
基于知识蒸馏的超分辨率卷积神经网络压缩方法
2019-11-15 04:49高钦泉赵岩李根童同
计算机应用 2019年10期
高钦泉 赵岩 李根 童同
摘 要:针对目前用于超分辨率图像重建的深度学习网络模型结构深且计算复杂度高,以及存储网络模型所需空间大,进而导致其无法在资源受限的设备上有效运行的问题,提出一种基于知识蒸馏的超分辨率卷积神经网络的压缩方法。该方法使用一个参数多、重建效果好的教师网络和一个参数少、重建效果较差的学生网络。首先训练好教师网络,然后使用知识蒸馏的方法将知识从教师网络转移到学生网络,最后在不改变学生网络的网络结构及参数量的前提下提升学生网络的重建效果。实验使用峰值信噪比(PSNR)评估重建质量的结果,使用知识蒸馏方法的学生网络与不使用知识蒸馏方法的学生网络相比,在放大倍数为3时,在4个公开测试集上的PSNR提升量分别为0.53dB、
中图分类号:TP391
文献标志码:A
Abstract: Aiming at the deep structure and high computational complexity of current network models based on deep learning for super-resolution image reconstruction, as well as the problem that the networks can not operate effectively on resource-constrained devices caused by the high storage space requirement for the network models, a super-resolution convolutional neural network compression method based on knowledge distillation was proposed. This method utilizes a teacher network with large parameters and good reconstruction effect as well as a student network with few parameters and poor reconstruction effect. Firstly the teacher network was trained; then knowledge distillation method was used to transfer knowledge from teacher network to student network; finally the reconstruction effect of the student network was improved without changing the network structure and the parameters of the student network. The Peak Signal-to-Noise Ratio (PSNR) was used to evaluate the quality of reconstruction in the experiments. Compared to the student network without knowledge distillation method, the student network using the knowledge distillation method has the PSNR increased by 0.53dB, 0.37dB, 0.24dB and 0.45dB respectively on four public test sets when the magnification times is 3. Without changing the structure of student network, the proposed method significantly improves the super-resolution reconstruction effect of the student network.
Key words: super-resolution; knowledge distillation; convolutional neural network compression; teacher network; student network
0 引言
超分辨率(Super Resolution, SR)是计算机视觉中的经典问题,在监控设备、卫星图像、医学成像和其他许多领域都具有重要的应用价值。单张图像超分辨率(Single-Image SR, SISR)的目的是从单个低分辨率(Low Resolution, LR)图像中恢复出与其对应的高分辨率(High Resolution, HR)图像。SR是一种病态问题,可以从给定的低分辨率图像获得多个高分辨率图像。在例如双线性(bilinear)插值、双三次(bicubic)插值等传统插值方法中,使用固定的公式来对输入的低分辨率图像内的邻域像素的信息执行加权平均,来计算放大的高分辨率图像中所丢失的信息。然而,这种插值方法不能产生足够的高频细节来产生清晰的高分辨率图像。
近年来,由于GPU和深度学习(Deep Learning)技术的快速发展,卷积神经网络(Convolutional Neural Network, CNN)被广泛用于解决超分辨率问题,并且在超分辨率图像的重建中得到了显著的效果。Dong等[1]提出的超分辨率卷积神经网络(Super-Resolution CNN, SRCNN)算法首次将卷积神经网络应用在超分辨率问题中,它直接学习输入低分辨率图像与其对应的高分辨率图像之间的端到端映射。SRCNN的结构非常简单,仅使用了三个卷积层。它的成功说明使用卷积神经网络来解决超分辨率问题是一种有效的方法,并且可以重建高分辨率圖像的大量高频细节。Kim等[2]受VGG-net[3]的启发提出了非常深的超分辨率卷积神经网络(image SR using Very Deep convolution network, VDSR)。VDSR的网络由20个卷积层组成。VDSR中使用了大量卷积层,它的应用效果也表明在超分辨率中“网络越深,效果越好”。
Lim等[4]提出超分辨率的增强型深度残差网络(Enhanced Deep residual networks for SR, EDSR)是基于SRResNet[5]的结构,并去除了其中不必要的模块来优化它,以简化网络结构。该文指出,原始的ResNet[6]最初提出是为解决图像分类和检测等更高级的计算机视觉问题,直接把ResNet的体系结构应用到像超分辨率重建这样的低级计算机视觉问题时,并不能达到最理想的结果。由于批量标准化(Batch Normalization, BN)层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的重建效果。
此外,RDN(Residual Dense Network)[7]和RIR(Residual In Residual)[8]分别提出了更深的SR网络,进一步提高了SR重建效果。
先前的研究表明,通过增加卷积神经网络的深度可以显著改善超分辨率重建效果;但是,其计算时间和内存消耗也同时增加。在低功率的嵌入式终端设备的实际应用场景中,计算资源和存储资源是部署深度CNN模型的约束条件。在实际应用中部署这些先进的SR模型仍然是一个巨大的挑战。这促进了对神经网络的加速和压缩[9]的研究。
Hinton等[10]提出的知识蒸馏(Knowledge Distillation, KD)技术,使用教师学生网络的方法简化深度网络的训练。
该框架将知识从深层网络(称为教师网络)转移到较小的网络(称为学生网络)中,训练学生网络使学生网络能够学习教师网络的输出。Remero等[11]用强大的教师网络训练一个窄而深的学生网络,以便改善网络训练的过程。在文献[11]中,不仅使用教师网络的分类概率作为学习目标,而且也使用教师网络的中间特征图作为训练期间的学习目标。
本文提出使用一种新颖的策略,该策略使用教师学生网络来改善图像超分辨率效果。其中的学生网络使用基于MobileNet[12]的结构,在不改变学生网络的模型结构、不增加计算时间的约束条件下,使用知识蒸馏来提高超分辨率学生网络(Student Net for SR, SNSR)模型的重建效果。把超分辨率教师网络(Teacher Net for SR, TNSR)的中间特征图的统计特征值作为知识传递到超分辨率学生网络。与未使用知识蒸馏的学生网络相比,网络的重建效果得到了提升,使得低功率的嵌入式终端设备能够有效地运行图像超分辨率模型。综上所述,本文的主要工作如下:
1)将知识蒸馏方法用在超分辨率问题中。利用知识蒸馏将知识从超分辨率教师网络转移到超分辨率学生网络,在不改变其网络结构的前提下,大幅提高了学生网络的超分辨率重建性能。
2)为了确定从教师网络到学生网络的有效知识传递方法,本文评估并比较了多种不同的特征图统计值提取方法,并选择最佳方式将教师网络的知识传递到学生网络。
3)将MobileNet用于超分辨率学生网络。与超分辨率教师网络相比,超分辨率学生模型需要较少的计算资源,并且可以在低功耗嵌入式设备上有效运行,因此提供了一种在计算受限的设备上实时部署超分辨率重建模型的有效方式。
1 本文方法
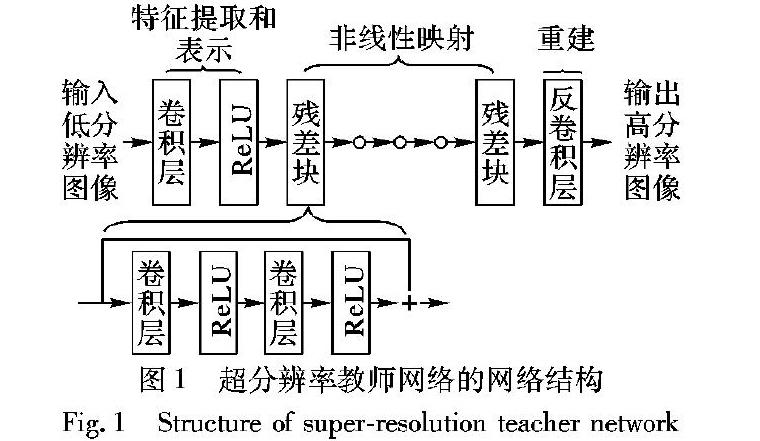
1.1 教师网络的结构本文的教师网络的结构如图1所示,教师网络的结构由三个部分组成:
1)特征提取和表示,由一个卷积层和一个非线性激活层组成。第一部分的操作F1(X)可表示为:
其中:W1和B1分别表示第一个卷积层中的权重和偏差,卷积核大小为k1×k1;“*”表示卷积操作;X是输入的低分辨率图像图像。
2)非线性映射,由10个残差块组成[6]。每个残差块中有两个卷积层,如图1所示。
每个卷积层后面都有一个非线性激活层ReLU。跳跃连接用于连接每个残差块的输入和输出特征。通过这种方式,仅学习每个残差块的输入和信息,它可以解决训练非常深的网络中的梯度消失问题[6]。
3)使用反卷积层重建HR输出图像。在先前的研究中,如SRCNN[1]和VDSR[2],使用双三次插值将低分辨率图像重建成超分辨率图像,然后将其作为卷积神经网络的输入。由于所有卷积运算都是在高分辨率空间中执行的,因此计算复杂度非常高。另外,插值预处理步骤会影响超分辨率重建效果。针对这一问题,FSRCNN(Fast Super-Resolution Convolutional Neural Network)[13]中采用反卷积层来代替插值操作,学习低分辨率图像和高分辨率图像之间的放大映射。
最近的研究成果例如LapSRN[14]和SRDenseNet[15]也采用了反卷积层来重建超分辨率图像。反卷积层可以被认为是卷积层的逆操作,并且通常堆叠在超分辨率网络的末端[13]。使用反卷积层进行放大有两个优点:第一,它可以加速超分辨率的重建过程,由于在网络的末端进行放大操作,所以仅在低分辨率空间中进行所有卷积操作。
如果放大倍数是r,则它将大致降低至计算成本的1/r2。
第二,因为通过在超分辨率网络的末端添加反卷积层来接收大的感受野,模型能够根据低分辨率图像的上下文信息推断更多高频细节。
1.2 学生网络的结构
学生网络的结构如图2所示。
学生网络包括三个部分:
第一部分是特征提取层,该部分与教师网络相同。MobileNet采用深度可分离卷积(Depthwise Separable Convolution)块在取得较好结果的情况下,能大幅降低模型的参数规模。受此启发,学生网络的第二部分的非线性映射使用了三个深度可分离卷积块。每个模块由深度卷积(Depthwise Convolution)層和逐点卷积层组成,逐点卷积是卷积核大小为1×1的卷积。深度卷积层将单个滤波器应用于每个输入通道,而逐点卷积应用1×1的卷积来组合深度卷积的输出。与MobileNet不同,本文没有使用批量标准化层,因为它会消耗大量的内存[4]。深度可分离卷积和逐点卷积之后都是非线性激活层,深度卷积可以表述为:
如果使用卷积核大小为3×3的滤波器,则深度可分离卷积块的计算量为标准卷积块的1/9到1/8这可以显著节省大量的计算资源,但会降低少许精度[12]。学生网络的第三部分是用于重建的反卷积层,这部分也与教师网络相同。
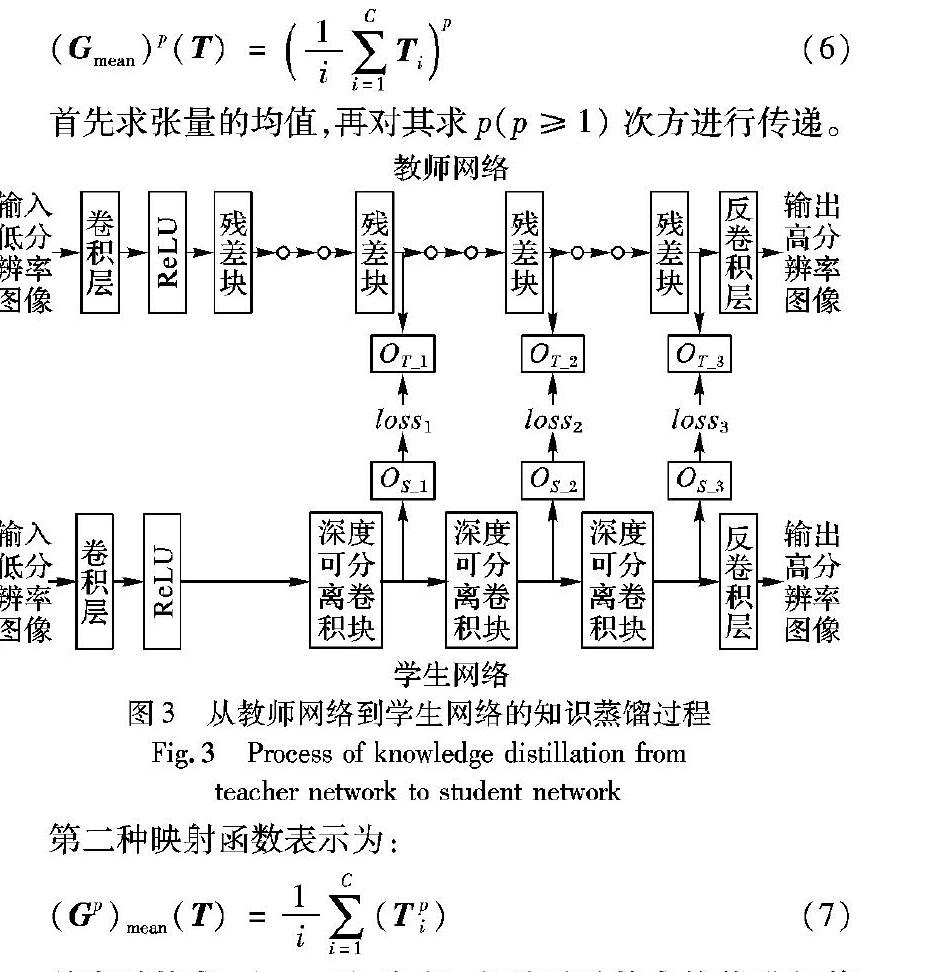
1.3 知识蒸馏与传递为了将有用的知识从教师网络传递到学生网络,分别从教师网络和学生网络提取统计图。如图3所示,使用教师网络的第4、第7和第10个残差块的输出计算统计特征图,并分别表示为OT_1、OT_2和OT_3,用来描述低级、中级、高级视觉信息。在学生网络中,本文使用第1、第2和第3个深度可分离卷积块的输出提取相应级别的统计特征图,分别表示为OS_1、OS_2和OS_3。之后,使用教师网络中OT_1、OT_2和OT_3的信息来指导训练学生网络中OS_1、OS_2和OS_3的信息。传递的统计特征是从网络的中间输出计算的,而不是直接使用网络的输出。在图像分类问题中已经证明了传递网络中间的特征图会比传递网络的输出效果更好[16]。网络的中间特征图输出可以表示为张量T∈RC×H×L,它由空间大小为H×L的C个特征通道组成。然后从张量T计算统计特征图S:
其中:G是将张量T映射到统计特征图S∈RH×W的函数。
本文用4种类型的映射函数来计算统计特征图:
第一种映射函数表示为:
首先求张量的均值,再对其求p(p≥1)次方进行传递。
第二种映射函数表示为:
首先对其求p(p≥1)次方,之后再对其求均值进行传递。最后两种映射函数分别将张量T特征图的最大值以及最小值作为统计特征图进行传递:
在训练学生网络期间,从学生网络提取的统计特征图S1、S2和S3学习从教师网络提取的统计特征图T1、T2和T3的內容。另外,重建超分辨率图像同时学习训练目标图像的内容。因此,训练学生网络的总损失函数可以表示为:其中:λi是损失的权重系数;loss0为计算重建图像Y′和训练目标图像Y之间的损失函数;loss1、loss2和loss3分别代表学生网络和教师网络不同级别统计特征图之间的损失函数。本文使用Charbonnier函数[13]作为损失函数,并将其定义为:其中ε2设定为0.001。Charbonnier损失函数用于计算式(10)中的所有损失。
2 实验设置
2.1 数据集和评价指标
本文使用公开的基准数据集进行训练和测试,其中DIV2K数据集[17]和Flickr2K数据集作为训练集。DIV2K数据集由800张图像组成,Flickr2K数据集由2650张图像组成。 在测试阶段,Set5数据集[18]、Set14数据集[19]、BSDS100数据集[20]和Urban100数据集[21]用于SR基准测试。本文使用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似性(Structural SIMilarity index, SSIM)来评估超分辨率重建结果。峰值信噪比经常用作测量图像退化等领域中图像重建质量的方法,是目前使用最广泛的客观图像质量评价标准,峰值信噪比的值越高表示超分辨率的重建效果越好。结构相似性对亮度、对比度和结构这三个因素进行整合来衡量两张图像之间的相似性,范围在[0, 1],当结构相似性的值为1时,说明两张图像是一致的。由于超分辨率模型是在YCbCr空间中的亮度通道Y进行训练的,因此本文仅在亮度通道Y上计算峰值信噪比和结构相似性。
2.2 参数设置
对于训练数据集,首先用双三次降采样方法对其分别进行2倍、3倍、4倍的下采样,得到其对应的低分辨率图像,再把低分辨率图像裁剪成尺寸为40×40的非重叠图像块作为网络的输入,把其对应的高分辨率图像块作为训练目标。每个图像块都转换到YCbCr空间,并提取其中的Y通道进行训练。在教师网络中,卷积核大小设置为3×3,每层卷积的通道数设置为64。在学生网络中,深度卷积层的卷积核大小设置为3×3,并且输出通道的数量设置为64。当放大倍数为2时,教师网络和学生网络末端的反卷积层的卷积核大小设置为4×4,步长设置为2,输出通道设置为1;当放大倍数为3时,教师网络和学生网络末端的反卷积层的卷积核大小设置为3×3,步长设置为3,输出通道设置为1;当放大倍数为4时,需要在网络末端放置两个反卷积层,每一个反卷积层对特征图进行2倍放大,其中:第一个反卷积层的卷积核大小设置为4×4,步长设置为2,输出通道设置为32;第二个反卷积层的卷积核大小设置为4×4,步长设置为2,输出通道设置为1。在训练期间,所有实验都使用Adam[22]进行优化,并使用其默认参数β1=0.9, β2=0.999。学习率设定为固定值0.0001,批量大小(batch size)设置为32。每组实验在NVIDIA Titan X GPU上使用Tensorflow进行500000次训练迭代后进行测试。
3 实验结果分析
首先将单独训练教师网络和学生网络,训练教师网络的作用是在接下来的实验中对学生网络进行指导,训练学生网络的目的是与经过教师网络指导后的学生网络进行对比。在利用教师网络指导学生网络的训练过程中,利用测试集选取出教师网络最好的迭代次数,将低分辨率图像分别输入教师网络和学生网络,但教师网络的参数保持不变,经教师网络指导的学生网络不使用已经训练好的学生网络的参数,从第0次迭代次数开始训练。本文实验均采用峰值信噪比和结构相似性作为评价指标。
3.1 不同级别的特征图的重要性
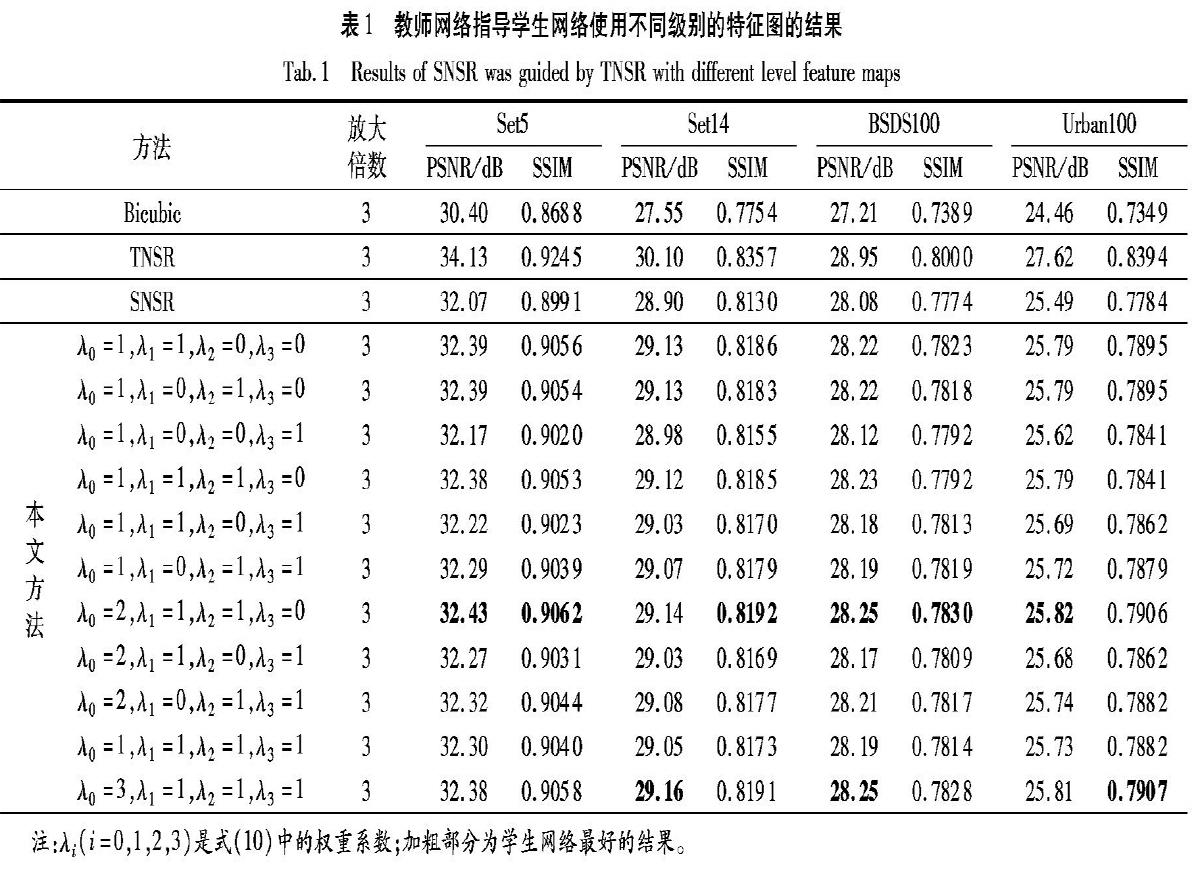
本文分析了不同级别的特征图在知识蒸馏过程中的重要性,本节在低分辨率放大倍数为3的情况下进行对比实验。在式(10)中设置不同的权重进行比较,其对比结果如表1所示。从表1可以看出,传递第一级别和第二级别的特征图信息显著改善了超分辨率重建效果。这表明高级特征(第三级别的特征图)在低级计算机视觉任务(在本文的例子中是超分辨率)中用处较小。因此,本文的后续比较实验中,仅使用第一级别和第二级别的特征图作为知识蒸馏过程所传递的特征图。
3.2 不同知识蒸馏方式的比较
本节对使用不同知识蒸馏方式的统计特征图性能在低分辨率放大倍数为3的情况下进行对比实验。使用式(6)计算4个统计特征图,其中系数分别设置为1、2、3和4。这些统计特征图在本文的工作中表示为Gmean、(Gmean)2、(Gmean)3和(Gmean)4。使用式(7)~(9)计算另外3个统计特征图,并分别表示为(G2)mean、Gmax和Gmin。从教师网络和学生网络中提取相同蒸馏方法的统计图进行传递。在训练学生网络期间,学生网络的统计特征图学习教师网络的统计特征图。图4显示了学生网络使用了不同的知识蒸馏方式在峰值信噪比的表现。
学生网络利用到了特征图的所有信息,其重建效果要显著优于仅使用了张量通道中的部分值Gmax和Gmin的方法。在訓练过程中,本文将训练数据集归一化为[0,1],在使用知识蒸馏训练学生网络的过程中,使用(Gmean)3和(Gmean)4作为统计特征图进行传递时,对[0,1]内的值求3次方或者4次方时,其计算结果极小,使用这两种方法的特征图间的损失函数在计算总损失函数时无法提供很多有用的信息。同时,使用(Gmean)2作为统计特征图进行传递获得了最高的峰值信噪比。因此,本章的后续实验最终选择了(Gmean)2来计算统计特征图。
3.3 知识蒸馏在超分辨率中的有效性
本文在表2对有教师网络指导的学生网络(表示为SNSR(Gmean)2)和没有教师网络指导的学生网络(表示为SNSR)的超分辨率重建效果在不同放大倍数的情况下进行了比较,并且在表中给出了Urban100测试集在iPhone X运行所需要的时间,同时将本文的结果与移动设备中的非深度学习快速超分辨率(Rapid and Accurate Super Image Resolution, RAISR)算法[23]进行比较。
如表2所示,学生网络的重建效果在所有测试数据集上都有了提升:峰值信噪比在放大倍数为2的情况下的提升范围为0.24~0.52dB;在放大倍数为3的情况下的提升范围为0.24~0.53dB;在放大倍数为4的情况下的提升范围为0.10~0.25dB,并且它们的每秒浮点运算次数(Flops)和参数量(Params)也没有改变。使用SNSR和SNSR(Gmean)2的结果的视觉比较如图5所示,可以明显地看出超分辨率重建效果的显著提升。
本文将该高分辨率图像先缩小到原来的1/3后得到低分辨率图像;
图(b)是将该低分辨率图像经过双三次插值放大3倍的图像;图(c)是将低分辨率图像经过不使用知识蒸馏方法时的学生网络所得到的结果;图(d)是将低分辨率图像经过使用知识蒸馏方法时的学生网络所得到的结果。图(b)为使用传统的插值方法对低分辨图像进行放大,该方法所生成的图像在比较图中最模糊,视觉效果最差。图(c)与图(d)相比,线条的波纹感较重,图(d)重建的图像与原图最相似,说明用知识蒸馏方法可以有效地提升该小型网络的超分辨率重建效果。
同时改变教师网络中卷积的通道数和学生网络中深度级卷积的通道数进行对比实验,来验证知识蒸馏在超分辨率问题中的可行性。对于其通道数c=64,进行了通道数分别为c=32,c=128和c=256的三组对比实验,其余参数设置以及实验条件不变。在放大倍数为3时,学生网络不同通道数的比较结果如表3所示。
从表3可以看出:当通道数发生改变时,学生网络的峰值信噪比会随着通道数的增加而增加,而经过教师网络指导的学生网络也可以从相应的教师网络中进行知识蒸馏,并从中受益获得更高的峰值信噪比。但是当通道数减少时,教师网络的特征图提供的知识信息较少,所以学习效果较为一般,而当通道数越来越大时,学生网络与教师网络的差距会逐渐变小,所以从教师网络可以学到的知识也逐渐减少,峰值信噪比的提升值逐渐降低。
4 结语
本文采用知识蒸馏将知识从教师网络转移到学生网络,在不改变其结构、不增加计算成本的前提下,大幅提高了学生网络的图像超分辨率重建效果,满足终端设备实时计算的要求。为了确定在教师网络和学生网络之间传递信息的有效方式,从两个网络中提取不同的统计图并进行比较。此外,学生网络利用深度可分离卷积来降低SR的计算成本,从而可以在低功率设备上部署超分辨率重建模型。但是学生网络未能完全学习到教师网络的知识,学生网络的重建效果与教师网络的重建效果依旧有明显的差距。在将来研究工作中,将研究构建更小、更高效的超分辨率神经网络。
参考文献(References)
[1] DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Berlin: Springer, 2014: 184-199.
[2] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1646-1654.
[3] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1409.1556.pdf.
[4] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1132-1140.
[5] LEDIG C, THEIS L, HUSZR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 105-114.
[6] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[7] ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2472-2481.
[8] ZHANG Y, LI K, LI K, et al. Image super-resolution using very deep residual channel attention networks[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Berlin: Springer, 2018: 294-310.
[9] 陳伟杰. 卷积神经网络的加速及压缩[D]. 广州: 华南理工大学, 2017:1-7. (CHEN W J. The acceleration and compression of convolutional neural networks[D]. Guangzhou: South China University of Technology, 2017: 1-7.)
[10] HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1503.02531.pdf.
[11] REMERO A, BALLAS N, KAHOU S E, et al. FitNets: hints for thin deep nets[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1412.6550v2.pdf.
[12] HORWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1704.04861.pdf.
[13] DONG C, LOY C C, TANG X. Accelerating the super-resolution convolutional neural network[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Berlin: Springer, 2016: 391-407.
[14] LAI W, HUANG J, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5835-5843.
[15] TONG T, LI G, LIU X, et al. Image super-resolution using dense skip connections [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 4809-4817.
[16] ZAGORUYKO S, KOMODAKIS N. Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1612.03928.pdf.
[17] AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1122-1131.
[18] BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single image super-resolution based on nonnegative neighbor embedding[EB/OL]. [2019-01-10]. http://people.rennes.inria.fr/Aline.Roumy/publi/12bmvc_Bevilacqua_lowComplexitySR.pdf.
[19] ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[C]// Proceedings of the 2010 International Conference on Curves and Surfaces, LNCS 6920. Berlin: Springer, 2010: 711-730.
[20] MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]// Proceedings of the 8th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2001: 416-423.
[21] HUANG J, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 5197-5206.
[22] KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1412.6980.pdf.
[23] ROMANO Y, ISIDORO J, MILANFAR P. RAISR: rapid and accurate image super resolution[J]. IEEE Transactions on Computational Imaging, 2017, 3(1): 110-125.
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
河南科技(2021年35期)2021-04-25
科技创新与应用(2020年4期)2020-02-25
上海师范大学学报·自然科学版(2019年5期)2019-12-13
初中生世界·九年级(2018年12期)2018-12-22
中国新通信(2017年9期)2017-05-27
CHIP新电脑(2016年3期)2016-03-10
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
意林(2011年10期)2011-05-14
