
样本量对云南松幼苗生物量模型构建及预估精度的影响
2019-11-15 08:17李亚麒许玉兰孙继伟汪梦婷蔡年辉
植物研究 2019年6期
李亚麒 许玉兰, 李 伟 孙继伟 汪梦婷 蔡年辉,*
(1.西南林业大学西南山地森林资源保育与利用教育部重点实验室,昆明 650224; 2.西南林业大学云南省高校林木遗传改良与繁育重点实验室,昆明 650224; 3.云南吉成园林科技股份有限公司,弥勒 652300)
生物量模型法(包括异速生长关系和生物量—蓄积量模型),是目前测定生物量最常用的方法。其利用较易获得的实测数据,通过一定的函数关系转换获取生物量[1]。既能满足建模精度的要求又可减少人力、物力、财力及工作量等[2]。在生物量模型法中异速生长方程又最具代表性,是应用最为普遍的一类模型[3],为生物量估测提供了一种简便、有效的方法。特别是在大范围的森林生物量调查中,能大大减少工作量[4~5]。
在构建生物量方程时,样本的代表性、样本量、模型形式、模型评价等都与模型精度密切相关[6]。一般而言,选取的样本容量越大,样本的代表性就越好,建模的精度也就越高,但耗费的人力、物力也就越多,甚至难以完成。相反,如果样本量过小,建模精度不满足要求[7~8]。因此为了节约成本并提高工作效率,寻求合适的样本数量十分必要。已有很多类似的研究表明样本量会对模型构建的准确性产生影响,诸如样本量对叶面积指数遥感经验建模精度影响[9],样本容量对BIOCLIM模型模拟物种分布准确度的影响[10]、样本量对MaxEnt模型预测物种分布精度和稳定性的影响[11]等。这些研究表明,与样本量充足时所建立的模型相比,小样本量使得统计分析研究面临着许多挑战,其预测能力相对较低。随着样本量的增加,模型模拟精度增加,增加的幅度慢慢减小直至不再增加,最终趋于达到模型的最大准确度。说明模型的精度在不同的样本量下会有所不同。
云南松(PinusyunnanensisFranch.)又称青松、飞松、长毛松,为喜光性强的深根性树种,生长迅速且耐干旱耐瘠薄,是西南地区荒山造林先锋树种及主要的用材树种,也是云南省的主要的经济树种。可供建筑、枕木、板材、家具及木纤维工业原料等用。具有较高的经济价值和生态效益[12~13]。目前人们对云南松幼苗生物量的测定仍以整株收获法为主,不但耗时、耗力且破坏性大。而通过构建生物量模型,能够在减小工作量、降低破坏性的基础上提供一种更为直观、准确的生物量估算方法,便于云南松苗期生物量估测。且从已有研究文献来看样本量对模型构建精度的影响主要是针对遥感经验模型[9]、物种分布模型[14]等模型的研究,基于不同样本量对生物量模型构建的研究涉猎甚少,且对生物量模型的研究也只是基于乔木树种的不同抽样方法[15],关于幼苗样本量对生物量模型构建精度影响的研究尚处空白。鉴于此,本文构建了不同样本量云南松幼苗生物量模型,探讨样本量对生物量模型构建及预估精度的影响,并确定构建模型所需的临界样本量。以期为云南松生物量模型的构建提供一个具有参考价值的实例研究。
1 材料与方法
1.1 研究区概况与材料
试验地设在西南林业大学温室,位于102°45′41″E,25°04′00″N,海拔1 945 m。于2014年12月在云南省昆明市宜良县进行种子采集,在成熟的云南松天然林中选择生长正常、无明显病虫害的植株,采集发育正常的成熟球果。将采摘的球果做好标记、分类带回实验室晾晒风干,待球果开裂取出球果中的种子,用点播方式进行播种于苗床,苗床规格为1 m×30 m,株行距为5 cm×10 cm,采用完全随机区组设计,共20个家系,每个家系播种40株,设置3个重复。播种后,盖薄膜小拱棚,不定期浇水,待苗出齐后,进行露天培育,旱季根据情况进行浇水。于2016年12月底,对615株2年生云南松苗木的苗高,地径等生长性状进行测定并记录。待生长停止后,采用“全挖法”挖取云南松苗木,用电子天平称量各样株根、茎、叶各组分的鲜质量,分别装入标记好的纸袋中,在105℃的烘箱中杀青30 min后,调至80℃进行烘干处理至质量恒定,测量根、茎、叶各组分的干质量,即为生物量,精确至0.001 g。
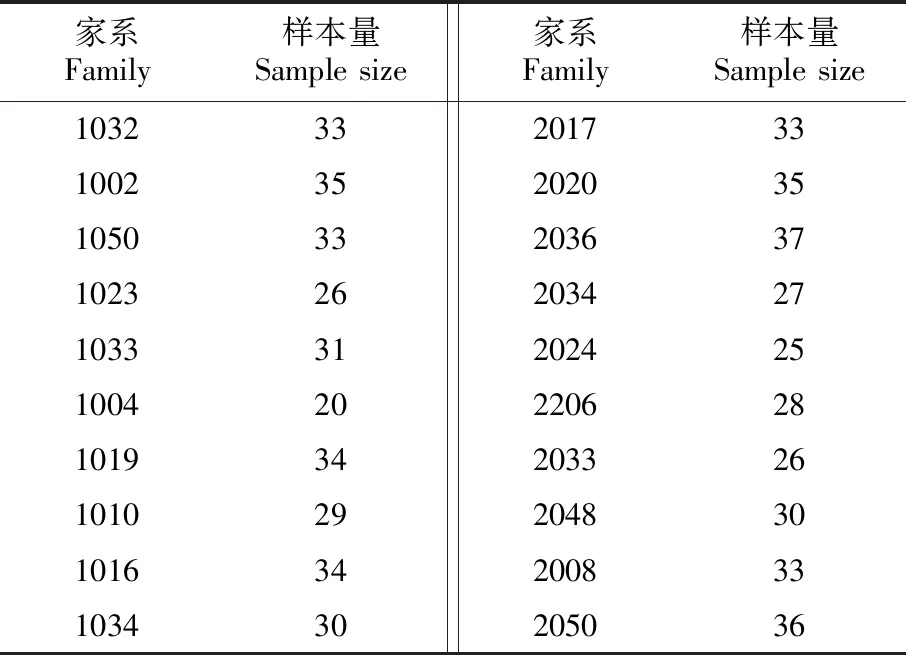
表1 云南松各家系样本量基本情况
1.2 研究方法
1.2.1 样本量确定
采用不同的样本量对表1中20个云南松家系进行随机抽样以构建生物量估测模型。设置的样本量分别为40、80、120、160、200、240、280、320、360、400,共10个梯度(S1、S2……S10)。其中S1包含20个家系各2株,S2包含20个家系各4株,以此类推。编写计算机程序建立抽样框进行简单随机抽样。根据抽取的样本分别构建生物量估测模型,利用总体615株幼苗进行精度检验。
1.2.2 模型建立
以随机抽取的20个云南松家系的不同样本量中苗高、地径等生长性状和根、茎、叶及单株生物量的测定值为建模数据构建生物量模型(表2)。具体以苗木的地径(D)、苗高(H)、地径与苗高的乘积(DH)、地径平方与苗高的乘积(D2H),分别与苗木根生物量(W根)、茎生物量(W茎)、叶生物量(W叶)以及单株生物量(W单株)进行Pearson相关分析,筛选出与各器官及单株生物量相关性较强的因子,再以相关性最好的因子作为模型的自变量,根、茎、叶及单株生物量(W)作为因变量,选用常用函数(幂函数)[16~17]构建生物量估测模型。
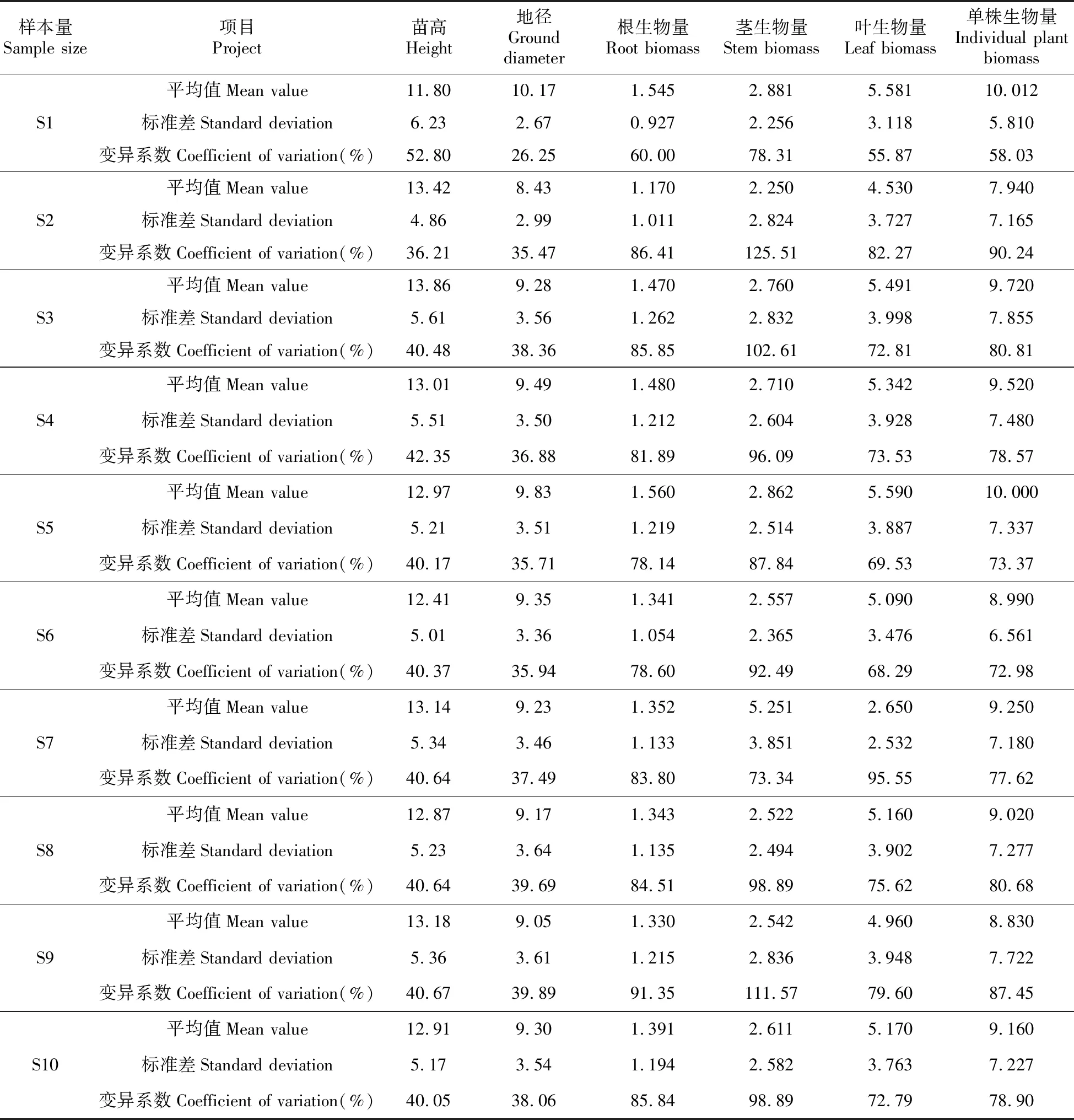
表2 云南松苗木生物量建模样本基本情况
1.3 数据处理与模型评价
通过编写计算机程序建立抽样框(Windows Forms Application2)进行简单随机抽样,采用Excel进行数据统计,SPSS 21.0进行回归分析。对拟合的回归方程均进行F检验,根据决定系数(R2)、估计值的标准误(SEE)及均方根误差(RMSE)对构建生物量型进行拟合优度评估。选取相关最密切、拟合度较好的模型,即R2大,SEE、RMSE小的模型。并根据生物量实测值与估计值之间的总相对误差(RS)、平均误差绝对值(MAB)进行验证方程的准确性和适用性[18~19]。一般RS值小于30%,说明拟合的生物量模型比较符合实际。模型的MAB越小,则精度越高。相应的数学表达式为:
均方根误差(RMSE):
(1)
平均误差绝对值(MAB):
(2)
相对误差(RS):
(3)
2 结果
2.1 生物量估测模型自变量选择
以云南松幼苗的地径(D)、苗高(H)、地径与苗高的乘积(DH)、地径平方与苗高的乘积(D2H),分别与苗木根生物量(W根)、茎生物量(W茎)、叶生物量(W叶)以及单株生物量(W单株)进行相关分析。由表3可知,云南松幼苗根、茎、叶各器官及单株生物量与D2H相关性最好,均达到极显著水平(P<0.01)。因此选取D2H作为自变量构建生物量估测模型。
2.2 不同样本量模型确立
由表4可以看出:采用幂函数模型拟合得到的不同样本量云南松幼苗的根、茎、叶各器官以及单株生物量估测模型均达到极显著水平(P<0.001)。根、茎、叶及单株生物量生物量决定系数R2范围分别为0.714~0.819、0.752~0.806、0.648~0.799、0.745~0.867。根、茎、叶及单株生物量估算值的标准误SEE及均方根误差RMSE均小于1。说明幂函数模型拟合效果较好,可较好估测云南松幼苗生物量。
对不同样本量云南松幼苗根、茎、叶及单株生物量模型的决定系数(R2)、估计值的标准误(SEE)及均方根误差(RMSE)进行比较分析。由图1可见:不同样本量拟合得到的根、茎、叶及单株生物量模型的决定系数R2、估计值的标准误SEE、均方根误差RMSE间差异不大。说明相对生长模型的稳定性较好,对样本量的敏感性不大。

表3 苗木生物量与预测变量间的相关系数
注:**表示在0.01水平(双侧)上极显著相关;*表示在0.05水平(双侧)上显著相关;H.苗高;D.地径;D2;地径的平方;DH.地径与苗高的乘积;D2H.地径平方与苗高的乘积;W根.根生物量;W茎.茎生物量;W叶.叶生物量;W单株.单株生物量
Note:**indicates a significant correlation at the 0.01 level;*indicates a significant correlation at the 0.05 level; H.Height; D.Ground diameter. DH.Product of ground diameter and height; D2H.Square of the diameter multiplied by height; Root W is root biomass; stem W is stem biomass; leaf W is leaf biomass; Individualplant W is single plant biomass.

表4 不同样本量幼苗生物量估测模型
注:W根.根生物量;W茎.茎生物量;W叶.叶生物量;W单株.单株生物量
Note:Wroot.Root biomass; Wstem.Stem biomass; Wleaf.Leaf biomass; Windividualplant.Single plant biomass
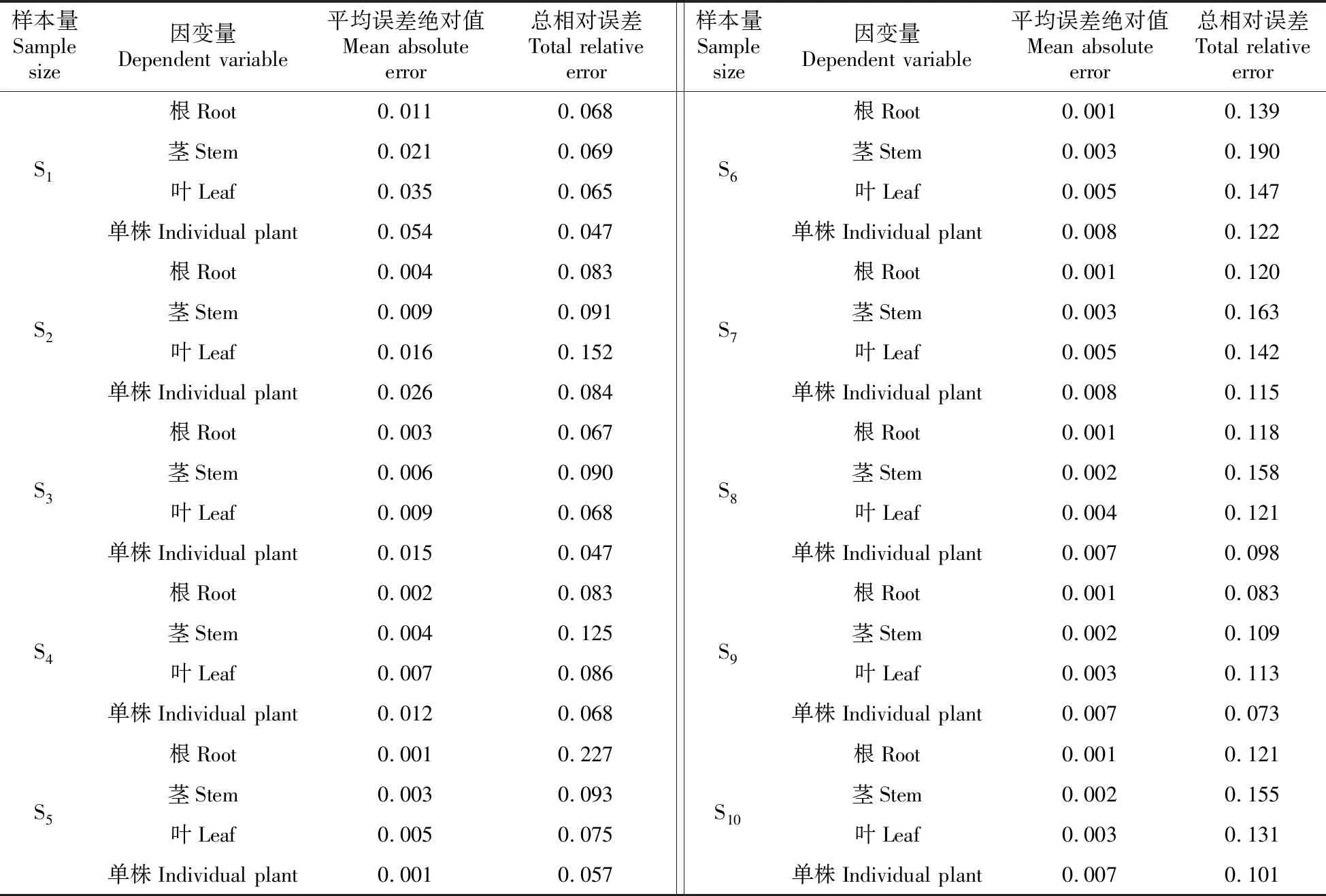
表5 不同样本量幼苗生物量估测模型精度检验
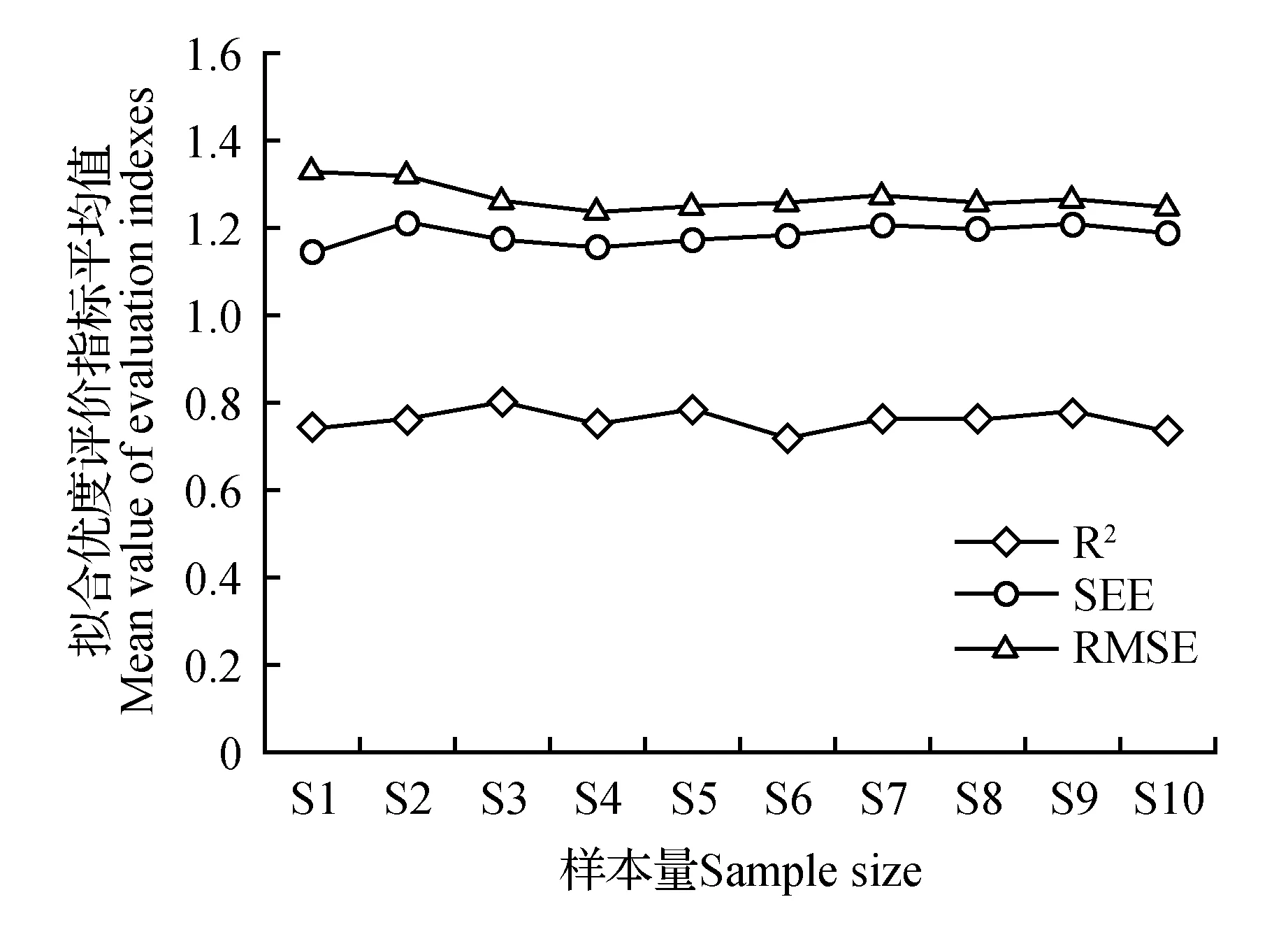
图1 不同样本量各拟合优度评价指标平均值的变化趋势Fig.1 Variation trend of the mean value of evaluation indexes of goodness of fit for different sample sizes
2.3 模型精度检验
为了验证模型的估测效果,对不同样本量幼苗各器官以及单株生物量的估计值与实测值进行验证分析(表5),可知估测模型RS范围为:0.047%~0.227%,MAB的范围为0.001~0.054,说明所构建的生物量估测模型精度满足要求。
平均误差绝对值随样本量的变化趋势(图2)表明,随着样本量的增加,MAB呈幂函数形式逐渐减小。总体模型检验精度顺序S10>S9>S8>S7>S6>S5>S4>S3>S2>S1。对于不同样本量根、茎、叶及单株生物量模型精度都表现为样本量小于200时,随着样本量的增加,MAB呈急剧下降趋势,而当样本量大于200时,MAB虽然有所波动,但变化趋势较为平稳。因此,根据MAB的变化趋势,样本量达到200时采样数据可以构建精度较高且稳定模型。
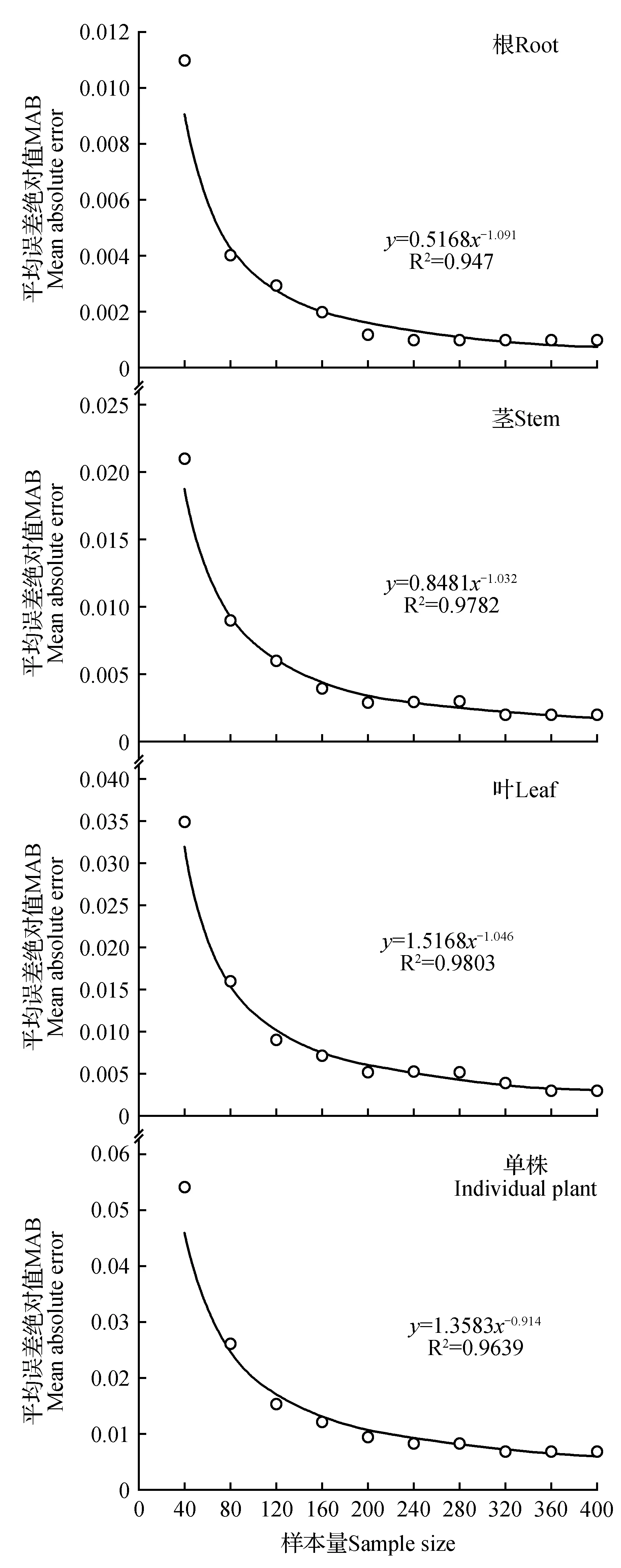
图2 平均误差绝对值随样本量的变化趋势Fig.2 Variation trend of mean absolute error with sample size
3 讨论
一直以来,异速生长方程被认为是拟合生物量的一个较为理想的模型[20~21]。针对构建方程的自变量多数人认为D2H是一个很好指标,拟合效果较好[22~23]。本研究基于对云南松地径、苗高,根、茎、叶各器官及单株生物量等的测定,筛选与苗木生物量相关性最强的因子(D2H)拟合不同样本量云南松苗木生物量估测模型。结果表明,采用幂函数方程拟合得到的云南松幼苗生物量模型均具有较大的R2值与较小的SEE与RMSE值,说明幂函数可较好的用于估测云南松幼苗生物量。与前人的研究结果类似,刘林森[24]在云南松生物量模型的研究中:分别以的胸径(D)、树高(H)、胸径与树高乘积(DH)、胸径平方与树高乘积(D2H)为自变量,采用线性模型、多项式模型、指数模型、对数模型及幂函数模型对云南松生物量进行拟合。也表明幂函数模型估测效果最佳,并根据云南松的生长特性最终确定W单木=a(D2H)b为滇西北云南松单木生物量模型。另外本研究中基于不同样本量构建的生物量模型中R2、SEE、RMSE值间相差不大,说明幂函数方程的稳定性较好,对样本量的敏感性不大。
在构建生物量模型时,选取合适的样本量至关重要。因为样本量的大小不仅会影响模型参数估计的变化,也会对模型的精度造成影响[25~26]。在本研究中,建模样本量较小时,MAB值的变动比较大,模型的稳定性较差。随着建模样本量的不断增大,MAB值变化越来越小,即模型精度越来越好。最后随着样本量增大,MAB值几乎也不再发生变化,趋于稳定状态。这与其它样本量对模型精度影响的研究结果类似,Wisz等[27]、Hernandez等[28]在对MaxEnt物种预测模型的精度随着样本量变化的研究中,表明随着样本量的增加,MaxEnt物种预测模型的精度随之增加。Stockwell等[29],也得出随样本量增加,模型的AUC均值随之增加,其认为最高的模型准确度都来自使用最大样本量构建的模型。毕志宏等[30]在对样本数量对白桦群体遗传参数估算影响的研究中,也表明不同样本数量会对白桦的各遗传参数产生影响。
样本量的临界值对模型估测精度产生重要的影响,在临界值以下,估测精度随样本量增大而提高,达到临界值后,样本量的增加对测量精度改善起的作用很小。在本研究中总体看来,当样本量小于200时,随着样本量的增加,MAB呈急剧下降趋势。当样本量达到200时,云南松有幼苗生物量的预测均达到了一个比较稳定的值。当样本量大于200时,MAB虽然有所波动,但变化趋势较为平稳。因此,最终得出构建云南松幼苗生物量模型时,选取的样本量应大于200株。构建生物量模型时,选取的样本容量越接近样本总体,建模的精度也就越高,但综合建模精度与成本等因素而言,确定了模型的临界样本量也可构建精度较好的模型。
综上所述:(1)幂函数方程具有较好的预测精度,可较好的用于估测不同样本量云南松幼苗生物量。(2)小样本量下的模型精度较低,随样本容量的增加模型精度逐渐增加。在构建生物量模型时应采用较大的样本,以保证其估测精度及准确性。但综合建模精度与成本等因素而言,确定了模型的临界样本量也可构建精度较好的模型。(3)对于本研究的测定群体而言,要获得精确度较高的生物量模型,所需的建模样本量应大于200株。样本容量越大,样本的代表性就越好,建模的精度也就越高,相反,如果样本量太小,其建模精度不能够满足需求。构建生物量估测模型有助于简便、快捷的测定幼苗生物量,但在构建生物量估测模型时采用不同的自变量、不同的模型均会存在差异,在实际应用中应充分考虑这些因素。因此在研究区外应用本研究的生物量模型,需要进一步的检验。
猜你喜欢
心理学报(2022年10期)2022-10-12
福建农林大学学报(自然科学版)(2022年5期)2022-10-08
中国循证心血管医学杂志(2022年1期)2022-03-15
内蒙古统计(2021年4期)2021-12-06
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
种子(2019年5期)2019-07-02
南方农业·下旬(2017年8期)2017-10-23
绿色科技(2017年3期)2017-03-14
