
融合判别区域特征与标签传播的显著性目标检测
2019-11-11 01:08顾广华
燕山大学学报 2019年5期
王 明,崔 冬,李 刚,*,顾广华
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004)
0 引言
图像显著性检测就是将视觉系统中人眼感兴趣的区域准确地提取出来。近年来,随着计算机视觉领域的发展,显著性检测也得到了广泛的研究。显著性检测方法主要分为两种类型:自下而上的显著性检测和自上而下的显著性检测。前者由目标驱动,需要具体的先验知识。后者需要数据驱动,不需要任何先验知识。
早期的显著性检测研究大多通过生物启发模型来解决。Itti等[1]提出一种基于生物学启发的视觉模型的中心——周围环绕算子,来进行显著性检测。Zhai等[2]使用全局对比度来优化局部对比度中显著性区域不连续的问题,通过计算整个图像的全局对比度得到图像的显著性值。Li等[3]利用多尺度全卷积网络模型将高级语义信息和超像素特征结合起来,并用全连接条件随机场CRF[4]进行优化。Goferman等[5]根据局部对比度的不同并结合上下文区域的联系,得到最后的显著图。这些利用局部对比度的方法,一般会使图像边缘产生极大的显著值,而不能凸出显著的目标。Cheng等[6-7]提出了基于区域对比度的显著性检测算法,利用全局和局部对比度差异,结合图像上下文的特征对比,能够较完整地检测出显著目标,但计算效率较低。Yang等[8]根据流形排序方法计算图像边界和其他区域的相关性,由距离的远近判断相关性的大小得到每个区域的显著值。Li等[9]提出了一种基于标签传播(Label Propagation,LP)的显著性检测方法,这种方法能准确检测出前景区域,并在图片细节部分得到有效的保留,但是在复杂背景下,会影响到显著区域的检测。Liu等[10]提出在条件随机场框架中学习显著特征的线性融合权重。Wang等[11-12]提出了一种判别区域特征整合(Discriminative Regional Feature Integration,DRFI)方法,能自动整合高维区域显著特征并选择判别模型。这种方法可以有效地检测出图像的显著区域,并在复杂场景下有着良好的效果,但是存在较大的背景噪声。为了解决这一问题,本文采用一种指数融合函数[13],将判别区域特征图和标签传播显著图融合得到最终融合显著图。本文方法不仅抑制了背景噪声,还保留了图片细节信息,使得复杂场景下的显著图检测更加准确。
1 显著性检测方法
本文算法框图如图1所示。首先对图像进行预处理,利用简单线性迭代聚类算法(Simple Linear Iterative Clustering,SLIC)[14]对图片进行超像素分割,分割成N个区域,将分割的超像素块称为节点或区域;然后利用超像素的平均颜色特征计算相似度得到相似度矩阵,提取一部分边界超像素定义为背景标签,利用已得到的相似度矩阵和标记的背景区域通过标签传播方法检测未标记区域的显著性,得到标签传播显著图。同时,提取超像素的背景区域特征,通过随机森林进行训练得到回归模型,将特征映射为显著值,得到判别区域特征显著图。最后,通过指数函数将二者融合得到融合显著图。

图1 显著性目标检测算法框图
Fig.1 Salient object detection framework
1.1 判别区域特征显著图
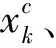
(1)

图像背景的识别取决于整个图像的上下文,具有相似外观的图像区域可能属于一张图片的背景却属于另外图片的前景区域,所以,提取伪背景区域并计算每个区域的背景描述符。伪背景区域Q定义为图像的宽度为15像素的窄边界区域。

(2)
除了区域对比之外,还考虑了区域的通用属性,区域背景先验描述器表示一个混合特征集,包括外观和几何特征。这两个特征是独立于每个区域提取的,如图像标注中的特征提取算法[15]。外观特征描述区域中颜色和纹理的分布,可以表征显著对象和背景的共同属性。最后,获得一个包括颜色、纹理、形状等35维的区域属性描述符。
将图像I的多层分割结果L=(L1,L2,…,LM)与相应的真值图进行匹配,得到超像素对应的标签,通过随机森林对图像特征向量与标签进行训练,得到回归模型a=f(X),从而将特征向量映射为显著值a。对于每个级别的显著图,将超像素区域的显著性值分配给其包含的像素,生成M级显著图(SA1,SA2,…,SAM),然后将它们融合在一起得到最终的显著图SA=g(SA1,SA2,…,SAM),其中g(·)是一个线性组合器,如式(3)所示:
(3)
ηm表示权重,通过最小二乘估计学习权重,使损失函数最小化。
1.2 标签传播显著图
通过任意两个超像素节点平均特征值的距离来定义两个超像素节点的相似性,相似度wij定义为
(4)
其中,i,j为两个超像素的序号,B为边界节点集合,bi和bj分别表示两个超像素的平均特征向量,ε为权值参数,Γ(i)表示超像素i的相邻区域的集合。

F=D-1·W,
(5)
得到相似度矩阵F之后,利用背景边界标签估计其他超像素区域的显著性值。给定一个数据集R={r1,…,rl,rl+1,…,rN}∈RΛ×N,前l个数据已经被标记,Λ是数据的特征维度,定义一个函数V=[Vr1,Vr2,…,VrN]T,使得V:R→[0,1]∈RN×1,相似度V(ri)满足:

(6)
其中,Fij是相似度矩阵F中的元素,t是递归步数,t初始值设为0。每一个超像素区域的显著值SB(ri)定义为
(7)
Alexe等[16]提出了一种类物体性(objectness)的概念,它是一种基于底层先验计算给定图像窗口的类物体性得分的方法,表示的含义是窗口中包含目标的可能性。这里使用多尺度显著性,颜色对比度,边缘密度作为先验。设Pu为第u个矩形框包含目标的概率值,像素p包含目标的概率值O(p)定义为
(8)

(9)
其中,ni表示超像素ri中包含的像素个数,超像素区域显著值SO(ri)定义为
(10)
最后,为了消除SLIC算法的分割误差,将像素级显著性Sp定义为其周围超像素区域显著性SB(ri)和SC(ri)的加权线性组合:

k2‖zp-zi‖)]SB/C(ri)
(11)
SC(ri)=αSB(ri)+βSO(ri),
(12)
其中,cp、ci、zp、zi是像素p和i的颜色和坐标向量,G表示超像素区域ri的直接邻居的数量,k1和k2是控制颜色和位置的参数,α和β分别为SB(ri)和SC(ri)的权重参数。
1.3 融合显著图
由上面模块可获得两个先验显著图:其中判别区域特征显著图可以更好地突出目标,同时会存在一些背景噪声;标签传播显著图可以更好地抑制背景噪声。二者能够互为补充,本文采用一种指数融合方法,融合两张先验显著图得到最终显著图
S=SA{1-exp(-λSp)}
(13)
其中,SA为判别区域特征显著图,Sp为标签传播显著图,λ为权值系数,将其设置为6。从图2中可以看出,融合后的显著图不仅准确地检测出了突出的显著目标,而且有效地抑制了背景噪声。

图2 融合显著图与初始显著图的对比
Fig.2 Contrast between the fusion saliency map and the initial saliency map
2 实验结果分析
本文在两个公开数据集MSRA-1000和DUT-OMRON上进行了实验。MSRA-1000数据集包含1 000张图片,图片目标相对简单,目标较为单一。DUT-OMRON数据集包含5 166张图片,图片数量较多,背景更加复杂,具有一定难度。两个数据库都具有相应人工标注的真值图。
为了更好评估算法的优越性,本文利用准确率、召回率和F-measure柱状图来衡量检测效果。首先采用固定阈值分割的方法计算准确率-召回率(P-R)曲线图,将待检测的显著图量化至[0,255],设定阈值对显著图进行二值化,将二值化的结果同真值图进行对比,得到待测图像的准确率和召回率,根据这些结果,画出P-R曲线图。另外,通过自适应阈值进一步评测显著结果,将阈值设为显著图像素均值的二倍。经过二值分割后,将得到所有图片的平均准确率和召回率,F-measure值计算式为
(14)
式中,P为准确率,R为召回率,根据实验经验,本文设μ2=0.3。
为了验证本文方法的有效性和可靠性,本文方法与其他6种显著性算法进行比较,分别是LPS算法[9]、DRFI算法[11]、BFS算法[13]、BM算法[17]、SF算法[18]、GR算法[19]。比较结果如图3所示。

图3 MSRA-1000中7种算法的显著图对比
Fig.3 Comparison of seven algorithm saliency maps in MSRA-1000
图3为7种算法在MSRA-1000数据库中部分图片显著图,MSRA-1000数据库目标较为单一,对于显著性检测相对简单。从对比图中可以看出SF方法和BFS方法没有完整有效地突出显著目标,效果比较模糊。GR方法和LPS方法可以清楚地看出显著目标,但是轮廓不够清晰。BM方法和DRFI方法能够突出显著目标,但背景噪声较大。本文方法能将显著目标很好凸显出来,并有效抑制了背景区域。
图4为7种算法在DUT-OMRON数据库中部分图片显著图,DUT-OMRON数据库具有更大的挑战性。从图4可以看出,SF方法、GR方法、BFS方法和LPS方法的显著区域凸出不明显,检测结果较为模糊,BM方法和DRFI方法存在较大的背景噪声,本文方法的检测结果更加准确,也说明了本文方法在复杂背景下有着良好的效果。
图5是7种算法在MSRA-1000数据库上的准确率-召回率曲线图。由图5可知,BM算法、SF算法、LPS算法和BFS算法的准确率和召回率偏低,因为SF算法和LPS算法检测到的显著区域不明显,显著目标不够突出。BM算法和BFS算法虽然能检测出显著区域,但是包含了大量的背景噪声。DRFI算法的P-R曲线较高,显著目标突出,但是有较大的背景干扰。本文算法显著目标突出,背景干扰较小,从图5中可以看出,本文算法效果要优于其他算法。

图4 DUT-OMRON中7种算法显著图对比
Fig.4 Comparison of seven algorithm saliency maps in DUT-OMRON

图5 7种算法在MSRA-1000数据库上的P-R曲线图
Fig.5 P-R Curves of the seven algorithms on the MSRA-1000 database
图6展示了7种算法的准确率、召回率和F-measure值。从图6中可以看出结果较好的是GR算法,LPS算法,DRFI算法和本文算法。本文算法准确率、召回率及F-measure值均优于LPS算法;GR算法准确率与本文算法持平,但其召回率与F-measure值低于本文算法;虽然DRFI算法召回率高于本文算法,但其准确率与F-measure值低于本文算法。本文算法的准确率为0.928 4,召回率为0.893 6,F-measure值为0.920 1,由图6中可以看出本文算法的F-measure值要优于其他6种算法,充分体现了本文算法的有效性。
图7是7种算法在DUT-OMRON数据库上的准确率-召回率曲线图。与MSRA-1000数据库相比,DUT-OMRON数据库的图片更加复杂,并且数量更多。从图7可以看出,当召回率低于0.9时,本文的准确率要高于其他算法,当召回率高于0.9时,本文算法准确率低于DRFI算法。

图6 7种算法在MSRA-1000数据库上的性能对比
Fig.6 Performance comparison of the seven algorithms on MSRA-1000 database
图8是7种算法在DUT-OMRON数据库上的准确率、召回率和F-measure值。图8中本文算法的F-measure值是最高的,达到了0.622 6,F-measure值有较大优势。本文算法的准确率仅低于GR算法,高于其他5种算法。本文算法召回率低于DRFI算法,但是高于其他5种算法。虽然本文算法的准确率与召回率都不是最好的,但是F-measure值最高,整体上说明了本文算法的有效性。

图7 7种算法在DUT-OMRON数据库上的P-R曲线图
Fig.7 P-R curves of the seven algorithms on the DUT-OMRON database
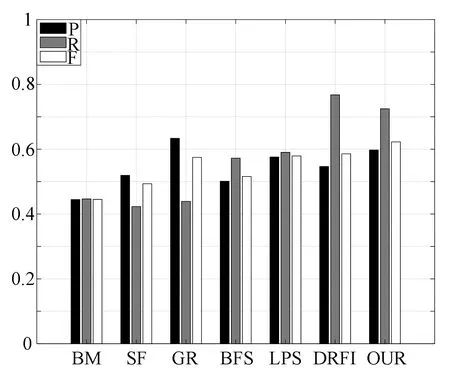
图8 7种算法在DUT-OMRON数据库上的性能对比
Fig.8 Performance comparison of the seven algorithms on DUT-OMRON database
3 总结
本文提出了一种融合判别区域特征和标签传播的显著性目标检测方法,判别区域特征充分考虑了区域之间的对比度、背景和特征属性,而标签传播则倾向于邻居之间的传播和优化,本文结合了区域对比和标签传播的优势,融合二者得到最终显著图。实验结果表明,本文算法与其他方法相比,既有效的抑制了背景,又突出了显著区域,整体性能优于其他显著性目标算法。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年7期)2021-11-17
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年24期)2019-02-23
中国知识产权(2018年12期)2018-12-29
