
基于时间序列的高炉水温差多维度模糊综合评判
2019-11-18 05:44崔桂梅张胜男张勇马祥
中国测试 2019年9期
崔桂梅 张胜男 张勇 马祥

摘要:为克服炉缸局部热状态评判的局限性,全面考虑高炉各冷却壁段水温差对热状态的影响,该文建立基于时间序列的高炉水温差多维度模糊综合评判模型。首先,选取炉身、炉腰、炉腹、炉缸各冷却壁段水温差时间序列,用相关系数法确定上部各段水温差对下部水温差影响的滞后时间,并筛选相关系数大于阈值的参数为主要指标参数;其次,用概率统计法划分指标参数最优区间,计算其相对劣化度值,选择分段岭形分布函数计算各指标参数隶属度值;最后,对各层指标参数自下而上进行模糊合成,结合指标参数权重和最大隶属度原则综合获得最终评判等级。经实际数据仿真分析,模型评判命中率为81.7%,能实时地评判高炉实际水温差状态。
关键词:多维度;时间序列;相关系数法;概率统计分析;相对劣化度;模糊综合评判
中图分类号:TP391 文献标志码:A 文章编号:1674-5124(2019)09-0013-08
收稿日期:2019-01-18;收到修改稿日期:2019-03-27
基金项目:国家自然科学基金(61763039)
作者简介:崔桂梅(1963-),女,河北保定市人,教授,博士,研究方向为复杂过程系统的建模及运行优化控制研究。
0 引言
高炉系统具有非线性、时滞性及强耦合性。冶炼过程实质上是高炉炼铁系统与外界环境之间频繁的物质、能量、信息交换和转化的过程。系统中的能量以焦炭、煤粉等物质为载体进入高炉,经过炉内的复杂反应再以铁水、高炉煤气等物质为载体从高炉输出。图1为某高炉的整体结构图,有效容积为2500m3,炉身下部是软融带的起始位置[1],该区域主要受上升煤气流的冲刷、化学侵蚀和热震剥落;炉腹是软融带的根部,主要靠渣皮工作,长期经历着炉渣、铁水的冲刷和高温煤气流侵蚀[2]。高炉各冷却部位的水温差,从炉底至高炉上部,水温差逐渐增大,从炉腹开始,水温差增大幅度加剧,高炉冷却壁段水温差的跳变可反映炉内炉温的波动性[3]炉内渣皮的稳定性、局部煤气流强度及软熔带的相对位置等。根据高炉冷却强度和冶炼强度的适应性,将高炉立体水温差作为表征高炉立体热状态的重要指标,高炉立体水温差即对空间立体高炉冷却壁段水温多维度分析[4]。高炉水温差的多维度评判为预判炉况奠定基础,从而提高生铁质量和实现节能降耗。
近年来,国内外学者采用一系列智能算法对高炉热状态进行研究。王华秋等[5]通过自反馈RBF神经网络模型预测铁水中硅的含量来预报高炉热状态,但该模型忽略了水温差对高炉热状态的影响。周朝營等[6]用改进的PSO算法训练BP神经网络,建立炉温预测模型,结合炉缸局部水温差判断炉体热状态。宋小鹏等[7]提出用炉缸水温差和流量监测炉体热流判断炉体热状态。针对传统高炉热状态,尚无高炉立体水温差综合评价方面的研究,高炉水温差多维度综合评价模型克服炉缸局部水温差考虑的观念,依据高炉炼铁过程中能量流的传递特性及高炉冷却壁段水温差间的滞后性影响,对前一时刻和当前时刻水温差建立评判模型,采用下一时刻的采样数据验证模型的有效性。由于实际工艺限制,如图1所示,对高炉本体的冷却,选取炉缸(H1、H2)、炉腹(H3)、炉腰(H4)、炉身(H5、H6)等6段冷却壁,每段冷却壁周围等间隔采取48个测量点,图1右侧图为冷却壁测量点横向刨面简图。建模主要过程为:根据相关性分析法提取有效特征[8],选出的指标参数经劣化度分析后进行归一化;利用相关系数法和专家经验对各层指标分配权重;计算覆盖相对劣化度区间的隶属度值;最后通过模糊综合评判模型自下而上对每个子系统的状态进行多属性综合评价。
1 数据预处理
选取该高炉在2018年10月21日至11月21日期间不同工况下的工业现场生产数据585组,评价指标H1、H2、H3、H4、H5、H6当前时刻及历史时刻水温差。
1.1 异常值检测与修补
高炉平稳运行时,采集的过程参数应在小范围内波动,不会出现突跳点[9],3σ原则是根据过程数据的波动情况选取分布在(μ-3σ,μ+3σ)中数值,在此原则下,突跳点数据与平均值的偏差大于3σ。其中,μ和σ分别为样本数据的平均值和标准差。
原始样本集中检测出的异常数据用牛顿插值法修补[10]。对修补后的整体数据,计算48个点的平均水温差得到每段冷却壁的实际水温差。
1.2 相关系数分析法提取关键特征
由于建立模型时采集数据较多,相关分析法是一种采取数学降维的思想,选择相关性大的因素作为评价体系的参数。图2为高炉立体水温差指标参数相关系数矩阵可视化图,横、纵轴均为高炉冷却壁段k-1~k时刻的水温差,图中不同颜色的方块为相关系数的可视化,右侧的条形颜色图代表每个相关系数对应的颜色,相关系数为正时,方块儿颜色趋于红色系,反之,方块儿颜色趋于蓝色系。相关系数的绝对值越大,方块面积越大,反之越小。
相关系数绝对值越接近于1,参数相关度越强,越接近于0,相关度越弱。结合专家经验和图2分析结果,选取|g|≥0.2的因素作为相关因素[11],炉缸保留H1(k-1)、H1(k)、H2(k-1),H2(k);炉腹保留H1(k-1)、H1(k)、H2(k-1)、H2(k)、H3(k-1)、H3(k):炉腰保留H2(k-1)、H2(k)、H3(k-1)、H3(k)、H4(k-1)、H4(k);炉身保留H3(k-1)、H3(k)、H4(k-1)、H4(k)、H5(k-1)、H5(k)、H6(k-1)、H6(k)。
1.3 参数等级区间确定
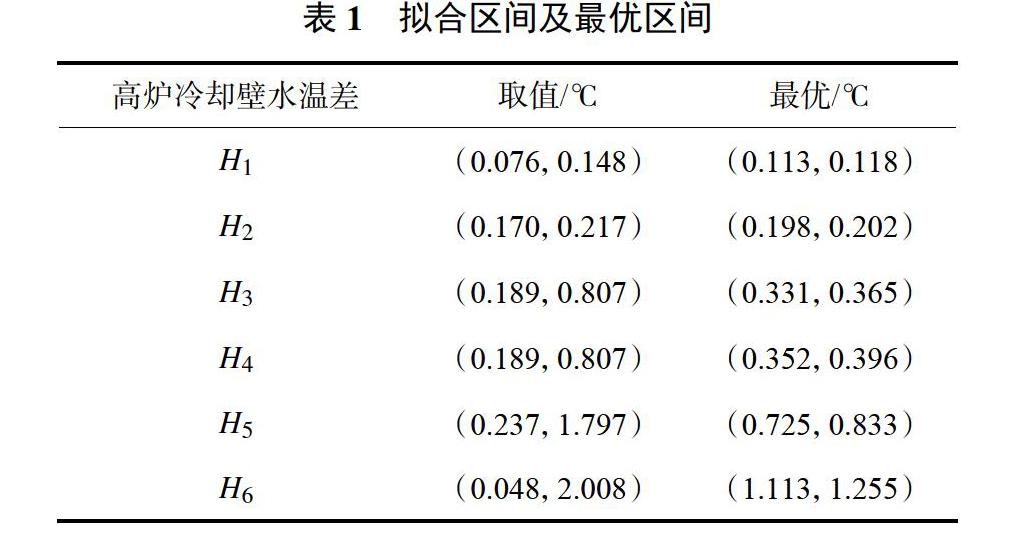
概率统计法:高炉长期运行于稳定状态,各过程参数近似服从以理想工作点为均值的正态分布,通过公式(2)可将非标准正态曲线的横轴区间折合为标准正态分布曲线区间进行计算,由查表法选取正态分布曲线下,横轴(μ±10.19σ)区间内面积为15%的区间为最优区间[12]。图3为H1、H2、H3、H4、H5、H6的概率统计分析图。
z=X-μ/δ(2)其中μ和δ分别为正态分布曲线的均值和方差,X为样本数据,z为标准化后的正态分布数据。
由于评价模型需在炉况稳定的情况下建立,各过程参数应在小范围内波动,根据图中各个区间拟合程度得到各参数取值区间及最优区间如表1所示。
2 高炉水温差多维度模糊综合评判模型
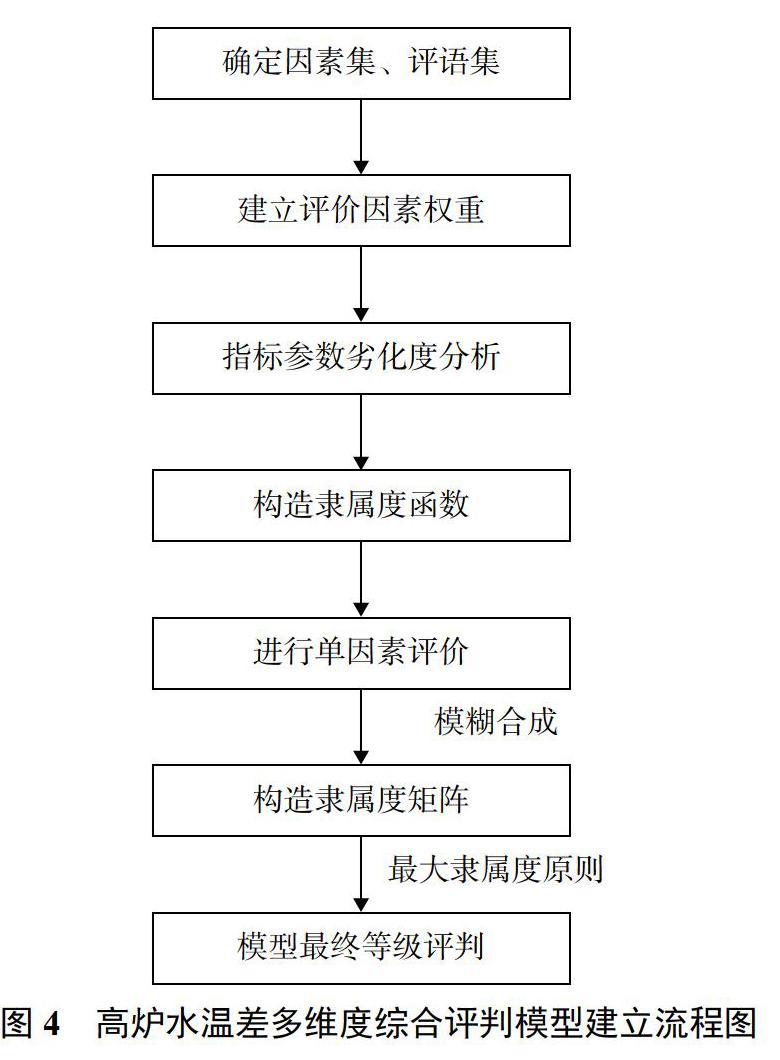
模糊综合评判法是一种基于模糊数学的方法,对受多种因素影响的事件进行综合评判。模糊综合评判能更好地解决具有模糊、难以量化和不确定性对象的状态评估问题,它具有清晰、系统性强的特点,主要涉及4个要素:评语集L、指标体系集X、隶属度矩阵R和模糊权向量W,本文中将高炉冷却壁水温差多维度评价状态分为4个等级[13],记为L=[理想,良好,一般,预警]。根据影响因素的层次性,模糊综合评判体系可分为一级和多级,对高炉立体水温差采用两级模糊综合评判体系[14]。高炉立体水温差多维度综合评判模型建立的流程见图4。
2.1 构建高炉水温差多维度综合评价指标体系
由图2的相关分析结果构建高炉冷却壁水温差多维度综合评价体系,一级指标集为X=[X1,X2,X3,X4],二级指标集分别为:
X1指标参数:H1(1)(k-1)、H1(1)(k)、H2(1)(k-1)、H2(1)(k)。
X2指标参数:H1(2)(k-1)、H1(2)(k)、H2(2)(k-1)、H2(2)(k)、H3(2)(k-1)、H3(2)(k)。
X3指標参数:H2(2)(k-1)、H2(2)(k)、H3(2)(k-1)、H3(2)(k)、H4(2)(k-1)、H4(2)(k)。
X4指标参数:H3(2)(k-1)、H3(2)(k)、H4(2)(k-1)、H4(2)(k)、H5(2)(k-1)、H6(2)(k-1)、H6(2)(k)。
2.2 确定模糊权向量
由于各因素对评价对象作用程度不同,应设法给予不同的权重,确定评价指标体系权重的方法可分为两类:主观赋权和客观赋权。主观赋权主要依据专家经验赋权值,首先聘请有关专家,由每位专家根据总分s对每个考核指标的重要性打分,然后对每个考核指标的分数取平均值,作为最终权重。客观赋权依据数据计算赋权值,如相关系数比值法和熵权法[15]。高炉水温差多维度模糊综合评价体系利用专家经验对一级指标赋权值,设权重矩阵为W,相关系数法对二级指标进行客观赋权,权重矩阵为w。
专家经验对一级指标X赋为:
W=[W1,W2,W3,W4]
式中:aj——第j个指标参数权重;
n——专家总数;
m——指标参数个数;
spj——第p个专家对第j个指标打分。
相关系数比重计算二级指标参数权重为
w=[wi1,wi2,…,wij]
式中:cij——第i个子系统第j个指标的相关系数;
wij——第i个子系统第j个指标的权值;
m——子系统X1、X2、X3、X4参数指标的个数。
2.3 评估指标相对劣化度分析
相对劣化度是指与故障状态下的劣化程度相比,其当前实际状态的劣化程度,对比各指标因素,需对所有数据进行相对劣化度处理消除量纲的影响,相对劣化度的取值范围为[0,1],取值越小表示指标的状态越好,相对劣化度计算方法有2类,即越小越优型和中间型[16]。高炉立体水温差评价体系中,过程参数工作在区间内,故选择中间型函数计算劣化度值。中间型劣化度函数的总体参数需要估计变量的最大值xmax、最小值xmin和最佳范围[xa,xb],最佳取值范围可由概率统计分析法确定,其劣化度函数为
2.4 因子隶属度矩阵计算
隶属度是将评估指标的劣化度转化成评估等级隶属度的重要工具,各指标参数经相对劣化度分析得到归一化后的值,模糊综合评价的关键是合理选取覆盖相对劣化度区间的隶属度函数。將高炉冷却壁水温差多维度评价的4个评价状态记为L=[理想,良好,一般,预警],计算各等级劣化范围内数据的隶属度值,区间内取值偏小的数据,隶属度函数采用降岭形分布,中间取值采用中间型岭形分布函数,区间内取值偏大的数据采用升岭形分布函数,隶属度的交叉重叠率控制在0.2~0.6[17]。根据隶属度随相对劣化度变化的原则,得到各评价等级的隶属度函数为
dij为第i个子系统第j个指标参数的劣化度,rij1、rij2、rij3、rij4为第i个子系统第j个指标参数对4个评价等级的隶属度函数,构建隶属度矩阵
rij=[rij1,rij2,rij3,rij4j
4个评价等级在不同劣化度区间的隶属度函数如图5所示。
2.5 等级评价原则
对评价体系指标参数从下到上逐层进行模糊合成,计算隶属度矩阵向量得到最终评价向量,模糊合成过程为其中,bi表示第i个子系统的评判等级,C是各类指标参数的综合评判矩阵,rji为第i个子系统第j个指标参数的隶属度值。由以上模糊合成过程可计算最终评判向量,根据最大隶属度原则有
bi0=max{bi},1≤i≤4(12)
等级评判原则:
经过多层权值的传递,劣化现象在最终层可能被掩盖,最终评价原则不采用“最大隶属度原则”,针对最终评价向量分情况讨论:
1)当最大隶属度远大于其他等级项的隶属度,且权重最大的等级项隶属度极低(<0.3)时,采用“最大隶属度原则”进行评判。
2)当最大隶属度远大于其他等级项的隶属度,权重最大的等级项隶属度也较高(≥0.3)时,则表明权重最大的等级项为评价对象的状态。
3)当有2个以上的等级项隶属度与最大隶属度差别较小时,需对其权重分析,权重较大的这些等级项采取“取隶属度>0的最低等级项”的原则。
4)当所有的等级项隶属度较相近时,评价原则以权重为主导,取权重最大的等级项。
3 实例分析
选取该高炉10月21日至11月21日期间不同炉况下的现场生产数585组,以其中两组数据为例进行详细分析,对高炉立体水温差进行两级模糊综合评判,验证本文所提模型的有效性,详细分析过程如下:
1)利用相关系数及专家经验确定模糊权向量,由相关系数计算得到二级指标权重:
由专家经验分配一级指标权重:
W=[0.37,0.23,0.21,0.19]
2)根据图2选取的最优区间,采用中间型劣化度函数计算劣化度值如表2所示。
3)根据隶属度函数计算二级指标的隶属度矩阵,设第一组数据隶属度分别为R11、R12、R13、R14,第二组数据隶属度分别为R21、R22、R23、R24,详细结果如下所示。由公式(11)计算一级指标隶属度矩阵
由公式(10)计算最终评价向量:
C1=W1R1=[0.715 0.264 0 0]
C2=W2R2=[0.270 0.043 0.680 0]
综合权重和最终评价矩阵分析:
第一组数据评判结果为理想状态,第二组数据评判结果为一般状态,观察该时刻高炉其他数据如表3所示。
综合表格数据分析:
第一组生产数据:由十字测温法计得到的z/w值位于最优区间内,此时高炉边缘煤气流分布合理,渣皮产生稳定,软化区间和熔滴区间的温度均位于最优区间内,软熔带位置合适,初步判断该时刻炉况稳定。
第二组数据:z/w值减小,边缘煤气流旺盛,渣皮脱落,冷却壁热面温度升高,软化区间和熔滴区间的温度均低于最优区间内取值,软熔带位置偏高,间接还原区缩减,纵观该时刻附近数据,炉温波动造成矿石软熔带根部位置频繁变化,炉况稍有波动。
在实际建模过程中,对选取的585组数据均做了仿真分析,图6为585组数据实际仿真结果,模型的命中率为81.7%(允许误差为0)。该模型命中率高,能实时地评价高炉实际水温差状态。
4 结束语
为克服传统热状态炉缸局部水温差评价,考虑冷却壁段水温差间的滞后性影响,本文提出一种基于时间序列的高炉水温差多维度综合评判模型。首先针对数据预处理后的高炉生产过程数据建立单因素评判矩阵,同时引入相关性分析法计算各指标参数的权重;其次结合单因素隶属度评判矩阵和专家经验确定的模糊权向量进行二级评判;最后依据二级隶属度评判矩阵和评价等级原则确定最终等级。高炉立体水温差可间接反映高炉炉况的稳定性,在此基础上做高炉立体热状态评判,更能准确地预判炉况的稳定性,实验结果表明该研究具有良好的延展性,可指导炉长提前、准确地判断炉况的稳定性,对企业降低成本、节焦降耗及高炉优化运行具有现实意义。
参考文献
[1]杨贵军,蒋朝辉,桂卫华,等.基于熵权-可拓理论的高炉软熔带位置状态模糊综合评判方法[J].自动化学报,2015,41(1):75-83.
[2]马洪斌,张贺顺.首钢2号高炉铜冷却壁使用的体会[J].炼铁,2008,27(5):9-12.
[3]杜國萍.包钢6#高炉冷却系统运行实践[J].包钢科技,2011,37(3):6-8.
[4]余斌,张少伟,刘洋,等.首钢京唐5500m-3高炉冷却壁水温差无线监测系统[J].山东冶金,2018,40(1):60-62.
[5]王华秋,廖晓峰,邹航,等.自反馈RBF网络在高炉热状态模型预测中的应用[J].系统工程与电子技术,2008(5):929-934.
[6]周朝萱.基于粒子群的BP神经网络在高炉炉热状态预报中的应用[A].Intelligent Information Technology ApplicationAssociation.Agricultural and Natural ResourcesEngineering(ANRE 2011 ABE V3)[C].Intelligent InformationTechnology Application Association:智能信息技术应用学会,2011.
[7]宋小鹏.高炉炉体热状态在线监测系统[A].中国金属学会.2012年全国炼铁生产技术会议暨炼铁学术年会文集(下)[C].中国金属学会:中国金属学会,2012.
[8]崔桂梅,李静,张勇,等.高炉铁水温度的多元时间序列建模和预测[J].钢铁研究学报,2014,26(4):33-37.
[9]张良均,杨坦,肖钢,等.数据分析与挖掘实战[M].北京:机械工业出版社,2016:47-53.
[10]吴礼斌,李柏年,张孔生,等.MATLAB数据分析方法[M].北京:机械工业出版社,2017:39-57.
[11]周英,旧金武,卞月青.大数据挖掘系统方法与实例分析[M].北京:机械工业出版社,2016:106-107.
[12]杨立才,张朋飞,王德伟.基于主成分分析的代谢综合征模糊综合评价方法[J].生物医学工程学杂志,2013,30(1):67-70,79.
[13]陈龙,李涛,徐啸峰.基于概率密度函数的时滞依赖故障检测与诊断[J].计算机工程与应用,2018,54(6):257-263.
[14]代雪静,田卫.水质模糊评价模型中赋权方法的选择[J].中国科学院研究生院学报,2011,28(2):169-176.
[15]李晨曦,孙哲,蒋景英,等.近红外光谱主成分分析与模糊聚类的典型地面目标物识别[J].光谱学与光谱分析,2017,37(11):3386-3390.
[16]黄必清,何焱,王婷艳.基于模糊综合评价的海上直驱风电机组运行状态评估[J].清华大学学报(自然科学版),2015,55(5):543-549.
[17]徐铭铭,曹文思,姚森,等.基于模糊层次分析法的配电网重复多发性停电风险评估[J].电力自动化设备2018,38(10):19-25,31.
(编辑:商丹丹)
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
中国计算机报(2020年9期)2020-03-25
福建基础教育研究(2019年2期)2019-09-10
福建基础教育研究(2019年2期)2019-05-28
筑路机械与施工机械化(2016年12期)2017-01-13
科学与财富(2016年29期)2016-12-27
中国市场(2016年41期)2016-11-28
商(2016年32期)2016-11-24
软件工程(2016年8期)2016-10-25
现代经济信息(2016年12期)2016-07-11
