
数据挖掘技术在NBA球队比赛应用研究
2019-11-12 12:01侯汝冲兰海翔卢涵宇胡正江薛安琪
电脑知识与技术 2019年25期
关键词:聚类算法
侯汝冲 兰海翔 卢涵宇 胡正江 薛安琪

摘要:随着人工智能的发展,Python网络爬虫技术应用越来越广。本文利用Python网络爬虫技术进行NBA球队数据的爬取,主要是采用requests及beautifulsoup包进行网络爬虫,利用pandas,matplotlib,numpy等模块对爬取的球队的篮板,抢断等数据进行分析筛选以及可视化处理,用聚类算法数据分析并将数据存储为csv格式文件,同时也探讨了数据挖掘在最佳球员归属,薪资匹配,球员搭档以及选秀模板等应用问题。
关键词:NBA; Python; csv;聚类算法;球队胜负
中图分类号: TP208 文献标识码:A
文章编号:1009-3044(2019)25-0199-03
Abstract: With the development of artificial intelligence, Python network crawler technology is applied more and more widely. This paper uses Python network crawler technology to crawl NBA team data, mainly using requests and BeautifulSoup package for network crawler, using pandas, matplotlib, numpy and other modules to crawl team rebounds, steals and other data analysis, screening and visualization processing, using clustering algorithm data analysis and will The data is stored in CSV format file. At the same time, the application of data mining in the attribution of the best players, salary matching, players'partners and draft templates is discussed.
Key words: NBA; Python; csv; clustering algorithm; team victory or defeat
NBA是美国职业篮球联赛(National Basketball Association)的简称,于1946年6月6日在纽约成立,是美国四大职业体育联盟之一。然而,对于球队的管理层来说,球员开薪资以及球队的收入问题随着NBA数据的日益复杂化就成了一个很棘手的问题,他们需要去考虑球员的技术能力的搭配,以及薪资的匹配问题。因此,球队很需要现行的数据挖掘技术去分析球员、球队数据,球员的搭配等诸多问题。或者说NBA的各项数据技术指标进行挖掘分析具有很大的需求与应用价值。
1 网络爬虫技术
网络爬虫是通过编程语言的实现对网站发出请求,并且用迭代或者递归的函数去对网络上的数据,图像,文字以及其他内容进行抓取。我们对NBA近十个赛季获胜球队的数据进行统计,如果手工浏览,那你就需要浏览大概上千张网页。这样就造成了很大的工作量。使用网络爬虫之后,就可以使用语言对网站发出请求,使用迭代或者是递归的函数对NBA历史数据进行下载,让计算机去完成数据的收集工作,提高了我们的收集数据的效率。
1.1网络爬虫实现步骤
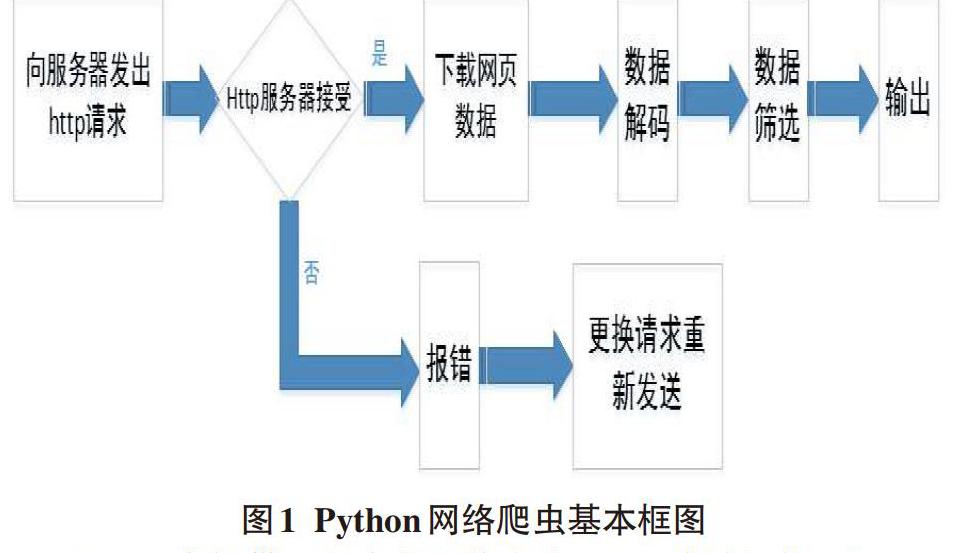
本文主要采用Python进行网络爬虫,基于Python的网络爬虫一般包括几个步骤,第一步进行对网站发出请求,第二步是下载数据,第三步是对数据进行筛选,第四步就是输出数据。使用Python进行网络爬蟲的基本框图如图1所示。
Python中提供了很多的网络爬虫工具,从最初的urllib,正则表达式,到后来有urllib2,慢慢地出现爬虫框架scrapy以及requests及beautiful的爬虫数据包。使用Python中requests包以及beautifulsoup包进行网络爬虫,使用以上两个数据包进行网络爬虫具有效率高,速度快以及代码复杂度低等优势。使用requests可以很快地下载到网页数据,然后beautifulsoup进行网页数据筛选,beautifulsoup最适合对文本及表格数据进行筛选,他可以大大降低筛选的难度
1.2本文的网络爬虫介绍
本文的实验数据来源是虎扑体育官方网站,主要对NBA过去两个赛季的球队对阵中的统计数据进行爬取。如投篮、命中率、篮板、助攻、抢断、得分等数据,并且将爬取的数据存储为csv格式,待后续处理。
2 聚类算法原理
2.1 KMeans算法原理
在聚类算法中,KMeans算法是使用最为广泛的一种算法,它的功能主要是把n个对象按照他们的属性将其分为k个聚类并且让这些类满足:同一个类型的对象相似度较高而不同的对象相似度较低。它的算法的核心就是计算样本点到中心的欧几里得距离(如式1),
2.2 KMeans++算法原理
K-Means++算法选择初始聚类中心的思想是:初始的聚类中心之间的相互距离要尽可能远。KMeans++算法可以说是在KMeans算法的基础上做了一些升级,但是其原理是与KMeans算法相同的,其算法步骤如下:
(1)随机挑选一个点作为第一个聚类中心;
(2)对于每一个点x,计算和其最近的一个聚类中心的距离D(x),将所有距离求和得到Sum(D(x));
(3)然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”(其思想是,D(x)较大的点,被选取作为聚类中心的概率较大);
(4)重复2和3,直到K个聚类中心被选出来;利用这K个初始聚类中心进行K-Means算法。
2.3 KMeans与KMeans++算法的优缺点
KMeans算法的有点便是简单快捷易理解,但是KMeans算法也存在很大的弊病就是需要事先去给定k个聚类中心,这样一来人们就很难认为的去划分这些聚类中心,其次就是他很可能导致极大的误差,或者说是不同的聚类中心会得到完全不同的聚类结果。
KMeans++算法算法理论上克服了KMeans算法需要事先给定聚类中心个数的缺点,他可以自己确定随机k个聚类心。
3 应用研究与结果分析
3.1 球队的投篮、罚球及三分命中率对比赛胜负的影响分析
本次采用KMeans算法的分析结果如图2-图4所示.
3.3 篮板,前场板与场板对比赛胜负的影响分析
采用KMeans算法对以上三项数据的分析结果如图8-图11所示。
4 结论
根据以上数据输出结果显示,投篮、三分与罚球命中率对于比赛的影响是,当球队的投篮命中率接近38%,三分命中率接近38%,罚球命中率接近70%的数据时,球队的得分仅为78.3,然而当以上数据接近49%,49%,78%时,球队的得分118.6,当三项数据接近44%,44%,75%时,球队的得分为100.7分,综合以上数据分析,根据官方数据统计,当球队的当场得分接近120分时,球队的赢球率为86.8%,当球队的得分到达100分附近时,球队的胜率为44.6%,但是当球队的得分低于80的时候,赢球的胜率仅为0.9%。综上所述,球队命中率更高,球队更可能赢得比赛。篮板对于比赛胜负的影响不是特别明显,因此,从目前已有的数据可以得出结论:篮板不是影响比赛胜负的关键因素。当篮板,抢断与助攻放在一起分析时候,助攻是影响比赛胜负的关键因素,当球队的助攻达到28时,总得分高达120分,根据上面的数据显示,球队胜率到达86.8%,此外,篮板与抢断对于胜负的影响很低,但综合来说还是数据更高的胜率更高。
参考文献:
[1] 王继重.基于Hadoop和Mahout的kmeans算法的设计与实现[J].大连海事大学,2016(3).
[2] 周敦飏.基于星型模型的球隊数据挖掘应用研究[J].华中科技大学,2012(5).
[3] 马遥.计算机数据挖掘技术在CBA联赛中的应用理论研究[J].郑州大学,2014(3).
[4] 柏宇轩.kmeans应用与特征选择[J]. 电子技术与软件工程,2018(1).
[5] 侯敬儒.基于spark的并行KMeans聚类模型研究[J].计算机与数字工程,2018(3).
[6] 张亚娟. OFDM系统同步技术研究[D].大连理工大学,2004(6).
[7] 王璠.中国体育事业统计数据的挖掘与分析[J].西安体育学院,2011(5)
[8] ywjun的学习笔记.Python KMeans使用[J]. CSDN博客,2018(8).
[9] lanse_zhicheng. K-means和K-means++算法代码实现(Python)[J].CSDN博客,2019(1).
[10] cx爱小芹芹. python爬虫+数据分析之NBA球员LBJ13个赛季的数据分析.[M].CSDN,2016.
【通联编辑:光文玲】
