
三种话音网络性能研究方法的比较分析*
2019-11-28 03:09马文君
舰船电子工程 2019年11期
马文君 王 磊
(1.解放军91033部队 青岛 266000)(2.解放军91049部队 青岛 266000)
1 引言
随着用户的增加以及资源的消耗,电话网络阻塞日益严重,远不能满足人们的需求。基于此,通过仿真话务量模拟各局间电路的使用情况,分析网络阻塞的原因并提出改进措施已成为解决此类问题的最有效方法[1~3]。
话务量(Erl)是指单位时间(一般为1h)内用户的平均占线时长,实际统计时都是取某段时间内用户忙时的话务量[4~6]。
2 数学分析法
2.1 话务量的产生
以图1中的拓扑结构为例对话务量的产生进行说明。
节点1为一级用户交换机,节点2为二级用户交换机,节点3,4为端局交换机。话务量假设:
1)节点1承载500个用户,向节点2的出局话务量需求每线0.15erl。

图1 节点交换机示例拓扑结构
2)节点2承载500个用户,10%的用户向节点1的出局话务量需求每线0.11erl;90%的用户向节点3和节点4的出局话务量需求为每线0.06erl。
3)节点3和节点4分别承载300个用户,其中10%的用户向节点1的出局话务量为每线0.05erl;20%的用户向节点2的出局话务量为0.08erl;节点3->节点4,节点4->节点3的出局话务量为每线0.03erl(10%的用户)。
根据以上需求对节点间的话务量进行计算:
节点1->节点2:500×0.15=75erl;
节点2->节点1:500×10%×0.11=5.5erl;
节点2->节点3:500×90%×0.06×[300/(300+300)]=13.5erl;
节点2->节点4:500×90%×0.06×[300/(300+300)]=13.5erl;
节点3->节点1:300×10%×0.05=1.5erl;
节点3->节点2:300×20%×0.08=4.8erl;
节点3->节点4:300×10%×0.03=0.9erl;
节点4->节点1:300×10%×0.05=1.5erl;
节点4->节点2:300×20%×0.08=4.8erl;
节点4->节点3:300×10%×0.03=0.9erl。
因此根据话务量需求得到的局间话务量矩阵为

利用VC++模拟话务量的产生即根据上述方法。
2.2 基于VC++的话务量产生
2.2.1 输入文件《demand_properties.txt》
《demand_properties.txt》中的数据含义以表 1为例进行说明。

表1 节点3话务分布属性
属性说明:
1)Node_ID 3:表示此节点的编号为3;
2)Node_name一级节点:表示该节点名称为一级节点;
3)User_number 100:表示此节点承载的用户数目为100;
4)grade 0:grade为级别标志,0表示此节点的级别为一级节点(本程序的grade共包括0、1、2共3个级别;其中0、1、2分别对应一级、二级以及端局;
5)area 0:area为区域标志,0表示此节点在一级所在地(本程序的area共包括0、1、2共3个区域;分别对应一级所在地、二级所在地、端局所在地;
6)type行政部门:type为节点类别标志,行政部门表示此节点属行政类(本程序的type共包括行政部门、后勤部门、管理部门、教学部门共4个类别;
7)properties:properties为节点出局话务属性标志,表示后面的内容全部属于节点出局话务属性部分。
8)0.3一级全网向下:此节点承载的用户中有30%的用户与二级及端局有通信需求;
9)0.2一级横向:此节点承载的用户中有20%的用户与同级别节点有通信需求。
2.2.2 输入文件《group.txt》
《group.txt》是对《demand_properties.txt》中各节点话务分布属性的概述,即与某一节点有通信需求的其他节点的属性集合。具体数据含义以文本1为例进行说明。
文本1一级全网向下属性集合

文本1中,如果一个节点的属性(properties)中有“一级全网向下”,则表示此节点与级别(grade)为1(二级),区域(area)为1~2中的任何一个,节点类别(type)不限的节点有通信需求。图2为利用VC++模拟局间话务量的产生情况。

图2 局间话务量的产生
2.3 网络话务量资源分配
根据当前网络资源的占用情况,从业务量对应的源宿节点对的最短路由集合中选择路由。根据“先直达、后迂回”的原则,本文采用K-shortest算法求解路由,即为每对业务需求找k条符合实际需求的最短路,选择最短的一条作为传输路径。若最短路无法满足需求,则选择次短路;若次短路仍然无法满足需求,则选择下一次短路;以此类推,直到选到合适的路由,并分配资源。如果所有的备选路均无法满足需求,则此业务量即此次呼叫无法连通。
采用网络仿真的方法研究电话网性能时同样选取K-shortest路由算法。
2.4 基于VC++的网络性能仿真
2.4.1 输入文件《topology.txt》
文件《topology.txt》主要用于描述实际网络拓扑的基本信息。具体的数据含义以文本2为例进行说明。
文本2网络拓扑输入文件部分数据

文本2中,每一行代表网络中一条有向链路的基本信息。第一列数据的物理含义为链路的源节点;第二列数据表示链路的目的节点;第三列表示链路的权重(即根据权重和最小的原则选取最短路);第四列表示该链路的带宽资源。这里的带宽资源是以干线时隙为基本单位。
2.4.2 输入《traffics.txt》
《traffics.txt》即为话务量生成程序的输出文件(图2所示)。图3为基于VC++的仿真结果。
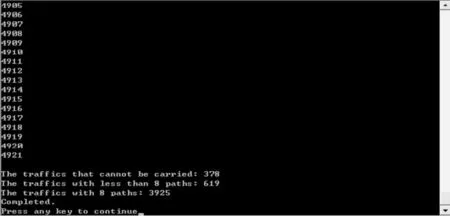
图3 仿真结果显示
2.4.3 仿真结果的收集
收集的仿真结果为各局间链路的利用率(列举部分),如表2所示。
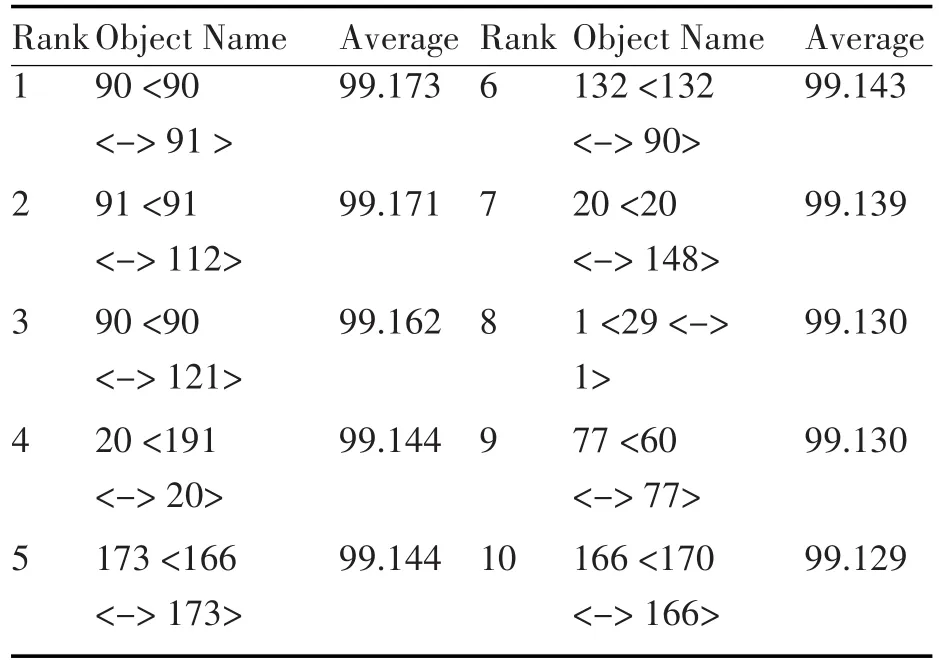
表2 Circuit Trunks.Utilization(%)
3 网络仿真法
3.1 基于OPNET10.5仿真平台的电话网性能研究
3.1.1 网络仿真拓扑的构建
本文所仿真的节点数共187个,对于节点数多且网络分布比较复杂的情况下,手工绘制拓扑图的做法不可取。OPNET中的拓扑快速配置(Rapid Topology Configuration)功能只适用于有限种类的拓扑结构,且生成的模型节点可能重叠。针对这种情况,OPNET提供了基于EMA文件的网络拓扑导入功能[7~8]。
EMA(外部模型访问)技术通过类C和C++语言使OPNET在没有图形编辑器的情况下实现网络模型的读写控制[9],如图4所示。

图4 利用EMA实现网络拓扑模型的读写控制
拓扑构建的具体流程如下:
1)打开OPNET控制台窗口,进入EMA代码文件(后缀名为*.em.c)所在目录,输入命令op_mkema-m文件名(本例为tele_circuit-EMA,不加后缀);执行刚创建的可执行文件<文件名.i0.em.x>。具体如图5所示。

图5 后台运行过程
2)点击菜单File->Model Files->Refresh Model Directories刷新模型目录,然后点击Scenarios→Scenario Components→import…即可。
由以上三种拓扑构建方法可以看出,在网络节点数多且分布不规律的情况下,利用EMA技术生成网络节点的做法是可取的,减少了仿真前期的工作量。所生成的网络拓扑如图6所示。
3.1.2 仿真话务量选择
如表3所示,各级别节点的话务量大小如下:
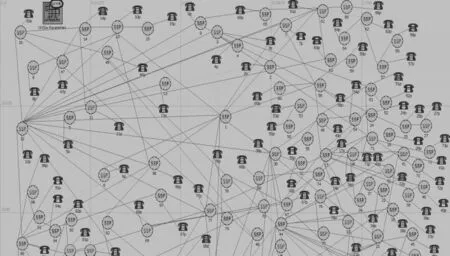
图6 网络仿真拓扑

表3 话务量统计
1)一级局的话务量最大,其忙时话务量为0.15er;
2)二级局对上和对下的话务量差别不大,但对下的话务量一般都是通过本区域的网络直达端局的节点,对其他节点和干线几乎没有影响,所以其忙时话务量为二级局到一级局和横向的话务量之和,即0.06er;
3)端局对本区域内一级和二级局的话务是最大的,但本区域的话务对其他节点和干线几乎没有影响,所以选择端局的横向话务量为0.01er。仿真时各级节点选取的单位用户话务量大小如表4所示。
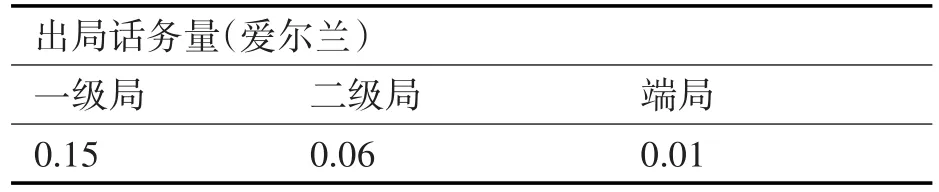
表4 各级局的出局话务量
3.1.3 仿真结果的收集
收集的仿真结果为各局间链路的利用率,如表5所示。
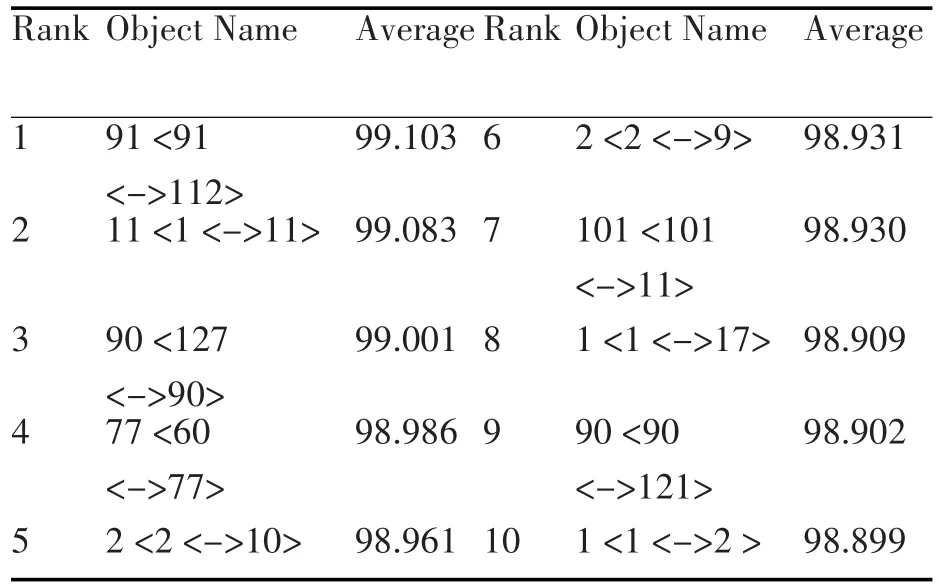
表 5 Circuit Trunks.Utilization(%)
3.2 基于OPNET 14.5仿真平台的电话网性能研究
OPNET 10.5利用离散事件仿真(DES)的机理进行电话网性能研究,无论是仿真的繁琐程度或是仿真效率都是不可取的。
虽然OPNET10.5里提供的Flow Analysis模块[10]可以提高仿真运行速度,但其需要首先导入背景流量(background traffics),而 background traffics的构建只适用于IP-enabled类节点,且对于电路交换,只有OPNET中的promina节点模块族支持背景流量的导入和Flow Analysis功能。这种缺陷使得Flow Analysis模块的运用受到了限制。
因此OPNET14.5做了改进,使用Flow Analysis模块研究电话网性能时,不再局限于promina节点模块族,普通的电路交换节点设备即可满足(如图7所示)。因此仿真的繁琐和仿真的效率较10.5版本都有了较大的提高。

图7 OPNET 14.5中的背景流量导入(黑色双向虚箭头)
为举例说明,图8为OPNET 14.5中局间链路2->10方向上的背景流量(话务量)导入界面。

图8 背景流量设置
收集的仿真结果为各局间链路的利用率,如表6所示。

表 6 Circuit Trunks.Utilization(%)
4 结语
由前面三种研究电话网性能的方法可知,三种方法所得到的结果虽然相似,但是三种方法所耗费的时间却是迥异的。据粗略估计,不包括前期相关模型建立和参数配置花费的时间,其中数学分析的方法总共耗时3h才运行出结果,基于OPNET10.5仿真平台中的DES机制总共运行了2分31s,而利用OPNET14.5中的Flow analysis机制总共的运行时间仅为5s。因此基于OPNET14.5中流分析机制的话音网络性能研究方法是一个不错的选择。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
移动通信(2021年5期)2021-10-25
科技创新导报(2016年27期)2017-03-14
作文大王·笑话大王(2016年6期)2016-06-22
作文大王·笑话大王(2016年4期)2016-04-27
作文大王·笑话大王(2016年3期)2016-03-11
作文大王·笑话大王(2016年1期)2016-02-24
