4):
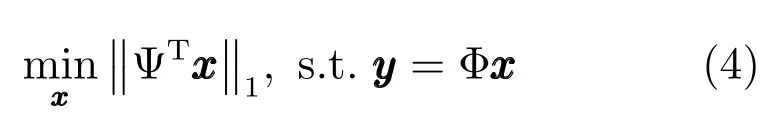
求解该问题时需要多次迭代运算,因此重构速度较慢.
传统的优化方法基本不能实现实时重构,如果用m×n的测量矩阵Φ 对图像nH×W进行采样时计算量和存储量比较大,影响重构速度.为了减少存储量,提高采样速度,对图像进行分块采样[20]重构.将图像分成B×B的小块,用相同的采样矩阵ΦB对图像块进行采样.则每个小块对应的测量信号表示为yiΦBxi,其中ΦB是一个nB×B2的行正交高斯矩阵.
2 重构网络
2.1 网络结构
如图1 所示,受文献[18]的启发,本文首先使用线性重构网络即一个全连接层对图像进行重构,得到原始图像xiRn×1的近似解,再通过多尺度残差网络学习与原始图像xi的残差di,最终得到高质量的重构图像.

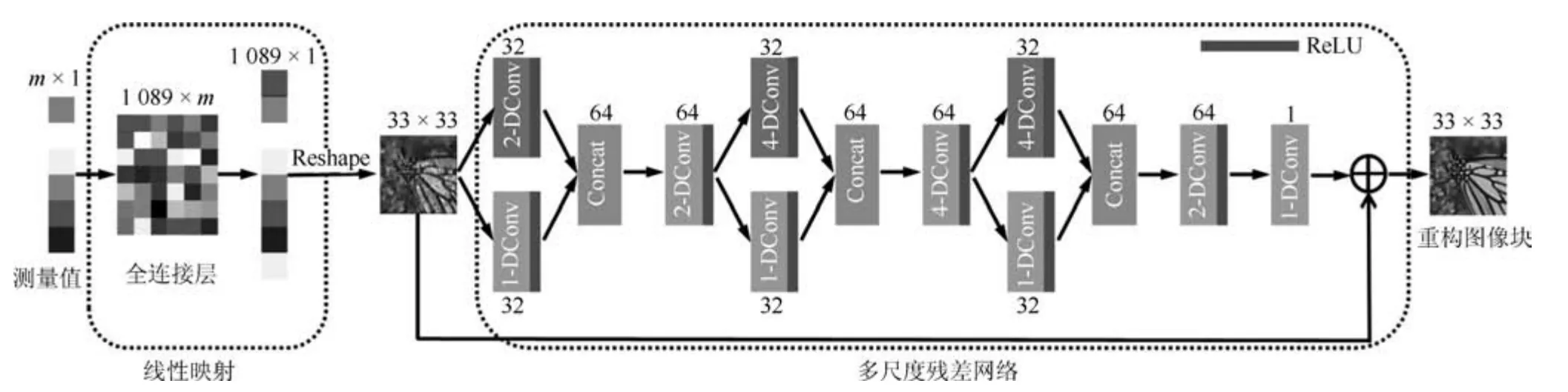
图1 多尺度残差重构网络(MSRNet),s-Dconv 表示扩张卷积, s 1,2,4Fig.1 Mult-scale residuce recontruction network,s-Dconv denotes s-dilate convolution,here s 1,2 and 4
2.2 线性生成网络
在文献[18]中,使用一层全连接层对图像进行初等的重构.本文在图像重构过程中也引入这一结构.训练集包含N个训练样本即{(y1,x1),(y2,x2),···,(yN,xN)},yiRm×1为测量值,yiAxi,Rm×n为随机行正交的高斯矩阵,xiRn×1为对应的图像块,损失函数使用均方误差函数如式(6)所示:
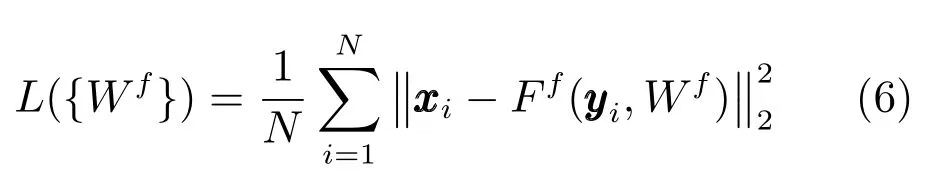
使用Adam (Adaptive moment estimation)[21]方法进行训练,优化得到WfR1089×m,使得 式(6)最小.Ff(·)表示由一个全连接层组成的线性映射,网络Ff(·)包含1 089 个神经元,训练完成后利用测量值yi通过式(7)重构得到xi的近似解.
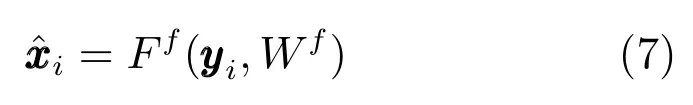
2.3 多尺度残差网络
线性映射网络Ff(·)重构出的图像,图像质量较差,为了提高重构图像的质量,引入多尺度残差网络Fmsr(·).
如图1 所示,线性网络的输出作为多尺度残差网络Fmsr(·)的输入,通过网络输出大小为33×33的图像块.多尺度残差网络有7 层卷积核大小为3×3 的卷积层,除最后一层其他所有卷积层的激活函数为ReLU (Rectified linear units)[22],第1 层到第6 层输出64 个特征图,第7 层输出一个特征图.网络中有3 层多尺度层,分别是第1 层、第3 层和第5 层,每一个多尺度层由两种不同扩张因子的扩张卷积组成,第1 层扩张因子s为1 和2,第3、5 层的扩张因子s为1 和4,每一种扩张卷积输出32 个特征图,然后将每一层输出的特征图级联,输出64个特征图.为了增大网络的感受野,剩下的卷积层也使用扩张卷积,第2,4,6,7 层的扩张因子s分别为2,4,2,1.
测量值yi作为网络的输入,首先由线性映射层Ff(·)重构出一幅中间图像,再通过多尺度残差网络Fmsr(·)估计出残差di,最后由式(8)得到重构图像

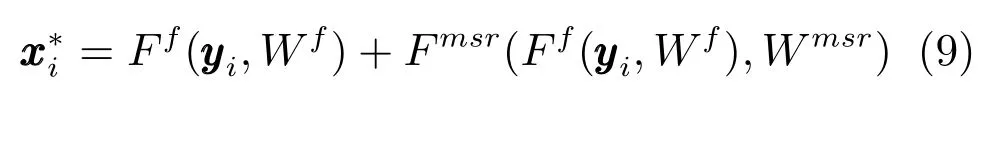
将式(6)求解所得的Wf作为式(9)中Wf的初始值,使用Adam 算法更新MSRNet 中的参数Wf和Wmsr.所使用的损失函数为均方误差(Mean squared error,MSE)损失函数,即式(10):
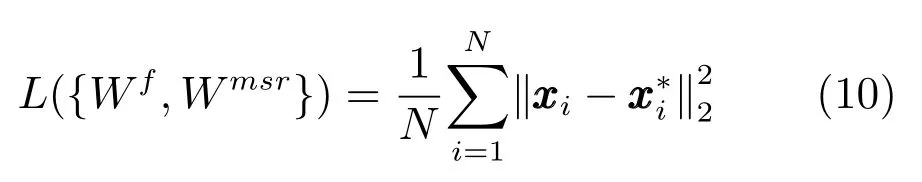
其中,N表示训练集中样本的数目,yi为压缩感知测量值,xi为yi对应的图像块标签,为网络的输出即重构图像块.
2.4 多尺度卷积层
卷积神经网络中的卷积核常常用来提取图像中的特征,但是相同尺寸的卷积核只能提取同一尺度特征,MSRNet 在同一层使用两种不同尺寸的卷积核提取图像中不同尺度的特征,通过级联操作(Concat)将多尺度层的特征信息融合作为下一层的输入.本算法分别在网络的第1 层、第3 层和第5 层使用多尺度层,组合成多种感受野,捕获图像中不同尺度的特征,提高图像的重构质量.多尺度层如图2 所示,由一个卷积层和一个级联层组成.s1和s2为不同值的扩张因子,将3×3 的卷积核扩张为不同尺寸大小的卷积核,组成多尺度卷积层.每一个卷积核输出32 个特征图,再通过级联层将不同尺度的特征融合为64 个特征图,作为下一层的输入.
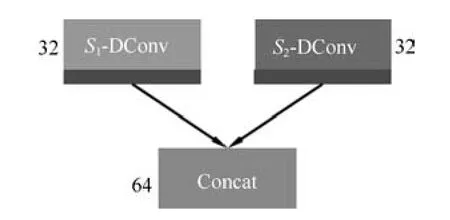
图2 多尺度卷积层Fig.2 Multi-scale convolution layer
2.5 使用扩张卷积增大网络感受野
图像重构过程中,感受野是非常重要的,大的感受野可以捕捉更多的图像信息,提高图像重构质量.在卷积神经网络中,一般使用大尺寸的卷积核、增加卷积层的层数和引入池化层(Pooling layer),来增加网络的感受野.但是随着卷积核的增大和网络层数的增加,网络的计算复杂度也会增加,使得图像重构时间变长.池化虽然没有增加网络的计算复杂度,但是丢失了许多的信息,导致重构图像质量较差.本文引入文献[19]中的扩张卷积来增大网络的感受野.扩张卷积增大了网络的感受野,但不增加网络的参数,使得图像重构速度较快.例如,使用扩张因子s2 对3×3 的卷积核进行扩张,得到(2s+1)×(2s+1)即5×5 的卷积核,该卷积核有9 个位置不为零,其余位置都为零,感受野从原来的3×3 变为5×5,如图3 所示,左边为普通的卷积,右边为s2 的扩张卷积.
在MSRNet 网络中引入多尺度卷积核用来提取图像中不同尺度的特征,提高重构图像的质量.本文在第1 层、第3 层和第5 层分别加入多尺度卷积核,使得MSRNet 有多种感受野,其尺寸分别为25×25、27×27、31×31、33×33、37×37 和39×39.网络中不同大小的感受野可以捕获图像中不同尺度的特征,从而提高重构图像的质量.

图3 扩张卷积Fig.3 Dilate convolution
2.6 重构过程
在图像重构过程中,给出一幅图像,对图像进行非重叠取块,块大小为33×33.用随机行正交高斯矩阵对每一个图像块进行采样,得到的测量值y作为MSRNet 网络的输入,重构出高质量的图像块.由于MSRNet 所重构出的图像块在测量矩阵上的投影与测量值具有一些误差,所以本文对重构图像进行修正,进一步提高图像的重构质量.利用式(11)对重构图像进行修正:

其中,为修正后的重构图像块,为网络重构的图像块,A为随机行正交的高斯采样矩阵.在式(11)中,这一项衡量重构图像块在测量矩阵上投影与测量值的误差,使得修正后的图像块与网络重构图像块更加接近,实验中令参数λ1.对式(11)求导,令导数为零,得

其中,I为1 089×1 089 的单位阵.然后使用BM3D[23]去除块效应,再通过式(12)进行一次修正,最终获得一幅高质量的重构图像.利用式(12)进行修正时,(ATA+λI)−1计算一次即可,因此在修正过程中只需计算(ATy+)这一项,修正过程时间复杂度较低.
图4 显示了Barbara 重构图像块修正前后在测量矩阵上投影与测量值误差的比较,明显可以看出修正后的图像块在测量矩阵的投影与测量值更加接近.误差Error 为重构图像在测量矩阵的投影与测量值的差的l2范数,N为重构图像块的序号.
3 网络的训练
3.1 训练多尺度残差网络
本文使用和文献[16]一样的训练集,共91 幅图像.将图像分别放缩到0.75、1、1.25 三个不同的尺度得到273 幅图像.不同的颜色空间对图像分类、图像分割有一定的影响[24],但对图像重构方面影响较小.为了公平起见,本文采用与ReconNet 和DR2-Net 相同的颜色空间,将RGB 图像空间变换到YCrCb 图像空间,选取亮度通道,对图像进行取块操作,块大小为33×33,取块步长为14.为了增加训练集中图像数量,分块前对图像做翻转,旋转等操作,最终得到128×5 414 块图像块.再对图像块进行随机投影,将33×33 的图像块向量化为1 089×1 维的向量.本文采用4 种不同的采样率对图像块进行采样,分别是0.25、0.1、0.04、0.01,每一个图像块有1 089 个像素,所以测量值yi的长度分别是272、109、43、10.训练过程中使用图5 中的图像作为测试集.使用Tensorflow[25]深度学习开源工具训练网络,所有实验均在Inter Core i5-7500 CPU,主频3.4 GHz,内存16 GB,显卡GTX 1080ti平台下完成.

图4 重构图像块修正前后误差的比较(Barbara 图像)Fig.4 The comparison of the error of the reconstructed image block before and after refined (Barbara)

图5 标准测试集图像Fig.5 Standard test set images
3.2 网络参数初始化
训练线性生成网络Ff(·)时,使用均值为0,方差为0.01 的高斯矩阵初始化权重,偏置初始化为0.训练多尺度残差网络Fmsr(·)时,所有卷积层的权重,使用Xavier[26]初始化方法进行初始化,偏置初始化为0.
3.3 网络训练参数设置
网络分两步进行训练,首先使用比较大的学习率训练子网络Ff(·),学习率为0.001,最大迭代次数为1 000 000,每训练200 000 次学习率衰减为原来的0.5 倍.子网络Ff(·)训练完成后,使用较小的学习率对整个网络进行训练,迭代120 轮、学习率为0.0001,每训练40 轮学习率衰减为原来的0.5倍.使用Adam[21]方法训练网络,动量因子分别为0.9 和0.999.图6 为训练期间采样率为0.10、0.25时,损失函数随迭代次数的衰减曲线.图中损失函数的值随迭代次数的增加逐渐降低,当迭代到40 轮时,学习率衰减为原来的0.5 倍,损失函数的值会骤降,迭代到80 轮时,学习率继续衰减0.5 倍,损失函数的值变化较小,随着迭代次数的增加,曲线趋于平稳,网络收敛.
4 实验结果
4.1 重构结果
本文与已有的五种算法进行比较,这五种算法分别是TVAL3[27]、NLR-CS[28]、DAMP[29]、ReconNet、DR2-Net.前三种是基于迭代优化的算法,后两种是基于深度学习的算法.实验结果如表1 所示,在测量值没有噪声的情况下,本文算法具有较好的重构效果.图7 显示,本文提出的算法能够有效地重构出图像的细节,在采样率较大时重构图像中含有的伪迹较少.
表1 显示了6 幅测试图像在不同算法不同测量率下的PSNR 和图5 中11 幅测试图像的平均PSNR.TVAL3、NLR-CS 和D-AMP 使用文献[16]提供的结果,表中“w/o BM3D”表示未使用BM3D去除块效应,“w/BM3D”表示使用BM3D 去除块效应,“平均PSNR”表示图5 中11 幅图像的平均PSNR.从表1 中看出,多尺度残差网络(MSRNet)的重构图像平均PSNR 最高.在较高的采样率下,基于深度学习的算法ReconNet 重构性能低于传统的优化迭代算法TVAL3、NLR-CS、DAMP.但是本文算法和DR2-Net 的重构性能优于上述三种算法,相比于上述五种算法,本文算法重构图像质量较好.例如,在MR0.25 的情况下,平均PSNR 比DR2-Net 高0.82 dB,高于NLR-CS算法1.43 dB.在较低采样率下,传统的优化迭代算法TVAL3、NLR-CS、D-AMP 基本不能够重构出有意义的图像,但是基于深度学习的算法Recon-Net、DR2-Net、MSRNet 都能重构出图像的大致信息,且本文算法性能优于ReconNet 和DR2-Net.
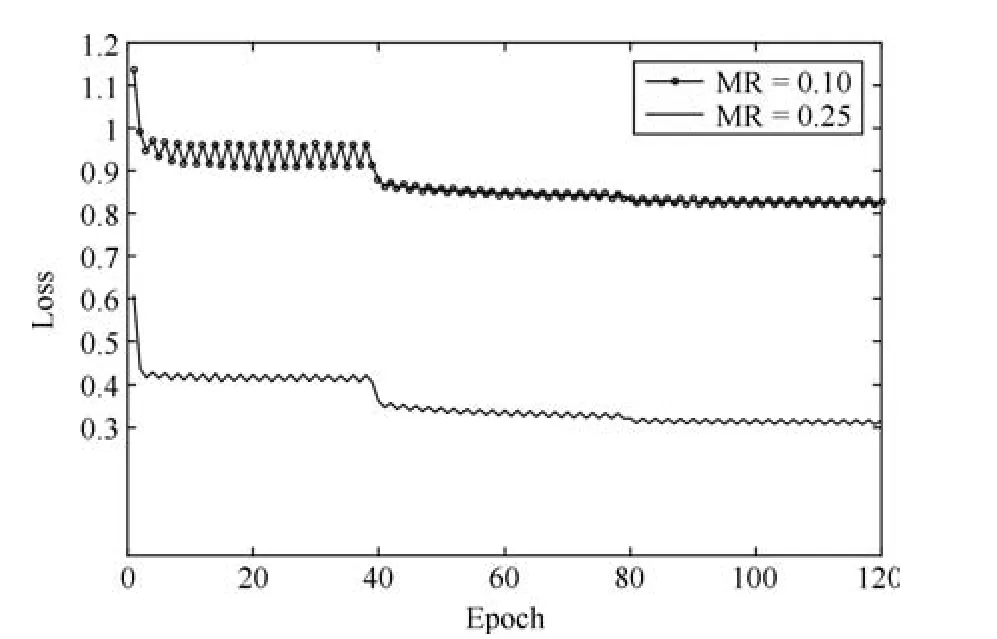
图6 训练期间的损失Fig.6 The network losses in training phase
图像重构质量的评价也应该包含人的视觉效果.结构相似指数(Structural similarity index,SSIM)是衡量两幅图像的相似度.SSIM 越接近于1,表示两幅图像越相似.比较结果如表2 所示,本文算法的平均SSIM 明显高于其他算法,重构图像质量不仅PSNR 值比较高,且有较好的视觉效果.
图8 显示了修正前后的Barbara 图像,从图中可以看出修正后的图像块效应明显减少,与修正前图像相比细节更加清晰.如表3 所示,修正后的重构图像PSNR 和SSIM 均有不同程度的提高,有更好的视觉效果.
4.2 扩张卷积对图像重构性能的影响
扩张卷积能够增大网络的感受野,本文算法中所有的卷积层都使用扩张卷积.为了比较使用扩张卷积的网络与普通卷积网络的重构性能,本文设计了一组对比实验,训练两个网络,即采用普通卷积的网络和采用扩张卷积的网络,分别对BSD500 数据集和图5 中的11 幅图像进行测试.测试结果如表4、5 所示,在图5 中测试集上,当采样率为0.25、0.10、0.04 和0.01 时,使用扩张卷积网络的重构图像平均PSNR 分别高于普通卷积网络0.43 dB、0.37 dB、0.18 dB 和0.04 dB.在BSD500 测试集上,使用扩张卷积网络的重构图像平均PSNR 也都高于普通卷积网络.结果表明,使用扩张卷积的网络重构性能优于普通卷积网络.
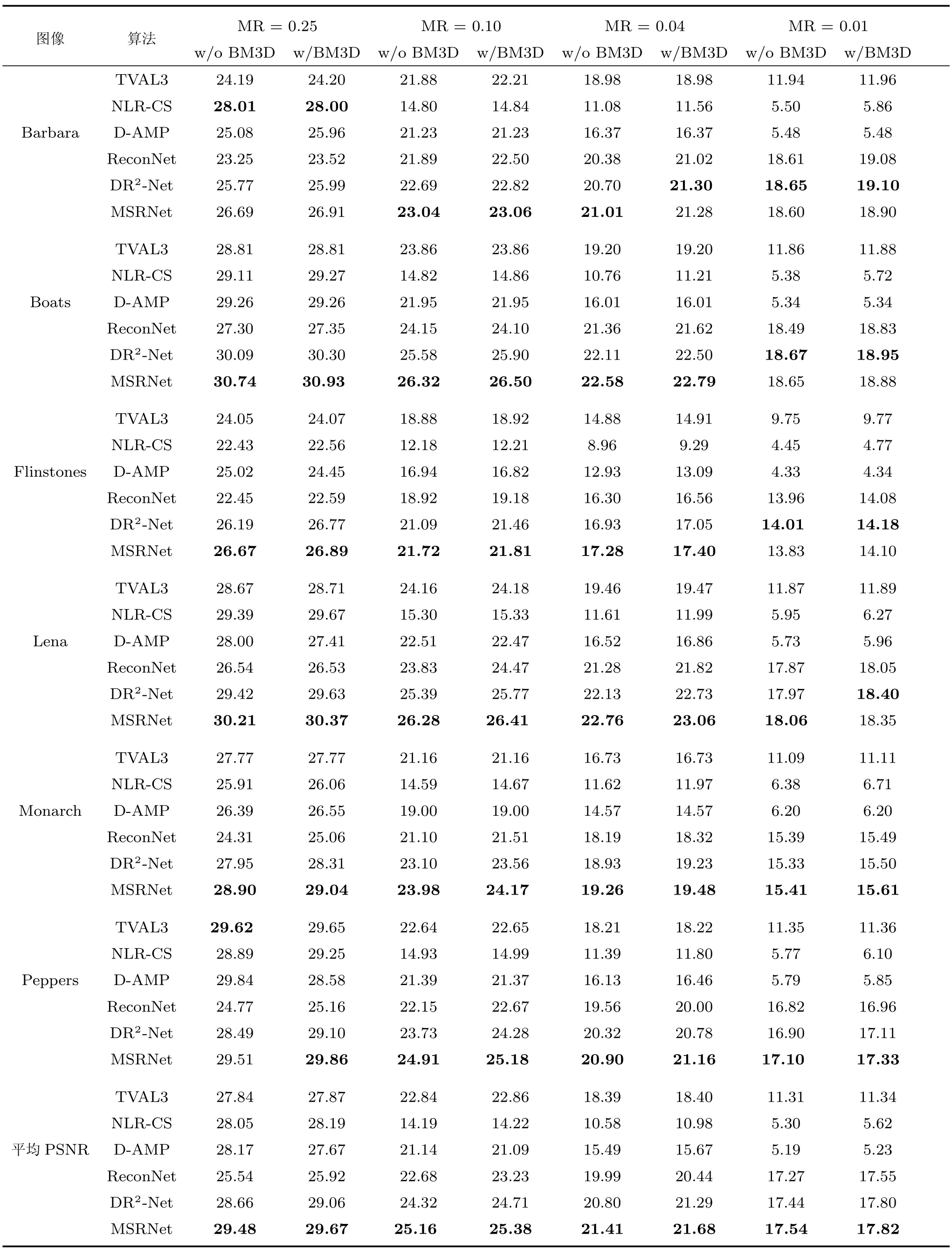
表1 6 幅测试图像在不同算法不同采样率下的PSNRTable 1 PSNR values in dB for six testing images by different algorithms at different measurement rates

图7 比较几种算法的重构性能(第1 行到第3 行采样率MR 0.25,0.10,0.04)Fig.7 Comparison of reconstruction performance of various algotithms (MR 0.25,0.10,0.04)
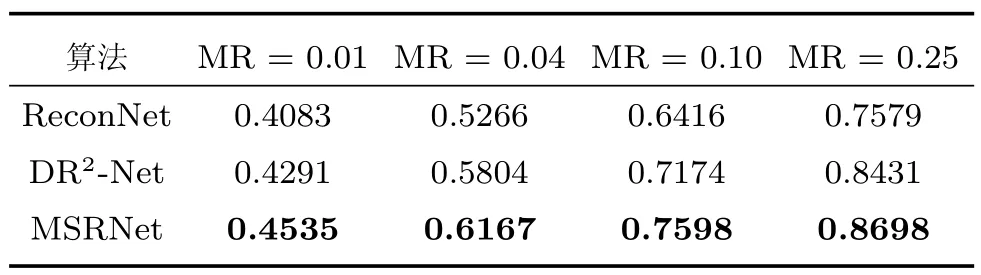
表2 不同算法下11 幅测试图像平均SSIMTable 2 Mean SSIM values for 11 testing images by different algorithms

图8 修正前后的重构图像对比(MR 0.25)Fig.8 The comparison of reconstructed images before and after refined (MR 0.25)
4.3 时间复杂度
重构时间也是比较的重要标准之一.基于深度学习的重构算法比传统的迭代算法快100 多倍[16],所以只比较MSRNet 和其他基于深度学习算法的重构时间.为了公平起见,表6 只比较网络重构图像所消耗的时间.如表6 所示,与DR2-Net 相比,本文算法重构时间较短.与ReconNet 相比,重构时间基本相同,但本文算法重构性能较好.
4.4 大数据集下的评估
为了验证本文算法在大测试集上的泛化能力,比较MSRNet、DR2-Net 和ReconNet 在BSD500(该数据集包含500 张图像)上的重构性能.MSRNet、DR2-Net 和ReconNet 的模型参数都是基于相同训练集训练得到的.如表7 所示(重构图像未经修正),本文算法在BSD500 测试集下也表现出较好的重构性能.在采样率为0.25、0.10、0.04 和0.01 时,MSRNet 的重构图像平均PSNR 和SSIM都高于DR2-Net.实验表明,本文算法在大的测试集中也能表现出较好的重构性能.

表3 MSRNet 重构图像修正后11 幅测试图像的PSNR (dB)和SSIMTable 3 The PSNR (dB)and SSIM of 11 test images of refined MSRNet reconstruction

表4 不同卷积方式在图5 的测试集中重构图像的平均PSNR (dB)Table 4 Mean PSNR in dB for testing set in Fig.5 by different convolution
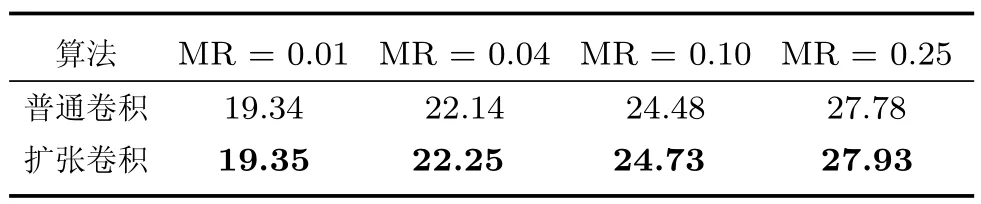
表5 不同卷积方式在BSD500 测试集中重构图像平均PSNR (dB)Table 5 Mean PSNR in dB for BSD500 testing set by different convolution
4.5 网络的抗噪性能
对图像测量值添加四种不同水平的高斯噪声,噪声强度0.01、0.05、0.10、0.25.使用的MSRNet模型是在无噪测量值下训练得到的.如表8、9 所示(重构图像未经修正),在采样率MR0.25、0.10时四种不同噪声强度下,本文算法重构图像的平均PSNR 均高于ReconNet 和DR2-Net,尤其在MR0.25,噪声强度σ0.25,图5 中的测试集上重构图像的平均PSNR 比ReconNet 和DR2-Net 分别高4.31 dB 和4.14 dB.在测试集BSD500 上,本文算法在不同噪声的强度下,对图像的重构性能也优于ReconNet 和DR2-Net.因此,本文算法相比ReconNet、DR2-Net 对噪声具有更好的鲁棒性.

表6 重构一幅256×256 图像的运行时间(s)Table 6 Time (in seconds)for reconstruction a single 256×256 image

表7 不同算法在BSD500 测试集的平均PSNR (dB)和平均SSIMTable 7 Mean PSNR in dB and SSIM values for BSD500 testing images by different algorithms

表8 比较ReconNet、DR2-Net 和MSRNet 三种算法对高斯噪声的鲁棒性(图5 中11 幅测试图像)Table 8 Comparison of robustness to Gaussian noise among of ReconNet,DR2-Net,MSRNet(11 testing images in Fig.5)

表9 比较ReconNet、DR2-Net 和MSRNet 三种算法对高斯噪声的鲁棒性(BSD500 数据集)Table 9 Comparison of robustness to Gaussian noise among of ReconNet,DR2-Net,MSRNet (BSD500 dataset)
5 结论
本文提出了一种基于深度学习的多尺度残差网络结构,利用测量值通过网络重构图像.网络引入多尺度卷积层用来学习图像中的多尺度信息,重构网络中使用扩张卷积增大网络中的感受野从而重构出高质量的图像.最后,本文算法对网络重构图像进行了修正,使得重构图像在测量矩阵上的投影更加接近测量值.在常用的11 幅测试图像和BSD500 测试集的实验结果进一步表明了本文的算法相比于其他几种算法在图像重构质量和重构时间拥有更好的表现,并且对噪声具有鲁棒性.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
中国生殖健康(2020年7期)2020-12-10
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
自动化学报(2019年6期)2019-07-23
商周刊(2017年6期)2017-08-22
太空探索(2016年5期)2016-07-12
