
融合朴素贝叶斯和协同过滤的外卖推荐并行算法研究
2019-11-12 05:11鲍凯丽刘其成牟春晓
计算机应用与软件 2019年11期
鲍凯丽 刘其成 牟春晓
(烟台大学计算机与控制工程学院 山东 烟台 264000)
0 引 言
随着信息技术的高速发展,电子商务系统中的用户数量和产品种类越来越多,导致用户很难从海量的信息中获取自己感兴趣的内容。推荐系统作为一种重要的信息过滤技术和手段,是解决信息过载的有效方式[1]。推荐系统主要包括基于内容的推荐、协同过滤推荐和基于知识的推荐[2],协同过滤推荐算法是目前应用最广泛的推荐算法[3]。
随着信息化的迅速发展,餐饮业也加快了脚步,越来越多的用户通过网上订餐的方式进行美食选择。由于美食的种类和样式不断增多,导致了用户在选择美食时需要花费更多的时间和精力。在推荐算法领域进行外卖的研究分析,不仅可以帮助商家更好地锁定用户群,也可以帮用户高效地选择自己喜爱的美食。
本文提出了一种融合朴素贝叶斯和协同过滤的外卖推荐并行算法。该算法基于MapReduce分布式计算框架,通过对外卖评论数据集进行深入挖掘,实现外卖个性化的推荐,推荐的信息对用户具有很高的参考价值。
1 相关工作
评论挖掘是现有的协同过滤算法中用以缓解数据稀疏问题的重要方法之一,当前,已经有许多专家和学者对融入评论文本的推荐方法进行了大量研究。
文献[4]围绕从评论标签中挖掘用户对产品特征的观点展开研究,向用户推荐在他们感兴趣的特征上有较高评价的产品。文献[5]围绕从评论信息中提取社交情感展开研究,在推荐系统中推荐。文献[6]研究将用户评论集和商品评论集各自潜在的主题向量建立正向映射关系,进一步优化推荐模型。文献[7]提出网络评论数据的产品设计综合评价模型,运用情感倾向分析技术和LDA主题模型算法进行主题发现的研究。文献[8]提出利用评分数据生成评论态度影响因子,建立用户偏好与物品特征,进而进行评分预测与物品推荐。文献[9]提出对评论文本进行情感倾向的分析来产生相应的分值,从而进行推荐。文献[10]研究基于朴素贝叶斯的协同过滤推荐算法,采用改进的朴素贝叶斯方法对没有评分的数据进行预测。
随着餐饮行业的快速发展,如何通过网络及时准确的为用户提供合适的美食推荐已经成为目前研究的重点。
文献[11]研究基于协同过滤算法的美食推荐系统,根据用户对各种美食的评分,结合其他用户的兴趣相似度,并利用美食属性特征的相似度作为权重因子进行矩阵补全。文献[12]研究基于LDA模型的餐厅推荐方法。该算法首先对餐厅评价信息进行情感分类,进而获取积极评价和好评率,然后计算用户需求与餐厅标签的相似度,根据相似度和好评率向用户推荐餐厅。文献[13]研究基于协同过滤的美食推荐算法,该文献在计算相似度时引入了遗忘函数和用户间的信任度。
可以看出,无论是在融入评论文本的推荐方法方面,还是在美食推荐方面,上述文献都未对融合评论文本和评分数值的外卖推荐针对性的进行深入研究。本文同以上工作相比,数据对象来源于互联网的上真实美食评论,具有复杂性高、涉及面广等特点。在提高推荐系统的准确性方面,一方面设计融合评论文本和评分数值综合评分模型;另一方面在ALS模型前融合物品的相似性信息,设计一种新的损失函数。通过以上改进,本文算法在一定程度上减小了系统的均方根误差,提高了推荐准确率,改善了推荐系统性能。
2 相关概念
2.1 朴素贝叶斯分类
朴素贝叶斯分类是利用概率统计进行分类的算法,主要利用贝叶斯定理来预测一个未知类别样本属于其他类别的可能性,其基本思想如下:
假设有k个类C1,C2,…,Ck给定一个未知的数据实例X,分类器将预测数据实例X分类为属于具有最高后验概率的类,其中最大后验概率的类用P(Ci|X)最大的类Ci表示。
(1)
2.2 ALS算法
ALS算法的实质是填充用户—物品评分矩阵中缺失的部分,如果用户评分矩阵为R,其元素表示的是用户u对物品v的评价,由奇异值分解原理,矩阵R等于几个矩阵相乘。公式如下:
R=UTV
(2)
通过用户-物品的评分矩阵分解原理可知,预测用户对物品的喜好只需求取UT和V,一般通过最小化损失函数求取。为了防止损失函数过拟合,采用正则化方法添加正则化项,最后损失函数如下:
(3)
对于求解上述损失函数的最优化,可以使用梯度下降也可以使用最小二乘法,其中二乘法求取的是全局的最小值,固定一个向量,求取另一个向量,然后交替迭代执行,最终训练出一个最好的预测模型。
2.3 MapReduce
MapReduce是处理大数据的一种并行编程框架,将数据表达成键值对的形式。MapReduce包含任务分解(Map)和结果汇总(Reduce)两个步骤处理数据,Map任务和Reduce任务可以被分配到不同的资源节点并行执行。
3 外卖推荐并行算法设计
3.1 综合评分模型设计
目前,越来越多的外卖网站都支持用户对购买的外卖进行打分和发表评论,用户在挑选外卖时越来越注重商品的评论。评论文本内容是用户对外卖美食特征、质量、商家服务等的描述,评分并不能全面衡量用户对外卖的情感,所以结合评论文本这一指标来修正原来评分。
3.1.1评分预测
对外卖评论文本进行关键词提取,进而构建出针对外卖评论的情感词典,然后设计并行化的朴素贝叶斯文本情感分类器,量化评论文本情感值。经过数据预处理输出外卖训练评论数据形为D={C1,C2,…,Ck,A1,A2,…,An}, 其中A是属性变量,C为情感倾向。这部分算法主要分为两个步骤:
第一步训练阶段的主要目标就是生成外卖评论数据情感倾向的分类器,在算法训练阶段的Map阶段中,每一个节点随机抽取本台机器中存储的训练集Di中的外卖评论数据,Map阶段中每个节点执行的Map任务描述如下:
输入: 训练集
输出:
Begin
(1) While Di!=null do
(2) for each value do
(3) vals=str.split(″″)
(4) ClassID.set(vals[0])
(5) write(ClassID, one)
(6) end for
(7) for each value do
(8) GetCateInClass()
(9) cws.set(temp)
(10) write(cws, one)
(11) end for
End
Reduce阶段主要负责将Map阶段每个节点输出的内容进行汇总,输出<划分属性值,数量统计>键值对和情感倾向的先验概率prior[c]。Reduce阶段中每个节点执行的Reduce任务描述如下:
输入:
输出:
Begin
(1) int Num=0
(2) int Count=0
(3) for each vido
(4) Num+=val.get()
(5) write(ClassID, Num)
(6) end for
(7) for each vido
(8) Count+=val.get()
(9) write(cws, Count)
(10) end for
(11) for each calss do
(12) prior[c]=Num/sum
(13) end for
(14) write(ClassID, prior[c])
End
第二步分类阶段目标是使用第一步的分类器对未知情感倾向的评论文本预测分类,对每一条测试数据,根据式(1)计算测试样本的后验概率,然后将最大的后验概率的情感倾向判定为测试样本的类。
算法分类阶段的Map阶段的目标是计算每条外卖测试数据的条件概率,根据先验概率和条件概率通过计算测试样本的后验概率。Map阶段中每个节点执行的Map任务描述如下:
输入: 测试数据集
输出:
Begin
(1) While Bi!=null do
(2) for each value do
(3) Record=Data.freq.get(date)
(4) Tct=Record/Num
(5) P=P*Tct
(6) end for
(7) for each Class do
(8) Posterior[c]=prior[c]*P
(9) end for
(10) write(id, Posterior[c])
End
算法分类阶段的Reduce阶段的任务是把上一步输出结果进一步合并处理,若Posterior[积极倾向]大于Posterior[消极倾向],判断该评论数据为积极倾向,否则为消极倾向。其中, Score即该外卖评论文本情感值。
输入:
输出:
Begin
(1) for each calss do
(2) if(P>maxf)
(3) maxf=p
(4) end for
(5) id=new Text(val[ ])
(6) Score=new Text(ClassNames.get(maxf));
(7) write(id, Score)
End
由于外卖评分值是五分制,需要对上述量化的情感值Score进行处理使其取值范围在[0, 5]之间。
3.1.2综合评分模型
本文将外卖评分数值与评论文本情感值模型结合构建外卖综合评分模型。综合评分模型如下所示:
Score(i)new=w1×Score(i)1+w2×Score(i)2
(4)
w1+w2=1
(5)
式中:i表示第i条外卖评论;Score(i)1表示外卖评分数值;Score(i)2表示外卖评论文本的情感值;w1和w2分别表示外卖评分数值和外卖评论文本情感值的权重;Score(i)new表示结合外卖评分数值和外卖评论文本情感值的综合评分。
3.2 构建推荐模型
在得到外卖综合评分数据集后将其整合到并行文件系统HDFS中。在后续的并行推荐过程中,算法将从HDFS直接获取数据。
3.2.1算法的优化
依据ALS算法的原理可以发现,损失函数忽略了物品之间有价值的数据信息。因此,针对这个问题本文设计了一种新的损失函数,引入物品相似度。本文选择修正的余弦相似度,则此时损失函数为:
(6)
式中:nui表示用户Ui评价过的外卖的数量;nvj表示为外卖Vj评过分的用户数量;rui表示用户u对物品i的评分;ruj表示用户u对物品j的评分。
3.2.2计算推荐集
该部分主要通过3个步骤实现: ① 针对用户评分数据集求出外卖项目向量矩阵和用户向量矩阵。 ② 求用户特征矩阵U和外卖特征矩阵V。 ③ 利用上述步骤产生的U和V,求出推荐矩阵。
第①步的实现需要两个MapReduce过程,分别求出用户u评价过的外卖的集合和评价过外卖v的用户的集合。第一个Map阶段接受初始输入的数据集合, 统计不同用户对同一外卖的评分,Reduce阶段将其合并输出记为R[n]。第二个Map阶段统计同一用户对不同外卖的评分,Reduce阶段将其合并输出记为R[m]。
第②步计算用户特征矩阵U和外卖特征矩阵V, 每次求用户特征矩阵U和外卖特征矩阵V都需要一次MapReduce过程。由于用户ID和外卖ID的唯一性,在迭代计算过程不需要Reduce阶段。当求解U矩阵时,输入用户评分过的外卖的集合R[n]及外卖特征矩阵V,利用式(6)计算用户的特征向量Ui,Map阶段中每个节点执行的Map任务描述如下:
输入: R[n]
输出:
Begin
(1)whileDi!=nulldo
(2)foreachvifromDido
(3) V=rand()
(4) calculate Uiaccording to formula
(5)endfor
(6) write(
End
同理,当求解V矩阵时,输入评价过的外卖的用户的集合R[m]及用户特征矩阵U,利用式(6)计算外卖的特征向量Vj,Map阶段中每个节点执行的Map任务描述如下:
输入: R[m]
输出:
Begin
(1)whileDi!=nulldo
(2)foreachvifromDido
(3) U=rand()
(4) calculate Vjaccording to formula
(5)endfor
(6) write(
End
这样反复迭代计算U和V, 最后通过一个迭代次数计数器的任务来结束整个算法流程。
第③步利用上述步骤产生U和V,根据X=UVT求出预测评分矩阵X,得到的结果即为用户对每个项目的预测评分。最后对这些评分从高到低进行排序, 同时除去用户已经评价过的外卖,即可得到最终的用户推荐外卖项目集。
4 实验结果与分析
4.1 实验数据
从某外卖网站抓取了外卖的评论数据记为Date,采集的评论数据包括评论用户编号、外卖编号、评论时间、评分数值、评论文本。其中,评分值都是整数值(1~5之间),分数越高代表用户相应的外卖评分就越高。本实验数据集包括三组:第一组从Date中随机抽取5 000条评论数据记为Date1;第二组从Date中随机抽样500 000条数据记为Date2;第三组从Date中分别采集3种不同规模的数据集,得到数据规模分别为三组测试数据的大小分别是:589 MB、1 432 MB和2 471 MB。
4.2 评价指标
(1) 准确度。衡量一个推荐系统的优劣,有很多种评价指标[14]。本文将通过均方根误差(RMSE)来评价评分预测的准确度。均方根误差值越小,意味着准确度越高。公式表示为:
(7)
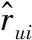
(2) 加速比。加速比用来衡量并行算法并行化的性能和效果。指同一个串行算法的运行时间(Ts)和并行处理器算法中运行消耗的时间(Tp)的比率,公式表示为:
(8)
4.3 综合评分模型分析
权重的确定方法主要分为主观赋权法[15]和客观赋权法[16]两大类。本文使用主观赋权法,通过人工标注对Date1数据集中评论文本和评分数值进行综合打分(5分制),然后比较评分数值的正确率(A1)和评论文本情感值正确率(A2)。
正确率=判断评分和人工标注评分相同的个数/总个数,结果如表1所示。

表1 评论文本和评分数值正确率 %
从表1可以看出,评论文本情感值的正确率比评分数值的正确率高,所以评论文本情感值更能反映外卖的真实评分,因此在构建综合评分模型时通过正确率的大小来确定评论文本和评分数值这两个变量的权重。
(9)
(10)
得到综合评分模型为:
Score(i)new=0.46×Score(i)1+0.54×Score(i)2
(11)
4.4 推荐结果分析
(1) 准确率分析。本文算法中最重要的参数是正则化参数λ和迭代次数。其中,迭代次数越大越精确,但是设置的越大也就意味着越耗时,算法在每次迭代时都会优化矩阵,因此经少数迭代就能收敛到一个较合理的模型,所以本文选取迭代次数为20、30、40。正则化参数越高正则化越严厉,但并非越高越好,在本文中选取正则化参数的值为0.1、1、10。因此共产生9个模型,该部分实验使用数据集Date2,分别计算9个模型的均方根误差如表2所示。

表2 本文算法均方根误差
从表2中可以发现,在正则化参数固定的条件下,随着迭代次数值增大,均方根误差的值越来越小。而在迭代次数值不变的情况下,随着正则化参数值增大,均方根误差值越来越大。其中当迭代次数为40,正则化参数为0.1时,算法的均方根误差最优,得到最优模型后,可以通过最优模型来进行推荐。
(2) 加速比分析。实验采用第三组数据集,分别测试三种规模数据在1个、2个和3个节点上的运行时间,实验结果如表3所示。
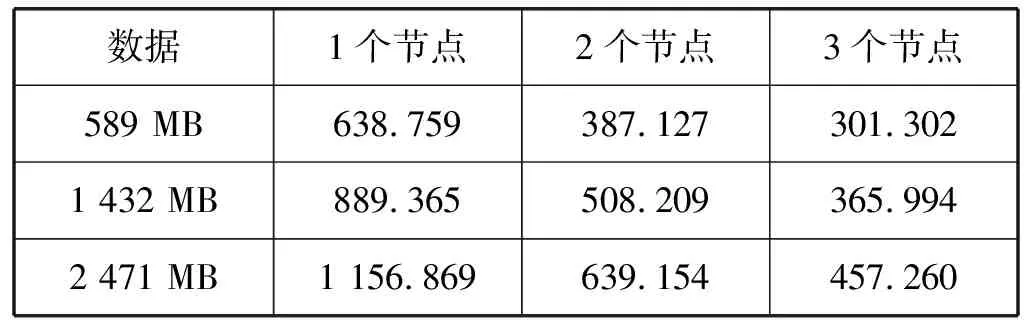
表3 运行时间 s
根据表3中的数据,可以计算出算法在三组数据集的加速比如表4所示,算法加速比的曲线如图1所示。

表4 数据运行加速比

图1 不同规模数据的加速比
分析表4和图1可以发现,在数据量不变的情况下,加速比随着节点数目的增加而增加。当节点数目不变时,随着数据规模的增大,加速比也会随之增高。实验结果表明,本文算法在处理比较大规模的数据时展现出了良好的性能,可以有效提高算法的执行效率,具有比较好的加速比。
4.5 实验对比
(1) 综合评分模型有效性实验对比。为验证融合评论文本和评分数值综合评分模型有效性,对数据集Date2进行处理,将仅有评论数值的外卖评论数据记为训练数据集D21,融合评论文本和评分数值的外卖评分数据记为训练数据集D22。使用两个数据集分别进行实验,推荐结果准确率对比如表5所示。

表5 均方根误差的值
由表5可知,采用训练数据集D22比训练数据集D21进行实验得到的均方根误差略小。实验结果表明,使用融合评论文本和评分数值综合评分模型会降低RMSE值,使推荐结果更加准确。
(2) 算法准确性实验对比。为验证本文算法是否提高了推荐结果的准确性,采用ALS算法在相同的数据集、正则化参数和迭代次数情况下,用均方根误差指标对以上两种算法的推荐效果进行对比。得到ALS算法的均方根误差值如表6所示,在正则化参数不变的情况下,随着迭代次数的变化两种算法的均方根误差值对比如图2所示。
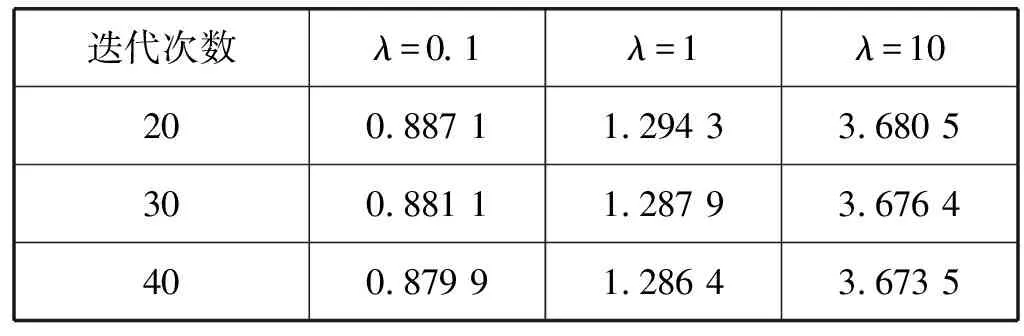
表6 ALS算法均方根误差
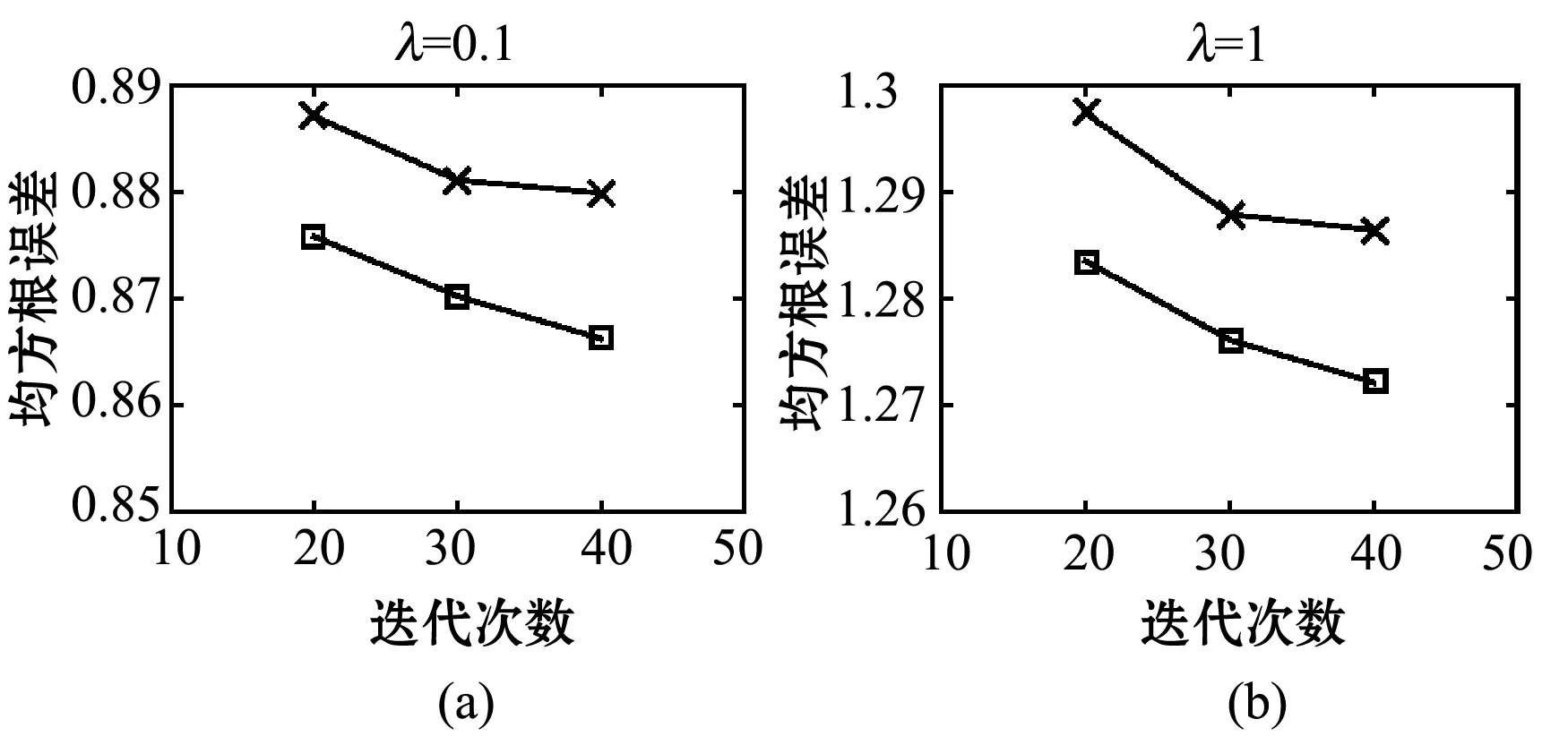
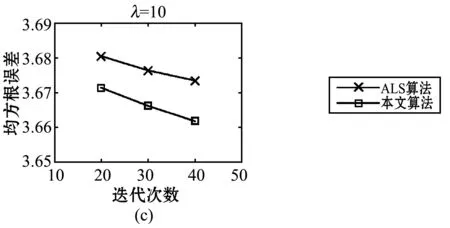
图2 RMSE值对比
结合表2、表6和图2可以发现,无论在迭代次数固定正则化参数增加,还是在正则化参数固定迭代次数增加的情况下,本文算法的RMSE值比ALS算法的值都有所减小。实验结果表明,本文算法与传统ALS算法相比降低了预测评分的均方根误差,提高了推荐系统的准确率,该算法用于个性化外卖推荐是可行和有效的。
5 结 语
本文提出了一种融合朴素贝叶斯和协同过滤的外卖推荐并行算法,该算法具有较高的准确性,能够较准确地对用户进行外卖推荐。同时,算法可以处理大规模的数据并且具有良好的加速比,有效地提升了协同过滤算法对于海量数据的处理能力。本文实现了对外卖信息的深度挖掘,推荐的信息对用户具有很高的参考价值。
推荐系统的一个目标是向用户推荐满足个性化要求的物品,而如果只以推荐准确度为目标进行推荐,将影响推荐系统的长期性能,导致长尾效应。所以下一步的研究重点是如何将本算法与其他推荐方法结合使用,提升推荐结果的多样性,从而构建以本文算法为核心的高效推荐算法。
猜你喜欢
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
小学生优秀作文(低年级)(2020年5期)2020-07-25
南通大学学报(医学版)(2020年3期)2020-06-30
飞天(2019年6期)2019-07-08
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
新高考·高二数学(2015年2期)2015-05-27
