
一种基于概率主题模型的恶意代码特征提取方法
2019-11-15 01:43刘亚姝王志海侯跃然严寒冰
计算机研究与发展 2019年11期
刘亚姝 王志海 侯跃然 严寒冰
1(北京交通大学计算机与信息技术学院 北京 100044) 2(北京建筑大学电气与信息工程学院 北京 100044) 3(北京邮电大学网络技术研究院 北京 100876) 4(国家计算机网络应急技术处理协调中心 北京 100029)
恶意代码是各种类型恶意软件的统称,包括病毒、特洛伊木马、后门、蠕虫等.据2019年Symantec发布的《互联网安全威胁报告》称,全球日均拦截威胁数量达142亿个,几乎每一种物联网设备都很容易遭受攻击[1].恶意代码对互联网企业、个人用户的数据安全和财产安全造成了极大的威胁.
最常见的恶意代码检测方法是基于特征码的检测,通过人工提取、构造特征库,比对相同位置的字节码来判断样本是否为恶意代码[2].这种方法被各大反病毒工具广泛使用,通过不断更新特征库以提高保护企业、个人用户信息安全的能力.但是基于特征码的检测方法不能识别未知的恶意代码,而随着各种开发工具的发展,恶意代码的变体越来越多样、反检测能力越来越强,使得各大反病毒和安全厂商面临着巨大的挑战.在与恶意代码博弈中,研究人员也提出很多有价值的研究成果.
Moskovitch等人针对反汇编后的文件指令、结构等从语法和语义角度分析汇编代码,提出以n-grams操作码序列为特征构造恶意代码的特征集[3];Santos等人分析操作码的频度以达到检测未知恶意样本的目的[4].Kapoor将操作码与控制流程图(control flow graph, CFG)结合起来实现多类别的分类[5].Ashkan提出基于API调用的检测方法[6].
2001年Matthew将数据挖掘技术引入恶意代码检测中,恶意代码检测技术有了飞速地发展,传统恶意代码检测技术与数据挖掘技术相结合产生了更好的检测效果[7-8].Saxe等人引入深度神经网络可以实现大规模恶意样本的低误报率检测[9].以Nataraj为代表的研究人员另辟蹊径,将二进制可执行PE文件转化为灰度图像,借助图像处理的办法和机器学习算法实现恶意样本的分类问题[10-13].
Tamersoy等人考虑样本之间的关系图[14];Ye等人结合样本内容和样本之间的关系实现云端恶意代码的检测[15];Fan等人将样本与API、样本与压缩包、样本与机器之间关系构造为异构信息网络以检测应用程序的恶意性[16].
由于恶意代码相对于良性代码而言会有特殊的行为,例如会有特定的访问序列、特定的行为以及对内存的控制,因此基于行为的分析是动态检测中常用的技术[17-20].
综上,无论是动态还是静态分析方法,通过分析样本的内容、样本之间的关系提取恶意特征,并采用机器学习的方法分类恶意样本是一种常用的方法.
本文基于Windows平台,从静态分析入手针对恶意代码样本的反汇编文本,采用概率主题模型聚集样本特征,并用机器学习算法实现恶意样本的分类问题.本文主要贡献有3个方面:
1) 给出了汇编指令标准化规则.该规则不仅针对操作码,同时也考虑了操作数的影响.细化后的规则可以提高0.4左右的分类精确率.
2) 提出了具有潜在语义的特征表示方法.本文引入概率主题模型——LDA,通过计算潜在的“文档-主题”概率分布得到样本特征.该特征具有潜在语义信息,更具有鉴别能力.
3) 给出了一种无监督学习模型.本文结合LDA模型提出了一种全新的、无监督的学习模式,它可以为新样本赋予与训练集相关的主题概率分布,具有检测新样本的能力.同时将困惑度与不定步长相结合快速、准确选取合适的“主题”数目,解决LDA模型需要预先设定主题数目的问题.
本文为恶意代码的检测提出了一个新的研究视角.实验表明:与其他方法相比,本文方法不仅具有较好的分类性能,而且能够识别新的恶意代码.
1 概率主题模型
概率主题模型是一种统计方法,以非监督学习的方式分析文本中的“词”从而发现蕴藏于其中的“主题-词”、“主题-文档”之间的结构.Christos等人于1998年提出了潜在语义索引(latent semantic indexing, LSI)[21].Hofmann于1999年提出了概率潜在语义分析(probabilistic latent semantic analysis, PLSA)[22].随后,Blei等人于2003年提出了潜在狄利克雷分布(latent Dirichlet allocation, LDA)[23].LDA是一个生成模型,也是一个3层贝叶斯概率模型,包含词、主题和文档3层结构,可以生成“文档-主题”模型.在主题模型中,“主题(topic)”就是文本中“词(word)”的条件概率分布,表示“词”与“主题”之间的关联性,反映了“词”在该“主题”下出现的频繁程度,即与该“主题”关联性高的“词”有更大概率出现.其概率模型图如图1所示:
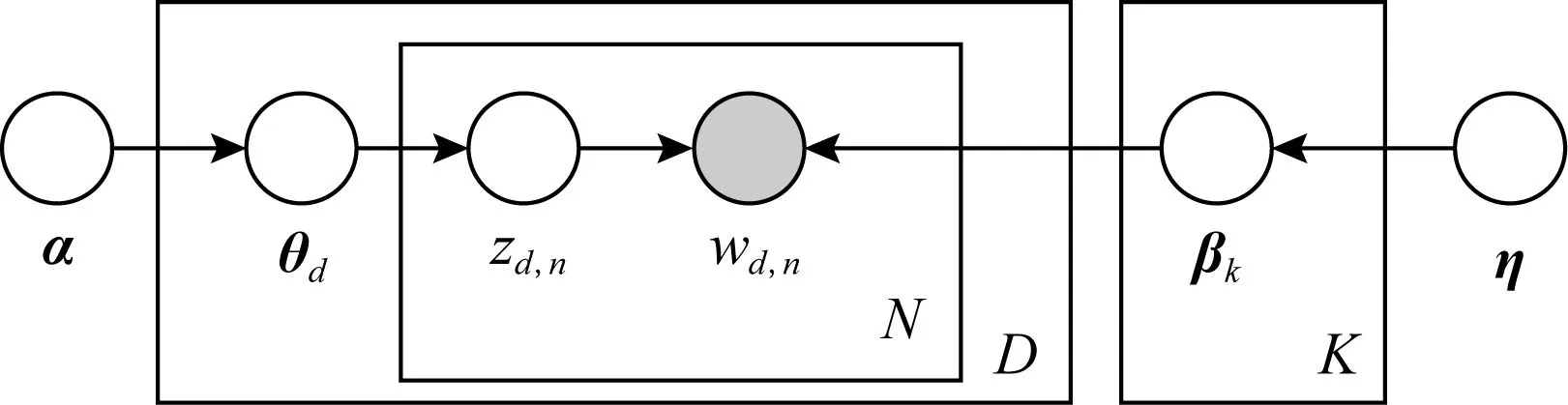
Fig. 1 Probabilistic model diagram of LDA图1 LDA概率模型图
1.1 模型定义
在主题模型中,涉及到“文档”、“主题”、“词”,下面给出符号定义.一篇“文档”W是由N个“词”wi构成,即W={w1,w2,…,wN}构成,这里wi表示第i个“词”;一个“语料库”D是M篇文档的集合,即D={d1,d2,…,dM},语料库中包含的全部“词”可以表示为W={w1,w2,…,wV};“主题”是隐含在文档中,用于聚集相关的“词”,可以表示为Z={z1,z2,…,zK}.概率主题模型,不仅能够对语料库中的“文档”而且对于其他“相似文档”都具赋予较高的概率.LDA模型中“主题”分布与“词”分布都服Dirichlet先验分布.
根据图1,产生一篇文档的方式为:
1) 采样主题d的主题分布θd~Dirichlet(α),得到文档d的主题分布;
2) 生成第d个文档的第n个主题zd,n~Multinomail(θd),得到词的主题;
3) 采样主题zd,n的词的分布βk~Dirichlet(η),得到该主题的词分布;
4) 采样生成文档d的第n个主题下的词wd,n~Multinomail(βzd,n).
这里,α为Dirichlet分布的K维超参,用于产生任一文档di的主题分布θi;η为Dirichlet分布的V维超参,V代表D中“词”的个数.本文中使用的符号及说明如表1所示:

Table 1 Notations in this Paper表1 本文使用符号说明表
LDA模型的目标是找到每一篇文档的“主题分布”和每一个主题中“词的分布”.在模型中,需要预先假定主题数目——“K”.LDA模型中,假设文档中的“词”是无序的、互相独立的.文档中的词,通过统计词频构成词向量,也即“词包(bag of words)”.“主题”产生“词”不依赖具体某一个文档,因此“文档-主题”分布和“主题-词”分布是相互独立的.
1.2 模型推导
为了获得“文档-主题”和“主题-词”的概率分布,也即Z,W的概率分布,可以采用Gibbs采样的方法.
由于P(W,Z)∝P(W,Z|α,η),根据Dirichlet分布与多项式分布共轭的特性,可以简化条件概率P(W,Z|α,η)的求解:

(1)
有:
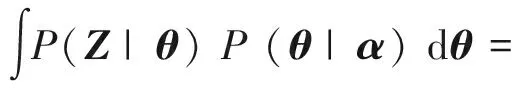
(2)
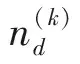
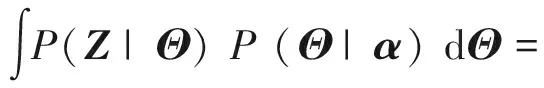
(3)
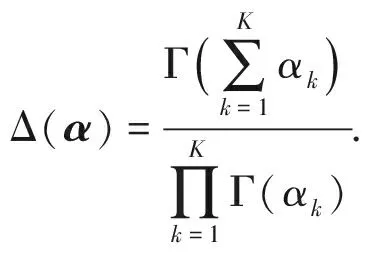
由于Dirichlet分布与多项式分布共轭则式(3)可写为
(4)
同理可得,式(1)中,
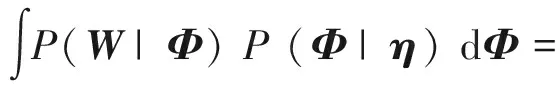
(5)


(6)
这样,获得了P(W,Z)联合概率分布的近似形式.在P(W,Z)中词向量W是已知的,因此:
P(zd,n|W,Z,α,η)=
(7)
其中,Z表示去掉词wd,n的主词分布,W表示词向量W中去掉词wd,n,由于:
P(θd|Zd,α)=Dirichlet(θd|α+nd),
(8)
P(βk|Z,W,η)=Dirichlet(βk|η+nk).
(9)
根据Dirichlet分布的期望公式,对式(8)(9)取数学期望,可以得到:
(10)
(11)
Gibbs采样“词”的“主题”,即得到所有词的采样主题,进而得到θd,βk.
2 恶意样本特征的提取
一个恶意样本可以通过逆向工具将其PE文件转化为汇编语言代码.本文通过LDA模型对恶意样本集中的汇编操作指令进行分析、提取其特征,并解决恶意样本的分类问题.
2.1 汇编指令的预处理
本文采用了python包中的pefile完成对PE文件的解析,获得汇编文件,如图2所示:
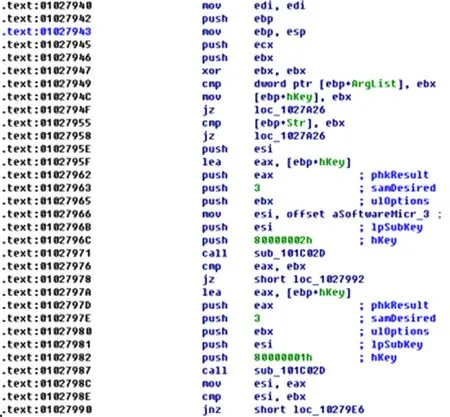
Fig. 2 Disassemble example of PE file图2 PE文件反汇编示例
如图2所示,经过反汇编解析得到的汇编文件中包含了很多冗余、干扰信息.在此仅针对其中的汇编指令提取特征.一条汇编指令由操作数和操作码构成,本文不仅针对操作码,同时操作数也参与特征的聚集.由于汇编指令的格式复杂、长短差距悬殊、含义高度丰富和杂乱、数量庞大,不能直接作为语料库.为了更好地控制“词典”的数据量,对数据进行粗糙化处理——汇编代码标准化,使其表示的类型有限、表示的规律性更明显.
具体方法为:
1) 操作码对齐
在汇编指令中操作码的长度为2~6个字符不等,由于3个字符长度以内的操作码占操作码类型的48.2%、4个字符长度的操作码占28.8%、5个字符长度的操作码占17.8%、6个字符长度的操作码占5.2%.而如果考虑到使用频率,3个字符长度内的操作码被调用的占比超过90%.因此,本文选用3个字符长度描述操作码.例如push→pus,mov→mov,call→cal,je→je_(_表示空格)等.
2) 操作数标准化
① 寄存器.由于寄存器的种类较多,常用的有8 b,16 b以及32 b三种主要的寄存器.如eax,ebx,ecx,edx,esi,edi,ebp,esp等寄存器标准化为r32;ax标准化为r16;al标准化为rg8[24].
② 内存.标准化为MEM.如[eax],[edi+4]等
均表示为MEM.
③ 立即数.标准化为VAL,如0,5A4Dh表示为VAL.
④ 调用指令.调用外部的系统库函数时指令不做处理;调用内部函数如“call sub_101C02D”时规范化为“call sub”.
⑤ 跳转指令后的操作数.如“jz short loc_4023E7”规范化“jz loc”.
表2给出了按照如上规则标准化前后的代码块的对照.

Table 2 Example of Standardizing the Assembly Instructions表2 汇编指令标准化示例
将每条汇编指令设定为一个“词”.图3所示的是MD5为0C1BF77A51B6308D62F0743C3B1A9FF1.3AF3EF67的样本,经过汇编指令规则化后、提取“词”的部分结果.
2.2 检测框架
将训练集中恶意样本按照上述方法标准化后,可统计出训练集的词典、每个样本的“词袋”作为LDA模型训练的输入数据,进而得到恶意样本的特征并实现分类.
本文在使用LDA模型提取恶意样本特征时,训练集样本会被使用2次,第1次是用来构建LDA模型,第2次是用来产生训练集的特征数据.但是,不论训练样本还是测试样本,都需要经过样本预处理.具体的工作流程如图4所示.工作流程可以分为3个阶段:
1) 训练样本预处理阶段.该阶段产生可被LDA模型处理的数据.首先需要标准化训练集样本的汇编指令、提取“词典”,计算每个样本的“词包”.初始设置LDA模型主题个数、输入LDA模型其他参数,产生当前数据分布下的LDA模型.经过多次困惑度和不定步长评价、选择最优的主题数目,进而得到最优主题数目下LDA的训练模型.
2) LDA建模阶段.样本预处理结果输入LDA模型会产生与LDA主题数相同维度的特征,每个维度标识在相应主题上的拟合程度,从而得到训练样本的特征,并训练分类器.
3) 分类阶段.该阶段将测试样本经过样本预处理、获得测试集的特征,将特征输入训练好的分类器,得到分类结果.
3 实验与分析
本节中我们构建了基于LDA模型的恶意代码检测模型,并在2个数据集测试了本文方法.首先选取2015年微软Kaggle数据集[25],包括训练集、测试集和训练集的标注.其中每个恶意代码样本(去除了PE头)包含2个文件:一个是十六进制表示的“.bytes”文件,另一个是利用IDA反汇编工具生成的“.asm”文件.
我们首先进行了小样本验证实验.在微软Kaggle数据集中,随机选取某一家族为测试集(例如随机选择编号为7的家族中的70个样本);训练数据为标号为7的家族中抽取的80个样本,以及其余家族中随机抽取的80个样本,共160个样本.经实验,当主题数为5时采用随机森林(random forest, RF)分类器(参数为30)精确率为0.969.证明本文方法对恶意代码的分类是有效的.
第2个数据集来自于CNCERT,包含10个家族、15 000个恶意代码样本.本文在CNCERT提供的数据集上测试了我们的方法并完成与他人方法的实验对比.
3.1 汇编指令标准化粗糙程度对分类结果的影响
按照2.1节汇编指令标准化规则,在CNCERT数据集上,当主题数目为240个时本文方法平均分类精确率达到最好,为0.90.每个家族具体的分类评价指标如表3所示:

Table 3 Classification Results of Every Family表3 各家族分类结果
从表3可以看出LMN家族分类结果最好,分类精确率可以达到100%;Softpulse家族和Ageneric家族的分类精确率较低.经过对比这2个家族的标准化操作码的结果发现,32 b寄存器均被标准化为r32,这种标准化方法过于粗糙,不利于分析较敏感的数据.
为此,细化了汇编指令的标准化规则,以便尽可能地抽取其中的信息,同时保证词典不会过于庞大.
寄存器中32 b寄存器更多地负责与程序有关的信息,将32 b寄存器具体标示出来.这些寄存器有EAX,EBX,ECX,EDX,ESIEDI以及EBP等.
此外还有R0~R3四个与程序运行息息相关的寄存器,也将它们具体进行标示.但是,这些寄存器并不是所有的编译环境都支持的,在样本中几乎不出现.
细化了寄存器类别后,采用RF分类器(参数为30)、主题数目为240时,平均分类精确率为0.94,相比细化前(0.90)有了较大提高,如表4所示:
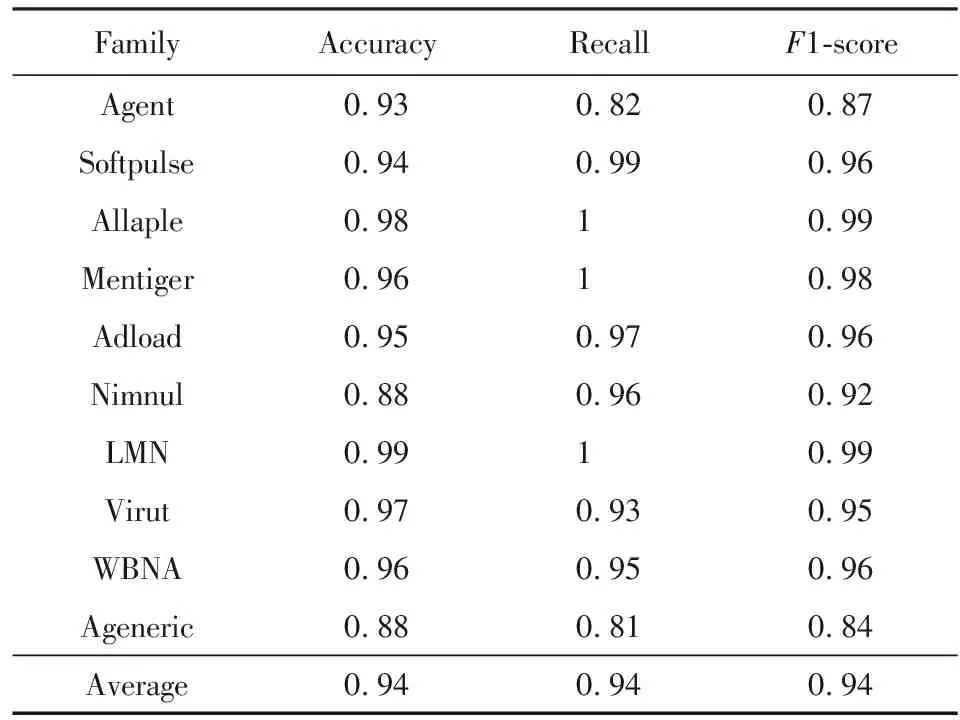
Table 4 Classification Results After More Specified Register Classes
从表4相比表3可以看到,Agent家族、Softpulse家族、Ageneric家族的精确率、召回率和F1-score都有了比较明显的提高.这说明对寄存器采用较精细的标准化规则能够更有效地反映出家族特征,会获得更好的分类结果.
3.2 主题数目的确定
在LDA建模过程中,需要预先设定主题的数目,但是如何准确设置主题的数目,这是一个很困难的问题.本文采用了困惑度来评价主题数目对模型的影响.困惑度(perplexity)是一种信息理论的测量方法.若求A的困惑度值,则定义为基于A的熵的能量(A可以是一个概率分布或者概率模型):
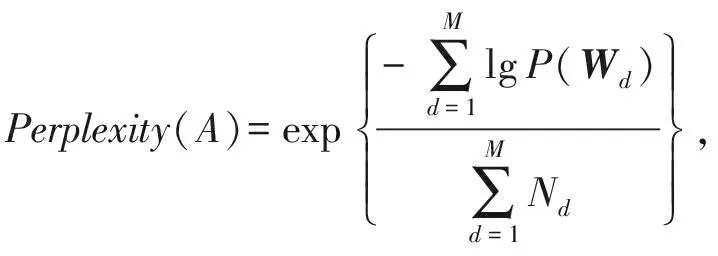
(12)
显而易见随着主题数的增加,困惑度会减小——更多的主题可以把单词更轻松和置信到不同的主题上.但是在主题数极少的时候,困惑度不会随着主题数上升而减小,反而会增加,这是因为在没有到达当前语料库合适的主题数时,大量困惑的样本一直难以被分配到合适的主题上.因此,本文选择拐点作为LDA模型的主题数,如图5所示:
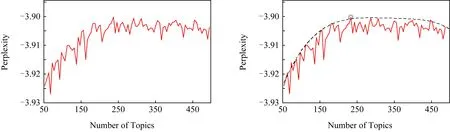
Fig. 5 Perplexity curve of LDA model using different topic numbers图5 LDA模型在不同主题数下困惑度曲线
在确定最优主题数目的过程中,为了加快最优主题选择的效率,本文采取的策略为:主题数目低于200时,按照固定步长的递增方法设置主题数目;当超过200时采用变化的步长,由大到小地确定主题数目的方法,加快了主题数目确定的速度,减少了一半以上的时间消耗.
3.3 LDA主题模型的特征描述能力
在LDA模型中,为了更明确地表述主题模型的特征描述能力,本文从实验中提取2个分布明显的家族——Allaple与Adload进行分析.首先提取2个家族中占比最多的几个主题,列出每个主题前十的汇编指令.根据“主题-词”分布,尝试分析其行为.图6为Allaple家族主题分布图,这里主题数目为240个.主题概率分布居前2位“主题”中的前十个“词”如表5所示.图7为Adload家族主题分布图,同样地选择主题概率分布居前2位的“主题”中前十个“词”如表6所示.
在这2个家族中可以看到的是,每个具有高拟合度的主题具有各自不同的特点.反映出来的或是在底层上的操作、或是在寄存器上的操作、或是在数据类型上的变化、或是中断的处理、或是函数的调用和返回、或是循环使用、或是权限申请,或是硬件端口使用等等信息.这些信息具有可读性以及可解释性.
虽然在构造LDA模型过程中词包是离散的、无序的形式,可从表面上看损失了汇编指令的上下文信息,但是从表5、表6的分析中也可以看到,本文方法聚集的特征具有隐含的语义信息,这并没有受到“词”序的影响,这就是LDA模型的魅力所在.
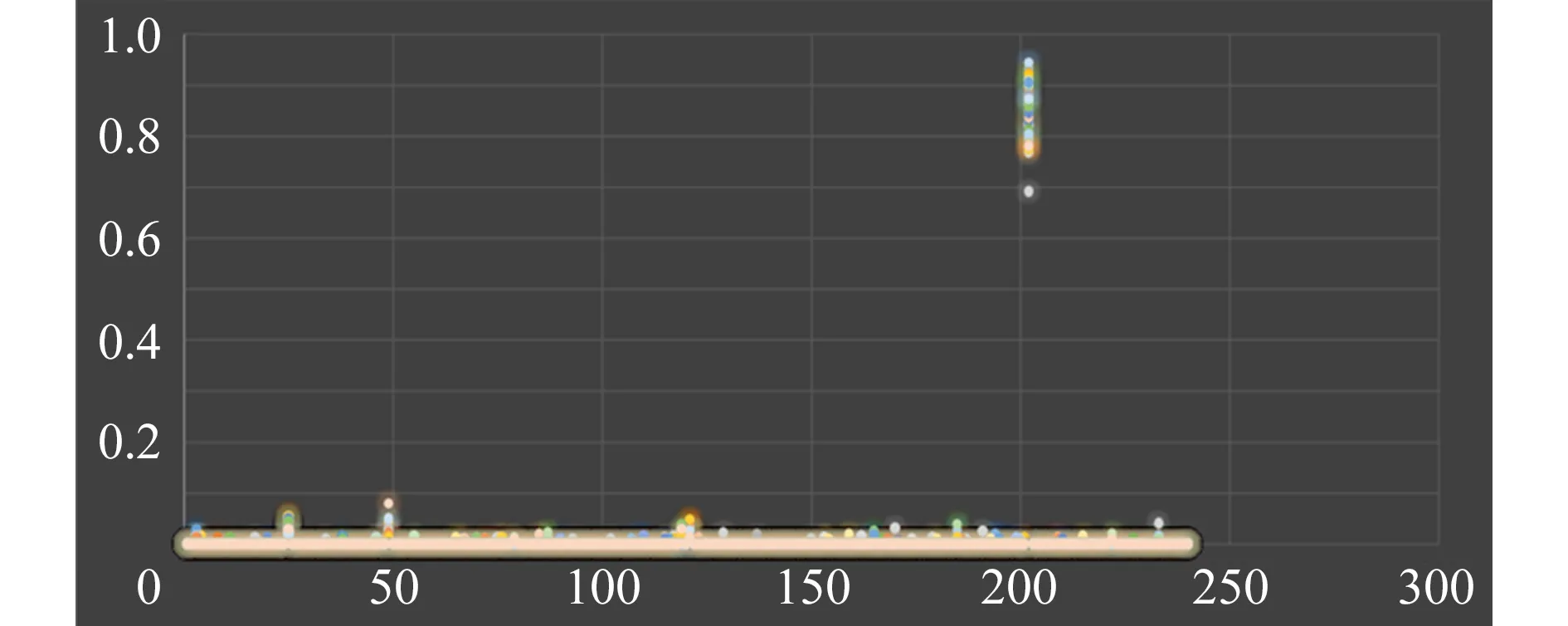
Fig. 6 Probability distribution diagram of Allape family图6 Allaple家族主题分布图

TopicTop Ten WordsBehavior DescriptionThe 200thTopic“ire oth”,“pus oth”,“stc oth”,“pop oth”,“imu ecx mem oth”,“arp mem oth”,“.by oth”,“dec oth”,“inc oth”,“xch eax oth”interrupt return;application for privilege level;exchange the value of register “eax”;The 23thTopic“pus oth”,“.by oth”,“inc oth”,“pop oth”,“dec mem”,“dec oth”,“jmp oth”,“int oth”,“cld oth”,“std oth”plus 1;minus 1;loop operartion;string operation;
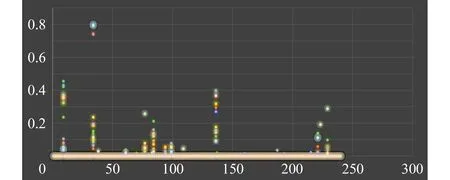
Fig. 7 Probability distribution diagram of Adload family图7 Adload家族主题分布图

TopicTop Ten WordsBehavior DescriptionThe 7thTopic“cdq oth”,“pus oth”,“pop oth”,“and ecx mem”,“.by oth”,“xch eax oth”,“mov val oth”,“dec oth”,“inc oth”,“int oth”extended registerhigher digits;register;replication andcomputing operations;plus 1;minus 1;The 32thTopic“pop oth”,“pus oth”,“dec oth”,“.by oth”,“xch eax oth”,“mov val oth”,“inc oth”,“ret oth”,“mov rg8 oth”,“int oth”register assignmentoperation;function return;
3.4 与其他方法的比较
在Kaggle和CNCERT数据集上的实验结果验证了本文方法的有效性.下面给出与他人方法的实验对比.
本文在CNCERT数据集上完成了其他3篇文献方法的实验:
1) 提取恶意代码反汇编文件的操作码序列并转化为点阵图的恶意代码分类实验[26];
2) 将恶意代码二进制可执行文件转化为灰度图像的分类实验[10];
3) 基于恶意代码反汇编文件Opcode 频度的恶意代码分类实验[4].
对比3个方法与本文方法的分类结果,可以看到本文方法与其他分类方法相比具有一致的或者更好的分类精确率,结果如表7所示:
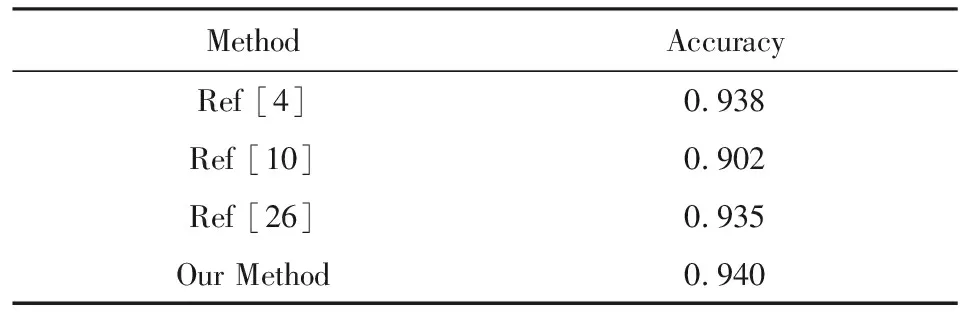
Table 7 Classification Results of Many Methods表7 多种方法的分类结果
此外,由于LDA的无监督学习特性,使得基于主题概率模型的特征提取方法可以为新样本赋予与训练集中的文档相关联的一组不同的主题概率[23].因此,本文方法完全有能力检测新样本,这是文献[4,10,26]不具有的能力.
4 总 结
本文将LDA主题模型用于Windows平台下的恶意代码分析中,采用LDA模型聚类恶意样本的特征,设计恶意代码检测的工作框架,实现恶意样本的分类问题.针对LDA模型主题数目不易确定的问题,提出了困惑度的评价方法,并采取了加速策略,大大提高运行效率.同时本文方法还能够检测未知样本.
但是受限于反汇编技术,目前在汇编命令的层级能获得的信息描述更加偏向于底层,如果想获得更抽象的信息可以采用2种方法:在静态分析的情况下,通过IDA获得WinAPI;在动态的情况下,可以通过沙箱获得API调用的词包信息,预测这些信息应用在本文的方法上依然是可行的,这将是本文接下来的研究内容.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
数码世界(2020年12期)2021-01-20
学校教育研究(2020年11期)2020-06-08
计算机应用(2020年5期)2020-06-07
汽车工程师(2019年7期)2019-08-12
科技与创新(2019年2期)2019-02-14
电子技术与软件工程(2018年1期)2018-03-22
电脑爱好者(2017年7期)2017-05-06
