
CNN与LSTM结合的语句级情感极性分析模型研究
2019-12-05 08:40韩硕蒿红可
无线互联科技 2019年17期
韩硕 蒿红可

摘 要:CNN与LSTM在情感分析任务中已有广泛应用,但单独应用CNN与LSTM模型时,模型自身的局限性限制了任务最重的分类准确率。文章结合CNN与LSTM,设计了两种情感极性分析模型,并对两种模型进行了论证。最后分别在两种数据集上测试了模型,并将结果与常规模型进行了比较。测试结果表明,这两种模型相比常规模型均达到了更高的分类准确率。
关键词:情感分析;自然语言处理;深度学习
近些年,因分布式数据存储技术的发展,大量数据被存储下来,特别是各个论坛、博客、微博、Twitter和电商平台用户产生的在线评论等文本数据。自21世纪以来,情感分析成为自然语言处理(Natural Language Processing,NLP)中最活跃的研究领域之一。由于情感分析的研究对象多为人类语言,又因其对商业和管理、社会的重要性,其研究已经从计算机科学扩展到管理科学与社会科学,如政治学、市场营销学、金融、通信、健康科学甚至历史。这种扩散是自然发生且重要的,正确认识这些人类活动,对本文对事物的看法和未来的决策有着重要影响。
本文将使用深度学习模型在Twitter数据集(英文)与电商评论数据集(中文)上实现情感极性分类。任务目的是将数据集中的每一条文本准确分类为“积极情感”或“消极情感”。
本文将引入多个深度学习模型,并且在本文收集到的数据集基础上实现情感分类任务,观察其不同表现。本文还探究了两种比较流行的深度学习模型的组合在情感分类任务上的使用效果,设计了两种组合模型,与其基础模型和基于统计的方法作了比较。
1 CNN与LSTM简介
2006年Geoffrey Hinton[1-2]等提出了多隐层的人工神经网络,它相比浅层的神经网络具有优异的特征学习能力。多层次的网络模型成为之后许多模型的主要架构。随着深度学习技术的发展,之后又相继出现了堆栈自编码[3]、更深层的卷积神经网络(Convolution Neural Networks,CNN)、循环神经网络(Recurrent Neural Networks,RNN)等深度学习模型。CNN最初在图像领域内取得了卓越的成绩。Kim等[4]使用CNN对文本进行分类,也取得了很好的效果,证明CNN同样可以抽取文本的特征信息。Lee等[5]使用RNN与CNN训练文本的向量,通过前馈神经网络实现文本分类,取得了相对较好的准确率,证明了在文本任务中,文本序列特征同样重要。普通RNN虽然可以有效利用较短的上下文特征[6-7],但缺点较为明显,在训练时存在梯度消失的问题,所以不能处理句子中的长依赖特性。为解决这一问题,RNN出现多个变种循环神经网络模型,如长短时记忆网络(Long-Short Term Memory,LSTM),可在文本上提取比普通RNN更长距离的语义特征。本文的研究着重基于CNN与LSTM两种基础模型。
1.1 卷积神经网络
卷积神经网络最初因解决图像问题而出现,近几年,在自然语言处理领域中也有广泛应用。CNN可以从原始数据中抽取局部信息。例如,CNN可以在不受图片布局的影响下,以很高的准确率判断一张图片里是否有一只猫[8]。
基础的CNN模型由卷积层、池化层、全连接层构成。原始数据被输送到卷积层,这些数据可以是多重维度的,如彩色图像的红、绿、蓝3个通道。卷积层中的多个卷积核可以横向、纵向滑动,从而实现对数据进行局部采样,采样后的信息在池化层中池化。池化后的数据维度一般会大幅缩小,这些信息最终被送到全连接层,全连接层负责最后的数据处理。
在对文本进行卷积操作前,原始文本被词向量层表示为本文矩阵K,维度为l×d。其中,l为文本的最大长度,d为词向量的维度。CNN通过卷积核Wn×h×d对Kl×d编码,此处n是卷积核的个数,h是卷积核的高度,在文本处理任务中,卷积核寬度d通常等于词向量维度。在卷积层中,卷积核Wi在K中滑动取样,i=1,2,…n。在文本的处理中,由于字、词转化成的词向量维度一般是固定的,所以卷积核通常不会在词向量维度上滑动采样,而只是在词的维度上滑动。卷积层的输出为O={o1,o2,…,on},o的维度与每个卷积核的尺寸、步长有关。在池化层中,建立像卷积核一样可以滑动的矩阵窗口,此窗口在oi上滑动,此处i属于1,2,…,n,对在窗口内oi的部分使用最大池化方法,保留窗口的最大值,池化层输出为P=[p1,p2,…,pn]。将P中的向量平铺,再使用全连接层及softmax运算得到最后的分类。
1.2 长短时记忆模型
长短时记忆模型是一种循环神经网络模型,该模型拥有记忆前序状态的能力,所以特别适合处理序列问题。由于训练算法通常是基于梯度的,在序列较长的数据上,原始的循环神经网络模型在训练时往往会产生梯度消失。为了解决这个问题,LSTM在神经元之间添加了“记忆细胞”,“记忆细胞”直接贯穿于整个神经元之间,只参与少量的线性运算,每个神经元通常通过“输入门”“输出门”“遗忘门”获取或控制“记忆细胞”中的内容。
首先,句子中的词被表示成维度为d的词向量,文本被编码成l×d的文本矩阵。这些向量被逐步输送至神经网络中。第步数为t时,遗忘门根据当前步的输入计算出记忆细胞中哪些信息可以被遗忘,σ为sigmoid函数,最终输出一个0~1之间的数值,公式如下:
输入门由两部分组成:第一部分,计算当前输入的哪部分需要更新,第二部分,创建一个初始的待更新向量。
经上述操作后,更新细胞状态为:
输出层会基于细胞状态计算输出。首先,输出层计算细胞中被输出的部分:
其次,将细胞状态通过tanh函数运算得到﹣1~1之间的值,并与上部分的结果相乘,得到最终输出的部分:
因这些门可以控制信息的流入与流出,记忆细胞可以储存比一般的RNN更长的序列信息,LSTM在处理文本任务中有着独特的优势,它可以综合上下文重新对文本进行编码。在情感分析任务中,它可以准确处理情感比较复杂的语句。
1.3 数据集
1.3.1 推特数据集(英文)
推特数据集是Neik Sanders创建的“Twitter情感语料库”,共有229 484条已标记数据,使用朴素贝叶斯方法得到的最高正确率为65%。
1.3.2 商品评论数据集(中文)
商品评论数据包含约25 000条电商买家评价,所有数据已标记,其中,积极情感、消极情感文本分别占所有数据集的50%。
2 模型设计
由于CNN具有抽取局部信息的能力,可以无视位置而对情感词和词组进行抽取,LSTM可以依据顺序处理情感特征。基于以上考虑,本文结合了CNN与LSTM模型进行探究。
2.1 CNN+LSTM
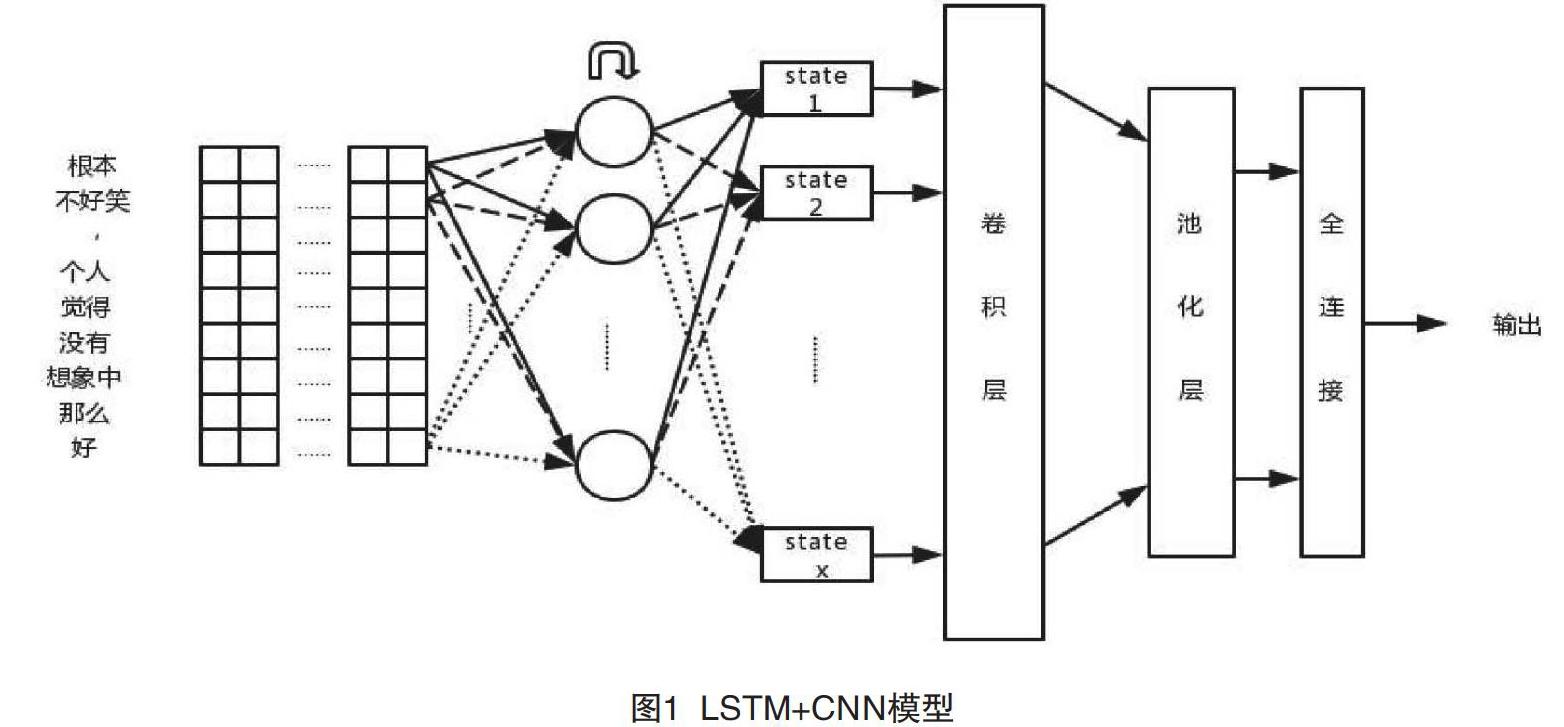
因为决定文本情感类别的情感词只在文本局部出现,所以实际中有一部分文本对情感分类任务是无用的,首先,CNN可以从原始文本中提取局部的情感信息;其次,利用LSTM序列分析能力对整体文本作出情感判断。最后,用CNN抽取局部信息可以缩短LSTM的输入序列长度,避开LSTM无法处理长依赖的缺陷。本文基于情感分类语料库长度的考虑与两种基本模型的特点,设计了CNN-LSTM模型(见图1)。
此模型包含CNN与LSTM两部分。文本为CNN设计了多个尺寸的卷积核,在尺寸相同的卷积核上使用不同步长的采样策略,可以让CNN以不同的尺度感知文本中的情感因素。矩阵K被输送到CNN中,经过卷积操作后得到O={o1,o2,…,on},其中,n等于卷积核的个数,即有n×d个参数。视卷积步长而定,使用不同尺寸的卷积核可能会导致O中的向量维度不统一。文本根据o1,o2,…,on的维度,使用不同尺寸的池化窗口,使池化后的向量维度相等,得到P=[p1,p2,…,pn]。在Kim等的研究中,CNN模型在池化层在对卷积结果进行池化时,将每个卷积核的结果进行整体池化,Kim等称之为Max-over-time。为了保存文本的序列信息,本文在池化操作时没有采用Max-over-time方案,而采用了小窗口的池化采样,这种池化方式可以使每个卷积核保留若干值组成的序列,以供LSTM提取序列特征。由于P中的每个向量还保存着原始文本的序列信息,故在重排列层将P做一次转置操作得到PT,紧接着PT被送到LSTM的输入层,LSTM会试图学习情感特征之间的序列关系。取LSTM的最后一步状态F1×λ,其中λ为神经元个数。在softmax层中,先让F与Wλ×cF做点击运算到L1×c,其中,c是情感类别个数,WF是待评估参数,在本文的实验中取c=2。再对F做softmax计算,得S=[s1,s2,…,sc],其中,,i,j∈L;η=1,2,…,c。S中各个元素的数值即为原文本属于各个情感类别的概率。
2.2 LSTM+CNN
LSTM可以依据其强大的序列处理能力对词向量进行重新编码,编码后的詞向量拥有更为丰富的上下文表达。CNN可以进一步提取这些信息的局部信息,从而给出更准确的情感分类结果。
首先,文本矩阵K被输送到LSTM中,得到LSTM每一步的输出Hλ×1=[h1, h2, …, hl],其中,λ为LSTM神经元的个数;其次,将H作为CNN的输入。在卷积层的设计中,文本使用的卷积核宽度与LSTM单元的个数相同,卷积核在LSTM输出的步维度上滑动取样得到O=[o1,o2,…,on],经过池化层得到P=[p1,p2,…,pn],再将P中的每个向量平铺得到F。在全连接层中,F与WF做点积运算再经过softmax运算,最终得到文本的情感分类概率。
2.3 损失函数
在上述两种模型的学习过程中,均采用交叉熵误差作为模型的损失函数。具体公式如下:
其中,N为训练的样本数,y为模型输出的每个类别的预测概率,t为第i个样本的真实类别,训练目的是让J最小化。
3 实验
3.1 实验准备
为了验证模型的分类效果,本文使用tensorflow对前两部分所述模型进行了构建,并在两种语言的公共语料上进行实验,列举了实验过程及结果,最后对这两种实验结果进行了分析。
英文的推特数据集样本容量较大,本文仅使用了1%的数据作为测试集,其余数据均参与训练。每个模型均测试3次,测试结果取其平均值。本文对中文电商数据进行了分词预处理,使用了2 000条积极情感文本、2 000条消极情感文本作为测试集,其余数据均参与训练。每个模型均测试3次,测试结果取平均值。
本文使用的词向量维度为512,LSTM单元64个,卷积核32个。实验所使用的设备配置如下:系统16.04-Ubuntu,CPU为Intel酷睿i7-7700,主频2.8 GHz,16 G内存,GPU为NVIDIAGeForce-1060,6 G显存。
3.2 实验结果分析
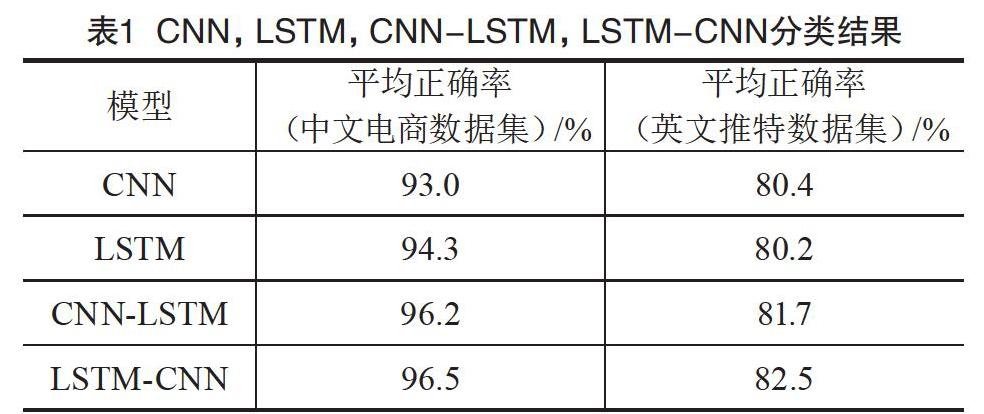
在不同语言的数据集上进行实验后,本文发现LSTM-CNN与CNN-LSTM模型均优于CNN及LSTM模型1.5%~3.5%,LSTM-CNN模型以0.3%~0.8%优于CNN-LSTM模型。在不同数据集方面,CNN,LSTM,LSTM+CNN,CNN+LSTM模型的表现差异较大,这4种模型在中文数据集上表现更好,当然,这可能和推特文本中存在大量简写及错误拼写现象有关。
实验结果印证了本文的论证。CNN+LSTM模型可以使LSTM更高效地利用原始文本的序列信息,本文进一步猜测,这种优势在处理长度更长的句子时更加显著。但是在句子长度普遍小于70的情感分类语料中,LSTM+CNN模型的效果是这几种组合中最好的。该模型中的LSTM单元充当解码器,将原始句子中的每个词都解码为一个中间信息,这个中间信息除了这个单词本身的含义,还包含它之前单词的信息。之后,CNN可以利用其强大的信息识别能力处理更为丰富的中间信息,从而获得更好的分类效果。CNN,LSTM,CNN-LSTM,LSTM-CNN的分类结果如表1所示。
4 結语
在本文的研究中,结合了CNN与LSTM模型,并在两种不同语言的数据集中测试,最终获得了更高的情感分类准确率。实验结果发现,LSTM-CNN与CNN-LSTM模型以1.5%~3.5%的准确率优于CNN及LSTM。实验结果验证了本文的设想,在语句级的情感分析任务中,联合CNN与LSTM可以发挥两个模型的优势,达到更佳的准确率。
此次实验中,CNN+LSTM的表现虽然优于CNN与LSTM模型,但在这两种语料中的效果都不是最好的,本文进一步地猜测此模型更适用于较长的句子。另外,LSTM+CNN模型虽然表现最佳,但是该模型组合并没有克服LSTM不能处理长序列的缺陷,其在更长的句子中的效果可能欠佳。在未来,笔者将进一步测试此模型在长句的情感分析任务中的表现,进一步对模型进行研究以克服长序列难题。
[参考文献]
[1]HINTON G E,SALAKHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science,2006(5786):504-507.
[2]HINTON G E,OSINDERO S,TEH Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006(7):1527-1554.
[3]LAROCHELLE H,BENGIO Y,LOURADOUR J,et al.Exploring strategies for training deep neural networks[J].Journal of Machine Learning Research,2009(10):1-40.
[4]KIM Y.Convolutional neural networks for sentence classification[J].Eprint Arxiv,2014(14):1181.
[5]LEE J Y,DERNONCOURT F.Sequential short-text classification with recurrent and convolutional neural networks[J].arXiv Preprint:2016(4):515-520.
[6]CHO K,VAN M B,GULCEHRE C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[J].arXiv Preprin,2014(14):1078.
[7]EBRAHIMI J,DOU D.Chain based RNN for relation classification[C].Colorado:Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2015.
[8]SANDERS N.Twitter sentiment corpus[EB/OL].(2019-03-15)[2019-09-10].http://www.sananalytics.com/lab/twitter-sentiment/.
猜你喜欢
计算机应用(2016年12期)2017-01-13
预测(2016年5期)2016-12-26
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
