
基于RGB-D的肉牛图像全卷积网络语义分割优化
2019-11-08 00:57邓寒冰周云成许童羽
农业工程学报 2019年18期
邓寒冰,周云成,许童羽,苗 腾,3,徐 静
基于RGB-D的肉牛图像全卷积网络语义分割优化
邓寒冰1,2,周云成1,2※,许童羽1,2,苗 腾1,2,3,徐 静1,2
(1. 沈阳农业大学信息与电气工程学院,沈阳 110866;2. 辽宁省农业信息化工程技术研究中心,沈阳 110866;3. 北京农业信息技术研究中心,北京 100097)
基于卷积神经网络的深度学习模型已越来越多的应用于检测肉牛行为。利用卷积操作实现肉牛图像的像素级分割有助于实现远距离、无接触、自动化的检测肉牛行为,为肉牛异常行为早期发现提供必要手段。为了提高复杂背景下肉牛图像语义分割精度,降低上采样过程中的语义分割误差,该文提出基于RGB-D的肉牛图像全卷积网络(fully convolutional networks, FCN)的语义分割优化方法,用深度密度值来量化深度图像中不同像素点是否属于相同类型的概率,并根据深度图像与彩色图像在内容上的互补关系,优化和提升FCN对肉牛图像的语义分割(像素密集预测)精度。通过试验验证,该方法与全卷积网络的最优分割结果相比,可以将统计像素准确率平均提高2.5%,类别平均准确率平均提升2.3%,平均区域重合度平均提升3.4%,频率加权区域重合度平均提升2.7%。试验证明,该方法可以提升全卷积网络模型在复杂背景下肉牛图像语义分割精度。
图像处理;模型;动物;语义分割;RGB-D;全卷积网络;多模态;肉牛图像
0 引 言
随着图像传感设备成本的不断降低,目前在畜牧养殖过程中已经逐步实现了全时段监控,特别是对动物全生命周期的行为监控和行为分析已经成为畜牧养殖业的一个研究热点。人们在获取大量动物图像和视频信息的同时,更关心如何实现对这些图像信息的处理、分析、理解和应用[1];如何将动态的目标对象从复杂环境背景中分割出来,这是进行动物行为分析的前提条件,同时也是实现远距离、无接触、自动化检测动物行为的关键。
计算机视觉领域中的传统分割方法是通过人工提取图像特征来实现像素的聚类和提取,当图像背景复杂时,特征提取将变得非常麻烦甚至难以实现[2]。而随着深层卷积神经网络技术的发展,一种“端到端”的概念被引入到计算机视觉中来。让计算机自动在每个特定类别对象中学习和寻找最具描述性、最突出的特征,让深层网络去发现各种类型图像中的潜在模式[3]。在大量标注数据的基础上,通过不断的训练来自动提高卷积神经网络的分类、分割、识别、检测等处理的精度,将人工成本从算法设计转移到数据获取,降低了技术应用难度[4]。
在农业领域,基于卷积神经网络的计算机视觉技术已经逐渐成为主流研究方向。例如植物关键器官识别[5-8],虫害个体识别[9-11],植物病害分级[12-13],利用多层卷积操作可以在不同尺度自动抽取图像特征,最后通过特征抽象可以获得目标位置和目标类型;针对家禽、水产等动物的视频图像处理方面,利用深层卷积网络可以实现针对动物个体轮廓提取、特征标定、行为轨迹追踪等[14-18]。然而,由于卷积神经网络中浅层的卷积感知域较小,只能学习到一些局部区域的特征;而深层的卷积层具有较大的感知域,对物体的大小、位置和方向等敏感性更低,有助于实现分类,但是因为丢失了物体的一些细节,不能指出每个像素具体属于哪个物体,很难做到精确的分割,不能够准确的给出目标对象的清晰边界信息[19-22]。而为了实现精准的像素分类,通常是以卷积过程中卷积核中心位置像素为基准点,通过判断该点周围区域像素组成的图像类别来预测该基准点的目标类别。然而,当卷积核区域不能覆盖一个完整对象时,预测精度会明显下降,而增大卷积核区域会造成运算过程中存储量的增加和计算效率的降低。为此,Evan等提出了全卷积网络(fully convolutional networks,FCN)用于图像分割[23],该网络从抽象的特征中恢复出每个像素所属的类别,与传统用CNN进行图像分割的方法相比,该网络采用的是全卷积连接的结构,卷积过程共享感知区域,因此可以避免重复计算并提高卷积操作效率。
然而对于肉牛图像分割问题,由于肉牛所处的养殖环境复杂,图像中环境信息的颜色和纹理等会对肉牛形体细节部位的分割产生影响。特别是FCN在上采样过程中使用反卷积操作,对于图像中细节信息不敏感,没有考虑像素间的类别关系,使分割结果缺乏空间规整性和空间一致性[24],这样得到的分割效果会非常粗糙。为了提高全卷积网络语义分割的精度,改善肉牛图像细节部位的分割效果,本文提出了基于RGB-D肉牛图像全卷积网络语义分割优化方法,定义了深度密度概念,利用深度密度值来量化深度图像中不同像素点是否属于相同类型的概率,并根据深度图像与彩色图像在像素内容上的映射关系,优化全卷积网络对肉牛图像的语义分割结果,提升分割的精度。
1 材料与方法
1.1 试验材料和准备工作
试验数据采集自辽宁省沈阳市北部地区肉牛养殖中心,肉牛品种为西门塔尔肉牛。为了增加样本多样性,试验在5月、8月和10月,分别于上午(8:00-10:00)、中午(11:00-13:00)和下午(14:00-16:00)在室内和室外获取肉牛图像信息。采集设备为Kinect Sensor(2.0版本),可以同步获取分辨率为1 920像素×1 080像素的彩色图像(RGB)和分辨率为512像素×424像素的深度图像(Depth)。由于Kinect设备通过设备本身发出的结构光来计算物体的距离信息,所以在室外采集的深度图像存在较大的噪声,因此在室外采集过程中,只使用获取到的RGB图像(用于分类网络训练);而室内采集的肉牛图像,由于外部光线可控,因此深度信息比较准确,可用于分割优化使用。在数据获取过程中,Kinect设备位置固定,与拍摄对象(肉牛)保持0.5~4.5m距离,被拍摄对象在该范围可以自主活动。具体环境布局如图1所示。
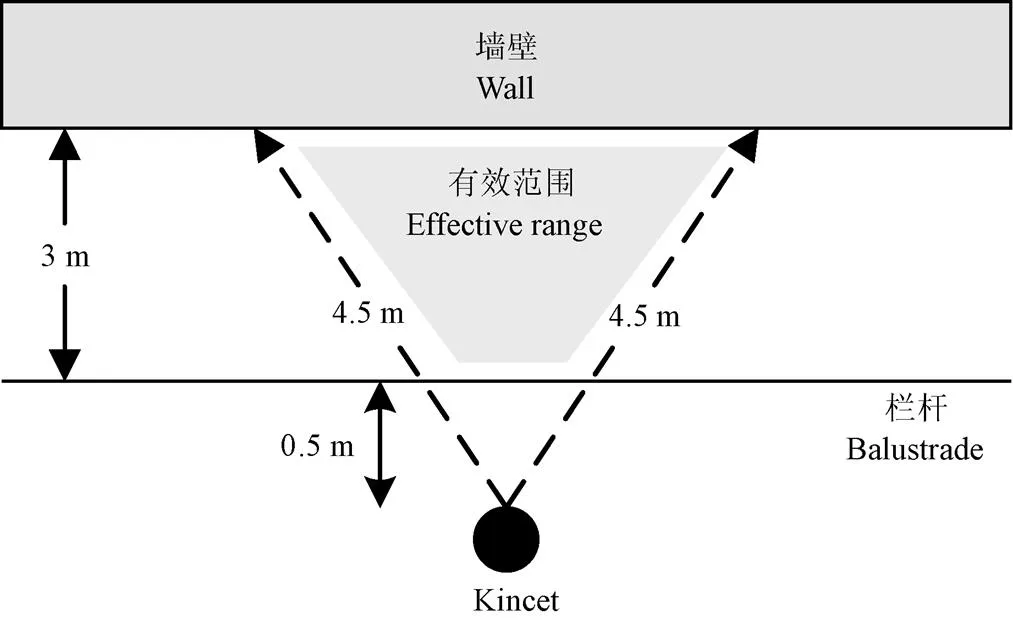
图1 试验环境布局图
本试验选取的肉牛数量约为70头(室内30头,室外40头),从Kinect视频流等间隔(5张/s)抽取RGB图像和深度图像,而且RGB图像和深度图像在时间轨迹上是同步的。将彩色图像通过人工加标注的方式形成4种用途的样本:用于分类网络训练,用于分类网络测试,用于分割网络训练和用于分割网络测试。在设定样本尺寸以及样本数量时,考虑到全卷积网络中不存在全连接层,因此可以实现对任意尺寸图片的处理。因此,本文利用可以将试验中用到的RGB图像和深度图像的尺寸统一到512像素×424像素。为了增加样本多样性,分别于不同日期的上午、中午、下午3个时间段中各选取2 000张图像作为分类网络的训练样本(共6 000张),500张图像作为分类网络的测试样本(共1 500张);与此同时,在上述3个时间中,从室内采集的样本中选取1 000张分割网络的训练样本,200张分割网络的测试样本。而深度图像是通过将Kinect获取的物体深度信息进行可视化表示后的效果图,即将可视范围内的深度值转换为灰度值,灰度归一化后范围是[0,1],在后文中会利用深度图像计算每个像素点的深度密度,利用深度密度值来优化FCN语义分割结果。
本文后面章节将介绍如何设计试验和实现相关方法,具体包括3个主要过程,如图2所示。

图2 主要方法流程图
1)利用分类样本集和分割样本集分别对基础分类网络和全卷积网络进行训练,其中基础分类网络的参数可以用于初始化全卷积网络,以加速训练过程中损失函数收敛;FCN的输出特征图可以通过上采样得到初步的分割结果。
2)提出深度密度概念并给出深度密度计算方法,通过深度图像中每个像素点的深度密度,可以量化该像素点与周围空间其他像素点属于同一类别的概率。
3)利用深度密度值对分割结果中细节部位(例如边缘部位)进行调优,得到最终优化后的分割结果。
1.2 基础网络构建与训练
建立深层分类网络是解决逐像素预测问题和语义分割问题的基础,而VGG系列网络在0~100类左右的分类问题上,其分类精度与Inception系列、ResNet系列等分类网络非常接近,而且VGG网络结构相对简单,没有Inception和ResNet网络结构中的用于优化训练的分支结构,因此更容易改造为全卷积网络,因此本文选择VGG-19[25]作为分类网络的基本模型。VGG系列网络在ILSVRC2014(ImageNet[26]Large-Scale Visual Recognition Challenge)上首次提出,其网络结构参考了AlexNet[27]。由于全卷积分割网络是在分类网络的基础上建立的,两类网络在多个卷积层上是权值共享的,因此对分类网络进行预训练可以简化分割网络的训练过程,并且对分割精度有明显提升。此外,为了防止数据量不够而导致的过拟合问题,在训练分类网络的过程中加入了ILSVRC2016部分数据集,其中选择与试验场景相似的150类图片,形成了151类的数据集合。
在训练VGG-19方面,本文采用与文献[25]相同的训练方法。由于分类网络与全卷积分割网络在卷积层是共享权值的,因此在训练全卷积分割网络之前,对分类网络进行训练会提高分割网络的分割精度,同时缩短分割网络的训练时间。图3a给出了VGG-19训练过程中的损失函数的变化趋势图。由于本文使用的数据集规模要远小于ImageNet[28],因此在经历次80 000次batch迭代后,损失值已经在(0,0.05)之间,而平均分类精度可以达到0.9以上,已经基本达到了分类要求。同时基于同样的数据集和训练方法对AlexNet进行训练,训练结果如图3b所示。而相比AlexNet而言,虽然VGG-19层数更多,但是由于卷积核更小,因此网络收敛过程更加平稳,没有出现AlexNet在训练后期出现的loss值跳变的情况。所得到的VGG-19分类网络模型可以作为后文中全卷积网络的基础网络模型。
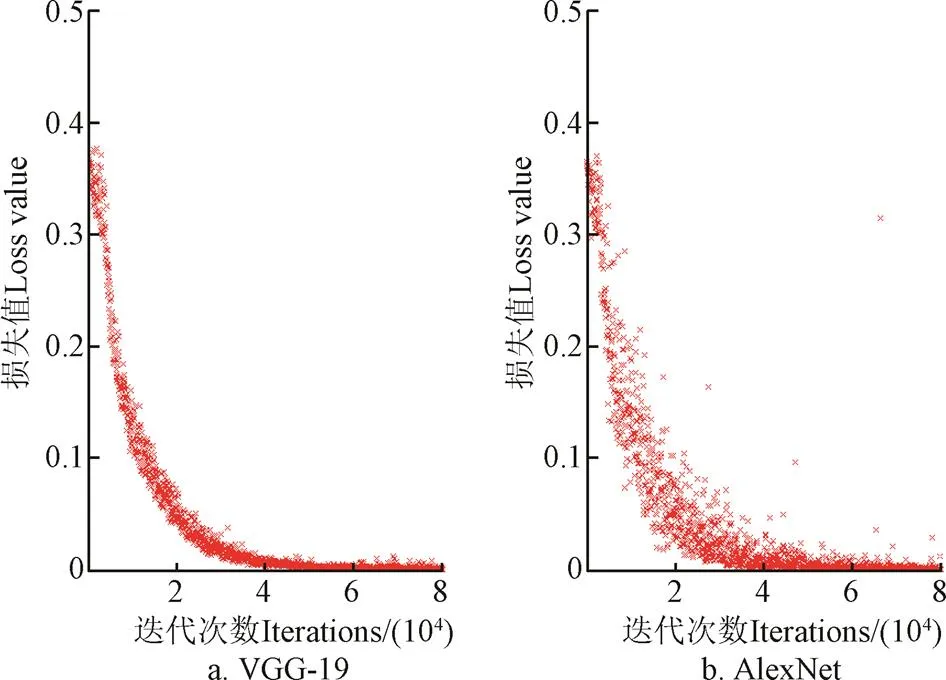
图3 VGG-19和AlexNet训练过程中的loss值
1.3 全卷积网络构建
VGG-19只能通过输出的特征向量来判定图像的具体类别,整个过程丢失大量的像素信息,无法实现像素级别的分类。全卷积网络(fully convolutional networks,FCN)以分类卷积神经网络为基础,将分类网络中的全连接层转换为卷积层,以保留输入图像的二维信息;对输出的特征图进行上采样操作,使其恢复到原始图像的尺寸,最后通过逐个像素分类获取每个像素的类别,从而实现对全图像的语义分割。本文中的全卷积网络的结构如图4所示,其中、分别表示初始图像的高和宽,表示通道数或维度。
FCN是基于VGG-19建立的,每层池化操作可以使图片缩小一半,将VGG-19中的全连接层全部换成卷积层,卷积核的大小为1×1,通道数保持不变,这样就可以保留特征图的二维空间属性,最终可以获得与类别数相等的热图(图4中FC19)。热图的尺寸在经历过5次池化过程后,变成原图像大小的1/32(如图4中FC17、FC18和FC19)。为了实现端到端的语义分割,需要将热图进行32倍的上采样操作,以获取与原图像尺寸相等的语义分割结果。

注:C表示卷积层,FC表示卷积核为1×1的全卷积层;H表示输入图像的高度值,W表示输入图像的宽度值,D表示输入图像和输出的特征图通道数。全卷积网络最后输出的特征图(热图)可以通过上采样操作获得与输入图像具有相同尺寸的语义分割结果。
1.4 基于全卷积网络的上采样操作
上采样(up-sample)是池化操作的逆过程,上采样后数据数量会增多。在计算机视觉领域,常用的上采样方法有3种:1)双线性插值[29](bilinear):这种方法特点是不需要进行学习,运行速度快,操作简单;2)反卷积[30](deconvolution),利用转置卷积核的方法,对卷积核进行180°翻转;3)反池化[31](depooling),在池化过程中记录坐标位置,然后根据之前坐标将元素填写进去,其他位置补0。
与文献[23]中的上采样过程不同,为了提高上采样操作的精度,本文对于2倍尺寸的上采样操作选择双线性插值法,对于大于2倍尺寸的上采样操作选择反卷积法。对于双线性插值法,设原始特征图的尺寸为×,双线性插值法首先将原始特征图的尺寸变为(2+1)×(2+1),然后利用2×2的卷积核对新特征图进行valid模式的卷积操作,最终获得尺寸为2×2的新特征图;而对于反卷积法,设原始尺寸为×,利用×的卷积核对特征图进行full模式的卷积操作,最终可以获得尺寸为(+-1)×(+-1)的新特征图。
因为VGG-19中有5次池化操作,每经过一次池化操作,特征图的尺寸都变为原尺寸的1/2。本文分别将每次池化后得到的特征图命名为p1、p2、p3、p4和p5。如图5所示,输入图像的尺寸为·,经过5次池化操作后p5的尺寸变为(/32)·(/32)。而p1~p5都可以作为本文上采样的输入特征图,参照输入图像的尺寸,分别恢复到对应特征图的2倍、4倍、8倍、16倍和32倍。本文沿用文献[26]中的名称,称这些结果为FCN-2s、FCN-4s、FCN-8s、FCN-16s和FCN-32s。(图5中只给出了FCN-8s、FCN-16s和FCN-32s的上采样过程)。为了解释计算过程,本文设输入图像的尺寸为32×32像素,VGG-19网络中卷积操作不改变该阶段输入图像或特征图的大小,则p1的尺寸为16×16像素,p2的尺寸为8×8像素,p3的尺寸为4×4像素,p4的尺寸为2×2像素,p5的尺寸为1×1像素。FCN最后的3个全卷积层的卷积操作(1×1的卷积核)不会改变特征图的二维空间属性,因此输出的特征图尺寸仍与p5相等,为1×1像素,而且通道数与分类数(Number of classes)相等。
1)对于FCN-32s,热图的大小为1Í1,FCN-32s是由热图直接通过32倍的反卷积操作还原成32Í32的尺寸。即用=32的卷积核对=1的特征图进行反卷积处理,输出的分割图为32Í32(+‒1=32)。
2)对于FCN-16s,对热图进行1次双线性插值操作,将热图的宽和高分别增大2倍,然后与p4相加,最后将相加的结果进行16倍的反卷积操作(=31,=2),可以获得与原图像相同尺寸的图像。
3)对于FCN-8s,对热图进行2次双线性插值操作,使热图的宽和高分别增大4倍;然后对p4进行1次双线性插值操作,即将p4的宽和高分别增大2倍;最后将增大后的热图、p4与p3相加,对相加的结果进行8倍的反卷积操作(=29,=4),可以获得与原图像相同尺寸的图像。
从结构上看,仍旧可以针对p1和p2的结果进行上采样处理,分别得到FCN-2s和FCN-4s,但是根据文献[23]的结果显示在8倍上采样之后,优化效果已经不明显。因此,本文选择可以生成FCN-8s的全卷积网络作为语义分割的基础网络,但是上采样操作将热图中的分类像素点还原到原输入图像的尺寸,该过程存在较大的像素分类误差,即像素的错误分类以及像素丢失,而基于深度密度的图像分割优化方法可以用于优化该网络的语义分割结果。
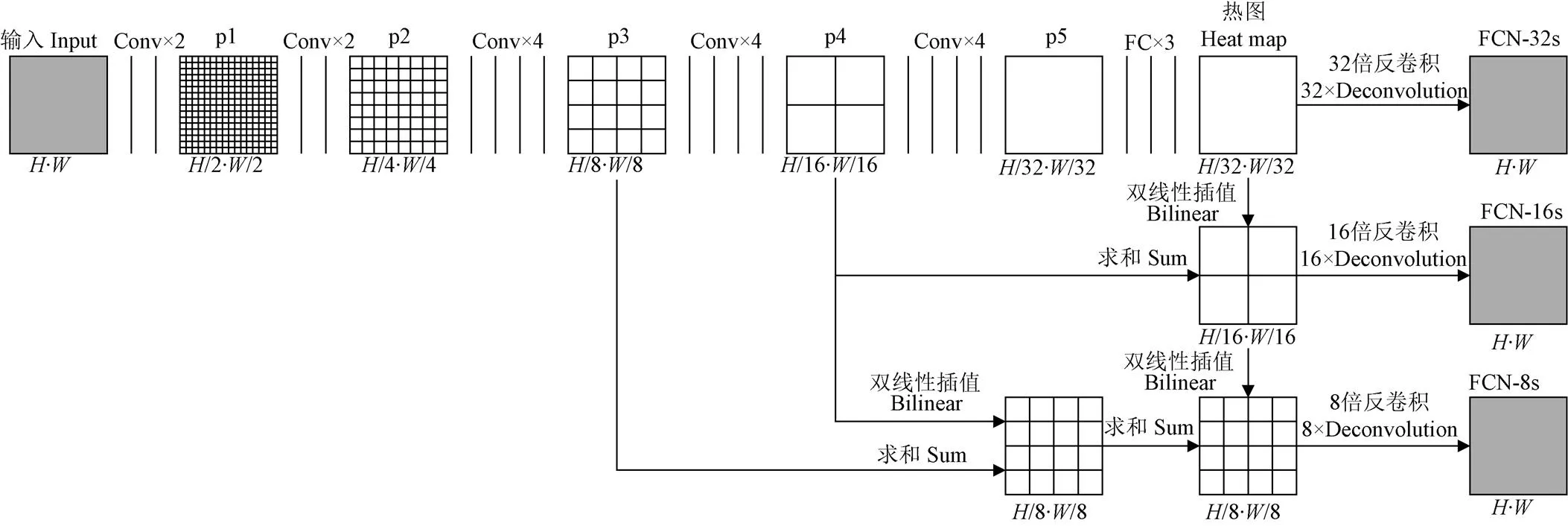
图5 全卷积网络的上采样操作
2 基于深度密度的图像分割优化
2.1 深度图像分析
深度图像中每个像素值表示空间中该点的位置与摄像头的空间距离,因此深度图像可以很好的描述复杂环境中肉牛的的轮廓信息(如图6a所示),而深度图像与RGB图像的像素之间存在内容上的映射关系(如图6b)。在试验中,每张用于语义分割的RGB图像有与其对应的、具有相同尺寸的深度图像,而且通过Kinect2.0的软件处理,可以实现RGB图像与深度图像在内容上的近似映射。

图6 Kinect获取的肉牛图像
从深度图像上可以看出,同一物体的细节信息可以通过连续变化的深度值表示出来,特别是对于同一目标来说,深度值一般是连续的,而相邻不同物体间的边界信息会出现深度值的跳变。通过统计可以发现,在同一张图片上,深度值相近的像素点在空间上有较大概率是是临近的,而且深度图像中属于同一物体并且在空间上连续的像素点,一般具有连续的灰度值区间。利用深度图像上的这一特点,本文提出了深度密度(depth density)的概念。
2.2 深度密度定义
设深度图像的尺寸为×,其中为图像的行数,为图像的列数;(,)为深度图像上点(,)的深度值(由灰度表示);(,)表示图像上点(,)对应的深度密度值,其表达式由公式(1)所示。

为了计算相似度,本文首先给出几个参数定义:

式中为深度密度计算过程中区域边长。
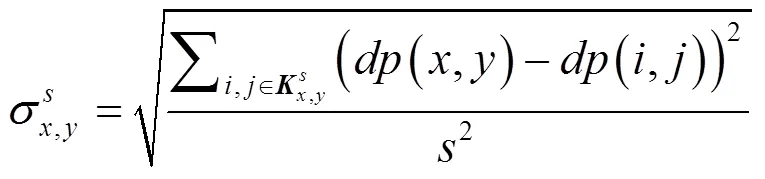
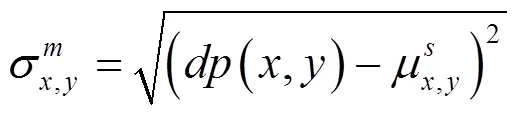

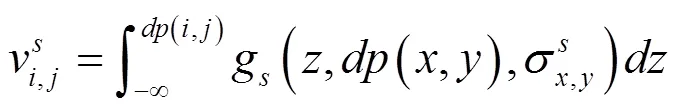


这样,利用公式(8)就可以计算像素点(,)的深度密度值,即
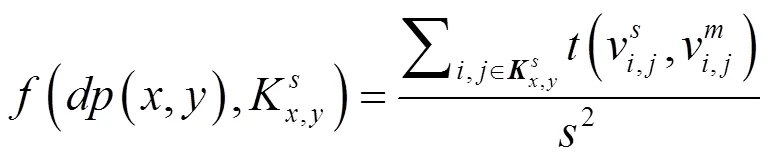
利用该公式计算得到的深度密度(,)的取值区间为(0,1]。其中,深度密度值越接近于0表示该点与该区域的整体深度值分布情况差异很大,则该点属于深度图中的边界像素或者噪声像素的概率较高;深度密度值越接近于1表示该点与该区域的整体深度值分布差异较小,则该像素点位于物体表面的几率较大。这就证明了如果一个像素点的深度密度接近于1,则该点有很大概率与其周围×范围内的像素点属于同一物体。基于这一原理可以对全卷积的分割结果进行优化。图7给出了=7时的深度密度图,其中图7a是肉牛的深度图像,图7b是深度图像通过计算深度密度计算后获取的深度密度图像。在深度密度图中,像素点的灰度值表示深度密度值,深度密度值越接近与1(白色),表示该像素点与周围像素点深度值差别越小,而深度密度值越接近于0(黑色),表示该像素点与周围像素点深度值差别越大,或该像素点在原深度图像中为无效小像素点。肉牛边缘处由于深度值变化明显、噪声多,因此边缘位置像素的深度密度值较低,而肉牛躯体部分由于深度值分布平滑,因此该位置深度密度值较高。

注:s为深度密度计算过程中K区域边长。
3 试验结果分析

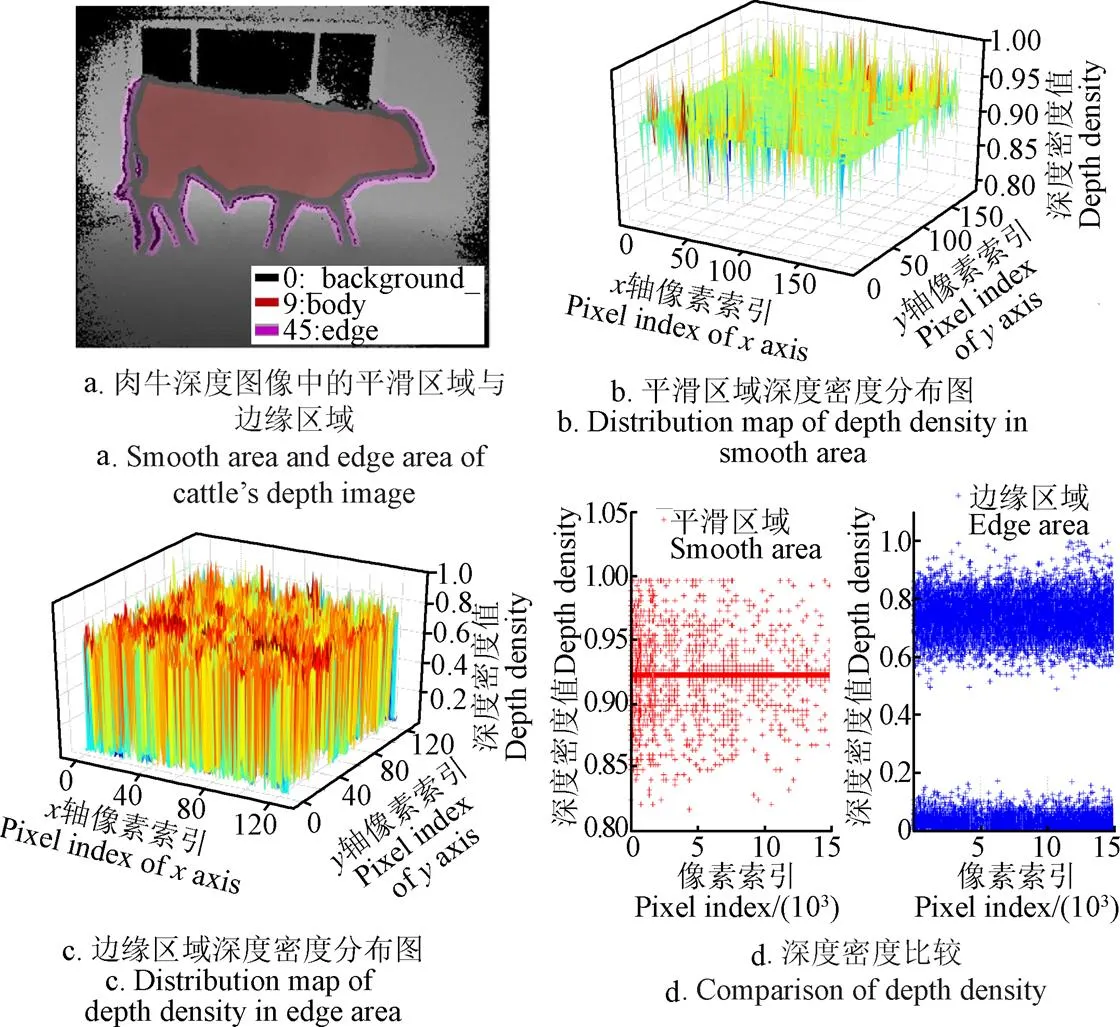
图8 平滑区域与边缘区域深度密度表示与对比
如图8a所示,在同一深度图中截取2类区域,其中红色区域(标注9)表示深度图像中的深度平滑区域,粉色区域(标注45)表示深度图像中深度边缘区域。通过像素映射找到2类区域对应的深度密度值,对这两个区域的深度密度进行分析。图8展示了=7值条件下深度平滑区域的深度密度分布情况。其中图8b表示深度图像中平滑区域(图8a中红色区域)的深度密度值,该区域图的深度密度值普遍分布在[0.8, 1]区间,这表明该区域所在的像素点与其周围像素点的深度差非常小;而图8c表示深度图像中边缘区域(图8a中粉色区域),从图中可见,该区域深度密度值在[0, 0.8]区间反复震荡,这是由于深度图边缘区域深度值变化很大,同时Kinect采集的深度图像在物体边缘区域存在大量“黑色”噪点,因此边缘的深度密度值会更接近于0边缘区域也是产生噪声的主要区域,因此深度密度变化剧烈。图8d给出了平滑区域与边缘区域深度密度值的比较结果,其中分别在每个区域选取15 000个像素点进行比较,其中红色点表示平滑区域的深度密度值,蓝色点表示边缘区域深度密度值,从图中可以明显看到平滑区域像素点主要分布在[0.8,1]区间,而边缘区域虽然有些像素点的深度密度值也能达到0.8,但那是由于在深度图像中截取边缘区域时附带的平滑区域像素点造成的。

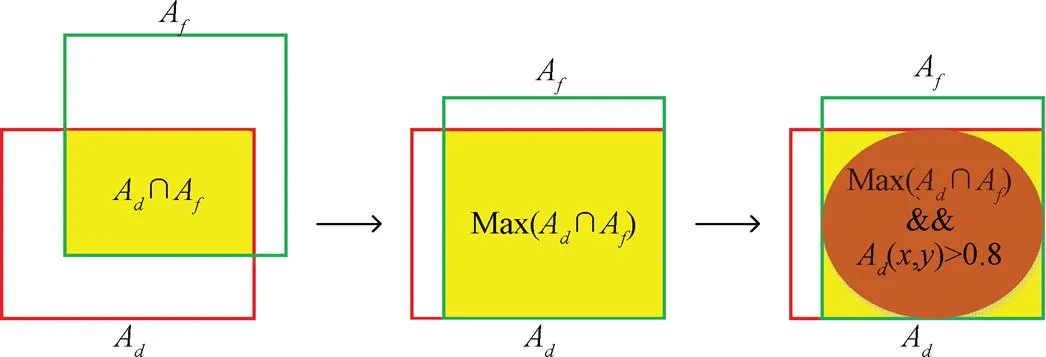
注:Ad表示深度密度图像中的有边缘信息的对象区域,Af为FCN-8s结果中的分割区域。
对于结果分析,本文选用4种通用的语义分割和场景解析的度量评价标准,用于评价像素精度和区域重合度,包括:统计像素准确率(pixel accuracy,pa)、类别平均准确率(mean accuracy,ma)、平均区域重合度(mean intersection over union,mIU)和频率加权区域重合度(frequency weight intersection over union,fwIU)。4种评价标准的取值范围在0到1之间,值越接近于1表示分割精度越高。具体定义如下:





为了避免对单一类别(肉牛)训练网络而造成的过拟合问题,本文将肉牛的训练数据与NYUDv2数据集[32](40个类别)混合使用,其中NYUDv2是用Kinect设备采集并整理得到的一个公开RGB-D数据集合,该数据集中有1 449张RGB-D图像,同时包含40个类的语义分割标签。利用NYUD2v数据集,本文对FCN网络的8倍上采样语义分割结果(FCN-8s),以及RGBD图像语义分割结果(D-FCN-8s)在4种语义分割度量评价标准下进行精度比较。具体结果如表1所示。

表1 在NYUDv2数据集上的语义分割比较
注:FCN-8s表示全卷积网络通过8倍上采样而获得的语义分割结果。D-FCN-8s表示基于深度密度的全卷积网络通过8倍上采样而获得的语义分割结果。NYUDv2+1表示在原NYUDv2数据集上添加1个新类别(肉牛)后形成的数据集(共41种类别)。NYUDv2-20+1和NYUDv2-10+1同上。
Note: FCN-8s denotes the semantics segmentation result of fully convolutional networks by ‘8×’ up-sampling. D-FCN-8s denotes the semantics segmentation results of fully convolutional networks based on depth density by ‘8×’ up-sampling. NYUDv2+1 represents the data set (41 categories) formed by adding a new category (cattle) to the original NYUDv2 data set. NYUDv2-20+1 and NYUDv2-10+1 are the same with NYUDv2-40.
经过对比发现,当数据集类别减少时(41类、21类、11类),FCN-8s和D-FCN-8s在分割精度上都有一定的提升,这是因为全卷积网络的基础分类网络参数较多,而随着数据集类别的减少,网络训练过程出现了轻微的过拟合趋势。此外,使用RGBD图像进行语义分割时,通过判断深度图像中每个像素点的深度密度值是否操作特定阈值,可以区分该像素点是否处于肉牛边缘像素或肉牛躯体平滑区域,进而提高全卷积网络对RGB图像上采样语义分割的像素分类精度。参照表1中D-FCN-8s和FCN-8s对应的统计像素准确率(pa)、类平均准确率(ma)、平均区域重合度(mIU)和频率加权区域重合度(fwIU)的4组值,分别求得D-FCN-8s和FCN-8s在不同数据集(NYUDv2+1、NYUDv2-20+1和NYUDv2-10+1)下的精度差,最后可以求得平均精度差值(Average precision difference, APD),如表2所示,精度差值D-FCN-8s在统计像素准确率、类别平均准确率、平均区域重合度和频率加权区域重合度4种指标上比FCN-8s分别提高了2.5%、2.3%、3.4%和2.7%(表2中最后一列)。
为了验证该方法在FCN系列网络中的有效性,本文对原FCN的模型进行了改良,参照了文献[33]和文献[34]中的方案,在FCN结构后面加入了全连接条件随机场(conditional random fields, CRF)和马尔科夫随机场(Markov random fields, MRF),其中全连接条件随机场能够建立像素之间的全连接距离关系,而距离值与颜色和实际相对距离相关,这可以让该网络在语义分割过程中让图像尽量在边界处分割。而马尔科夫随机场对原CRF中的二元势函数进行了修改,加入了惩罚因子,能够更加充分的运用局部上下文信息产生分割结果。表3中给出了4种分割方案在4种通用的语义分割度量评价标准下的比较情况,其中CRF-FCN-8s是加入全连接条件随机场得到的语义分割结果,MRF-FCN-8s是加入马尔科夫随机场得到的语义分割结果。结果表明,即时对原FCN网络进行改造,其各项指标也比深度密度对FCN-8s优化后的各项指标差,这是由于深度密度也采用了局部像素关联的方式来对具体像素点进行深度区域分类,而CRF和MRF虽然也是采用了距离关联方式,但是其关联关系的精度要低于深度图像中深度关联的精度,因此采用深度密度方法会得到更好的分割结果。这表明深度密度可以用于优化全卷积神经网络的语义分割结果,能够提升语义分割精度。图10分别给出FCN-8s以及为优化后的D-FCN-8s与真值的对比效果图,其中FCN-8s的分割细节部分明显不如D-FCN-8s,而利用深度密度得到的分割结果非常接近与真值图。
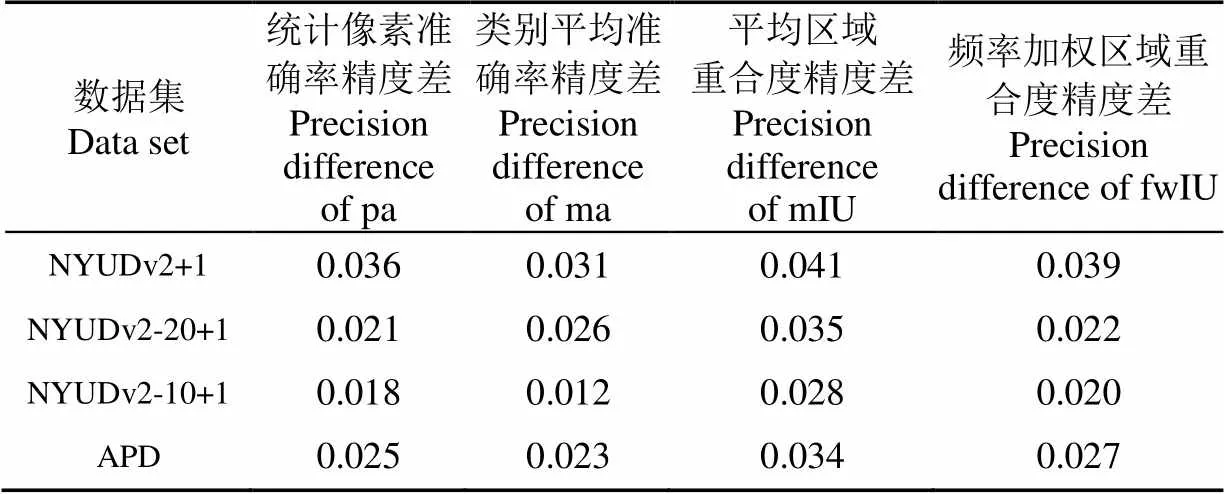
表2 FCN-8s与D-FCN-8s在3类数据集上的平均精度差
注:平均精度差(APD)的计算公式为,APD(average precision difference) = ((NYUDv2+1)X+(NYUDv2-20+1)X+(NYUDv2-10+1)X)/3,其中X∈{pa, ma, mIU, fwIU}.
Note: Formula for calculating the average accuracy difference is as follows, APD (Average Precision Difference)=((NYUDv2+1)X+(NYUDv2-20+1)X+ (NYUDv2-10+1)X)/3, where X∈{pa, ma, mIU, fwIU}.
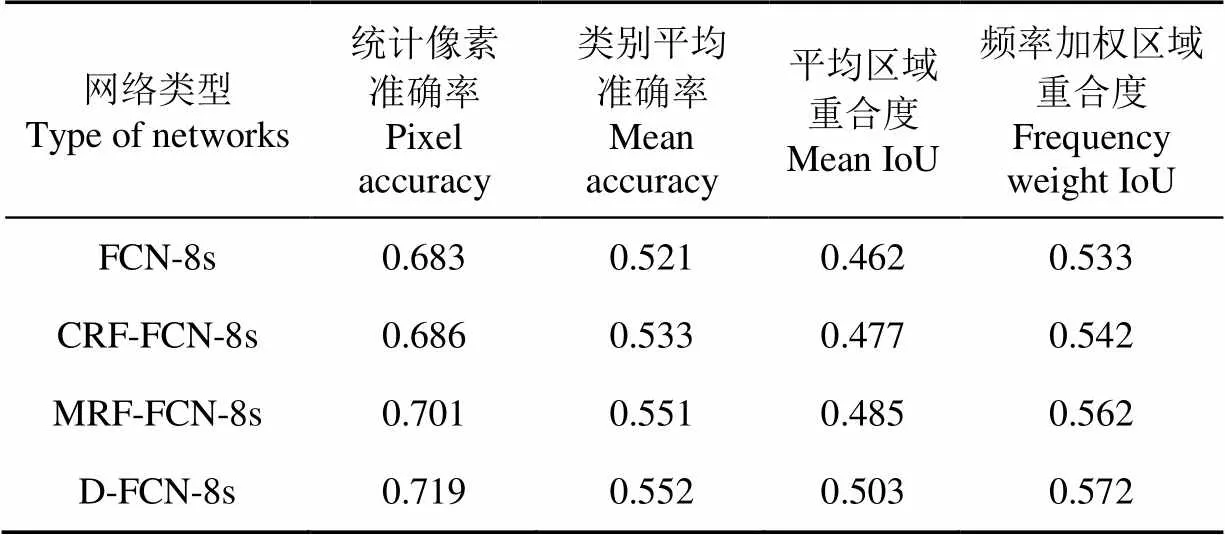
表3 FCN-8s、CRF-FCN-8s、MRF-FCN-8s和D-FCN-8s在NYUDv2+1数据集上的语义分割结果比较
注:CRF-FCN-8s是以FCN为基础并加入全连接条件随机场后得到的分割结果,MRF-FCN-8s是以FCN为基础并加入马尔科夫条件随机场后得到的分割结果。
Note: CRF-FCN-8s is s segmentation result based on FCN and adding Conditional Random Fields (CRF). MRF-FCN-8s is a segmentation result based on FCN and adding Markov Random Field (MRF).

图10 D-FCN-8s、FCN-8s与真值对比
5 结 论
1)在对全卷积网络输出的特征图(热图)进行上采样过程中,交替使用了双线性插值方法和全尺寸反卷积方法,避免了直接采用全尺寸反卷积操作而造成的分割结果粗糙的问题。
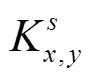
3)基于像素密度值,可以对FCN-8s中肉牛细节部分(例如边缘部位)进行优化,经过试验结果分析,在3类数据集上(NYUDv2+1,NYUDv2-20+1,NYUDv2-10+1)进行分割验证,与原始FCN-8s分割结果相比,D-FCN-8s在统计像素准确率提高2.5%,在类别平均准确率提升2.3%,在平均区域重合度提升3.4%,在频率加权区域重合度提升2.7%。
4)本文在FCN的基础上,分别加入了全连接条件随机场和马尔科夫随机场,用于在对像素分类过程中增加像素局部上下文信息,提高FCN系列网络的分割精度,通过NYUDv2+1数据集验证发现D-FCN-8s结果仍优于这两种网络,因为深度密度是在深度图像中使用了局部深度全局信息,而深度图像的精度要高于全连接条件随机场和马尔科夫随机场中的距离值,因此分割效果更好。
因此,上述结论证明通过计算和使用RGBD图像中像素点的深度密度,可以优化全卷积网络在肉牛细节部位的分割效果,提高全卷积网络的语义分割精度。
[1] Zhu Nanyang, Liu Xu, Liu Ziqian, et al. Deep learning for smart agriculture: Concepts, tools, applications, and opportunities[J]. IJABE. 2018, 1(4): 32-44.
[2] David Stutz, Alexander Hermans, Bastian Leibe. Superpixels: An evaluation of the state-of-the-art[J]. Computer Vision and Image Understanding. 2018, 166: 1-27.
[3] Bell S, Zitnick C L, Bala K, et al. Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition, Las Vega, 2016: 2874-2883.
[4] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2016, 313(5786): 504-507.
[5] 周云成,许童羽,郑伟,等. 基于深度卷积神经网络的番茄主要器官分类识别[J]. 农业工程学报,2017,33(15):219-226.
Zhou Yuncheng, Xu Tongyu, Zheng Wei, et al. Classification and recognition approaches of tomato main organs based on DCNN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(15): 219-226. (in Chinese with English abstract)
[6] 田有文,程怡,王小奇,等. 基于高光谱成像的苹果虫伤缺陷与果梗/花萼识别方法[J]. 农业工程学报,2015,31(4):325-331.
Tian Youwen, Cheng Yi, Wang Xiaoqi, et al. Recognition method of insect damage and stem/calyx on apple based on hyperspectral imaging[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(4): 325-331. (in Chinese with English abstract)
[7] 赵源深,贡亮,周斌,等. 番茄采摘机器人非颜色编码化目标识别算法研究[J]. 农业机械学报,2016,47(7):1-7.
Zhao Yuanshen, Gong Liang, Zhou Bin, et al. Object recognition algorithm of tomato harvesting robot using non-color coding approach[J]. Transactions of the Chinese Society for Agricultural Engineering, 2016, 47(7): 1-7. (in Chinese with English abstract)
[8] 贾伟宽,赵德安,刘晓样,等. 机器人采摘苹果果实的K-means和GA-RBF-LMS神经网络识别[J]. 农业工程学报,2015,31(18):175-183.
Jia Weikuan, Zhao Dean, Liu Xiaoyang, et al. Apple recognition based on K-means and GA-RBF-LMS neural network applicated in harvesting robot[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(18): 175-183. (in Chinese with English abstract)
[9] 杨国国,鲍一丹,刘子毅,等. 基于图像显著性分析与卷积神经网络的茶园害虫定位与识别[J]. 农业工程学报,2017,33(6):156-162.
Yang Guoguo, Bao Yidan, Liu Ziyi, et al. Localization and recognition of pests in tea plantation based on image saliency analysis and convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(6): 156-162. (in Chinese with English abstract)
[10] 谭文学,赵春江,吴华瑞,等. 基于弹性动量深度学习的果体病例图像识别[J]. 农业机械学报,2015,46(1):20-25.
Tan Wenxue, Zhao Chunjiang, Wu Huarui, et al. A deep learning network for recognizing fruit pathologic images based on flexible momentum[J]. Transactions of the Chinese Society for Agricultural Machinery, 2015, 46(1): 20-25. (in Chinese with English abstract)
[11] 王献锋,张善文,王震,等. 基于叶片图像和环境信息的黄瓜病害识别方法[J]. 农业工程学报,2014,30(14):148-153.
Wang Xianfeng, Zhang Shanwen, Wang Zhen, et al. Recognition of cucumber diseases based on leaf image and environmental information[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2014, 30(14): 148-153. (in Chinese with English abstract)
[12] 王新忠,韩旭,毛罕平. 基于吊蔓绳的温室番茄主茎秆视觉识别[J]. 农业工程学报,2012,28(21):135-141.
Wang Xinzhong, Han Xu, Mao Hanping. Vision-based detection of tomato main stem in greenhouse with red rope[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2012, 28(21): 135-241. (in Chinese with English abstract)
[13] 郭艾侠,熊俊涛,肖德琴,等. 融合Harris与SIFT算法的荔枝采摘点计算与立体匹配[J]. 农业机械学报,2015,46(12):11-17.
Guo Aixia, Xiong Juntao, Xiao Deqin, et al. Computation of picking point of litchi and its binocular stereo matching based on combined algorithms of Harris and SIFT[J]. Transactions of the Chinese Society for Agricultural Machinery, 2015, 46(12): 11-17. (in Chinese with English abstract)
[14] 赵凯旋,何东键. 基于卷积神经网络的奶牛个体身份识别方法[J]. 农业工程学报,2015,31(5):181-187.
Zhao Kaixuan, He Dongjian. Recognition of individual dairy cattle based on convolutional neural networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(5): 181-187. (in Chinese with English abstract)
[15] 段延娥,李道亮,李振波,等. 基于计算机视觉的水产动物视觉特征测量研究综述[J]. 农业工程学报,2015,31(15):1-11.
Duan Yan’e, Li Daoliang, Li Zhenbo, et al. Review on visual characteristic measurement research of aquatic animals based on computer vision[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(15): 1-11. (in Chinese with English abstract).
[16] 高云,郁厚安,雷明刚,等. 基于头尾定位的群猪运动轨迹追踪[J]. 农业工程学报,2017,33(2):220-226.
Gao Yun, Yu Houan, Lei Minggang, et al. Trajectory tracking for group housed pigs based on locations of head/tail[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(2): 220-226. (in Chinese with English abstract)
[17] 邓寒冰,许童羽,周云成,等. 基于DRGB的运动中肉牛形体部位识别[J]. 农业工程学报,2018,34(5):166-175.
Deng Hanbing, Xu Tongyu, Zhou Yuncheng, et al. Body shape parts recognition of moving cattle based on DRGB[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(5): 166-175. (in Chinese with English abstract)
[18] 杨阿庆,薛月菊,黄华盛,等. 基于全卷积网络的哺乳母猪图像分割[J]. 农业工程学报,2017,33(23):219-225.
Yang Aqing, Xue Yueju, Huang Huasheng, et al. Lactating sow image segmentation based on fully convolutional networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(23): 219-225. (in Chinese with English abstract)
[19] 郭祥云,台海江. 深度学习在大田种植中的应用及展望[J]. 中国农业大学学报,2019,24(1):119-129.
Guo Xiangyun, Tai Haijiang. Current situation and prospect of deep learning application in field planting[J]. Journal of China Agricultural University, 2019, 24(1): 119-129. (in Chinese with English abstract)
[20] 王丹丹,何东健. 基于R-FCN深度卷积神经网络的机器人疏果前苹果目标的识别[J]. 农业工程学报,2019,35(3):156-163.
Wang Dandan, He Dongjian. Recognition of apple targets before fruits thinning by robot based on R-FCN deep convolution neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(3): 156-163. (in Chinese with English abstract)
[21] 刘立波,程晓龙,赖军臣. 基于改进全卷积网络的棉花冠层图像分割方法[J]. 农业工程学报,2018,34(12):193-201.
Liu Libo, Cheng Xiaolong, Lai Junchen. Segmentation method for cotton canopy image based on improved fully convolutional network model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(12): 193-201. (in Chinese with English abstract)
[22] 段凌凤,熊雄,刘谦,等. 基于深度全卷积神经网络的大田稻穗分割[J]. 农业工程学报,2018,34(12):202-209.
Duan Lingfeng, Xiong Xiong, Liu Qian, et al. Field rice panicle segmentation based on deep full convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(12): 202-209. (in Chinese with English abstract)
[23] Evan Shelhamer, Jonathan Long, Trevor Darrell. Fully Convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
[24] Ronghang Hu, Piotr Dollar, Kaiming He, et al. Learning to segment every thing[C]//IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018, 4233-4241.
[25] Karen Simonyan, Andrew Zisserman. Very deep convolutional networks for large-scale image recognition[C]// International Conference on Learning Representations, San Diego, 2014: 1-14.
[26] Deng Jia, Dong Wei, Socher Richard, et al. ImageNet: A large-scale hierarchical image database[C]//IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, 2009: 248-255.
[27] Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton. ImageNet classification with deep convolutional neural networks[J]. International Conference on Neural Information Processing System, 2012, 60(2): 1097-1105.
[28] Jia Deng, Wei Dong, Richard Socher, et al. ImageNet: A large-scale hierarchical image database[C]// IEEE Conference on Computer Vision & Pattern Recognition, 2009: 248-255.
[29] Lin Tsungyu, Aruni RoyChowdhury, Subhransu Maji. Bilinear CNN models for fine-grained visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(6): 1309-1322.
[30] Zheng Shou, Jonathan Chan, Alireza Zareian, et al. CDC: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1417-1426.
[31] Matthew D Zeiler, Rob Fergus. Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision, Zurich, 2014: 818-833.
[32] Silberman N, Hoiem D, Kohli P, et al. Indoor segmentation and support inference from rgbd images[C]//In ECCV, 2012.7
[33] Zheng S, Jayasumana S, Romera-Paredes B, et al. Conditional random fields as recurrent neural networks[C]// 2015 IEEE International Conference on Computer Vision. 2015.
[34] Liu Ziwei, Li Xiaoxiao, Luo Ping, et al. Semantic image segmentation via deep parsing network[C]// IEEE International Conference on Computer Vision. 2015.
Optimization of cattle’s image semantics segmentation with fully convolutional networks based on RGB-D
Deng Hanbing1,2, Zhou Yuncheng1,2※, Xu Tongyu1,2, Miao Teng1,2,3, Xu Jing1,2
(1.110866,;2.110866,;3.100097,)
With the decreasing cost of image sensor equipment, full-time monitoring has been gradually realized in the process of cattle breeding. Especially, in the whole life of cattle, the monitoring and analysis for cattle’s behavior have become a research hotspot in the field of breeding. Acquiring a large amount of cattle image and video information, people are more concerned about how to process, analyze, understand and apply these data. How to segment dynamic objects from complex environment background is the precondition of cattle behavior analysis, and it is also the key of realizing long-distance, contactless and automatic detection for cattle behavior. The traditional machine vision image segmentation method is used to realize the clustering and extraction of pixels by artificially extracting image features. However, when the image background is complex, feature extraction will become very troublesome and even difficult to achieve. Deep Convolutional Neural Networks (DCNN) provides another solution, which enables computers to automatically learn and find the most descriptive and prominent features in each specific category of objects, and allows deep networks to discover potential patterns in various types of images. On the basis of massive labeled data, the accuracy of classification, segmentation, recognition and detection with convolutional neural network can be improved automatically through continuous training, and the labor cost is transferred from algorithm design to data acquisition, which reduces the difficulty of technology application. However, for cattle image segmentation, the complex breeding environment will be a problem. The color and texture of environmental information in the image will have an impact on the segmentation of cattle’s details. Especially when FCN uses deconvolution operation in the process of up-sampling, it is insensitive to the details of the image and does not take into account the class relationship between the pixels, which makes the segmentation result lack of spatial regularity and spatial consistency, so the segmentation effect will be very rough. In order to improve the accuracy of semantics segmentation for fully convolutional networks and segmentation effect of cattle image details, this paper proposes a method of fully convolutional networks semantic segmentation based on RGBD cattle image. We create a concept which named “depth density”. The value of depth density can quantify the probability about whether different pixels have the same category. According to the mapping relationship between RGB image and depth image on pixel level content, we optimize the semantic segmentation results of cattle’s image by FCN. The experimental results showed that, better than FCN-8s, the proposed method could improve the pixel accuracy, mean accuracy, mean intersection over union and frequency weight intersection over union by 2.5%, 2.3%, 3.4% and 2.7% respectively.
image processing; models; animals; semantic segmentation; RGB-D; fully convolutional networks; multimodal; cattle’s image
邓寒冰,周云成,许童羽,苗 腾,徐 静. 基于RGB-D的肉牛图像全卷积网络语义分割优化[J]. 农业工程学报,2019,35(18):151-160.doi:10.11975/j.issn.1002-6819.2019.18.019 http://www.tcsae.org
Deng Hanbing, Zhou Yuncheng, Xu Tongyu, Miao Teng, Xu Jing. Optimization of cattle’s image semantics segmentation with fully convolutional networks based on RGB-D[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(18): 151-160. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.18.019 http://www.tcsae.org
2019-04-02
2019-08-20
国家自然科学基金资助项目(31601218,61673281,31601219);中国博士后科学基金(2018M631812);辽宁省自然基金面上项目(20180551102)
邓寒冰,讲师,博士,主要从事农业领域的机器学习与模式识别研究工作。Email:denghanbing@syau.edu.cn
周云成,副教授,博士,主要农业领域机器学习与模式识别研究工作。Email:zhouyc2002@syau.edu.cn
10.11975/j.issn.1002-6819.2019.18.019
S823.92; TP391.41
A
1002-6819(2019)-18-0151-10
猜你喜欢
今日农业(2022年2期)2022-11-16
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2022年1期)2022-06-01
合肥工业大学学报(自然科学版)(2021年11期)2021-12-10
今日农业(2021年21期)2021-11-26
现代电子技术(2021年1期)2021-01-17
湖南饲料(2019年5期)2019-10-15
微型电脑应用(2019年1期)2019-01-23
电脑知识与技术(2018年35期)2018-02-27
长江学术(2016年4期)2016-03-11
