
基于正则表达式的海量数据清洗系统
2019-11-15 04:49常征吕勇
计算机应用 2019年10期
常征 吕勇


摘 要:针对目前主流的数据提取、变形、加载(ETL)工具和受限环境下一些应用的不足之处,结合受限应用场景下的特殊要求,提出一种基于正则表达式的海量数据清洗系统(REMCS)。REMCS首先针对超长错误数据问题、批量数据源文件融合问题、数据源文件自动分拣问题等典型的6个问题找到数据的特点,其次根据数据的特点设置合适的正则表达式和预处理算法,然后使用算法模型去除数据中的错误完成数据预处理工作。同时详细阐述了REMCS的系统逻辑结构、常见问题、对应的解决算法和代码实现方案。最后通过对兼容的数据源文件格式、能够处理的问题种类、问题处理时间、处理数据极限值等4个方面进行对比,从几组常见的数据处理问题的对比实验可知,相较于传统的ETL工具,REMCS支持csv格式、json格式、dump格式等典型的9种文件格式,能够处理全部的6种常见问题,处理时间更短,能够支持的数据极限值更大。实验结果验证了针对受限应用场景下常见的数据处理问题,REMCS具有很好的适用性和准确性。
关键词: 正则表达式;数据清洗;大数据;提取、变形、加载工具
中图分类号:TP391
文献标志码:A
Abstract:Based on the current mainstream Extract Transform Load (ETL) tools for data and the disadvantages of some applications in restricted environments, a Regular Expression Mass-data Cleaning System (REMCS) was proposed for the specific requirements in the restricted application scenarios. Firstly, the data features of six typical problems including ultra-long error data, batch fusion of data source files, automatic sorting of data source files, were discovered. And the appropriate regular expressions and pre-processing algorithms were put forward according to the data features. Then, data pre-processing was completed by using the algorithm model to remove the errors in data. At the same time, the system logical structure, common problems, and corresponding solutions, and code implementation scheme of REMCS were described in detail. Finally, the comparison experiments of several common data processing problems were carried out with the following four aspects: the compatible data source file formats, the soveble problem types, the problem processing time and the data processing limit value. Compared with the traditional ETL tools, REMCS can support nine typical file formats such ascsv format, json format, dump format, and can address all six common problems with shorter processing time and larger supportable data limit value. Experimental results show that REMCS has better applicability and high accuracy for common data processing problems in restricted application scenarios.Key words: regular expression; data cleaning; mass data; Extract Transform Load (ETL) tool
0 引言
筆者参与某集团公司的“核心电子器件在电子信息装备中的验证与应用”课题,本课题组通过构建的联试验证环境掌握了大量的实验数据的原始文件,亟须一种自主可控可靠的数据处理技术方法。
截止2017年10月底,该集团公司联试验证环境掌握的实验数据原始文件总大小为21.1TB,实验数据原始文件总数目为4970405。因为数据涉及商业秘密,该集团公司联试验证环境要求所有工作及工具必须经过严格审查。本项目团队面临的具体业务问题就是把如此海量的数据在有限的工具和环境下进行清洗、导入、迁移和发布[1]。
目前国内外针对海量数据的预处理过程已经有很多成熟的数据预处理——提取、变形、加载(Extract Transform Load, ETL)工具,包括Kettle、Spark stream、Navicat等[2]。关于不同应用场景下的ETL的学术研究也有很多,比较新的研究有基于MySQL环境下处理大数据量的轻量级SETL系统[3],也有针对Hadoop环境下的视频流数据的ETL工具的研究[4],还有面向银行支付清算业务的大数据分析平台的ETL流程设计的研究[5]。
本项目团队在数据处理过程中遇到了许多问题:总量成千上万,来源多种多样,格式千奇百怪,质量参差不齐,内容范围广泛。
而上面提及的主流工具和研究在面对海量实验数据处理时暴露出一些不足,例如处理数据灵活性不够,处理数据格式不够多样,针对数据处理过程中出现的问题没给出定位信息等。
而且因为数据敏感性较高,该集团公司联试验证环境要求尽可能在现有基础工具环境下进行处理,对于其他各种成熟工具都需要另外进行审批和检查。所以这就要求本项目团队必须在现有环境下进行数据处理方法上的创新,研发一些自动化工具模型来解决本项目团队处理实验数据时候面临的一些问题。
针对本项目中发现的问题,通过这一年来的积累,本项目团队逐渐累积下来一些常用的模型工具,整合得到基于正则表达式的海量数据清洗系统(Regular Expression Mass-data Cleaning System, REMCS)。
1 问题的提出
该集团公司联试验证环境要求尽可能在现有基础工具环境下进行处理,对于其他各种成熟工具都需要另外进行审批和检查。本项目团队加入之前,该集团公司联试验证环境的处理方式是通过人工查找。这种人力方法既费时费力,又只能处理少量的小文件,对于大量的数据文件或者单个大文件都无能为力。
在实验数据处理过程中本项目团队发现一些常见的典型问题:
1)数据源文件中出现过长数据内容问题;
2)大量单一表结构数据文件处理问题[6];
3)大量多表数据源文件混杂问题;
4)结构化数据重排列问题;
5)数据内容代码翻译问题[7];
6)数据内出现错行问题[8-9]。
接下来,本文就针对以上这6个典型问题给出基于正则表达式的海量数据清洗系统(REMCS)的处理方式。
2 方法
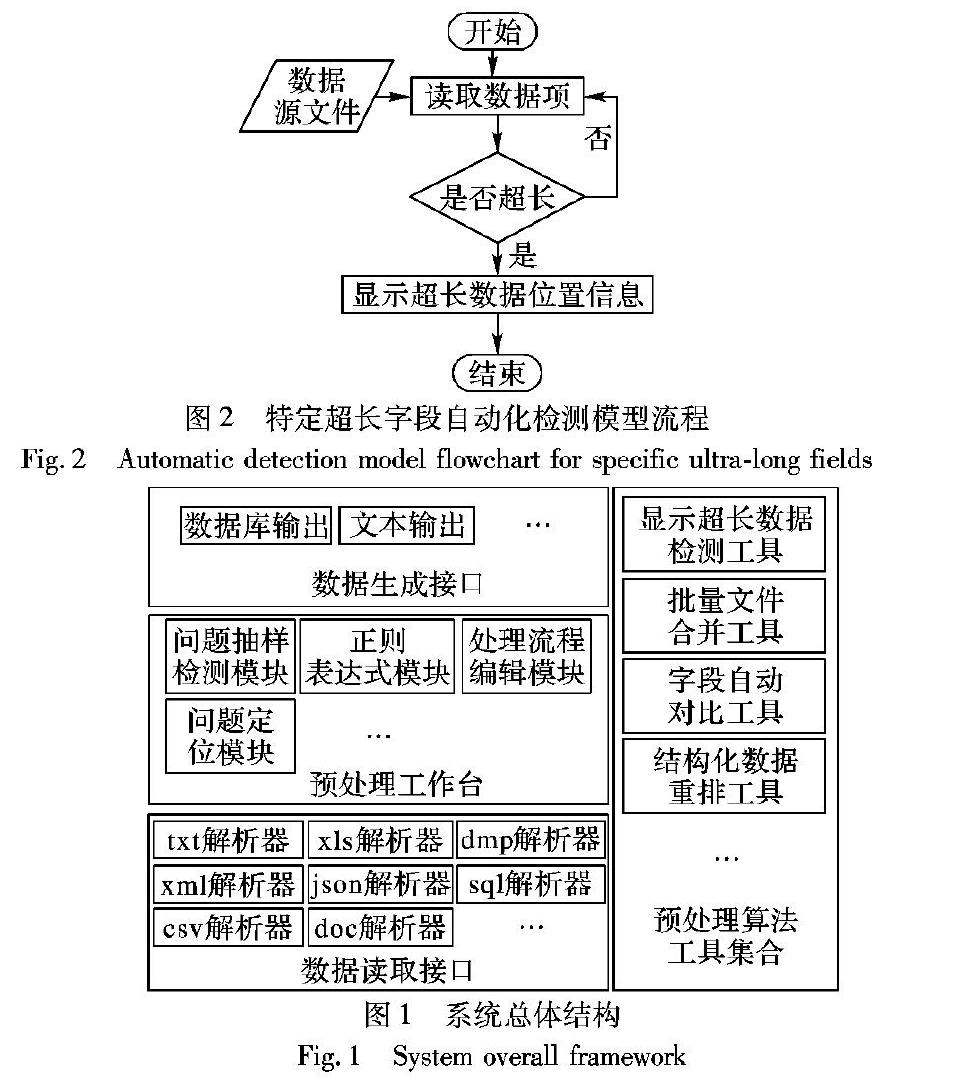
本文提出的基于正则表达式的海量数据清洗系统的总体结构如图1所示。
该结构参考了最新的ETL研究。
例如:基于Kafka和Disruptor技术的优化ETL工具[10],面向数据仓库的ETL工具的研究与实现[11],支持探索式研判分析的动态ETL流程服务研究[12],以及基于Kettle软件对气象数据ETL流程的政务云气象数据仓库研究[13],还有高性能正则表达式匹配算法研究[14]和正则表达式匹配算法研究[15]。这些最新的研究为本文提供了很好的研究思路,也为本项目团队后续的工作提供了参考。
与目前主流的三种典型ETL工具(包括Kettle、Spark stream、Navicat)相比,本文提出的REMCS的不同点主要体现在:
1)工具集合。REMCS针对常见的预处理典型问题预制了对应的模型工具,通过对比实验可以证明处理兼容性和时间效率上都更好。
2)输入输出接口。REMCS针对常见的数据源文件格式都提供了读取解析工具和输出工具,对于数据源文件格式和输出文件格式的兼容性更好。
3)预处理工作台。REMCS针对数据源文件中的常见错误都能自动纠正或者给出错误位置信息,便于后续纠正。
接下来本文将针对第1章提出的6个典型问题,重点阐述一下系统的工作原理。
本文会根据不同的问题给出不同的算法实现流程,以下算法模型都是使用Python脚本完成,运行调试环境都是sublime text3和Python2.7编译器。本文针对实际数据处理过程中遇到的不同数据格式文件出现同一常见问题,提供了多种实现模型。
2.1 特定超长字段自动化检测模型本模型主要针对数据原文件中出现超长问题字段的自动化检测问题,这种问题大量存在于excel格式数据、csv格式数据、文本格式数据等。
本文设计了特定字段超长自动化检测模型,并且提供了不同格式数据文件的处理功能。流程如图2所示。
图2 特定超长字段自动化检测模型流程因为这个问题广泛存在于多种数据格式的文件中,所以REMCS提供了多种数据文件的支持,包括:文本文件处理模型、excel文件处理模型、dmp文件处理模型。因为原始数据比较敏感而且数量很大,本文均以样例数据代替。
这里以文本文件处理模型为例。样例数据如下所示:
REMCS通过遍历所有的数据,分析得到每一个数据项,然后比较数据项的长度,得到超过最大限制值的数据项内容,给出对应的位置信息和数据内容。
数据处理人员就可以根据位置信息和数据内容来排除数据错误,使得数据能够成功导入。
2.2 批量文件合并自动化模型
本模型主要针对大量单一表结构数据文件的批量自动化处理问题。多个数据源文件中字段都是一样的,该集团公司联试验证环境现在提供的数据导入工具每次只能对于单一数据文件进行导入操作,所以对于大量的小数据文件就需要通过人力不停地进行导入配置,既费力费时又效率不高。
批量文件合并自动化模型的流程如图3所示。
REMCS处理这种问题的思路是通过Python脚本来遍历指定文件夹下所有原始数据文件的数据,把所有数据合并到一个数据文件中。
数据处理人员可以直接处理合并之后的数据源文件。
2.3 字段名称批量对比模型
本模型主要针对大量多表数据源文件混杂问题。根据不同的表头信息,大量数据源文件可以分为若干类,这样对于每一类数据源文件就可以归结到上面第二个问题了。
这种问题大量存在于excel格式数据、csv格式数据、文本格式数据等。
本文设计了字段名称批量对比模型,并且提供了不同格式数据文件的处理功能。
流程如圖4所示。
这里以多个csv文件挑选为例。样例数据如下所示。
REMCS处理这种问题的思路是通过Python脚本来遍历所有的数据源文件,分析得到每一个数据源文件的表头信息,然后对比表头信息,将数据源文件分到不同的文件夹中。数据处理人员可以在不同的文件夹中运行2.2节中的模型。
2.4 结构化数据重排模型
本模型主要针对结构化数据重排列问题。实验数据中的人力资源数据的预处理过程需要从文本格式文件中将人力资源信息进行重新排列,使其能够符合自动化导入工具要求的应用场景,并且将对应导出的人员图像根据其员工号码进行重命名。这种问题大量存在于txt格式数据、sql格式数据、 json格式数据等。本文设计了结构化数据重排列模型,并且提供了不同格式数据文件的处理功能。
REMCS通过Python脚本来遍历所有的数据,借助正则表达式分析得到每一个数据项,然后根据数据自动导入工具对格式的要求对分析得到的数据项进行重新排列。数据处理人员可以使用重新排列之后的数据文件进行导入操作。
2.5 文本数据代码批量翻译模型
本模型主要针对数据内容代码翻译问题。当数据来源文件为文本文件,并且数据来源方提供了对应的数据字典,需要根据数据来源方提供的数据字典对数据源文件内部数据进行代码翻译。
文本数据代码批量翻译模型的流程如图6所示。
REMCS处理这种问题的思路是通过Python脚本来遍历指定文件夹下所有原始数据文件的数据,并结合数据来源提供的数据字典,对数据内容进行翻译。数据处理人员可以直接导入翻译之后的数据源文件。
2.6 错行数据自动清洗模型
本模型主要针对数据内出现错行问题。某些文本格式数据原始文件中数据内部因为出现回车符,导致同一字段内部数据出现跨行,该集团公司联试验证环境提供指定数据导入工具针对错行数据导入出现错误。
REMCS处理这种问题的思路是通过Python脚本来遍历指定文件夹下所有原始数据文件的数据,模型可以通过正则表达式找到出错的数据行,并将跨行的数据记录进行纠正。数据处理人员可以直接导入处理之后的数据源文件。
3 实验与分析
为了验证本文提出的REMCS在功能和性能上的优势,从几个不同的角度进行实验对比。本实验使用简化过的测试数据,数据错误出现概率符合正态分布抽样,以便于对算法模型进行检验。实际数据体量应该需要放大成千上万倍,实际生产环境下的工作结果说明了上述算法模型在实际的海量数据环境下依然能够正常高效工作。
3.1 不同ETL工具问题适用文件对比
这里本文使用3种常见的通用ETL工具(包括Kettle、Spark stream、Navicat)和本文提出的系统对常见的数据文件格式进行实验处理对比,包括txt文件、sql文件、csv文件、dmp文件、 json文件、bson文件、xml文件、xls/xlsx文件、doc/docx文件等,以便验证本文提出的REMCS数据预处理系统对以上常见数据的兼容性。
和本文提出的系统对第2章中提出的6种常见典型问题进行实验对比,包括:特定超长字段自动化检测问题(简称问题1)、批量文件自动化合并问题(简称问题2)、字段名称批量对比问题(简称问题3)、结构化数据重排问题(简称问题4)、本文数据代码批量翻译问题(简称问题5)、错行数据自动化清洗问题(简称问题6),以便验证本文提出的数据预处理系统对以上6种典型问题的处理效果。
从表2可知,本文提出的REMCS对于6种常见的典型问题都具有很好的处理能力,而其他的3种常见通用工具都有或多或少的局限,不能很好地处理全部6种常见的典型问题。
3.3 处理时间对比
本实验使用3种常见的通用ETL工具和本文提出的系统对于给定3组数据集合进行处理,对比各种工具的处理时间。本文按照样本数量从UCI公共数据集合中选择了3组数据集合进行对比实验,如表3所示,
包括:
大样本量的数据集合Census Income(下文称集合1)、
中等样本数量的数据集合Wine Quality(下文称集合2)和
小样本量的数据集合Student Performance(下文称集合3),
并对这些标准化数据插入错误数据。错误数据种类会根据3组数据集合进行选择,错误数据的插入位置随机选择。
从图8的结果可知,本文提出的RENCS能够兼容3类数据集合的同时,还具有相对较短的处理时间。
相比较于其他的3种工具,本文提出的REMCS系统对于全部3组数据中的错误都进行了自动处理或者给出错误定位;而Navicat虽然在数据集合2上耗时接近REMCS,但是在数据集合1上因为无法处理的错误数据而意外终止;Kettle在数据集合2上也因为无法处理的错误导致意外终止,从而缺少结果数据。
在数据集合1中,REMCS、Kettle和Spark stream检测出全部的200处错误,Navicat意外终止是因为无法处理连续出现的数据内出现错行问题,当错行问题数量超过600行以上时会出现工具意外终止的现象。在数据集合2中,REMCS、Spark stream和Navicat检测出全部的50处错误,Kettle意外终止是因为出现无法处理数据源中数据过长的问题,当数据长度超过1000B以上时会出现工具意外终止现象。在数据集合3中,REMCS、Kettle、Spark stream和Navicat均检测出全部的10处错误。
3.4 处理极限值对比
为了验证本文提出的REMCS的处理极限值,这里本文跟其他的3种常见通用预处理工具进行了对比实验。
为了避免测试数据的数据量对实验结果的干扰,本文在不同大小的三种数据集合上都进行了多次实验,并统计了各种算法的處理时间。
本文按照样本数量从UCI公共数据集合中选择了3组分类问题数据集合进行对比实验,如表4所示,包括:SIFT10M(大总量,多字段,下文称集合4)、HEPMASS(大总量,较少字段,下文称集合5)和Record Linkage Comparison Patterns(较少总量,较少字段,下文称集合6),并对这些标准化数据随机插入错误数据,插入的错误数据是4种工具都可以处理的简单错误。
本文提出的REMCS对比其他工具在处理大数据量的数据时候也能满足时间和功能性的要求,对于全部的三种大小的数据集合都能在可接受的时间内处理完毕,并自动处理其中的错误或给出定位信息,便于用户进行手动调整。
4 结语
本项目团队针对处理大量实验数据过程中遇见的常见典型问题总结出REMCS。REMCS的应用场景为高度受限的敏感数据中心环境,该环境要求尽可能在现有基础工具环境下进行敏感数据的处理,对于其他各种成熟工具都需要进行繁琐的审批和检查。REMCS提升了本项目团队处理实验数据的效率,减轻了数据预处理工作的工作量和工作压力。本文通过多个对比实验从不同方面说明了所提REMCS在受限环境下的优良特性。
致谢 非常感谢“核心电子器件在电子信息装备中的验证与应用课题”对本项目的大力支持。
参考文献(References)
[1] KARAGIANNIS A, VASSILIADIS P, SIMITSIS A. Scheduling strategies for efficient ETL execution[J]. Information Systems, 2013, 38(6): 927-945.
[2] WILKINSON K, SIMITSIS A, CASTELLANOS M, et al. Leveraging business process models for ETL design[C]// Proceedings of the 2010 International Conference on Conceptual Modeling, LNCS 6412. Berlin: Springer, 2010: 15-30.
[3] 冯运辉. 一种基于MySQL的可扩展ETL系统的研究与实现[J]. 电子技术与软件工程, 2018(5): 185-187. (FENG Y H. Research and implementation of an extensible ETL system based on MySQL[J]. Electronic Technology and Software Engineering, 2018(5): 185-187.)
[4] 张敬锋, 刘琼, 李磊. Hadoop与ETL技术在视频数据中的应用[J]. 警察技术, 2018, 170(5): 29-31. (ZHANG J F, LIU Q, LI L. Application of Hadoop and ETL in video data[J]. Police Technology, 2018, 170(5): 29-31.)
[5] 谢亚龙. 支付清算业务大数据分析平台ETL流程设计与实践[J]. 金融科技时代, 2018, 276(8): 62-64. (XIE Y L. Design and practice of ETL process for large data analysis platform of payment and settlement business[J]. Financial Technology Time, 2018, 276(8): 62-64.)
[6] EL AKKAOUI Z, ZIMNYI E, MAZN J, et al. A model-driven framework for ETL process development[C]// Proceedings of the 14th ACM International Workshop on Data Warehousing and OLAP. New York: ACM, 2011: 45-52.
[7] SIMITSIS A, VASSILIADIS P, DAYAl U, et al. Benchmarking ETL workflows[C]// Proceedings of the 2009 Technology Conference on Performance Evaluation and Benchmarking, LNCS 5895. Berlin: Springer, 2009: 199-220.
[8] 徐安令. 正則表达式的应用研究[J]. 数字技术与应用, 2016(5): 68-68. (XU A L. Research on regular expression application[J]. Digital Technology and Application, 2016(5): 68-68.)
[9] 陈增鑫, 欧阳林艳, 龚思思, 等. 正则表达式在数据抓取中的应用研究 [J]. 佳木斯职业学院学报, 2017(4): 408-408. (CHEN Z X, OUYANG L Y, GONG S S, et al. Research on the application of regular expression in data grabbing[J]. Journal of Jiamjusi Vocational Institute, 2017(4): 408-408.)
[10] 王梓, 梁正和, 吴莹莹. 基于Kafka、Disruptor技术对传统ETL的改进[J]. 计算机技术与发展, 2018, 28(11): 26-29. (WANG Z, LIANG Z H, WU Y Y. Improvement of traditional ETL based on Kafka and Disruptor technology[J]. Computer Technology and Development, 2018, 28(11): 26-29.)
[11] 林昆. 面向数据仓库的ETL工具的研究与实现[J]. 计算技术与自动化, 2018, 37(1): 136-140. (LIN K. Research and implementation of ETL tool oriented data warehouse[J]. Computing Technology and Automation, 2018, 37(1): 136-140.)
[12] 张硕, 赵卓峰, 王桂玲, 等. 支持探索式研判分析的动态ETL流程服务[J]. 小型微型计算机系统, 2019, 40(1): 176-180. (ZHANG S, ZHAO Z F, WANG G L, et al. Dynamic ETL process service to exploratory judgment analysis[J]. Journal of Chinese Computer Systems, 2019, 40(1): 176-180.)
[13] 许皓皓, 廉亮, 姚浩立. 基于ETL的政务云气象数据仓库构建[J]. 计算机系统应用, 2018,27(9): 224-228. (XU H H, LIAN L, YAO H L. Establishment of meteorological data warehouse based on ETL tools[J]. Computer Systems & Applications, 2018,27(9): 224-228.)
[14] 付哲, 李军. 高性能正则表达式匹配算法综述[J]. 计算机工程与应用, 2018, 54(20): 6-18. (FU Z, LI J. Survey on high performance regular expression matching algorithms[J]. Computer Engineering and Applications, 2018, 54(20): 6-18.)
[15] 邵翔宇, 刘勤让, 孙淼. 基于模板有限自動机的正则表达式匹配算法[J]. 计算机应用研究, 2016, 33(7): 2139-2142, 2147. (SHAO X Y, LIU Q R, SUN M. Regular expressions matching algorithm based on templates finite automata[J]. Application Research of Computers, 2016, 33(7): 2139-2142, 2147.)
猜你喜欢
智慧少年·故事叮当(2020年10期)2020-11-06
作文周刊·小学二年级版(2018年29期)2018-11-26
数学大王·中高年级(2016年12期)2016-12-26
企业技术开发·下旬刊(2016年9期)2016-11-23
中学生物学(2016年10期)2016-11-19
文艺生活·中旬刊(2016年9期)2016-11-07
科技视界(2016年22期)2016-10-18
科技视界(2016年20期)2016-09-29
小哥白尼·趣味科学画报(2006年16期)2006-05-29
