
多核并行访问纹理单元的预处理方法∗
2019-11-29 05:13刘世豪杜慧敏黄虎才
计算机与数字工程 2019年11期
刘世豪 杜慧敏 黄虎才 王 可 卢 通
(西安邮电大学 西安 710121)
1 引言
随着计算机图形学技术的快速发展,用户对动画、游戏开发、虚拟现实等图形场景的真实感[1~3]的要求越来越高。纹理映射是GPU(Graphics Processing Unit,图形处理器)实现逼真效果的重要方法[4~5]。
纹理单元是GPU 中实现纹理映射的模块,可分为纹理前处理和纹理后处理,前处理部分读取纹理数据,包含纹理地址计算和纹理cache模块,后处理部分过滤纹理数据后将数据输出,包含纹理过滤和纹理数据输出模块。纹理单元接收SP(SIMT Processor,单指令多线程处理器)发来的纹理数据采样请求,地址计算模块根据纹理坐标计算出纹理数据的地址,再由地址访问纹理cache,读出纹理数据,最后根据纹理采样方式对纹理数据滤波处理,将过滤后的纹理数据返回给SP,纹理单元流水线如图1所示。
基 于tile 渲 染 模 式(Tile-based Rendering,TBR)将一帧图像划分为多个tile[6~7],为提升图像的渲染速度,通常采用多核并行渲染不同tile。当渲染的场景中存在大量重复纹理图片时,如教室内的课桌、草地、鸟群或军队等,不同tile 可能用相同的纹理进行贴图。如图2 所示,图中每个tile 对应的纹理图像都是兔子。
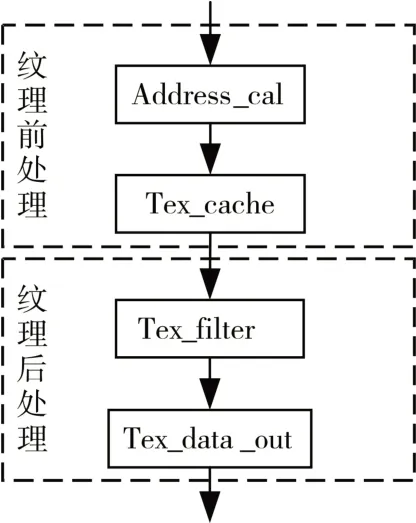
图1 纹理单元流水线

图2 重复贴图的兔子
在基于tile 的GPU 设计中,对于只有一个纹理单元的架构,多个SP 同时访问纹理单元。本文提出了固定处理模式与预处理模式两种方法实现SP对纹理单元的访问。其中,预处理模式可实现多个SP 用相同的纹理数据采样请求,纹理单元只执行一次操作,减少了纹理单元的功耗,提升了纹理映射的速度。本文用System Verilog 语言在VCS 环境下验证了两种方法,测试了4 类数据集。测试结果表明当存在大量重复纹理贴图的情况下,本文提出的预处理方法能够较好提升纹理映射性能。
2 相关研究工作
纹理映射作为提升图像真实感的重要处理方式,国内外进行了深入的研究。
在纹理映射综述方面,张英杰[8]等较早地介绍了纹理映射技术的发展历史和纹理映射中的图形反混淆算法,卢张平[9]等对纹理映射的算法进行分类,从二维纹理映射和三维纹理映射两个大类分别进行阐述。曾成强[10]系统地总结纹理映射技术的发展历史和纹理映射的几种经典算法,并比较了其中几种算法的优劣。
在纹理映射算法方面,谢丰等人采用mipmap滤波对凹凸映射进行优化[11],在保证纹理凹凸感的前提下,减少了凹凸映射的计算量。Wanghai Qing等针对纹理数据大传输粒度导致CPU 无法访问内存和空转的情况,提出了一种数据预取的方法[12],有效提升了渲染速度。杜慧敏和徐启超等提出了采用线性逼近的方法实现各向同性逼近各项异性滤波器[13],该算法易于硬件实现,且误差较小。
在纹理映射架构方面董梁等提出一种实用型流水线设计结构[14],分析纹理单元的功能,并提出了一种纹理映射的设计方法,通过软件进行了功能验证。赵国宇等提出了一种高效纹理单元的硬件架构[15],采用查找表和二次多项式逼近算法优化浮点除法运算,并且动态配置纹理cache的映射方式,优化了纹理单元运算和存储带宽的性能。沈春江完成了纹理单元各模块的设计,纹理载入速率达到了每秒30 帧[16]。韩立敏等提出了一种多模式并行处理硬件专用纹理引擎[17],并行实施多模式的纹理操作,显著提升了纹理贴图的执行效率。
高分辨率的图片意味着更真实的效果,但是会增加存储容量,研究人员以减少数据大小和带宽,同时以最小化视觉影响为目的提出各种纹理压缩方案[18~19]。现在常用的纹理压缩格式有S3 公司发布 的S3TC(S3 Texture Compression),Imagination Technologies 公 司 发 布 的 PVRTC/PVRTC2(PowerVR Texture Compression),Khronos Group 组织发布的ETC/ETC2,ARM 公司发布的ASTC(Adaptive Scalable Texture Compression)等。不同存储格式对纹理映射性能也会产生影响,可利用纹理数据的局部性提升纹理数据访问效率[20]。Baokang Wang 等提出一种Z 型布局的存储格式[21],缩小了地址跨度,减少了cache冲突缺失,纹理数据可根据纹理像素坐标将Z 型区域内的地址设置为连续地址。
纹理单元实现了纹理映射复杂算法,在多核并行访问纹理单元的情况下,若存在一种检测机制,将多核发送的相同纹理数据采样请求合并为一个请求,可减少纹理单元的执行次数,降低纹理单元功耗,并提升纹理映射的速度。业界对于纹理单元并行访问机制的处理方法并没有详细的公开资料,而多核并行访问纹理单元的预处理方法对纹理映射性能有很大提升,因此该方向的研究具有重要意义。
3 纹理映射的两种方法
3.1 固定处理模式
多个处理器核对应同一纹理单元的固定处理模式结构如图3所示。设定8个SP对应1个纹理单元,当多个SP 同时访问纹理单元时,纹理单元首先对多个请求进行仲裁,采用自适应轮询调度算法选出当前优先级最高的SP 请求。轮询调度算法[22]设定每个SP 的优先级相同,防止固定优先级导致的低优先级饿死情况。
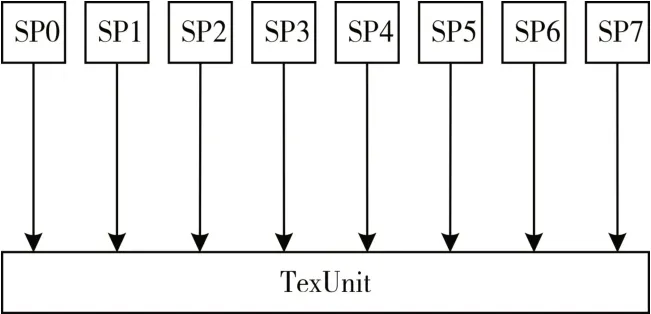
图3 固定处理模式结构
GPU 在处理图像时,所有的SP 不是每拍都会同时发出请求,针对此类情况采用自适应轮询调度算法。当全部SP同时发出请求时,第一拍执行SP0请求,第二拍执行SP1 请求,依次轮询。但是由于SP执行的tile场景可能不同,因此不一定全部SP同时发起纹理请求,如果当前拍只有SP1、SP2 和SP6访问纹理单元,那么当前的优先级为SP1→SP2→SP6,如果下一拍的请求为SP1、SP2、SP4 和SP6,那么当前优先级为SP2→SP4→SP6→SP1。优先级按照0-7 的顺序依次轮询,刚被执行的SP 在下一拍的优先级最低,当前拍的优先级排序只在有纹理请求的SP中进行。
纹理单元对仲裁出的请求进行处理,当多个SP 访问相同纹理坐标的情况,该模式仍然对每一个访问请求进行处理,在单帧重复贴图基数大的模型场景中,纹理单元会存在大量的重复性操作,导致功耗大并且处理内容冗余。
3.2 预处理方法
3.2.1 预处理方法的基本思想
根据自适应轮询调度算法确定当前SP 访问请求的优先级,当出现多个SP 的纹理采样点相同时,合并相同纹理采样请求,使纹理单元只执行一次纹理数据采样操作。预处理结构图如图4所示。
预处理方法是在纹理单元的前处理部分(Tex_pre_process 模块)增加外围电路,包括Arbiter模块、Req_buf 模块和Data_buf 模块。预处理方法通过两次比较解决了同一时刻和某段时间内出现相同纹理数据采样请求的情况,减少了纹理单元重复冗余的操作。
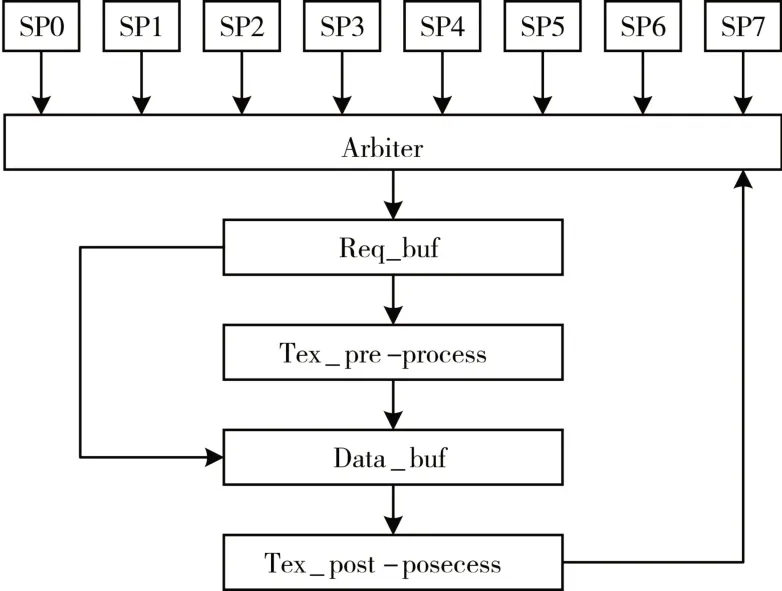
图4 预处理结构图
3.2.2 各模块功能及处理流程
1)发出采样请求
图中各个SP用于渲染不同tile内场景,SP下发纹理映射请求给Arbiter模块,请求数据包含纹理映射的状态信息(如纹理坐标、SP 的ID、每个SP 的请求ID、纹理图片大小、纹理数组使能和阴影贴图使能等)。
2)仲裁并处理采样请求
Arbiter 模块接收各个SP 发来的纹理映射请求,根据自适应轮询调度算法得到当前拍优先级最高的SP请求,并送给Req_buf模块。
Arbiter模块将优先级最高的SP请求与其他SP请求进行比较,如果纹理坐标相等,说明同一拍中不同SP 有相同的纹理数据采样请求,这里规定其他的纹理数据采样请求为副本请求。当前节拍仲裁出的纹理请求经Req_buf送给Tex_pre_process模块,然后通过Data_buf,再由Tex_post_process 模块把采样点处的纹理数据送给Arbiter 模块。优先级最高的纹理请求和所有副本请求对应的SP 都接收该次采样的纹理数据,上述处理过程如图5所示。
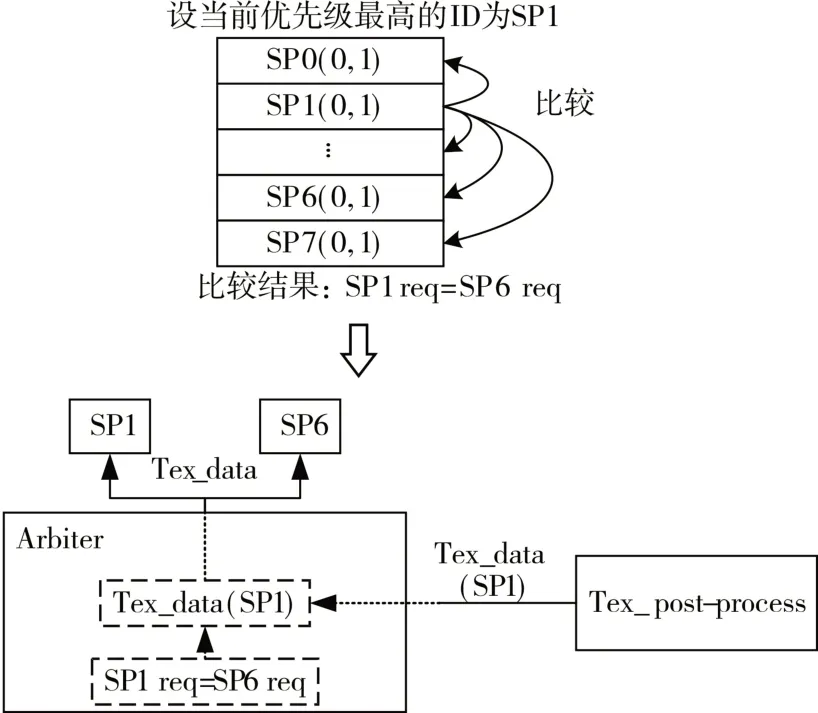
图5 合并相同SP请求示意图
Arbiter 模块解决了同一拍中多个SP 的纹理数据采样请求相同的问题,并行地将纹理数据返回给所有发出相同纹理坐标请求的SP。
3)缓存不同纹理数据采样请求
Req_buf 模块接收Arbiter 模块发送的纹理数据采样请求,并缓存最近n 次无副本请求的纹理坐标。Req_buf深度为n,缓存的数据为纹理坐标。
Req_buf每接收到一个新请求都会与其内部缓存的旧请求进行坐标比较,如果新请求的坐标和Req_buf 某行存储的纹理坐标不相同,则缓存本次新请求,并且将新请求发送给Tex_pre_process模块读取纹理数据。如果新请求和Req_buf 某行存储的纹理坐标相同,说明在n 次访问内已经读取了该纹理坐标对应的数据,那么本次的请求无需发送给Tex_pre_process 模块,将纹理坐标直接发送到Data_buf,读取该坐标对应行的数据,比较方式如图6所示。
当buffer 内数据存满并且新的纹理请求与buffer 中任意一行不匹配,则采用先入先出的替换策略,替换n行中最先存入buffer的数据,如图7所示。
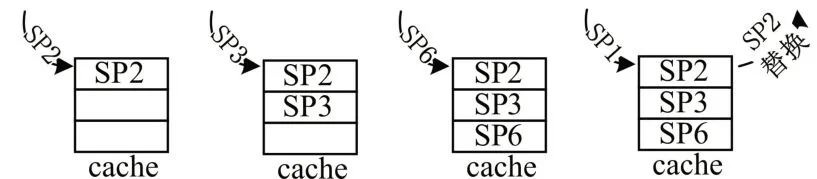
图7 替换策略
4)读取纹理数据
Tex_pre_process 模块实现纹理数据读取功能。该模块接收纹理采样请求,在经过纹理地址计算和读取纹理cache数据后得到对应坐标的纹理数据,将纹理数据和纹理坐标送给Data_buf。
5)缓存纹理坐标与纹理数据
Data_buf 每一行存放的数据为纹理坐标和纹理数据。Data_buf深度为n,当buffer数据存满时采用先入先出的替换策略。
Data_buf 将Tex_pre_process 模块输出的纹理坐标和数据缓存到buffer 内,然后将接收到的纹理数据送给Tex_post_process 模块。并且Data_buf 会与Req_buf 发送的坐标进行匹配,为未经过Tex_pre_process 模块处理的请求读取数据,如果坐标命中,将相应buffer 行的数据送给Tex_post_process 模块,如果坐标未命中,则将该坐标存入Data_buf中的失靶buffer中,Data_buf每接收一组纹理坐标与数据都会与失靶buffer 中的坐标进行匹配,直到读出纹理数据。
6)纹理后处理
Tex_post_process 模块根据纹理映射模式对纹理数据进行过滤和格式转换等操作,由该模块得到采样点处纹理数据,然后输出给Arbiter模块。
4 性能评价
本文对纹理映射的两种方法进行抽象,将方法一与方法二的性能进行比较。在存在大量重复纹理图像的场景中,量化地统计方法二相较于方法一的性能提升比率。
采用System verilog 进行建模,在VCS 平台仿真,时钟频率为100MHz,测试数据2048个,每个SP对应16*16的像素块,处理256个数据,不同测试集下预处理方法的速率提升结果如表1所示。

表1 预处理模式的性能提升比率
A 类测试集:16*16的像素块内贴4个8*8的纹理图像,每个SP随机发送纹理坐标。
B 类测试集:16*16 的像素块内贴16 个4*4 的纹理图像,每个SP随机发送纹理坐标。
C 类测试集:16*16 的像素块内贴64 个2*2 的纹理图像,每个SP随机发送纹理坐标。
D 类测试集:8 个SP 向Arbiter 模块发送纹理请求,每个发送256个,每个SP发送的纹理坐标相同。
5 结语
纹理映射是图形渲染管线中极其重要的一部分,它是图像真实性的有效保证,性能优越的纹理单元不仅能够保障图像的真实性,也能提升纹理映射的处理速度。对于多核并行访问纹理单元的架构,应该根据渲染图像的特点,合并相同的纹理数据采样请求,减少纹理单元的冗余操作,本文据此提出了一种多核并行访问纹理单元的预处理方法,对预处理模式的各个模块进行介绍,核心思路为采用两次比较的方式减少了冗余操作,提升了纹理单元的性能。实验结果表明,在存在大量重复纹理贴图的情况下,能够较好提升纹理映射性能。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康体检与管理(2022年4期)2022-05-13
建材发展导向(2021年23期)2021-03-08
软件(2020年3期)2020-04-20
保健与生活(2019年7期)2019-07-31
Coco薇(2017年8期)2017-08-03
中学生数理化·高一版(2016年6期)2016-05-14
