
基于Hadoop的海洋位置大数据平台架构设计*
2019-11-28 03:09彭庆喜
舰船电子工程 2019年11期
包 磊 彭庆喜
(武汉东湖学院计算机科学学院 武汉 430079)
1 引言
海洋位置大数据是指含有空间位置和时间标识的海上地理和人类社会信息数据,包括海洋地理环境数据、海上移动对象轨迹数据和海上空间媒体数据[1]。此类数据具有大数据所共有的数据类型多样、数据变化高速、数据规模海量和数据价值密度低等特性。同时其分布更加不均匀,时空跨度更大,过程中受水文、气象、人员以及船舶状态等大量因素影响。船舶自动识别系统(Auto Identification System,AIS)、GPS及北斗导航系统、国家海洋预警探测系统、以及Argo、海王星等诸多海洋观测计划源源不断地提供着海量数据,其数据量早已达到了TB级别,且呈持续增长的趋势。仅仅以AIS数据为例,全球每天通过卫星和基站收集的AIS数据约为4G,一年产生的AIS数据量可达1.4TB。建立适合海上位置大数据特性的平台,对相关数据进行采集、存储、分析和利用是当前一个焦点问题。
2 相关研究现状
由于传统大数据平台无法对数据的时空特征提供有力支持,海洋位置大数据的处理必须采用能够支持空间数据类型的空间大数据平台。目前空间大数据平台的实现有两种思路:其一,以空间数据库实现空间数据存储,结合分布式引擎Hadoop/Spark进行空间运算,形成分布式空间数据分析框架;其二,采取基于普通大数据处理平台Hadoop/Spark架构逐层拓展的方法,使其对空间数据处理具有敏感性。其中,Hadoop-GIS[2]通过与 Hive集成,利用MapReduce处理边界对象,实现了Hadoop的大型空间运算[3]。将数据存储在Post-GIS中,通过Java拓扑套件实现了用户自定义函数在Hadoop/Hive上的空间运算。Esri的Spatial Framework for Hadoop[4]将 ArcGIS与Hadoop集成,通过在 Hive中注册空间查询函数,查询Hadoop分布式文件系统(HDFS)上的空间数据,提高了空间大数据的并行化处理能力。SpatialHadoop对传统Hadoop存储架构进行了空间扩充,并设计了专用的Mapreduce计算方法来实现一些空间操作,用于支持空间位置数据处理[5]。GeoSpark[6]是建立了一种基于 Spark 的空间大数据处理架构,使用Apache Spark作为底层支持,使用空间RDD数据分布方法建立了空间查询的处理和计算能力。
由于侧重点不同,现有方法在存储层、计算层或基本操作层存在不同程度的不足,有的使用HDFS存储空间数据,无法建立空间索引,有的对空间数据格式存在一定限制,数据管理难度高。本文根据海洋位置大数据的特点和处理分析能力需求,对Hadoop平台进行了扩充,设计了一种专用数据处理平台架构,在数据类型层、存储层、计算层和基本操作层对海洋位置大数据提供了支持。
3 海洋位置大数据平台框架设计
3.1 总体框架
海洋位置大数据分析平台的核心部分是位置大数据的存储、计算和分析结构。在存储上沿用Hadoop的HDFS分布式文件存储系统,同时通过添加空间索引结构来提高计算效率。空间索引在文件输入时建立,使空间位置邻近的数据对象存储于同一个HDFS块内,并对块内数据建立索引。建立好的索引文件作为MapReduce计算框架的输入文件。并根据空间索引扩充MapReduce组件结合所实现功能的数据需求,利用索引文件滤除不相关数据,避免产生不必要的计算冗余。基于扩充MapReduce框架,实现基本空间分析操作,包括空间对象的基本拓扑操作以及范围查询,KNN最近邻查询等。基于这些基本空间分析操作可以进一步完成统计分析、时空聚类、分类或模式挖掘分析和可视化。如图1所示。
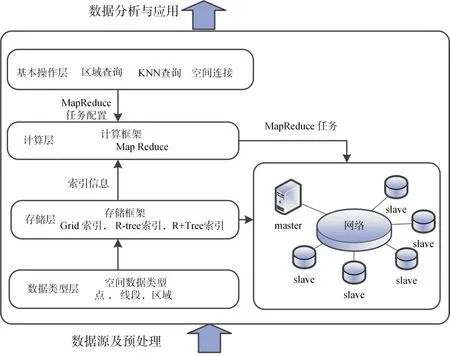
图1 海洋位置大数据分析平台架构
平台架构的核心设计为涵盖数据存储与计算的数据处理框架设计。空间Hadoop数据处理框架是在传统Hadoop数据处理框架的基础上对数据类型层[8~9]、存储层、计算层和操作层等核心内容进行空间拓展而来。
3.2 基于HDFS的空间索引与存储结构设计
在Hadoop上直接构建传统空间索引会遇到两个问题:其一,传统空间索引采用过程编程范式,而Hadoop采用的是MapReduce编程范式;其二,传统索引采用局部文件系统,而Hadoop采用HDFS分布式文件系统。为了克服这些问题,采用两级空间索引结构(即全局索引和本地索引)。全局索引在集群节点间分割数据,本地索引在节点内部高效地组织数据,两级空间索引结构适合MapReduce编程范式。索引建立由三个阶段组成,即数据分区阶段、本地索引建立阶段和全局索引建立阶段。
1)数据分区阶段
数据分区决定如何使用相互独立的空间矩形划分空间区域。不同的空间索引算法具有不同的划分过程和结果。在图2、图3中分别给出了均匀分布网格Grid索引和R-tree索引[10]的不同分区结果。
根据所确定的分割边界,创建一个MapReduce任务来实现物理分割。分割的难点在于如何处理跨边界对象。这里采用的方式为允许将该对象重复划分到所有覆盖的分区,而在后续计算过程中加以专门处理。
2)本地索引建立阶段
本地索引是单个分区内数据对象的空间索引结构(如网格索引或R-tree索引),并作为本地索引存储于Slave节点上。本地索引的存储位置为每个HDFS块,这样有利于:(1)允许空间操作使用MapReduce任务的单个Map函数去处理本地索引;
(2)本地索引处理均衡化。
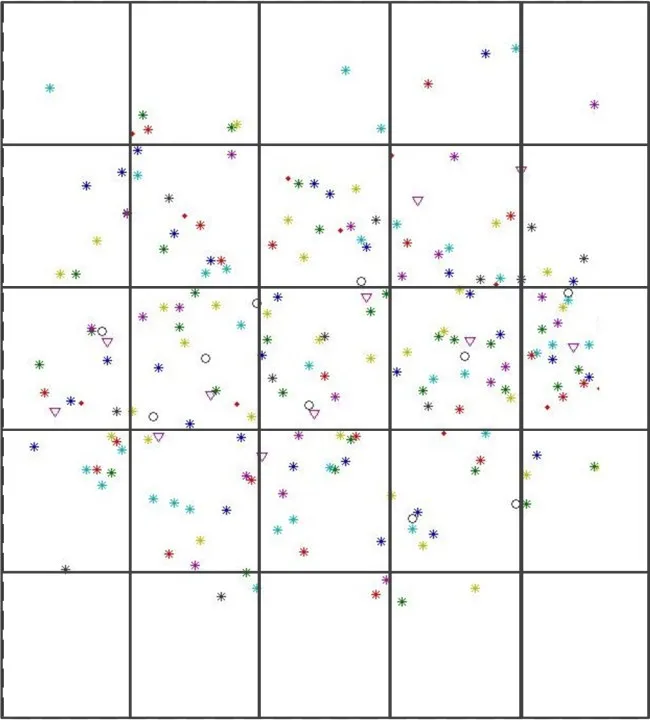
图2 Grid索引分区
3)全局索引构建阶段
建立所有本地索引的总体索引结构,并作为全局索引存储于Master节点上。因此,Master节点可以利用全局索引查询与任意矩形区域重叠的所有本地索引文件。
3.3 基于Map Reduce的空间计算框架
基于HDFS的空间索引结构是MapReduce空间计算框架的基础。传统的Hadoop中MapReduce计算框架处理的对象为不带索引的堆文件。由专用的分割器将将输入文件分割为多个分区,使用对应的映射函数,将分区解析为对应的键值,进而传递给Map函数进行处理。Map函数的处理结果传入Reduce函数进行处理。最后将Reduce函数的输出结果作为最终结果输出。
在这种机制上,考虑到空间索引,我们给出的计算框架在MapReduce层设计了两个新组件,即SF-Splitter组件和SR-Reader组件。SF-Splitter组件是传统MapReduce分割器的拓展,其输入是全局索引文件,利用全局空间索引,根据其空间位置对数据文件进行修剪,建立数据分区,传给SR-Reader进行后续处理。与传统Map函数不同,SR-Reader组件获取局部索引,按照数据块的空间区域最小外界矩形将局部索引的指针传递给Map函数,经过Map函数处理的键值传递给Reduce函数进行处理,后续处理与传统Hadoop计算框架一致。

图4 基于MapReduce空间位置数据计算框架
3.4 位置大数据基本空间操作设计
在存储层和计算层设计基础上,平台架构支持常用空间操作的设计与开发,基本空间操作[11~12]见表1。

表1 基本空间操作
以Rangequery操作为例:Rangequery操作的输入是一个区域A和一个空间对象集合R,输出为集合R中所有被包含在A中的对象集合。算法通过两步完成,首先利用所建立的空间索引筛选空间对象,然后利用空间拓扑分析操作对各个数据分块中的数据进行拓扑计算,最后整合结果。
4 结语
4.1 部分实验结果
根据海洋位置大数据特点和分析需求,本文设计了基于Hadoop的分析平台架构。平台的核心处理框架从数据类型层、存储层、计算层和基本操作层进行了拓展。数据类型层包括点、线段和面三种类型。存储层在HDFS的基础上插入了两级空间索引结构,支持Grid File、R-tree索引和R+tree索引的建立。计算层增加了两个新组件,用于支持索引文件的处理。按照此平台架构,我们建立了一个原型系统,实现了最小外接矩形MBR、空间范围查询以及空间KNN等六种基本操作,并以此作为后台数据处理引擎,使用实际AIS数据进行了初步的统计和时空数据挖掘实验。如图5~7所示,在这些实际应用中,我们建立的一个4个节点的小型平台,能够以高于传统Hadoop框架一个数量级以上的速度处理10g以上的数据集,取得了相当好的结果。

图5 船舶热点海域计算[7](数据量9G,马拉西亚附近海域)
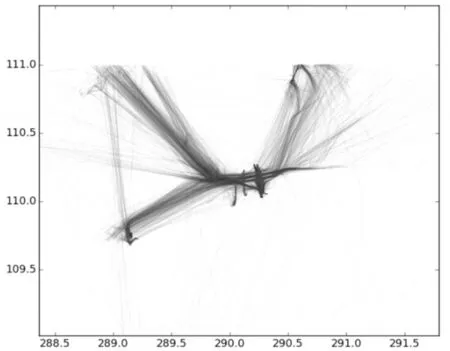
图6 船舶航迹聚类计算(数据量3G,琼州海峡)


图7 船舶航迹聚类与异常检测计算(数据量7G,纽约港附近海域)
4.2 下一步研究方向
基于平台,海洋位置数据经过统计分析、时空分类、聚类以及模式挖掘分析和可视化分析可以为海洋环境监测、航线优化、轨迹预测、海上危机评估和海上监管等应用提供服务。然而,为获得更好的分析结果,仅对位置数据进行分析处理是不够的,必须融合多源数据进行综合分析或协同挖掘,这要求平台应具备多种异质异构大数据的处理和分析能力。另外,本文中的平台只提供了空间索引能力,并未提供在时间上的有效索引机制。这些都是下一步需要研究的方向。
猜你喜欢
大众科学(2022年5期)2022-05-18
心理学报(2022年4期)2022-04-12
环球时报(2022-03-29)2022-03-29
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
现代职业教育·职业培训(2019年12期)2019-02-03
