
空间形态与绿化因素对夏季胡同居民社会聚集的影响
2019-11-30 12:00盛强胡彦学宋阳
风景园林 2019年6期
盛强 胡彦学 宋阳
1 研究背景
随着中国城市建设转入存量规划和品质提升的时代,居民在街道中的社会交往聚集活动成为评价城市公共空间活力的重要指标。大量的城市改造与更新项目中对地面铺装、环境绿化、街道家具、活动设施等各方面的投入是否能够真正提升街道空间品质,促进居民更频繁地使用公共空间,对城市规划和设计师有直接的意义。
从现有文献的研究内容来看,国内外对社会聚集现象大都关注空间环境要素的影响。如Mehta的研究发现步行街街道越宽,座椅越多,对停留性活动和社交活动的促进作用越明显[1]。类似的,同济大学陈泳教授的团队对商业街中逗留性行为的分析表明人行道宽度、界面的透明及开敞度与人群的逗留性行为呈正相关[2]。Zacharias等发现广场上的光照环境及温度对行为有重要影响[3]。
从现有文献的研究方法来看,对社会聚集数据的收集多采用问卷法或多次实地调研注记法[4]。随着街景地图等网络开放数据的发展,近期部分研究也开始探索应用该类数据取代传统调研方式的可行性。如叶宇等基于百度街景,应用机器学习工具探索了大批量获取绿视率的方法[5]。刘星等对比了百度街景与实地调研获取的商铺分布、步行者数量和社会聚集数据,发现前两者可以在一定程度上替代实地调研,但社会聚集与实地调研相比仍不理想[6]。此外,同济大学徐磊青教授团队使用VR设备对公共空间中的社会聚集现象展开研究,发现了广场面积以及高宽比、天空视角等与停留活动的关系[7]。徐磊青教授团队的其他一些基于街景图片的研究表明绿视率和车道数对安全感有明显的影响[8-9]。
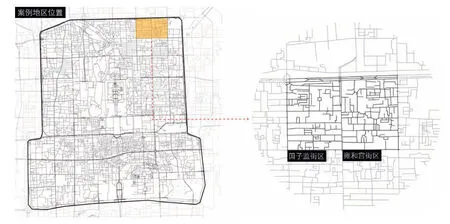
1 案例地区位置与街区形态Locations of case neighborhoods and their street patterns
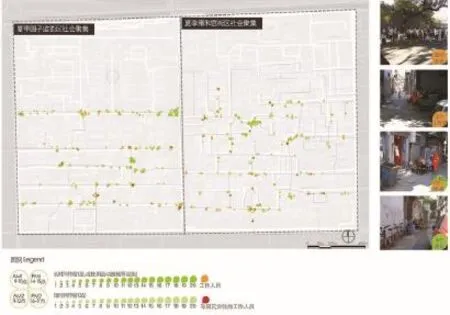
2 两个街区聚集强度与人群特征Social gatherings in the two neighborhoods
上述文献中的实证研究往往聚焦造成社会聚集现象周边小范围的空间形态、设施和环境要素,体现为对静态的、非关联性的空间条件的关注。然而,考虑到社会聚集行为(特别是街道上偶发的社会交往活动)往往是在居民出行过程中产生的,因此有必要探讨其产生的关联性空间条件。在这个方向上,空间句法理论和分析方法提供了一条新的研究路径。
在空间句法研究领域,早期的一些研究采用行为注记法记录街道空间中步行者的行为,分析性别、年龄差异体现出的空间分布规律[10]。在建筑内部尺度,也有研究通过记录公司中的非正式会议发生的地点,分析其体现出的空间分布逻辑[11]。从研究结果来看,这些研究大都验证了空间句法参数对上述活动分析的有效性。但较少有采用多片区样本,综合各非关联性空间环境要素与关联性空间要素,并针对社区内居民社会聚集行为的研究。近期,刘星针对北京中心城区4个案例区的实地调研,应用空间句法,较为系统地对比了不同居住建筑类型街区内,各空间句法参数对居民社会聚集的影响,其研究成果发现多层住宅区相对于胡同区的聚集行为,其空间规律更为明显,与空间句法参数的关联性也较为显著。但并未引入景观绿化等环境因素[12]。
在此基础上,将聚焦夏季北京胡同区的低层居住类型,选取位置临近但空间形态差异性较强的案例区域展开实证研究,综合考虑空间句法参数、绿化参数、服务设施和居住密度展开多元回归分析,试图发现影响夏季胡同居民聚集的稳定规律。
2 研究方法
2.1 研究区域概况
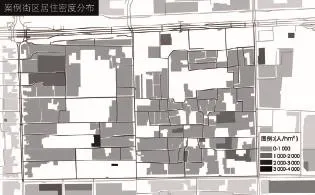
本文的研究范围为雍和宫和国子监所在的两个街区(图1),调研范围约142.5 hm2,其中雍和宫街区约71.4 hm2,国子监街区约71.1 hm2。两个街区均为北京老城内胡同地块,居住类型多为低层的四合院。
2.2 调研方法与数据筛选
本研究采取现场行为注记法来收集户外聚集数据,选取2018年夏季一天中的4个时间段(08:00—09:00,10:00—11:00,14:00—15:00,16:00—17:00)对两个街区地块进行循环调研。需要说明的是,在数据筛选时排除了清洁工、商贩以及等待办事的人群和排队的游客等必要性的聚集,从而过滤出“净”居民的社会聚集,同时又考虑到清洁工、商贩等街头工作者长时间在本地工作,与居民较为熟悉,往往成为社会交往的催化剂,也可以被看作居民的一分子。因此在进行数据处理的时候,将户外人群分为三类:街道工作者聚集、居民与街道工作者交往的聚集和净居民社会聚集(图2)。共记录了两个案例街区中总计177个聚集点539人次的社会聚集的空间分布数据。
2.3 数据的处理方法与空间形态变量选取
空间句法作为一种基于空间拓扑连接关系研究使用者行为的建筑和城市学理论,认为人在空间中的活动很大程度上受空间结构的影响,把空间抽象成彼此相交的直线段来计算空间之间的拓扑连接,因此可以定量描述空间与人的活动之间的关系。
笔者采用的空间句法线段地图建模范围包括北京六环路以内范围的所有街道。从参数选择上,整合度表示了某条线段的中心性,是以综合折转角为定义的与周边不同尺度线段的最短拓扑距离。选择度表示的是被周边一定尺度内任意两条线段之间最短路径穿过的次数,其中“最短路径”同样是以综合折转角度最小来定义的。以这两个指标为基础,Hillier、杨滔和Turner在2013年又提出了标准化角度选择度(Normalised Angular Choice,简称NACH)和标准化角度整合度(Normalised Angular Integration,简称NAIN)的指标,进一步削弱了线段数量对空间计算结果的干扰[13]。选用了0.2~10 km共14个计算半径下的整合度(Integration,简称INT)、选择度对数(Log Choice)、NACH和NAIN这4种空间句法参数进行数据分析。
在应用空间句法参数分析功能分布、社会聚集等静态类数据时(相对于各类交通流量等动态数据),往往需要采用适当的方法对数据进行均匀化处理,排除空间中偶然性因素的影响。笔者团队近年来广泛采用的方法为以某个街道段为起点,综合距离与角度衰减将周边的数据进行加总处理,方法及公式可参见笔者近期的相关论文[14]。在本研究中该方法用于在回归分析中(一元和多元)处理社会聚集、商铺分布、绿化率等静态数据。
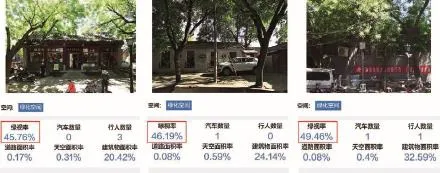
3 绿视率数据获取方式(应用“猫眼象限”APP)Acquisition of green view ratio (Applying Cat Eye Quadrant APP)
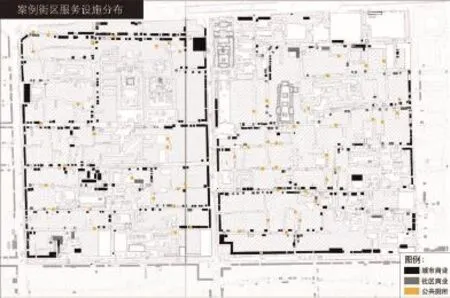
4 两个街区的商业服务设施空间分布Spatial distribution of commercial service facilities in the two neighborhoods
除空间句法参数之外,笔者引入了聚集位置距城市主干路的拓扑衰减和距离衰减参数、聚集位置的道路宽度、街道段的入口数量等空间形态参数:其中道路宽度为笔者实测宽度,数据处理则是按照与社会聚集相同的处理方式进行标尺均匀化;街道段的入口数量为笔者实地调研获取,其处理方式则是将其录入空间句法Depthmap软件后分别计算了以各街道段为中心100、200、300 m这3个可达范围内的入口加总值。
2.4 其他自变量选取与处理方法
其他自变量的选取则综合考虑了绿化因素、服务设施和居住密度三类参数并将之与处理后的社会聚集数据逐一进行一元回归。绿化因素又分为水平视角绿视率与俯瞰视角的绿化覆盖率,其中绿视率的原始数据是在街景地图中水平截取聚集点位置的街景图片将其导入“猫眼象限”(APP)来获取,再将同一条街道上的聚集点按每个聚集点的聚集人数取加权平均值作为该条街道的绿视率,然后采用与社会聚集同样的标尺均匀化处理方法对原始数据进行处理(图3);绿化覆盖率则是以卫星地图为背景,以每个聚集点为中心计算其沿道路前后50 m范围内的树冠面积占比,同样按照聚集点的聚集人数取加权平均值作为该条街道的绿化覆盖率,并采用与社会聚集同样的标尺均匀化处理方法对原始数据进行处理。
服务设施参数分为功能业态类及公厕,两者均采用街景地图与现场校核的方式获取其数量及分布,其中功能业态类又根据研究范围的业态类型分为社区商业与城市商业(图4)。其中社区商业的分类包括菜市场、粮油店、棋牌室、五金店、便民店等服务于本地居民的业态类型,城市商业则是除去以上社区商业之外的商业业态类型。城市商业和社区商业的处理方式分为两种:一种与前述社会聚集数据处理中采用的标尺均匀化方式相同,综合距离衰减与角度衰减计算了每个街道段周边复合可达范围内商铺数量加总值;另一种则是以简单的距离可达半径为基础,计算了以各街道段为中心200、400 m半径内的商铺数量加总值;公厕数据的处理则是计算了每条街道段距其最近的公厕位置的真实距离。
居住密度参数(图5)的处理则是将各小区(含各胡同片区)居住人口的数据按临近落位的原则导入空间句法模型的街道段上。为了避免由各片区出入口位置造成的误差,本研究分别计算了以各街道段为中心200、300、500、800 m这4个可达范围内的人口加总值。
3 居民社会聚集空间分布的初步统计
3.1 两个街区居民社会聚集强度对比
将两个案例街区的聚集强度进行量化描述(表1),对比后可以发现:尽管在排除了旅游者聚集的影响后,国子监的聚集规模从聚集数量、单位长度的聚集人次数量和单位面积的聚集人次数量统计仍明显大于雍和宫,但考虑到国子监地区居民数量较多,从聚集人口占比(户外聚集人次除以各案例区居民总数)来看两者差异并不明显。
3.2 两个街区居民聚集空间分布的统计分析
对两个街区以街道段为精度按聚集规模进行各聚集点的统计分析,试图发现社会聚集受空间拓扑形态影响的差异。两个地块从3人以内到20人以上不同规模的聚集点的统计结果中,分整合度和选择度两类参数列出了相同聚集规模的不同聚集点位置超过北京二环以内各半径空间句法参数平均值的百分比,其超出或低于平均值的比例表明了该聚集规模对所对应空间参数值的依赖程度(图6、7)。
从结果来看,国子监街区和雍和宫街区的聚集特征有明显差异:国子监街区户外活动所依赖的各空间句法参数半径较大,其峰值出现在1 500 m半径左右,而雍和宫户外活动的空间句法参数半径较小,其峰值出现在500 m半径左右。此外,观察各案例街区不同等级聚集的分布差异。国子监街区的分析结果显示规模越大的聚集越依赖1 500 m半径的选择度或整合度,体现出一种清晰的“外向型”规律。相反,雍和宫街区中规模越大的和规模越小的聚集都更依赖胡同的通达性,体现出一种“复杂”且“内向型”的规律:雍和宫的街道肌理更为复杂,对外通达性差,仅有少数街道与大路直接联系,大部分道路以迷宫形态位于街区内部。而这种肌理导致该街区的居民既可能在内部连接较好的街道上相遇,也可能在大街出入口上相遇。但是,这些聚集的规模差异却不一定与各街道在小尺度范围的通达性成正比。
5 两个街区的人口密度Population density of the two neighborhoods
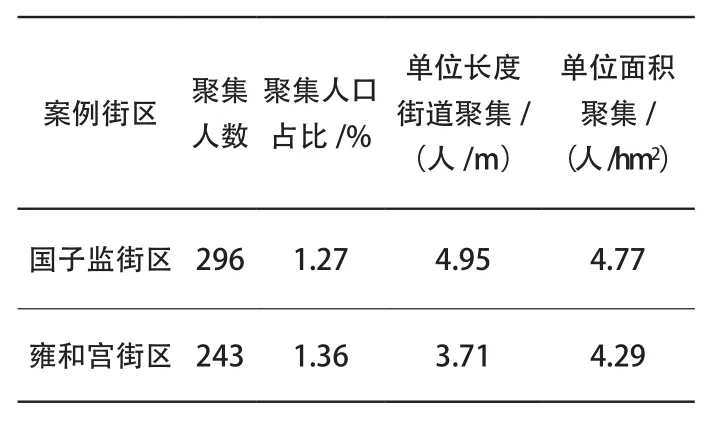
表1 两个街区的聚集强度对比Tab. 1 Comparison of gathering intensity between two neighborhoods
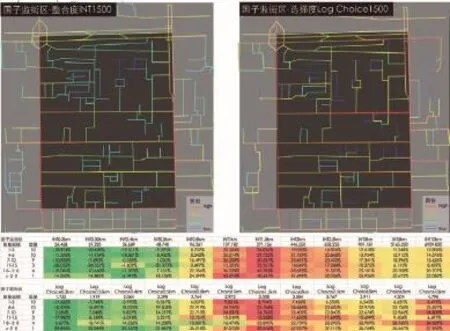
6 国子监街区聚集点的整合度与选择度分析Analysis on INT and Log Choice of gatherings in the Imperial College block
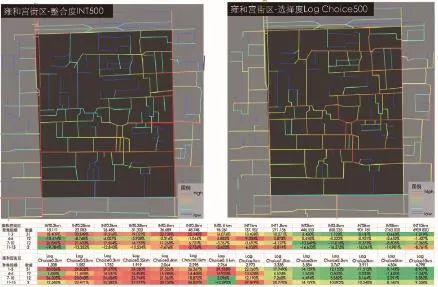
7 雍和宫街区聚集点的整合度与选择度分析Analysis on INT and Log Choice of gathering points in the Lama Temple block

8 两个街区聚集汇总和各街区聚集分别与各空间句法参数的一元回归分析Single variant regression analysis of the two neighborhoods in one model and in each case separately
4 居民社会聚集的多元回归分析
4.1 社会聚集与空间句法参数的一元回归分析
对社会聚集数据进行标尺均匀化处理后,采用不同半径的四类空间句法参数来分析两个街区聚集的空间分布规律。由0.2~10 km 14个计算半径下各空间句法参数对社会聚集的决定系数变化可知,大部分选择度系的参数的决定系数要高于整合度系参数的决定系数,这说明社会聚集受各街道段空间穿过性潜力的影响更强(图8)。
具体来看,国子监街区社会聚集与空间句法选择度参数的决定系数高达0.6,而雍和宫街区仅达到0.17。尽管二者分析效果不同,其峰值均集中在800~1 000 m半径,该数值区间大致对应居民10 min的步行可达范围,表明居民的社会聚集更多地依赖于小尺度半径范围街道的通达性。因此,在多元回归分析中笔者选取了800 m和1 000 m半径的选择度与穿行度共计4个参数作为空间句法参数的备选自变量。
4.2 国子监街区社会聚集多元回归分析
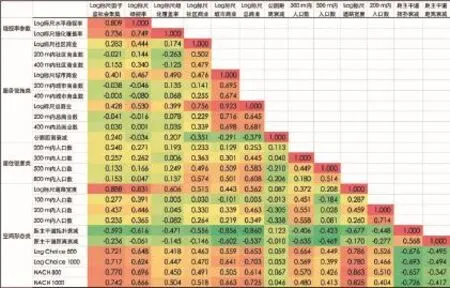
9 国子监街区社会聚集与各类参数的相关分析Correlation analysis of social gathering and various parameters in the Imperial College block
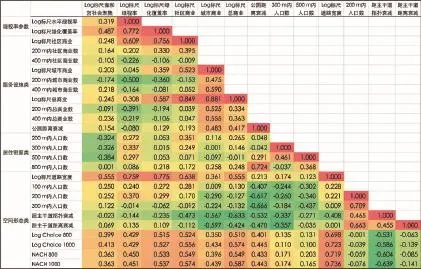
10 雍和宫街区社会聚集与各类参数的相关分析Correlation analysis of social gathering and various parameters in the Lama Temple block

表2 国子监街区社会聚集的变量多元回归分析Tab. 2 Multiple regression analysis of the parameters of the Imperial College block

表3 雍和宫街区社会聚集的变量多元回归分析Tab. 3 Multiple regression analysis of the parameters of the Lama Temple block
对标尺均匀化处理过的社会聚集数据与各空间句法参数、绿化参数(包括水平视角绿视率及俯瞰视角的绿化覆盖率)、服务设施(包括商业总数、城市级商业、社区级商业、公厕)、居住密度四大类共计26组数据进行了相关系数分析(图9)。从结果可看出,在四大类参数中,社会聚集与标尺均匀化处理过的绿视率、标尺均匀化处理后的总商业数、300 m可达范围内人口数以及标尺化处理后的道路宽度相关性较高。同时,道路宽度、绿化和各空间句法参数三者之间均有明显的相关。由于空间句法表达的道路通达性能够影响流量需求,而流量需求又反映在道路宽度上,因此它能够揭示出流量和宽度等参数背后的行为机制,经上述空间问法参数中备选自变量在多元回归结果中的测试,选取分析效果最优的Log Choice1000进入多元回归分析。另外,由于绿化覆盖率与绿视率对社会聚集的影响非常接近,因此经过测试后选取分析效果好的绿化覆盖率进入多元回归分析。
将遴选后的参数应用SPSS进行多元回归,结果显示4个参数回归模型的R2达到0.758,但人口数及总商业的Sig值过高,未通过显著性检验,并且人口数及商业类参数的标准化Beta系数为负,逻辑上不合理。删除这两个自变量后保留绿化覆盖率与Log Choice1000组合的模型R2为0.729,且Sig值均能通过检验,并且从标准化Beta系数来看,绿化覆盖率的影响(0.519)要大于空间形态(0.484)的影响(表2)。
4.3 雍和宫街区社会聚集回归分析
与前面案例相同,雍和宫街区社会聚集与各个参数的关联,其结果可看出在四大类参数中,社会聚集与绿化覆盖率、标尺均匀化处理后的社区商业数、500 m可达范围内人口数以及标尺化处理后的道路宽度相关性最高(图10)。同样考虑到空间句法参数与其他各自变量普遍存在的相关性,在空间形态类参数中,选取Log Choice1000与上述其他类参数进行多元回归。
结果显示4个参数回归模型的R2达到0.509,但社区商业的Sig值偏高。此外,社区商业与500 m内人口数的标准化Beta系数为负,不合理。删除上述两个自变量后保留绿化覆盖率和空间句法参数Log Choice1000组合的模型R2降为0.271,但两个自变量的Sig值在多元回归中均偏高,无法通过检验(表3)。而单独来看绿化覆盖率与Log Choice1000与社会聚集相关性的大小,明显绿化覆盖率的相关性(0.487)要好于空间形态的相关性(0.413),表明绿化覆盖率对社会聚集具有更高的解释度。
4.4 案例汇总社会聚集回归分析
为了在不同的案例中寻找相对稳定的规律,本研究将两个街区的各自变量拼合到一个大模型中进行多元回归分析。在社会聚集与各个参数的关联的四大类参数中,社会聚集与标尺均匀化处理过的绿视率、标尺均匀化处理后的总商业数、300 m可达范围内人口数以及标尺化处理后的道路宽度相关性最高(图11)。如前所述,在空间形态类参数中,选取Log Choice1000来与其他类自变量组合进行多元回归,在绿化参数中,选取绿化覆盖率进行多元回归。
结果显示4组自变量回归模型的R2达到0.480,但总商业的Sig值偏高,300 m内的人口总数虽能通过显著性检验,但其标准Beta系数仍为负,不合理。删除商业与人口两个参数后保留绿化覆盖率与Log Choice1000的R2为0.384,且两者的显著性均能通过检验。对比两者的标准化Beta系数,绿化覆盖率(0.371)的影响同样大于空间形态(0.357)的影响(表4)。
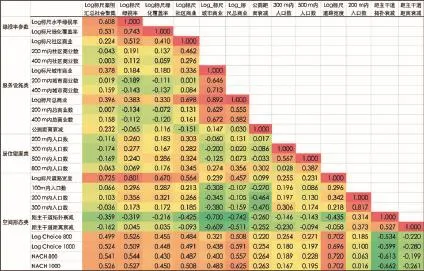
11 案例街区汇总社会聚集与各类参数的相关分析Correlation analysis of social gathering and various parameters in case neighborhoods
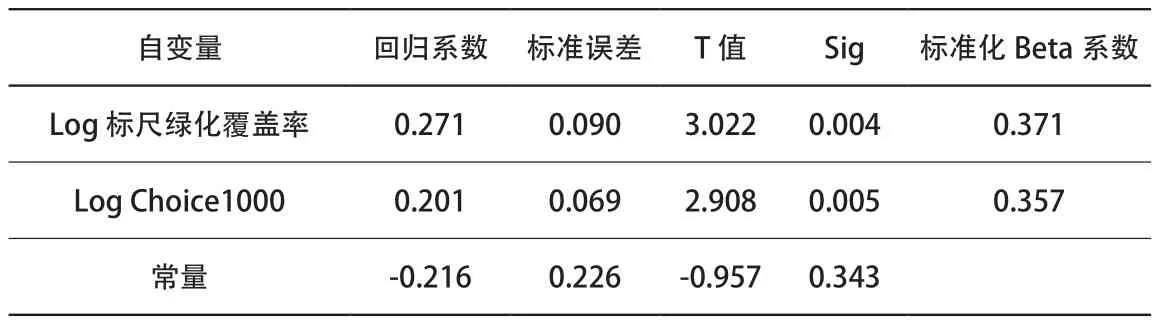
表4 案例街区汇总社会聚集的变量多元回归分析Tab. 4 Multiple regression analysis of the parameters of case neighborhoods
5 结论与讨论:现象与现象关联背后的机制
笔者通过对国子监和雍和宫街区夏季居民社会聚集调研数据的统计与分析,可得出以下几点结论。
1)从空间形态类参数的分析来看,社会聚集受街区形态的影响,国子监街区较之雍和宫街区更为开放和通达,其社会聚集体现出较强的外向性,聚集规模也体现出明显的规律性;而雍和宫的空间形态复杂,社会聚集体现出较强的内向性,聚集规模体现出的规律性差。
2)无论是两个街区单独分析还是汇总后分析,绿化类参数都能表现出稳定的影响,对社会聚集规模分布有最好的解释力,并且水平视角的绿视率与俯瞰视角的绿化覆盖率对社会聚集的影响相差不大,且在两个街区案例中两个自变量的相关性均在0.7以上,这也表明绿化覆盖率高的地方往往给人以较好的绿化视觉感受。
3)从服务设施类参数的分析来看,国子监街区社会聚集更容易受到城市商业的影响,而雍和宫则偏向受社区商业影响,从功能临近性上验证了两个街区外向和内向的属性。
4)从居住密度类参数的分析来看,各分析方式均未能发现社会聚集与各范围内居住人口数的显著关联,这个结果表面上违反常识,笔者分析其原因是胡同街区的居住密度分布比较均匀,街道通达性本身是影响步行者分布的更主要因素。
5)从各案例和汇总案例中各参数的相关分析中可以得出空间句法与绿化类参数、道路宽度以及商业分布等自变量均有较高的相关,这从侧面验证了空间句法的基础理论,即街道的网络拓扑形态影响运动分布,进而影响了街道的尺度和城市的功能。由于笔者在本研究中选取的调研时间为夏季,绿化率作为一个现象与社会聚集的关联更强并不意外,但现实来说,具有一定宽度的胡同才有空间支持更多的绿化,通达性好的街道才有足够的人流量享受树荫带来的环境,进而形成大量的社会聚集。因此,街道空间的通达性是引发这一系列相关现象背后的生成性机制,而对于新住宅区规划和设计而言,根据步行尺度范围的空间通达性计算来确定道路等级和绿化需求,为建立精细化景观设计提供了方法上的支持。
图表来源(Sources of Figures and Tables):
图3处理自猫眼象限APP截图,其余图表均由作者绘制或拍摄。
猜你喜欢
今日农业(2022年15期)2022-09-20
今日农业(2021年11期)2021-11-27
今日农业(2021年21期)2021-11-26
大连民族大学学报(2021年2期)2021-07-16
公民与法治(2020年3期)2020-05-30
当代陕西(2019年5期)2019-03-21
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
西南交通大学学报(2016年6期)2016-05-04
林业与生态(2016年2期)2016-02-27
