
改进YOLOv3模型对航拍汽车的目标检测
2019-11-27 05:23谢晓竹
装甲兵工程学院学报 2019年3期
谢晓竹, 薛 帅
(陆军装甲兵学院信息通信系, 北京 100072)
在小型无人机云台上加载高清摄像机进行图像和视频拍摄,已经成为其应用方式之一[1]。人们通过分析无人机拍摄回来的图像和视频,对感兴趣的目标对象进行分析,进而获取有用的信息。根据自动化程度的高低,获取有用信息的方式可区分为人工手段和智能手段。人工手段是指将无人机传回的图像和视频通过专业人员逐个检测,进而得到分析结果。但随着大数据时代的到来,当面临海量的数据时,这种方式不仅工作效率低,而且耗费了大量的人力和物力,已经不能适应时代的发展。智能手段是计算机辅助分析的一种方式,其中目标检测是其主要的研究内容和应用前提。
在计算机视觉领域中,目标检测是指通过计算机分析图像和视频,对感兴趣的目标进行识别,进而获取目标的类别和准确位置。传统的目标检测算法有很多,如Haar+Adaboost[2]、HOG(Histogram of Oriented Gradient)+SVM(Support Vector Machine)[3]和DPM(Deformable Parts Model)[4]等,这些算法的共同缺陷是需要手工设计特征,难以适应目标的多样性变化,检测模型的鲁棒性不强。深度学习方法以构建多层卷积神经网络为基础,通过对海量的数据进行学习训练,进而得出优化的网络模型参数,以此来实现目标的检测。相对于传统的方法,该方法不仅在检测准确率上有了很大提高,其对复杂背景(如光照、阴影、雾气等)下的目标检测也有很好的检测效果。因此,深度学习方法已成为目标检测的主流。
基于深度学习的目标检测方法可分为2大类:一类是基于区域建议的方法,通常称为两阶段检测,该方法首先提取可能存在目标的候选区域,而后对提取的候选区域进行分类和边界位置回归,其优点是检测准确率高,不足是速度慢,很难满足实时性要求;另一类是端到端的目标检测方法,也称作一阶段检测,相对于两阶段检测,其主要优势是速度快、实时性强。笔者基于端到端的目标检测YOLOv3模型[5],以无人机航拍汽车为检测对象,结合无人机航拍的应用场景特点,提出改进的模型,为无人机交通监管智能化提供前期的探索性研究参考。
1 YOLOv3模型
YOLOv3模型是当前YOLO(YouOnlyLookOnce)模型[6]的最新改进版本。该模型采用称作Darknet-53的全卷积网络结构作为主结构,拥有52个卷积层和1个池化层。同时借鉴了残差网络(Residual neural Network,ResNet)[7]和特征金字塔(Feature Pyramid Networks,FPN)[8],可实现多尺度目标的预测。其算法基本思想是:当训练模型时,利用全卷积网络提取输入图像特征,获取3种尺度大小的特征图,分别为N1×N1、N2×N2和N3×N3,相当于将输入图像分别划分为N1×N1、N2×N2和N3×N3个单元格。如果输入图像中的被检测物体中心点落入某个单元格,那么就由该单元格负责预测该目标。该单元格在3种尺度下分别选取和标签框最大的交并比IOU(Intersection Over Union)进行预测,同时使用多个逻辑分类器进行回归,从而训练出网络结构的每一层权重参数。当预测时,利用训练好的网络模型对输入图像即可实现一次性输出,即实现目标的分类和定位,其模型结构如图1所示。

图1 YOLOv3模型结构
输入图像在经过79层卷积后有3个分支:第1个分支经过3个卷积层生成第一种尺度(大小为13×13像素)的特征图,相对于原输入图像大小,下采样倍数为32,感受野最大,主要用来检测图像中相对尺寸较大的物体;第2分支经过1个卷积层卷积后,进行2倍上采样操作,然后与卷积层第61层进行特征融合,即相同大小的特征图维度相加,而后经过一系列卷积后形成第2种尺度(大小为26×26像素)的特征图,相对于原始输入图像大小,下采样倍数为16,主要用来检测图像中中等尺寸大小的物体;第3分支采用同样的原理,通过融合91层与36层,形成第3种尺度(大小为52×52像素)的特征图,下采样倍数为8,感受野最小,适合检测图像中尺寸较小的物体。
2 模型的改进
2.1 航拍汽车目标的特点
与普通拍摄相比,航拍汽车具有如下特点[9]:
1) 汽车目标相对尺度多样。由于拍摄的高度及角度不同,如50 m高空拍摄与300 m高空拍摄,正上方拍摄和侧上方拍摄,会形成图像或视频帧中的汽车目标大小不一,形状各异,这是检测的难点之一。
2) 拍摄图像质量差异多变。万里晴空下,成像质量较高。不良气候下,受到风力及无人机自身飞行稳定性能的限制,虽然有云台发挥作用,但抖动还是不可避免。同时,受阴雨、雾霾等不良天气的影响,成像画面模糊,汽车特征不明显。
3) 拍摄视野广。航拍的图像或视频帧中包含很多与检测目标无关的干扰信息,并且通常情况下一张图像或视频帧中包含的检测目标也较多,增大了检测的难度。
2.2 YOLOv3模型的改进
传统的YOLOv3模型通过在3个尺度中实现高层特征与低层特征的融合,形成了类似于金字塔式的语义信息,增强了网络的表示能力。相对于YOLOv2模型[10],虽然提升了对多尺度目标的检测能力,但对小目标的检测精度还不是很高,定位时IOU较低。结合单类别目标检测的特点和航拍汽车检测的实际应用场景需要,笔者对YOLOv3模型主要进行如下2个方面的改进。
2.2.1 增强分支融合
在YOLO系列模型思想中,网格分得越细,对尺寸较小的目标检测能力越强,但同时也会带来网络参数的成倍增加,增大了模型的训练难度和复杂度,进而会影响模型的实际检测精度和速度。综合衡量,为增强对小目标检测能力,提高定位精度,笔者提出了改进大尺度分支网络结构的模型,命名为ZQ-YoloNet,主要是通过加强第3分支的语义表征能力和位置信息,进而优化检测效果。改进的模型依然使用YOLOv3的主结构,在其他2个分支结构不变的情况下,卷积层(第79层)特征图经过4倍上采样后与第36层特征图进行级联融合,而后再与经过2倍上采样后的卷积层(第91层)特征图进行级联融合,最后与经过数次卷积后的卷积层(第11层)进行级联融合,最终构成尺度3分支结构,改进模型的结构如图2所示。

图2 改进模型的结构

2.2.2 优化生成锚点框(anchors)
YOLOv3模型使用k-means聚类(dimension clusters)方法自动生成锚点框,默认输入图像大小为416×416像素,使用距离公式为
d(box,centroid)=1-IOU(box,centroid),
(1)
式中:d(box,centroid)为标签框与中心框的距离;IOU(box,centroid)为标签框与中心框的交并比。因为应用场景的差异,原模型使用的锚点框是由COCO(Common Objects Context)数据集中得出的,并不适用于本文训练使用的数据集,因此需要分析k值的大小并重新生成相应的锚点框。与原模型不同,本文使用k-means++聚类[11]方法,其算法基本流程如下:
1) 初始化。获取训练数据集中标签框坐标(xi,yi,wi,hi),i=1,2,…,n,其中n为训练集中标签框的总数,(xi,yi)为标签框中心坐标,wi、hi分别为标签框的宽和高。同时从数据集中随机选定一个样本作为聚类中心C。

3) 重复第2)步,直至选出k个聚类中心,对应的大小为(Wj,Hj),j=1,2,…,k,其中Wj、Hj分别为中心框的宽和高。
4) 计算每个标签框与中心框的距离:d=1-IOU((xi,yi,wi,hi),(xi,yi,Wj,Hj)),将标签框归为距离最小的那个中心框类。
6) 返回第4)、5)步重新计算,直至(Wj,Hj)变化趋于0。
3 实验及结果分析
3.1 实验平台和数据集
实验环境配置如表1所示。
构建的数据集共有1 300张图像,其中训练集1 000张,验证集300张。图像最小为528×278像素,最大为1 280×720像素,标注工具使用yolo_mark软件。

表1 实验环境配置
3.2 模型的训练
3.2.1 生成锚点框
使用K-means++聚类方法生成锚点框。首先求取不同k值对应生成的锚点框和标签框的平均IOU,该值反映了锚点框与标签框的相似程度。当平均IOU越大时,选取的锚点框越接近标签框,越有利于模型的初始训练。同时,簇数k值越大,模型越复杂,训练中也就越难收敛。这里取k值为1~15,得出k与平均IOU关系曲线,如图3所示。
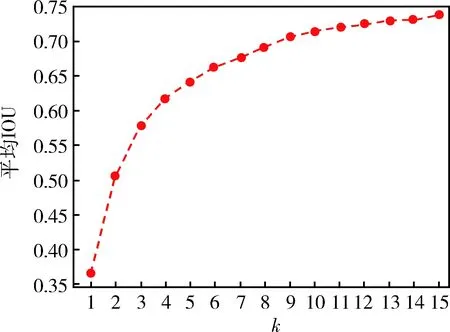
图3 k与平均IOU关系曲线
考虑到模型的训练复杂度和锚点框初始化的效果,这里选取k=9,并进行锚点框的生成,聚类生成图如图4所示。

图4 k=9的聚类生成图
3.2.2 改进模型的训练
采用多尺度训练模式,模型初始输入大小为416×416像素,每4个迭代循环后,从320~608,步长为32的范围中随机选择一个数值作为新的输入,使用darknet53.conv.74作为初始化训练权重参数[12],共迭代5 000次。训练过程主要参数选取如表2所示。

表2 训练过程参数选取表
训练中根据迭代次数动态调整学习率。初始学习率随机指定,当迭代次数>1 000次时,采用指定策略更新学习率。更新策略为:迭代次数在区间(1 000,2 000]时,学习率为0.001;在区间(2 000,3 000]时,学习率为0.000 1;在区间(3 000,5 000]时,学习率为0.000 01。训练收敛曲线如图5所示,平均IOU与训练迭代次数关系曲线如图6所示。

图5 训练收敛曲线

图6 平均IOU与迭代次数关系曲线
3.3 模型评测与分析
3.3.1 模型的评判标准
目标检测领域中,检测模型的评价指标通常包括平均精度mAP(mean Average Precision)、精确率P(precision)、召回率R(recall)和交并比IOU。结合本文的应用场景,具体评价指标计算如下:
当检测目标为单一类别时,平均精度mAP即为AP,其计算公式为
(2)
式中:ci为单张图像中目标检测的准确率;m为图像总数。
P=TP/(TP+FP),
(3)
R=TP/(TP+FN),
(4)
式中:TP为被正确检出的数量;FP为错误检出的数量;FN为漏检的数量。
IOU=A/U,
(5)
式中:A为预测框与标签框重叠的面积;U为预测框与标签框的并集面积。
除此之外,P和R的调和平均数F-Score也是一种评价指标,它综合衡量了精确率P与召回率R,其计算公式为
F-Score=(β2+1)×P×R/(β2×P+R),
(6)
式中:β为调和系数,本文取β=1,即使用F1-Score评价标准。
3.3.2 模型对比分析
使用同样的数据集和训练参数对原YOLOv3模型进行训练,在验证集中进行分析比较,改进后的YOLOv3模型ZQ-YoloNet和原模型性能参数对比如表3所示。

表3 模型性能参数对比 %
由表3可以看出:改进后的ZQ-YoloNet模型平均精度比原YOLOv3模型提高了0.2%,F1-Score指标提升了0.19%,平均IOU提升了2.18%,说明改进后的模型综合性能更好,检测准确率和定位精度更高。当对大小为1 280×720像素的mp4格式的视频进行检测时,帧速率不低于40帧/s,相对于PAL(Phase Alteration Line)制式和NTSC(National Television Standards Committee)标准,可以满足对视频实时检测的要求。
图7、8分别展示了对图像和视频的测试效果。可以看出:原模型在检测目标时标出的矩形框范围过大,即定位不够准确。改进的模型在检测目标时标出的矩形框范围相对合理,即定位较为准确,并且物体的置信度百分比也比原模型有所提高。经过验证,改进的模型对小型无人机航拍图像和视频中汽车的检测具有良好的效果。

图7 模型改进前后图像检测效果对比

图8 模型改进前后视频检测效果对比
4 结论
笔者提出的ZQ-YoloNet模型,在验证集中获得了较好的检测精确率和定位精度,同时通过对数据集之外的小型无人机航拍图片和视频进行验证检测,也得到了良好的检测效果。由于自身条件限制,本文制作的数据集图像分辨率不高,这在一定程度上降低了训练模型的性能。在后续学习中,将在研究深度学习模型结构的同时,制作出高分辨率的图像数据集,以此获得更好的试验效果。
猜你喜欢
——《艺术史导论》评介
美育学刊(2022年5期)2022-10-18
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电子技术与软件工程(2020年22期)2021-01-30
数字技术与应用(2020年12期)2021-01-22
时代邮刊·下半月(2020年9期)2020-09-23
移动通信(2020年5期)2020-06-08
电子制作(2019年11期)2019-07-04
金桥(2018年6期)2018-09-22
小学生优秀作文(低年级)(2018年6期)2018-05-19
