
基于MIC-CNN方法的中文新闻情感分类
2019-11-21 05:37李天赐王浩方宝富
山西大学学报(自然科学版) 2019年4期
李天赐,王浩,方宝富
(合肥工业大学 计算机与信息工程学院,安徽 合肥 230000)
0 引言
随着推荐技术和推荐系统[1]的发展,近年来新闻推荐领域逐渐兴起,而目前的推荐大都是基于新闻的主题类别,尽管已经足够个性化,但是不太“人性化”,因此本文从情感的角度对新闻进行分类,希望能从情感角度来丰富新闻推荐的方式,甚至调节用户的情绪状态。考虑到新闻内容普遍冗长,不利于处理和分析,而从新闻本身的特点可知,新闻标题简短同时又能表达文章的主题,所以本文将以新闻标题作为研究主体并从句子级的中文文本情感分类[2]角度来研究。
目前,国内外文本领域的情感研究方法主要分为基于情感词典、基于机器学习、词典与机器学习相结合、基于弱标记信息以及基于深度学习五大类方法[3]。基于词典的方法核心是词典和规则,它以情感词典作为情感极性的主要判断依据,同时根据不同文本的句法结构设计对应的规则,两者结合得出句子的情感类别。 Pang[4]等人首次提出使用机器学习方法解决篇章级的二元情感分类问题,文中验证了SVM比朴素贝叶斯分类和最大熵模型的分类效果要好。有些研究者尝试将词典与机器学习方法结合,如Miranda等人提出了使用Sentiwordnet和机器学习为Twitter内容中来自印尼语文本的印尼大选意见建立情绪分析模型[5]。所谓基于弱标记信息是指目前互联网中微博表情,评论评分等信息,由于此类信息没有统一标准,因此称之为弱标记信息。Qu等[6]提出使用包含评分信息的评论数据作为弱标注数据训练模型来解决语句的情感分类问题。虽然深度学习起步于图像领域,但在文本情感分类领域也有不俗的应用,Bespalov[7]提出了使用LSA初始化词向量,然后使用加权的n-gram特征进行线性组合进而计算出一篇文章的情感特征向量。Socher等[8-10]提出了一系列的递归神经网络(RNN)模型处理情感分类问题。 Kim[11]使用卷积神经网络(CNN)解决情感分类问题,在多个数据集上验证了CNN比RNN优越。后续Kalchbrenner等[12]在CNN的基础上提出了动态k-max池化和多层CNN相结合的网络模型。Abdullah等[13]提出了一种利用递归神经网络对孟加拉语文本进行情感分类的新方法,使用BiLSTM的深度递归神经网络,精度达到85.67%。Lin等[14]提出了一种基于拼音字符向量,重复“字向量”,应有另一种向量的三通道卷积神经网络应用于中文文本的情感分类,对数据集的实验表明,与基于单词向量特征的简单文本策略相比,具有语音化策略的PCCNN可以更有效地提高模型的分类性能。Du等[15]将循环神经网络与基于卷积的注意力模型相结合,并进一步叠加基于注意力的神经模型,以构建分层情感分类模型。
尽管基于词典的中文情感分类方法在许多场景有很好效果,但是比较依赖情感词库的设计,这其实是一个繁琐困难的过程,而且新闻标题的单词重复率较低,所以词典方法不太适合本文的研究。对于新闻标题来说通常也不含有可利用的弱标记信息,所以相比之下,普通的机器学习方法和深度学习方法具有较高普适性,因此针对中文新闻标题的情感分类任务,本文以卷积神经网络为原型提出多输入通道卷积神经网络(MIC-CNN)来做中文新闻标题的情感分类研究。
本文主要贡献是:(1)提出了以新闻标题为主体的客观文本情感分类问题;(2)提出了优于普通的机器学习方法和传统的卷积神经网络模型的多输入通道卷积神经网络(MIC-CNN)模型以适应(1)中的研究问题;(3)该研究问题的成果对以后做融入情感因素的新闻推荐有一定的铺垫意义。
1 相关工作
1.1 情感分析
文本情感分析[16]又称意见挖掘[17]、倾向性分析,它是对含有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。按处理的文本粒度可分为篇章级、句子级以及短语级。按处理文本的类型可分为基于产品评论的情感分析和基于舆情的情感分析。目前文本领域的情感研究大都集中在微博、博客、电商评论,影评等互联网文本上,有单纯的对某一类文本的情感研究,如:Lou等[18]研究分析中文微博情感,提出一种基于模板的微博情感新词自动发现算法,并采用字典和规则的组合方法对中文微博情绪进行分析;同时也有宽泛的文本情感研究成果,Saleh等[19]在3个不同的网络文本数据集上进行了多组对比实验,测试了选用不同的特征选择方法时的情感分类模型的效果。
1.2 卷积神经网络
自1942年McCulloch[20]提出第一个神经元数学模型——MP模型,神经网络的研究便层出不穷,20世纪50年代末Rosenblatt[21]提出了单层感知器模型,但是它只能处理线性可分问题。1986年,Rumelhart等[22]提出了反向传播网络才解决了线性不可分问题。一段时间的冷冻期后,2006年,Hinton等[23]再次将人工神经网络的研究浪潮掀起,而卷积神经网络[24](CNN)模型便是其中非常重要的一个网络模型,它是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习[25](Deep Learning)的代表算法之一,由于CNN能够进行平移不变分类,因此也被称为“平移不变人工神经网络”。
CNN通常由输入层、卷积层、池化层、全连接层以及输出层几部分构成。另外有些情况还会加入激励层,例如在卷积结果后面加入激励函数Relu(The Rectified Linear Unit),可以使得收敛速度加快并且梯度求解简单。 CNN的优点是它共享卷积核,对高维数据处理压力降低,不需要手动选取特征,这使得它在图像分类、人脸识别、音频检索等领域广泛应用,但同样也有不足之处,如需要调节大量的参数,需要大样本量,训练最好使用GPU,而且CNN是一个“黑箱模型”,通常物理含义很难确切解释,这也是传统的机器学习方法不会过时的原因。尽管CNN的可解释性不强,但它在文本情感分类中仍然应用广泛,除了前面提到的Kim、Kalchbrenner等人的CNN模型实验外,Kim等[26]在2015年再次提出了一种仅依赖于字符级输入的简单神经语言模型,他采用CNN和高速公路网络,但是输出被赋予长期短期记忆(LSTM)递归神经网络语言模型(RNN-LM),实验表明在许多语言中字符输入足以进行语言建模。
2 MIC-CNN模型
针对基于新闻标题的中文短文本情感分类问题,本文基于Kim的CNN模型提出了如图1的多输入通道卷积神经网络(MIC-CNN),该网络主要构成是文本的多输入词嵌入层,多卷积尺寸多卷积核卷积层,加权池化层,全连接层以及softmax分类层,各层的具体描述如下。
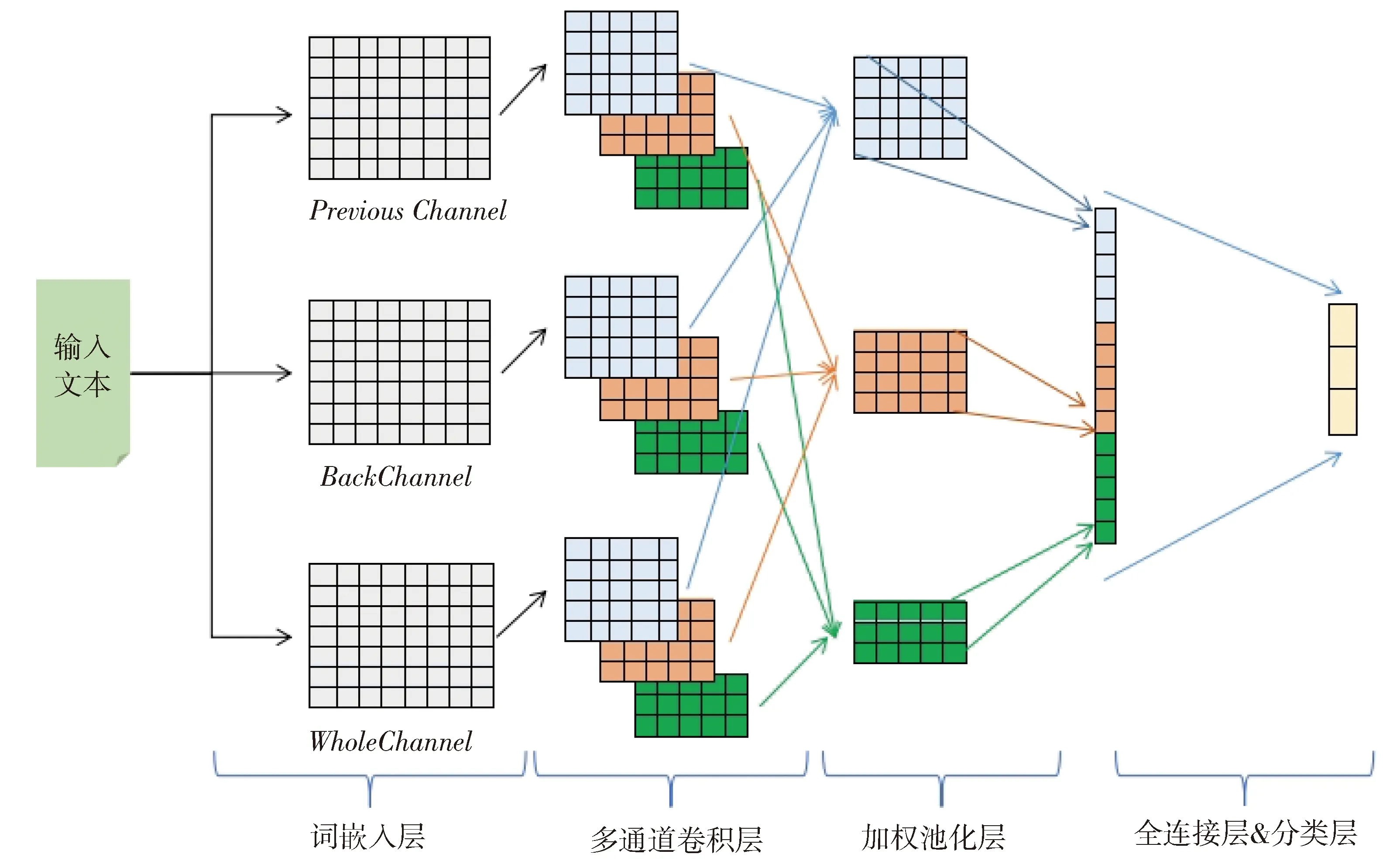
Fig.1 MIC-CNN (multiple input channel convolutional neural network) model图1 MIC-CNN(多输入通道卷积神经网络)模型
2.1 词嵌入层
空间向量模型(VSM)[27]假设特征项之间相互独立,这在传统的文本分类中大都是有效的,但由于新闻标题中单词稀疏问题,所以VSM不适合本文的研究,因此本文使用Word2Vec[28]分布式表示方法表示单词的词向量。经研究分析,大部分新闻标题形式为前后两个半句(Double-Type),其中绝大多数标题两个半句的情感倾向趋于一致(例如:“爱心企业开助学圆梦班五年资助近949名贫困生就业脱困”都传达了积极的情感),而其他的标题情感有的趋于后半句(例如:“外卖小哥街头受伤,湖州师院老师紧急救人小哥脱险”,虽然前半句会让人略感消极,但后半句的补充使这条新闻的报道趋于传达一种正能量,所以属于积极的情感);有的则取决于前半句(例如:“四川什邡一客车发生侧翻致9人受伤原因进一步调查中”,此标题主要集中在前半句的消极情感上)。另外还有一部分标题形式为一个单句(Single-Type)(例如:“关爱自闭症慈善音乐会唱响国家大剧院”,传达了积极的情感)。
鉴于以上特点,我们可以看出不同新闻标题的情感强度在前后两个半句分布是不均匀的,因此本文采用三输入通道的方式来改进普通的CNN以希望能够得到更适合本文的研究结果。三通道分别为:Whole-Channel(WCh),Previous-Channel(PCh)和Back-Channel(BCh)。WCh是指以整个新闻标题的词向量作为第一个输入通道并在尾部用全0的行向量补全到长度L。PCh是指用标题前半句的词向量作为输入并在尾部以全0的行向量补全到长度L,BCh同理。最终每个新闻标题经过中文分词处理并用Word2Vec表示成三个L×M的词嵌入矩阵Ew,Ep,Eb。
2.2 多通道卷积层
对于词嵌入层的三个输入通道,分别采用多卷积尺寸多卷积核对三个词向量矩阵Ew,Ep,Eb进行卷积操作。其中卷积核为l×M的权重矩阵,l是卷积核的宽度,M对应词嵌入矩阵的维度M,假设词向量矩阵为[Es]L×M,卷积核为[K]l×M,卷积尺寸个数为kernel-num,每个卷积尺寸的卷积核个数为kernel-dim,卷积步长为s,前后补零长度分别为pad-pre、pad-back则每一步卷积后的结果如式(1)。
(1)
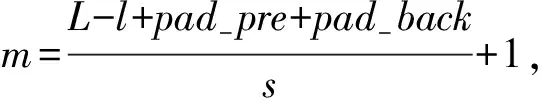
2.3 加权池化层
池化层的目的是减少特征向量的维度。由于本文的网络为多输入通道,因此在卷积后我们对不同输入通道相同卷积尺寸下的卷积结果先进行加权连接,假设以权重Ww,Wp,Wb分别对Ecwi,Ecpi,Ecbi进行加权操作,则加权后得到kernel-num个新的m×kernel-dim维的特征矩阵Eci,每个矩阵向量的元素表示为:
ej,k=[Ecwi]j,k×Ww+[Ecpi]j,k×Wp+[Ecbi]j,k×Wb.
(2)
接下来分别对这kernel-num个特征矩阵进行max池化操作,每个卷积尺寸池化后得到1×kernel-dim的行向量[Epi]1,kernel-dim,然后把每个行向量拼接成最终的情感特征行向量[Ep]1,kernel-dim×kernel-num。
2.4 全连接层和softmax分类
全连接层的每一个结点都与上一层的所有结点相连,用于把前面提取到的特征综合起来,其目的是通过学习全部的权重来整合“优秀”的特征。同时在全连接中加入非线性激活函数ReLU以适应复杂的文本情感分类任务,另外在全连接层加入Dropout算法让每次训练迭代去随机更新网络参数,引入这样的随机性可以增加网络泛化能力以防止训练产生过拟合,但是Dropout只在模型的训练阶段使用。最后经过softmax函数(见公式3)的计算,将特征向量转化为0~1之间的概率值向量,向量的维度为分类类别的个数C。模型训练结束后,再次运行可以达到对测试集文本进行测试,其中每个预测结果即为概率值向量中最大值的索引所对应的文本类别。
(3)
3 实验
在本节中,我们使用上文提出的基于多输入通道的卷积神经网络方法在采集的新闻标题情感数据集上做实验,并且所有实验均基于Intel(R) Core(TM)i7-8700的处理器和英伟达GeForce GTX1060 6GB显卡配置的台式机,同时实验中使用了Anaconda3 和Google的深度学习框架Tensorflow 1.7[29]。
3.1 实验数据和设置
由于本文研究的问题初次提出,在国内目前没有公开的数据集,因此本文所使用的数据是从国内中国新闻网上社会类别爬取的新闻标题,经过手工标注为积极、消极和中性三类别情感数据集,最终语料NewsSents共有4 410篇,其中积极1 297篇,消极1 602篇,中性1 511篇。实验中对数据作如下预处理:(1)爬下来的新闻标题如果为前后两个半句的,采用逗号替中间的空格;(2)使用Jieba分词包对中文标题在精确模式下做分词处理且不做过滤操作。
本文模型涉及到参数有:词汇表大小vocab-size,词向量维度M,输入文本长度L,卷积核尺寸数kernel-num,卷积尺寸大小kernel-sizes,每个卷积尺寸个数kernel-dim,全连接层隐藏单元数hidden-dim,Dropout算法保留比例Dropout-keep-rate,梯度下降优化算法的学习率learning-rate,各通道加权权重[Ww,Wp,Wb]。
实验采用五次交叉验证法[30],每次随机取60%作为训练集,20%作为验证集,剩余20%作为测试集,取平均值作为指标。采用网格搜索的方法对超参数进行调优,使用交叉熵(如公式4)作为神经网络的损失函数,使用Adam Optimizer改善传统梯度下降,促进学习率动态调整。
(4)
本文使用精度(Precision),召回率(Recall)和F1-score三个评价指标衡量最终的分类效果,并将本文MIC-CNN方法与以下方法做比较:
(1)两种朴素贝叶斯模型,多项式模型(MNM)和伯努利模型(BNM);
(2)逻辑回归模型(LR);
(3)支持向量机模型(SVM);
(4)递归神经网络模型(RNN);
(5)长短时记忆神经网络(LSTM);
(6)卷积神经网络模型(CNN)。
3.2 实验结果和分析
根据以往研究者的实验经验,超参数一般取值如表1所示。
经实验对比学习率取0.001较好。由于新闻标题长度较短且单词重复率较小,因此猜测要使情感分类精度高应尽可能保留所有的原始信息,经过实验证明了猜测的正确性。所以本文中取vocab-size为所有文本分词后的单词数,同样的输入文本的长度L也取所有文本中最长的长度。
在上述超参数的设定下其他超参数的调优实验

表1 超参数的一般取值
如表2-7,表中字母缩写含义分别为,Avg=平均值,max=最大值,min=最小值,Range=极差,SDev=标准差,使用这些常用的统计学指标来衡量最优值。
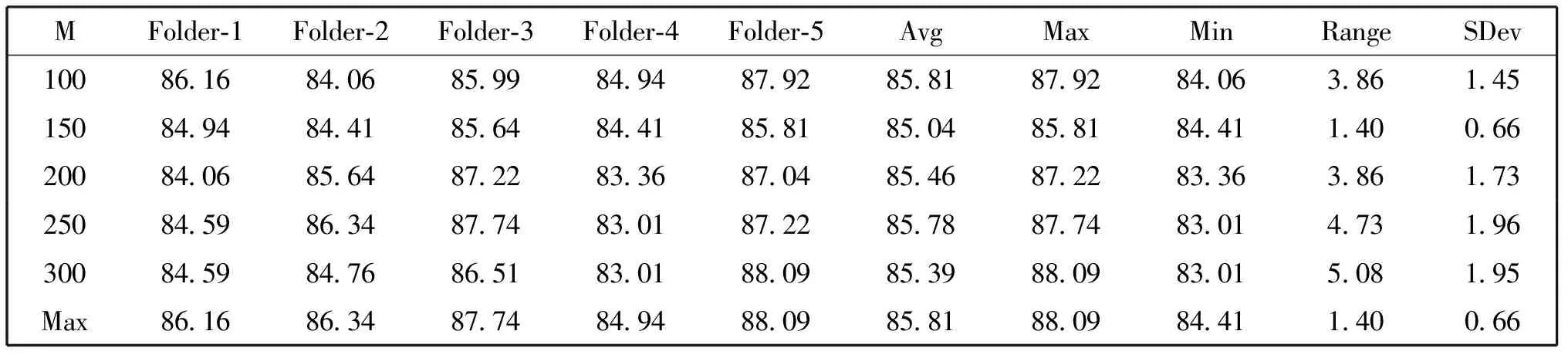
表2 五次交叉验证下的最优词向量维度M调优实验结果(%)
在参数预设kernel-dim=256,kernel-sizes=[3,3,3]时,五次交叉验证下对词嵌入维度M的实验如表2所示,数据分布的折线图如图2所示。

Fig.2 Word embedding dimension experiment result line chart under five cross-validation图2 五次交叉验证下的词嵌入维度实验结果折线图
在参数预设M=100,kernel-sizes=[3,3,3]时,五次交叉验证下最优卷积核个数kernel-dim的实验如表3所示。
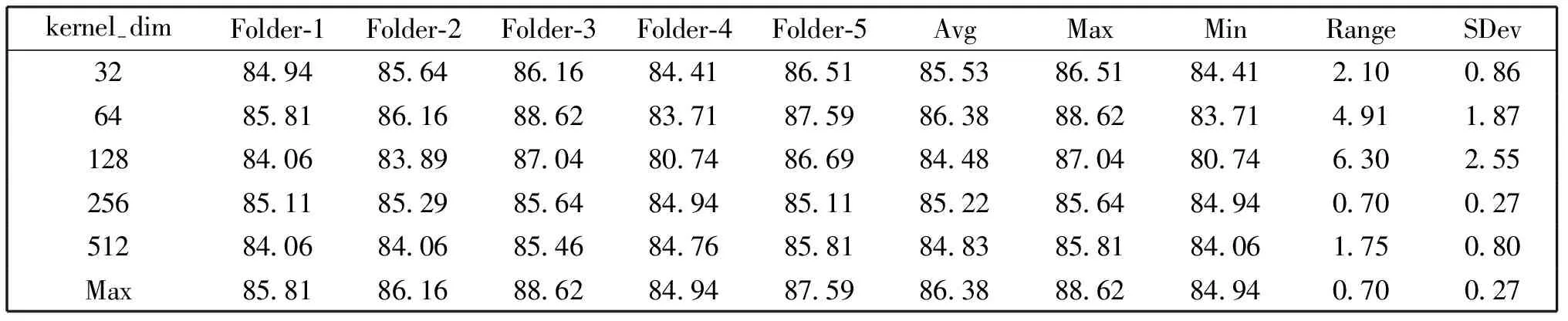
表3 五次交叉验证下的最优卷积核个数调优实验(%)
在参数预设M=100;kernel-dim=256时五次交叉验证下不同的单个卷积尺寸的调优实验如表4所示,不同的多个卷积尺寸组合的实验如表5所示。

表4 不同的单个卷积尺寸下的最优卷积尺寸测试实验(%)

表5 不同的多个卷积尺寸组合下的最优组合测试(%)
经过上述表2-5的参数调优实验结果,可进一步确定可选的超参数为:词嵌入维度{100,150},卷积核个数{64,256},卷积尺寸{[2],[3,5],[2,3,5]},经过网格搜索的方法进行权重调优实验得到最优的参数组合为{kernel-size=[2,3,5];kernel-dim=64;M=150},在此基础上的权重调优实验如表6所示。
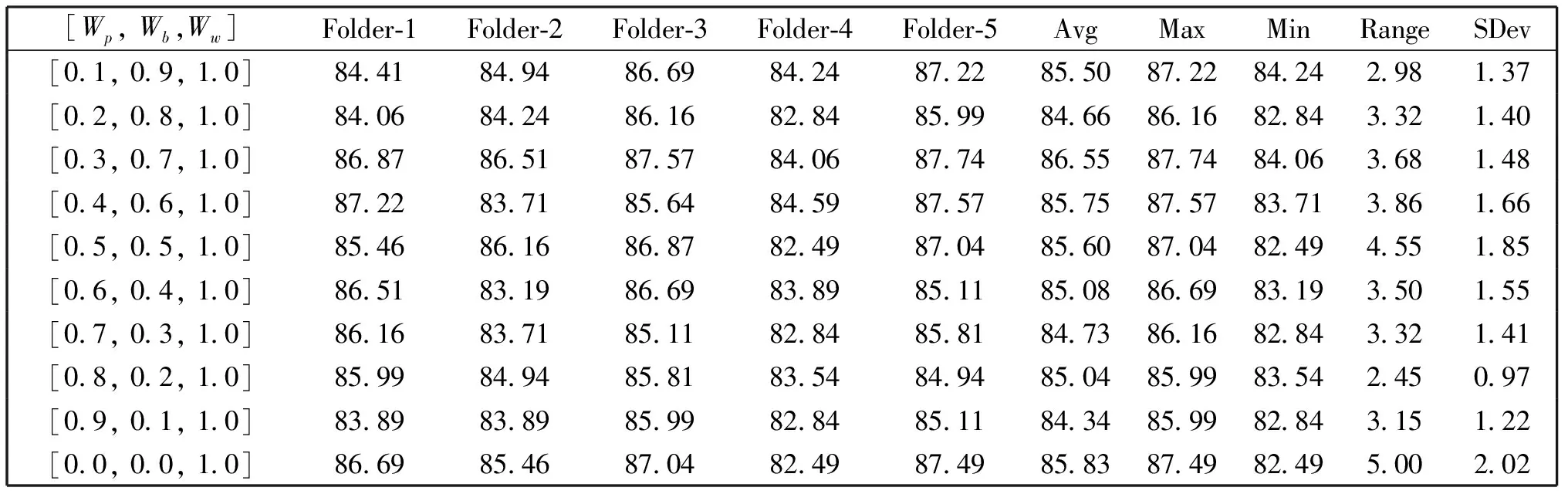
表6 加权池化层的加权权重调优实验(%)
在最优的参数组合条件下,普通的机器学习方法和本文的卷积神经网络方法在NewsSents上的情感分类实验对比结果如表7所示。
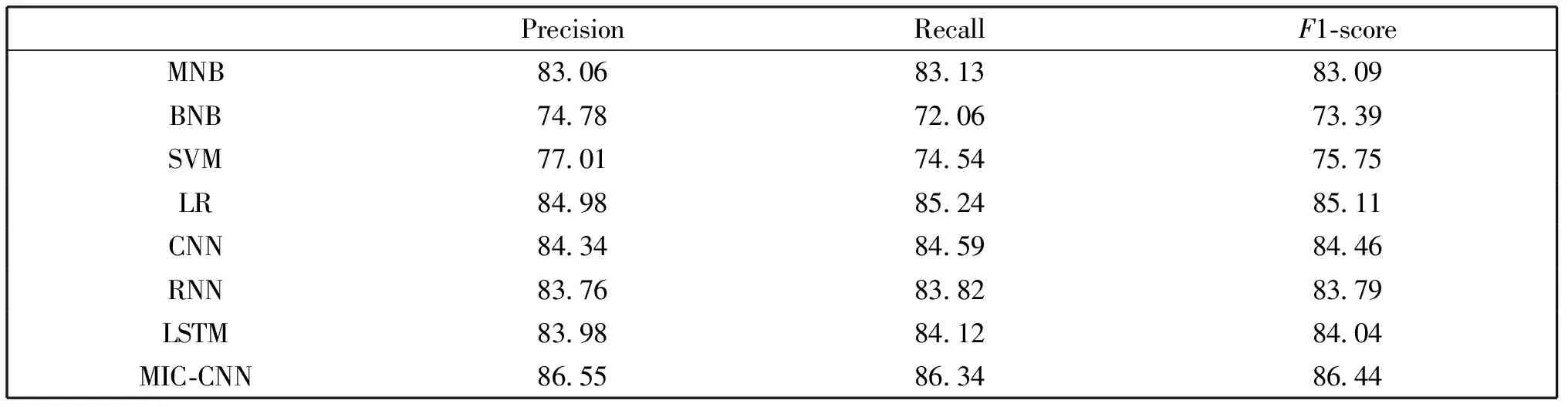
表7 最优参数下本文方法和其他方法的对比实验结果(%)
由图4中训练的精确率和损失变化曲线可以看出本文MIC-CNN模型在训练中能够在1 000次左右的迭代后收敛。从表2-6的超参数调优实验发现,不同的参数对于本文提出的网络模型有较大的影响。为了快速找到最优的参数,本文对五次交叉验证的结果分别取平均值、最大值、最小值、极差和标准差并综合比较,取平均值、最大值和最小值相对较大,极差和标准差相对较小的实验参数。在最优的超参数组合下MIC-CNN精确率在86%以上。同时根据加权权重的调优实验可以发现,不同的加权比例对实验结果也有一定影响,这也验证了本文开始提到的新闻标题的情感因素在前后半句分布不均等的假设,而最终的权重调优实验结果也说明了本文所采用的数据集的新闻标题大部分情感是包含在后半句的。最后表7是本文模型与其他方法的对比实验,可以发现MIC-CNN方法与普通的贝叶斯模型和SVM模型相比有很大的优势,而逻辑回归模型也有84%以上的精确率,分析原因可能是CNN模型的分类层同样采用的是softmax回归,不同之处在于特征的表示和提取方法;相比于RNN、CNN以及LSTM深度神经网络模型,本文的方法综合起来有2%~3%的提高。
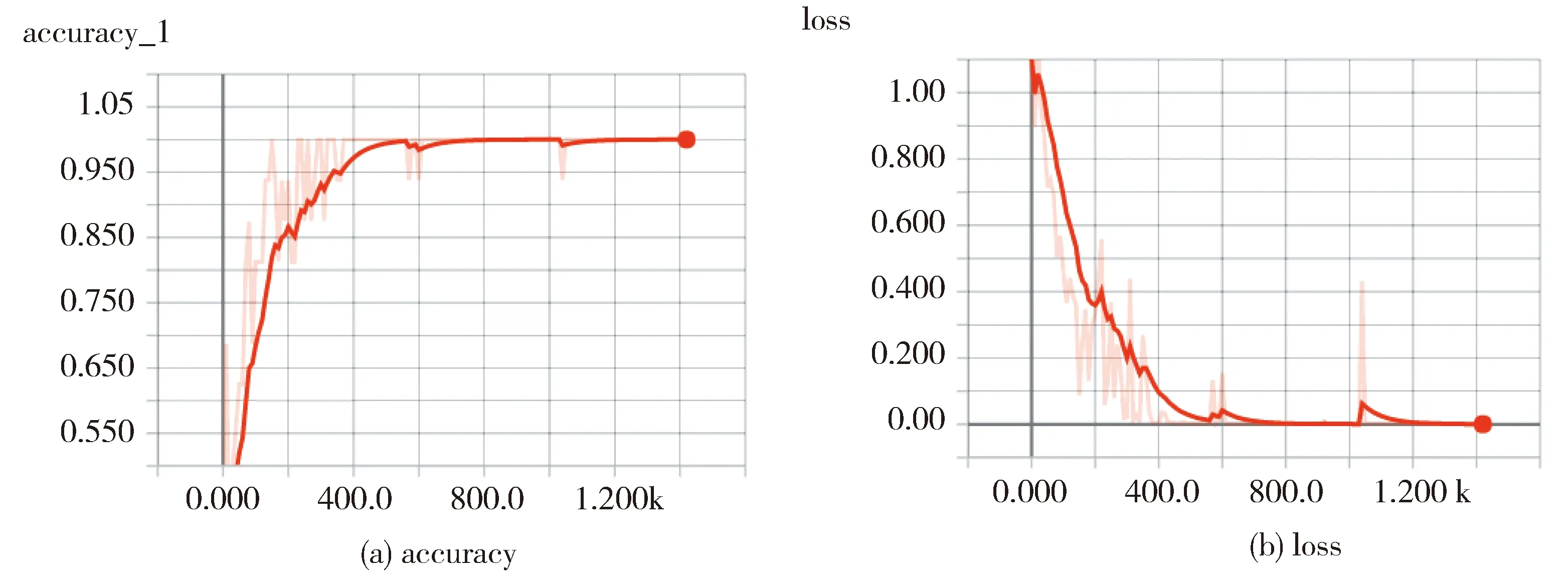
(a) is the accuracy and (b) is the loss.Fig.3 Transformation of accuracy and loss during the training of the model shown in Tensorboard(a)表示精确率,(b)表示损失图3 Tensorboard中显示的模型训练过程中的精确率和损失的变化
4 结论
针对中文新闻情感分类问题,本文以卷积神经网络为原型,在输入层以整句,前半句,后半句作为三个输入通道,然后对每个输入通道经过多卷积尺寸多卷积核卷积后分别以不同权重把各尺寸卷积结果相加,接着每个尺寸使用Max池化并拼接以形成最后的情感特征向量,最后使用softmax进行情感分类,由此构成了本文的MIC-CNN模型,由于公开数据集的欠缺,本文中使用了在中国新闻网上采集的社会类新闻,经过人工标定得到数据集NewsSents,基于此数据集,MIC-CNN方法的分类精确率高于普通的CNN,并且明显优于传统的机器学习方法,实验表明本文所提出的MIC-CNN网络模型对新闻标题的情感分类具有一定的效果。
中文新闻情感分类问题涉及的研究点比较多,本文是以新闻的标题作为研究对象,以神经网络方法为切入点来研究。由于本文的研究缺乏公开的数据集,所以研究的效果和方法未必是最优的,因此未来的研究我们希望从以下两方面考虑:(1)以本文的三类别情感或者更细粒度的情感划分去构造更好中文新闻情感数据集,(2)把基于词典的方法和神经网络的方法相结合看是否会有更好的效果。
致谢感谢合肥工业大学所提供的计算机设备,感谢本人所在实验室众多老师以及师兄弟的支持与帮助。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
北京航空航天大学学报(2018年1期)2018-04-20
喜剧世界(2016年9期)2016-08-24
高中生学习·高三版(2016年9期)2016-05-14
