
基于分部评分模型思路的多级评分认知诊断模型开发*
2019-12-12 05:54:38高旭亮汪大勋涂冬波
心理学报 2019年12期
高旭亮 汪大勋 王 芳 蔡 艳 涂冬波
基于分部评分模型思路的多级评分认知诊断模型开发*
高旭亮1,2汪大勋1王 芳2蔡 艳1涂冬波1
(1江西师范大学心理学院, 南昌 330022) (2贵州师范大学心理学院, 贵阳 550000)
基于分部评分模型的思路, 本文提出了一般化的分部评分认知诊断模型(General Partial Credit Diagnostic Model, GPCDM), 与国际上已有的基于分部评分模型思路的多级评分模型GDM (von Davier, 2008)和PC-DINA (de la Torre, 2012)相比, GPCDM的Q矩阵定义更加灵活, 项目参数的约束条件更少。Monte Carlo实验研究表明, GPCDM模型的参数估计精度指标RMSE介于[0.015, 0.043], 表明估计精度尚可; TIMSS (2007)实证数据应用研究表明, 与GDM和PC-DINA模型相比, GPCDM与该数据的拟合度更好, 并且使用GPCDM分析该数据的诊断效果也更优。总之, 本研究提供了一种约束条件更少、功能更为强大的多级评分认知诊断模型。
认知诊断; 多级评分认知诊断模型; GDM; PC-DINA
1 引言
目前, 教育评估和心理计量学的最新发展越来越强调形成性评估(Formative Assessments), 它可以提供更多的信息来改进学习和教学策略。认知诊断评估(Cognitively Diagnostic Assessments, CDA)旨在测量特定的知识结构和加工技能, 从而为教师和学生提供即时的诊断信息, 以便对课堂教学进行相应的规划或修改, 以促进个体的全面发展(de la Torre & Minchen, 2014; Leighton & Gierl, 2007)。特别地, 美国2001年通过了《不让一个孩子掉队法》法案(No Child Left Behind Act of 2001), 法案要求测验要给学生、家长和老师提供有价值的诊断性报告, 报告要包括关于学生在解决问题时所需的基础知识和认知处理技能等方面的掌握信息, 从而为学生提供量身定制的教育服务。美国政府2015年再次通过了每个学生成功(Every Student Succeeds Act)教育法案, 新法案继续强调测验要为学生及家长提供诊断性评价、形成性评价。我国在2010年通过的《国家中长期教育改革和发展规划纲要(2010−2020年)》强调要注重因材施教, 减轻学生负担, 改革教学评价制度, 建立科学的教育质量评价体系等。从国内外的教育政策可见, CDA在未来的教育评估领域将会发挥更大的作用。
当前, 研究者已经开发了大量的二级(0-1)评分认知诊断模型(Cognitive Diagnosis Model, CDM), 然而在实际教育和心理评估测验中存在大量多级评分的数据, 例如, 心理测验中经常使用李克特型(Likert-type)量表问卷, 在态度倾向性的问卷中, 使用“完全不同意”, “不同意”, “不确定”, “同意”和“完全同意”等5个选项来表示不同程度的态度倾向, 每个选项代表不同的得分。不仅如此, 与二级评分的题目相比, 多级评分题目可以提供更多的信息, 它只需要更少的题目就能达到和较多二级题目同样的测量精度(van der Ark, 2001)。
为了分析多级评分数据, 一个常用的方法是将多级评分数据转换为二级评分, 然后再使用二级评分的CDM来分析(Templin & Henson, 2006)。然而, 经过转换之后必然要损失很多有价值的信息, Ma和de la Torre (2016)以及Tu, Zheng, Cai, Gao和Wang (2017)的研究均发现, 与使用多级评分模型相比, 使用二级评分模型分析多级评分数据会在很大程度上降低测验的精度。
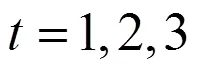
在CDA领域, 研究者已经开发了少量的多级评分CDMs (polytomous CDMs)。但是已有的多级评分CDMs主要是属于累积概率(cumulative probability)模型和连续比率(continuation ratio)模型。Hansen (2013)借鉴Samejima (1969)等级反应模型(Graded Response Model, GRM)的思想, 提出了多级评分的LCDM模型。涂冬波、蔡艳、戴海琦和丁树良(2010)基于等级反应模型(GRM)的建模思路提出了多级评分的DINA模型(polytomous DINA, P-DINA)。蔡艳、苗莹和涂冬波 (2016)在P-DINA模型的基础上加以改进, 提出了拓广的P-DINA (Generalized P-DINA, GP-DINA)模型。Ma和de la Torre (2016)在G-DINA模型的基础上提出了序列加工G-DINA模型(sequential G-DINA), 序列加工G-DINA模型是基于连续比率(continuation ratio)模型的一个特例。
然而, 目前对于相邻类别(adjacent category)或者分部评分(partial-credit)类的多级评分CDMs的研究还相对薄弱。已有的分部评分多级CDMs模型仅有von Davier (2008)提出的一般诊断模型(General Diagnostic Model, GDM)和de la Torre (2012)提出的分部评分DINA (Partial CreditDINA, PC-DINA)模型。但这两个模型具有以下缺陷:
(2) 其次, 对于GDM模型而言, 它假设属性之间不存在交互效应, 即它只考虑了属性的主效应。而在实际的数据中, 属性之间常常存在交互效应, 即被试答对题目的概率不仅受到属性主效应的影响, 还受到属性之间交互效应的影响; (3)对于PC-DINA模型来说, 它是基于DINA模型而提出的, DINA模型假设属性没有主效应, 仅有所有属性间的交互效应, 它属于具有严格理论假设的简单模型, 因此, 它不具一般性认知诊断模型的优势。

表1 两种不同类型的Q矩阵示例
基于此, 本研究重点关注基于分部评分模型的建模思路, 开发出新的功能更为强大的多级评分认知诊断模型, 以弥补当前国际上基于分部评分模型思路的多级评分CDMs (如GDM和PC-DINA)的不足。新开发的模型不仅将属性定义在得分类别水平(属性的定义更加精细), 而且它以G-DINA模型作为加工函数, 因此具有一般性认知诊断模型的优势。
2 基于分部评分模型思路的多级评分CDM开发
基于局部logit (local logit) 函数的定义, 定义了以下一般化的分部评分认知诊断模型(General Partial Credit Diagnostic Model, GPCDM)表达式:


假设题目的满分是3分, 即有4个得分类别(0, 1, 2, 3), 此时, 可以得到每个得分类别的答对概率, 如下所示:

化解公式3的方程组, 可以得到如下公式:

通过公式4, 进一步可以概括出GPCDM模型的每个得分类别的一般化公式:
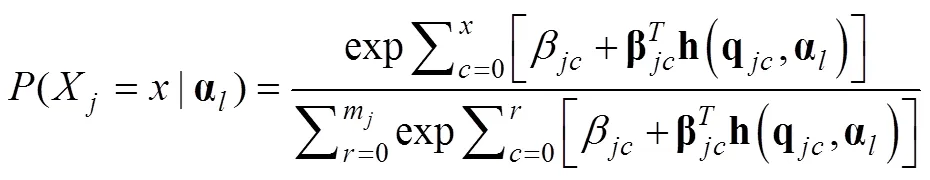
如果将Q矩阵定义在题目水平, 即使用Item-Q时, 并且假设属性没有主效应, 仅保留属性间的最高阶交互效应, 则公式(1)可以简化为:


综上, 已有的分部评分CDMs都将Q矩阵定义在题目水平, 而GPCDM的Q矩阵定义更加灵活, 它可以定义在题目水平和得分类别水平; 当Q矩阵定义在得分类别时, 即Q矩阵的定义更加精细, 有助于提供更多的诊断信息。在实际应用中, 使用者可以根据自身的需求灵活选择不同类型的Q矩阵。另外, GDM和PC-DINA的理论假设均比较严苛, 在应用中具有较大的限制。而GPCDM的约束条件更少, 因而, 理论上GPCDM在实际应用中更加灵活, 更具优势。
3 参数估计
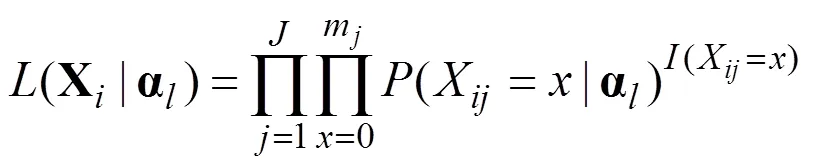


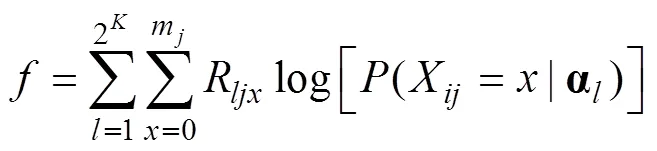
本研究的参数估计程序使用R软件来编写, 在R软件中optim函数包含了几种常用的极值优化算法。optim函数在R里的表达式是optim (par, fn, method), par代表项目参数初值, fn代表目标函数, method可选择的优化算法, 因此, 使用optim函数计算极值时只需要输入par (项目参数初值), 初值可以从均匀分布中随机生成, fn (目标函数)和选择的优化算法即可。
EM算法每循环一次, 就验证是否达到收敛条件, 如果达到收敛条件, 则迭代停止, 否则, 重复E步和M步。最后, 通过EM算法得到项目参数后, 采用期望后验(Expected a Posteriori, EAP)方法来估计被试参数(属性掌握模式)。
4 实验1: Monte Carlo实验研究
实验1旨在检验: (1)GPCDM模型的参数估计精度及其性能; (2)当采用Cat-Q矩阵生成数据时, 如果采用Item-Q矩阵分析数据是否会降低参数估计的精度, Item-Q可以从Cat-Q得到, 例如, 表2中的第1题得分类别1和2考察的属性向量分别是(1, 0, 0, 0, 0)和(0, 1, 0, 0, 0), 而Item-Q中得分类别1和2考察的属性向量都是(1, 1, 0, 0, 0)。
自变量包括: (1)样本容量(500, 1000, 2000和4000)。(2)属性个数(5个和7个); 5属性和7属性的Cat-Q见表2和表3, 多级评分题目中每个得分类别最多考察2个属性, 并且Cat-Q中每个属性的测量次数都是相同的。另外, 为了提高诊断测验的效果, 5属性和7属性的Cat-Q分别包含了5个和7个二级评分的题目, 且这些测验包括了一个完整的可达矩阵(R阵)。(3)测验长度, 5属性时包括20和40题, 7属性时包括25和50题, 40题和50题的Cat-Q与20题和25题的Cat-Q是重复关系。为了减少随机误差, 每种条件下重复模拟实验100次。

表2 5属性的Cat-Q矩阵

表3 7属性的Cat-Q矩阵
4.1 参数的模拟
4.1.1 被试参数的模拟

4.1.2 题目参数的模拟
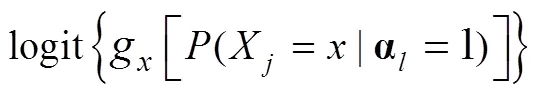

4.1.3 作答数据的模拟
4.2 评价标准
评价标准包括被试参数和项目参数的返真性, 它们的返真性分别用模式判准率(Pattern Match Rate, PMR)和均方根误差指标(Root Mean Square Error, RMSE)来反映(Ma & de la Torre, 2016)。两个指标的计算公式如下:
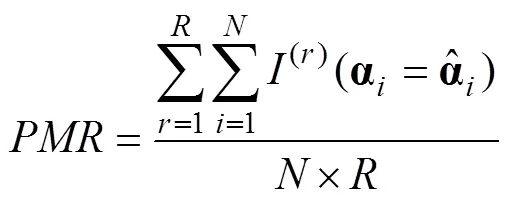

4.3 实验结果
表4和表5分别显示了各种实验条件下的测验PMR指标和RMSE指标。
需要强调的是, 作答数据是基于类别水平Q矩阵(Cat-Q)生成的。因此, 为了评估参数估计的精度, 主要关注Cat-Q的结果。从表4的结果可见, 属性个数等于5且使用Cat-Q时, 测验长度在20题时, 不同样本容量下的PMR值都在0.94以上, 而当测验长度增加到40题时, 不同样本容量下的PMR值均在0.99以上。当属性个数等于7且使用Cat-Q时, 在测验长度为25题时, 不同样本容量下的PMR值都在0.86以上, 而在测验长度为50题时, 不同样本容量下的PMR值都在0.98以上。

表4 各种实验条件下被试参数返真性PMR值
表5的结果显示, 当使用Cat-Q时, 不管属性个数、测验长度和样本容量如何变化, 在所有条件下的测验RMSE值均在0.05以下。随着样本量的增加, RMSE也随之降低, 例如, 属性个数等于5和测验长度等于20时, 在样本容量为500的条件下, 基于Item-Q和Cat-Q的RMSE值分别是0.103和0.043, 同样的条件下, 当样本容量增加到4000时,基于Item-Q和Cat-Q的RMSE值分别降低到0.053和0.015。
表6显示了在属性个数为5, 样本容量为1000, 测验长度为20题时, Cat-Q和Item-Q条件下每一题的RMSE指标, 由于其他实验条件下的结果和表6有相似的趋势, 因此, 限于篇幅的原因, 只提供了一种条件下的结果。
从表6的结果可以发现, 由于后5题是二级评分的题目, 此时Cat-Q和Item-Q是等价的, 因此Cat-Q和Item-Q的RMSE值基本相当, 而在多级评分的前15题中, 基于Cat-Q得到的RMSE值始终要小于基于Item-Q的RMSE值, 基于Cat-Q的最大RMSE是0.036。另外, 还可以发现, 二级评分题目的RMSE要略低于多级评分的题目, 这是因为, 二级评分题目考察的属性个数要少于多级评分题目。这个结果充分表明, EM算法可以提供精确的参数估计精度, 和Item-Q相比, 使用Cat-Q有助于提供更多有价值的诊断信息, 从而提高诊断测验的精度。
从表4和表5基于Cat-Q的结果可以发现, 当属性个数等于5或7时, 基于Cat-Q的PMR在短测验(20题和25题)时, 分别达到了0.9和0.8以上, 而在长测验条件下(40和50题)时, 它们的PMR值都在0.95以上, 它们的RMSE值均在0.05以下。这充分说明本研究提出的模型参数估计算法可以提供稳健、精确的估计精度。
对比基于不同类别Q矩阵的结果可以发现, 在同样的实验条件下, 与基于Cat-Q结果相比, 基于Item-Q导致更低的PMR值, 和更高的RMSE值。这两种Q矩阵之间的差异尤其在短测验(5属性时20题或7属性时25题)或被试人数较少(例如500人时)的条件下更加明显, 例如, 当属性个数等于7, 测验长度为20, 被试人数为500人时, 从表4可以看出, 使用Cat-Q时的PMR值大约是0.86, 而当使用Item-Q时的PMR值大约是0.82。而从表5可以发现, 在同样的条件下, 使用Cat-Q时的RMSE值大约是0.04, 而使用Item-Q时, 它的RMSE值则大约是0.1。这些结果都表明如果采用Item-Q来分析Cat-Q产生的数据确实会降低项目参数和被试参数的估计精度。这个结论启发实际使用者, 在编写多级评分的诊断题目时, 对于Q矩阵的标定, 应尽量构建基于得分类别的测验Q矩阵(即Cat-Q), 使用Cat-Q有利于提供更多的诊断信息, 从而提高诊断的精度。
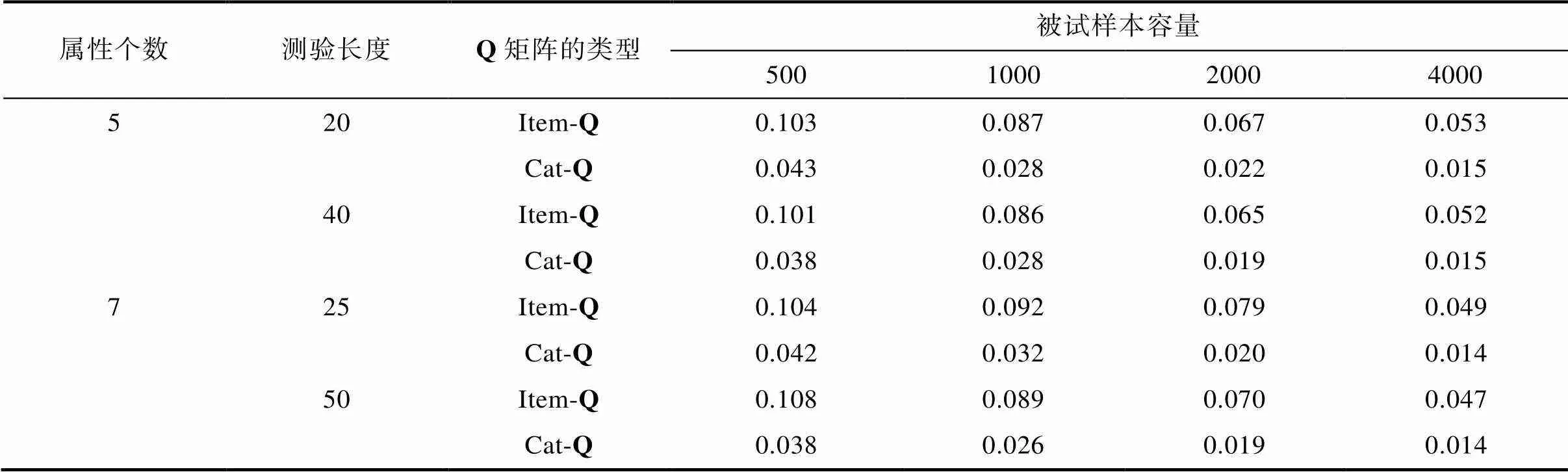
表5 各种实验条件下的项目参数返真性RMSE值
5 实验2: 实证数据研究
5.1 研究目的
为了进一步探讨和比较GPCDM在实证数据中的效果, 比较了三个基于分部评分模型思路的多级评分认知诊断模型, 即本文新开发的GPCDM以及国际上GDM和PC-DINA模型, 在国际数学与科学趋势研究(Trends in International Mathematics and Science Study, TIMSS) 2007四年级数学评估测验数据中的表现。TIMSS是由国际教育成就评价协会(International Association for the Evaluation of Educational Achievement)发起的一个国际大型教育评估项目, 该项目评估的对象是全球4年级和8年级的数学与科学学业成就。TIMSS从1995年开始第一次测试, 每4年举行一次。在2015年的TIMSS评估测验中, 来自世界各地的60多个国家参加了这次测试。
本文分析了TIMSS (2007)数据的一个子集, 其中包括823名学生对11个题目涉及8个属性的数据。11个题目中, 有3个多级评分题, 8个二级评分题目, 它的Q矩阵见表7。
5.2 评价标准
评价标准包括以下3个方面:
(1) 模型和测验数据整体拟合度: 通过模型拟合指标: −2倍对数似然(−2 log-likelihood values, −2LL), Akaike的信息准则(Akaike’s information criterion, AIC; Akaike, 1974), 和贝叶斯信息准则(Bayesian Information Criterion, BIC; Schwarz, 1978)等来比较3个模型的拟合度。
(2) 两类特殊被试的诊断属性边际概率(Marginal Probability): 两类特殊的被试是指测验得0分的被试和得满分(即14分)的被试, 一般来说, 得0分的被试意味着对所考察的属性基本没掌握, 而得满分的考生应该完全掌握了所考察的属性, 因此, 理论上, 得0分的被试估计得到的属性边际概率应该很低(接近于0), 而得满分的被试估计得到属性边际概率应该很高(接近于1)。属性边际概率的计算公式如下:
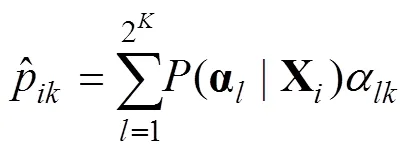
(3) 认知诊断信度分析: Templin和Bradshaw (2013)提出了一种计算CDM下属性信度(attribute reliability)的方法, 该方法可以分为以下几步: (1)首先, 使用选定的CDM估计每个被试的属性边际概率; (2)根据第一步估计得到的属性边际概率, 构建四格列联表, 其中的列联表的四个元素可以通过下列公式计算:

表7 实证数据的Q矩阵

5.3 研究结果
5.3.1 模型拟合结果
表8显示了3个模型的相对拟合指标, 结果显示, GDM和PC-DINA这2个模型相比而言, 在3个拟合指标中, GDM模型的拟合更优。而这3个模型相比而言, GPCDM在3个拟合指标的值都是最小的, 即与GDM和PC-DINA模型相比, GPCDM是相对拟合更好的模型。

表8 模型相对拟合指标
5.3.2 两类特殊被试的属性边际概率
表9显示了3个模型估计的两类特殊被试的属性边际概率, 对于得0分被试而言, 3个模型的平均属性边际概率从低到高顺序依次是: GPCDM、GDM和PC-DINA模型。对比3个模型的估计结果可以发现, PC-DINA模型估计的属性边际概率在8个属性上都要明显高于GDM和GPCDM, 其中属性A1的边际概率达到了0.548, 平均属性边际概率达到了0.375, PC-DINA模型会高估这些得0分被试的属性边际概率。GDM模型和GPCDM估计的属性边际概率都比较低, 两者的平均属性边际概率分别是0.093和0.001, 但就具体属性而言, GDM模型在属性A7的边际概率达到了0.278, 与GPCDM的结果相比, GDM模型高估了属性A7的边际概率。
对于得满分(14分)的被试而言, 3个模型的平均属性边际概率从高到低顺序依次是: GPCDM、GDM和PC-DINA模型。PC-DINA模型只有在属性A2、A3和A7的属性边际概率达到了0.9以上, 而在其余属性的边际概率都在0.7以下, 平均属性边际概率只有0.749; GDM模型和GPCDM的平均属性边际概率分别是0.881和0.975, 但与GPCDM相比, GDM模型在属性A1、A6和A8的边际概率分别是0.786、0.671和0.671, 都明显低于GPCDM的0.984、0.998和0.998。
总体来看, 对于得0分和满分的被试, 拟合最优的GPCDM模型估计的结果是最合理的, 其次是GDM模型, 最后是PC-DINA模型。
5.3.3 属性信度分析
表10显示了3个模型拟合该实证数据时的属性信度, 表10的最后一列表示8个属性的平均信度。对于GDM模型而言, 属性A8的信度指标只有0.710, 是相对最低的, 而其余7个属性的信度指标都在0.8以上, 属性信度指标的最高的是A6属性, 达到了0.997。对于PC-DINA模型而言, 属性A5的信度指标是相对最低, 只有0.507, 而属性A3的信度指标最高, 但也只有0.827。而GPCDM的8个属性最低信度指标是0.841。
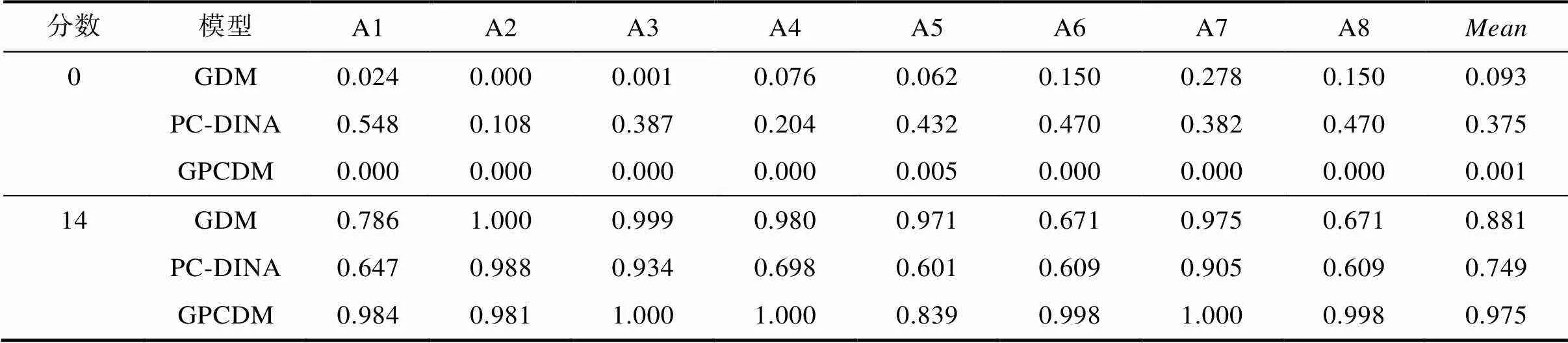
表9 两类特殊被试的属性边际概率

表10 每个模型下的属性信度
总体而言, PC-DINA模型的8个属性的信度指标都要明显低于GDM和GPCDM。而GDM和GPCDM相比而言, GPCDM在属性A1、A2、A4、A7和A8的信度指标也要高于GDM模型, 即GPCDM在5个属性的信度要优于GDM模型, GPCDM在剩余属性A3、A6和A7的信度指标和GDM非常接近。从平均属性信度指标来看, GPCDM的平均属性信度是最高的, 其次是GDM模型, 最后是PC-DINA, 即GPCDM分析该实证数据的效果更优。
6 研究结论与讨论展望
6.1 研究结论
本研究开发了一种更为灵活、功能更为强大, 且更有理论意义和应用价值的广义多级评分模型, 通过模拟研究验证了GPCDM的参数估计精度, 最后通过一个实证数据比较了GPCDM和已有基于分部评分思路的多级评分CDMs (GDM和PC-DINA)的应用效果, 研究结论主要有:
(1) Monte Carlo实验研究发现, 本研究开发的GPCDM的属性模式诊断正确率PMR在5属性时都在0.9以上, 项目参数的RMSE平均不到0.05, 这表明GPCDM模型具有较高的参数估计精度。
(2) 当使用Item-Q拟合Cat-Q生成的数据时, 题目和被试参数的估计精度都会降低。因此, 建议研究者在构建多级评分认知诊断的测验Q矩阵时, 应尽量构建基于得分类别的测验Q矩阵(即Cat-Q), 它能提供更多的诊断信息。
(3) 最后比较了GPCDM、GDM和PC-DINA模型在TIMSS (2007)数据的实际应用效果, 结果发现GPCDM的模型拟合度更优, 并且GPCDM分析该数据时的效果也更好。这表明新模型在实践应用中具有一定的优势。
6.2 讨论和展望
为使研究的结果不失一般性以及进一步拓展多级评分CDMs的相关研究, 未来至少还可以在以下几方面展开研究:
(1) 本研究假设属性之间是相互独立的, Q矩阵的标定完全正确, 另外, 本研究仅采用了EAP方法来估计被试参数, 并未对其他方法进行对比研究, 这些因素都可能会影响本研究的结论。
(2) 同一份测验中, 不同的题目可能拟合不同的CDM, 在二级评分的数据中, de la Torre (2011)应用Wald统计检验的方法为每个题目选择不同的CDM。而在多级评分数据中, 如何为每一题选择最适合的多级评分CDM也有待进一步研究。
(3) 多级评分的Q矩阵可以定义在得分类别水平, 这有助于提供更多诊断信息, 但是这也会增加Q矩阵标定的工作量。目前, 已经有学者开发了一系列辅助Q矩阵标定的算法, 但这些方法只局限于二级评分的模型。未来的研究可以继续探讨多级评分CDM中Q矩阵的标定算法。
(4) 本研究开发的模型假设考生的解题策略只有一种, 但在实际应用中, 同一道题目经常存在不同的解题策略。如果在诊断测验中考虑了被试解题策略的差异, 这也有助于提供更多有价值的信息, 从而提高诊断的精度(涂冬波, 蔡艳, 戴海琦, 丁树良, 2012)。因此, 开发多策略的多级评分CDM值得进一步研究。
(5) 已有的CD-CAT相关研究, 几乎都是基于二级评分的模型而展开, 事实上, 多级评分CD-CAT (Polytomous CD-CAT, PCD-CAT)在实际应用中具有更广阔的前景, 不仅是因为心理或教育评估测验中存在大量的多级评分数据, 更重要的是与二级评分的题目相比, 多级评分题目可以提供更多的信息, 即多级评分的CD-CAT有助于进一步提高测验的效率, 未来的研究可以针对PCD-CAT的相关算法展开研究。
Akaike, H. (1974). A new look at the statistical model identification., 19, 716–723.
Cai, Y., Miao, Y., & Tu, D. B. (2016). The polytomously scored cognitive diagnosis computerized adaptive testing.(10), 1338–1346.
[蔡艳, 苗莹, 涂冬波. (2016). 多级评分的认知诊断计算机化适应测验.,(10), 1338–1346.]
de la Torre, J. (2011). The generalized DINA model framework.(2), 179–199.
de la Torre, J. (2012). Application of the DINA model framework to enhance assessment and learning.(pp. 87–103). Springer, Dordrecht.
de la Torre, J., & Minchen, N. (2014). Cognitively diagnostic assessments and the cognitive diagnosis model framework.,(2), 89–97.
Hansen, M. (2013).. Unpublished doctoral dissertation. University of California at Los Angeles.
Leighton, J. P., & Gierl, M. J. (2007). Defining and evaluating models of cognition used in educational measurement to make inferences about examinees’ thinking processes.(2), 3–16.
Ma, W., & de la Torre, J. (2016). A sequential cognitive diagnosis model for polytomous responses.,(3), 253–275.
Mellenbergh, G. J. (1995). Conceptual notes on models for discrete polytomous item responses.(1)91–100.
Samejima, F. (1969). Estimation of latent ability using a response pattern of graded scores.(S1), 1–97.
Schwarz, G. (1978). Estimating the dimension of a model.,(2), 461–464.
Templin, J. L. & Bradshaw, L. (2013). Measuring the reliability of diagnostic classification model examinee estimates.(2), 251–275.
Templin, J. L., & Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models.(3), 287–305.
Tu, D. B., Cai, Y., Dai, H. Q., & Ding, S. L. (2010). A polytomous cognitive diagnosis model: P-DINA model.(10), 1011–1020.
[涂冬波, 蔡艳, 戴海琦, 丁树良. (2010). 一种多级评分的认知诊断模型: P-DINA 模型的开发.,(10), 1011–1020.]
Tu, D. B., Cai, Y., Dai, H. Q., & Ding, S. L. (2012). A new multiple-strategies cognitive diagnosis model: The MSCD method.(11), 1547–1553.
[涂冬波, 蔡艳, 戴海琦, 丁树良. (2012). 一种多策略认知诊断方法: MSCD方法的开发.,(11), 1547–1553.]
Tu, D., Zheng, C., Cai, Y., Gao, X., & Wang, D. (2017). A polytomous model of cognitive diagnostic assessment for graded data.,(3), 231−252.
Tutz, G. (1997). Sequential models for ordered responses.(pp. 139−152). Springer, New York, NY.
van Der Ark, L. A. (2001). Relationships and properties of polytomous item response theory models.(3), 273–282.
von Davier, M. (2008). A general diagnostic model applied to language testing data.(2), 287–307.
Development of a Generalized Cognitive Diagnosis Model for polytomous responses based on Partial Credit Model
GAO Xuliang1,2; WANG Daxun1; WANG Fang2; CAI Yan1; TU Dongbo1
(1School of Psychology Jiangxi normal university, Nanchang 330022, China) (2School of Psychology Guizhou normal university, Guiyang 550000, China)
Currently, a large number of cognitive diagnosis models (CDMs) have been proposed to satisfy the demands of the cognitively diagnostic assessment. However, most existing CDMs are only suitable for dichotomously scored items. In practice, there are lager polytomously-score items/data in educational and psychological tests. Therefore, it is very necessary to develop CDMs for polytomous data.
Under the item response theory (IRT) framework, the polytomous models can be divided into three categories: (i) the cumulative probability (or graded-response) models, (ii) continuation ratios (or sequential) models, and (iii) the adjacent-category (or partial-credit) models.
At present, several efforts have been made to develop polytomous partial-credit CDMs, including the general diagnostic model (GDM; von Davier, 2008) and the partial credit DINA (PC-DINA; de la Torre, 2012) model. However, the existing polytomous partial-credit CDMs need to be improved in the following aspects: (1) These CDMs do not consider the relationship between attributes and response categories by assuming that all response categories of an item measure the same attributes. This may result in loss of diagnostic information, because different response categories could measure different attributes; (2) More importantly, the PC-DINA is based on reduced DINA model. Therefore, the current polytomous CDMs are established under strong assumptions and do not have the advantages of general cognitive diagnosis model.
The current article proposes a general partial credit diagnostic model (GPCDM) for polytomous responses with less restrictive assumptions. Item parameters of the proposed models can be estimated using the marginal maximum likelihood estimation approach via Expectation Maximization (MMLE/EM) algorithm.
Study 1 aims to examine (1) whether the EM algorithm can accurately estimate the parameters of the proposed models, and (2) whether using item level Q-matrix (referred to as the Item-Q) to analyze data generated by category level Q-matrix (referred to as the Cat-Q) will reduce the accuracy of parameter estimation. Results showed that when using Cat-Q fitting data, the maximum RMSE was less than 0.05. When the number of attributes was equal to 5 or 7, the minimum pattern match rate (PMR) was 0.9 and 0.8, respectively. These results indicated that item and person parameters could be recovered accurately based on the proposed estimation algorithm. In addition, the results also showed that when Item-Q is used to fit the data generated by Cat-Q, the estimation accuracy of both the item and person parameters could be reduced. Therefore, it is suggested that when constructing the polytomously-scored items for cognitively diagnostic assessment, the item writer should try to identify the association between attributes and categories. In the process, more diagnostic information may be extracted, which in turn helps improve the diagnostic accuracy.
The purpose of Study 2 is to apply the proposed model to the TIMSS (2007) fourth-grade mathematics assessment test to demonstrate its application and feasibility and compare with the exiting GDM and PC-DINA model. The results showed that compared with GDM and PC-DINA models, the new model had a better model fit of test-level, higher attribute reliability and better diagnostic effect.
cognitive diagnosis; polytomous CDMs; GDM model; PC-DINA model
2019–02–12
* 国家自然科学基金(31660278, 31760288, 31960186 )资助。
汪大勋为共同第一作者。
B841
涂冬波, E-mail: tudongbo@aliyun.com。
10.3724/SP.J.1041.2019.01386
猜你喜欢
ELLE世界时装之苑(2023年2期)2023-02-17 00:50:21
甘肃科技(2020年20期)2020-04-13 00:30:56
中国自行车(2018年10期)2018-11-30 02:09:30
趣味(语文)(2018年7期)2018-06-26 08:13:48
消费导刊(2018年8期)2018-05-25 13:20:20
中国科技博览(2018年3期)2018-01-12 11:32:58
考试周刊(2016年88期)2016-11-24 13:30:50
河北地质大学学报(2015年5期)2015-02-27 13:09:58
少年科学(2014年10期)2014-11-14 07:38:17
科技经济市场(2014年5期)2014-09-09 08:25:48
