美DARPA等推动终身学习型人工智能研究
2019-11-06 03:09:20唐川
数据与计算发展前沿 2019年3期
过去十年,基于机器学习的人工智能(AI)在性能方面取得了突破性进展,经常接近人类专家的能力,有时甚至超过了他们,例如人工智能在图像识别、语言翻译、围棋中的表现。
这些应用使用大型人工神经网络,其中的节点由数百万个加权互联相连。它们模拟了大脑的结构和工作机制,但有一个关键领域做不到——人工神经网络无法像动物那样随着时间的推移而学习。一旦开发人员完成了人工神经网络的设计、编程和训练,如果不对其再进行训练,它们就不能适应新数据、完成新任务了,而再训练往往很费时间。
人工智能系统的实时适应性已成为研究领域的热点问题。例如,2018年美国优步科技公司(Uber Technologies)的计算机科学家发表了一篇文章,介绍在神经网络中引入“可塑性”的方法。在图像识别和迷宫探索等多个测试应用中,研究人员展示了已训练的神经网络无需再进行训练就能够快速高效地适应新情况。
“神经网络常用的训练方法是用范例慢慢地训练;范例的数量多达百万计,甚至数以亿计。”该文章的第一作者介绍说,“但我们人类可不是这么学的。我们学得很快,通常经过一次新情况或刺激就学到了。我们大脑中的连接具有突触可塑性,可以自行改变,让我们迅速形成记忆。”
60多年来,神经网络都是由互联的节点构成,连接的成对强度由权重决定,通常经标记的范例训练而固定下来。这种训练绝大多数时候通过反向传播算法(backpropagation)完成:系统计算突触输出的错误,将其通过网络层反向传播。目前大多数深度学习系统都采用了梯度下降的反向传播算法这种优化技术,连优步研究人员所用的测试系统也不例外。
以此为基础,优步研究人员使用了赫布学习(Hebbian learning)的方法。该法于1949年由加拿大神经心理学家唐纳德·赫布(Donald Hebb)提出,他观察到在突触间反复放电的两个神经元能够随着时间的推移加强它们之间的连接。通常将其归纳为:“一起放电的神经元,连接在一起(Neurons that fire together,wire together)。”
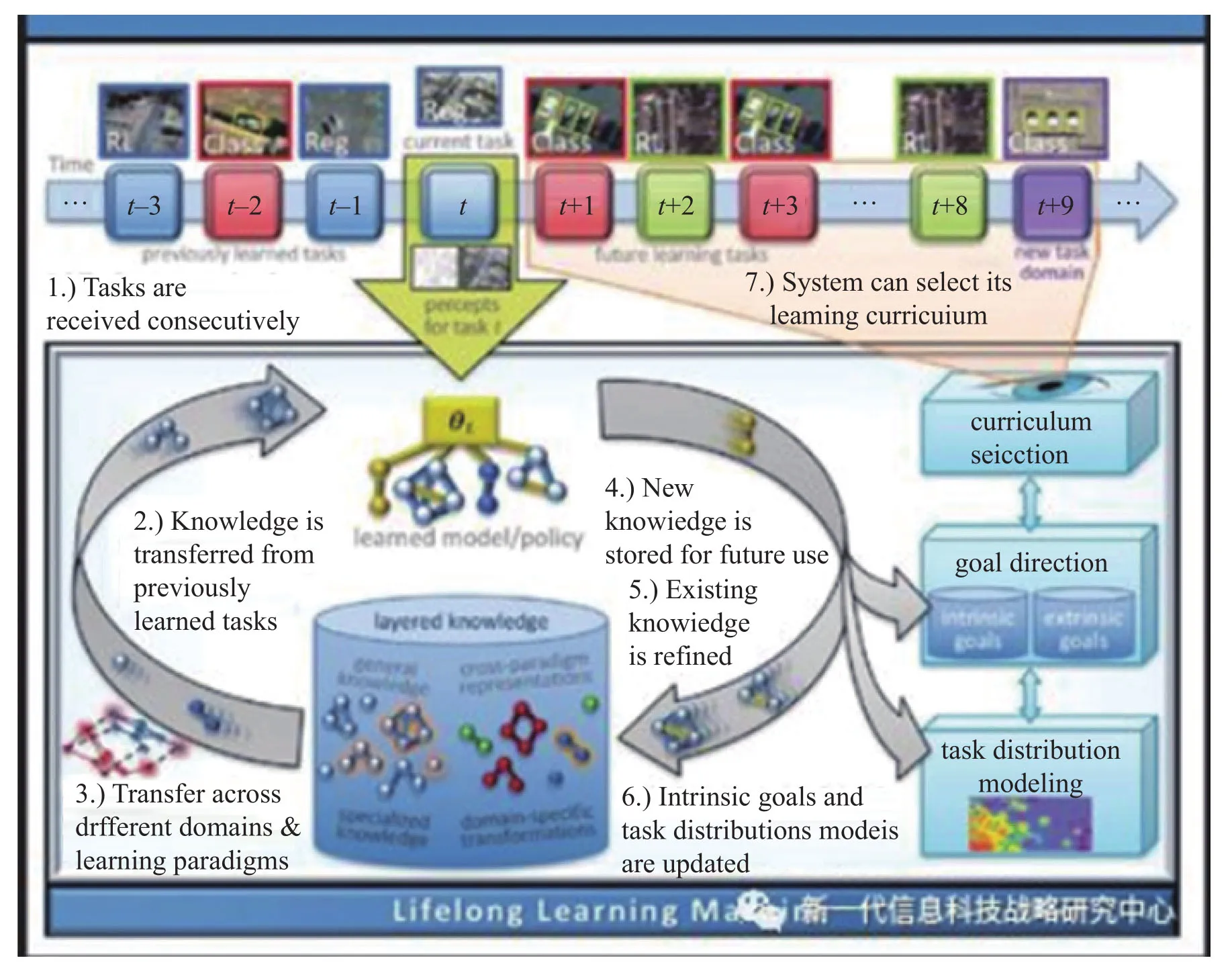
图DARPA终生学习机器(Lifelong Learning Machines,L2M)项目旨在开发出新的学习系统,能随着经验增加而不断提升,快速适应新情况和动态变化环境。
利用这种“赫布可塑性”,神经网络采用了一种“元学习”——本质而言,它们学习如何基于三个概念上简单的参数进行学习。神经元对在系统的训练过程中确定了传统的固定权重。它们还有个可塑权重,叫作“赫布边迹(Hebbian trace)”,可塑权重根据遇到的实际数据在一生中不断变化。这些赫布边迹可用不同的方法计算,但在简单例子中,它是突触前和突触后活动产物的运行平均值。
赫布边迹是由第三个固定参数——可塑性系数——对自身加权。因此,在任何时候,两个神经元之间连接的总有效权重等于固定权重与赫布边迹乘以可塑性系数之和。根据这三个参数的值,每个连接的强度可以是完全固定、完全可变或介于两者之间的。
“这是件很重要的工作。”美国卡内基梅隆大学计算生物学家评价道,“他们采用了生物学中的知名原则,展示其对人工神经网络有积极的影响。”但是他指出,这个方法是否会代表人工智能大型主流应用的重要进展,现在下结论还为时过早。
对于目前的超大型人工智能系统,该科学家说,“我们优化、优化、再优化,只能做到这一步。如果有新数据,可以重新训练它,但我们不是在试着让它适应新的东西。”举个例子,神经网络可能已经过训练,能够在对不同种类汽车进行分类时给出高度精确的结果,但是如果遇到一种新的汽车(例如,特斯拉),系统就不行了。“我们希望它能迅速地识别出这个新汽车,不用再训练。再训练要耗时数日或者数周。而且,我们怎么才知道出现了新的东西呢?”
动态学习的人工智能系统不是新事物了。在“神经进化”中,神经网络由采用了试错方法的算法进行更新,以实现精确定义的目标,例如赢得一场象棋比赛。它们不需要标记的训练范例,只需要成功的定义。“它们只通过试错的方法进行。”优步的研究人员说,“这种方法很强大,但很慢,本质上是随机的过程。如果我们看到一件新的事物,就得到一个错误信号告诉我们要向什么方向改变权重,这样会好得多。这就是反向传播算法带给我们的。”
军事应用
优步研究人员的做法只是人工智能自学习的众多新方法中的一种。美国国防部将突触可塑性纳入其提高防御系统准确性、安全性和灵敏度的系列实验方法中。美国国防高级研究计划局(U.S.Defense Advanced Research Projects Agency,DARPA)启动了终生学习机器项目,从两处着力,一是开发完整系统及其组件,二是探索生物有机体中的学习机制并将其移植到计算过程中。该项目的目标是让人工智能系统“在任务中学习和提升,将已有技能和知识应用到新情况,包容固有系统限制,提高自动任务的安全性。”DARPA 在其网站上表示,“我们不是在寻求逐步的改善,而是希望找到突破性的机器学习方法。”
优步的赫布可塑性研究很有前景,向神经网络终生学习又迈进了一步,DARPA 终生学习机器项目创始人及负责人表示,“没有这种方法,我们在自动驾驶汽车中就不会安全。”但它只是向着目标迈进了一步,还有很多必不可少的工作。“这绝不是圆满的结局了。”她说。
根据 DARPA 对终生学习的广义定义,有五大“支柱”,突触可塑性属于第一支柱。五大支柱包括:记忆连续更新,不出现灾难性遗忘;重组记忆,根据未来的行为将已学习的信息重新安排和组合;情景感知(context awareness)以及基于系统行为调整的情景;通过内部互动、自我意识和自我模拟来采用新行为;安全和防卫,意识到某事危险并相应地改变行为,并通过多个强约束的组合来确保安全。
该负责人列举智能假肢作为这些技术的应用例子。她指出,对于假腿中的控制软件,首先制造商可以通过常规反向传播法训练软件,然后训练该软件满足使用者的独特习惯和特点,最后让其快速适应从未遇到过的情况,例如结冰的人行道。
她表示,多年来,终生学习一直是人工智能研究人员的目标,但直到最近才有了重大进展。这得益于计算能力的进步、新理论基础和算法的出现、以及对生物学更好的理解。“不出几年,如果不具备终生学习的能力,很多我们现在称为人工智能的东西不会再被看作人工智能了。”她预测道。
优步的研究团队目前正致力于让其测试系统中的学习更动态、更精细。实现这一目标的一种方法是让可塑性系数随着系统的寿命周期而变化,目前可塑性系数作为一种设计选择是固定的。“每种连接的可塑性可由网络本身在每个点自行决定。”研究人员说。这种“神经调节”可能出现在动物大脑中,他表示,这可能会是实现人工智能系统进行最灵活决策的关键一步。
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28 07:43:34
昆明医科大学学报(2021年8期)2021-08-13 08:59:20
昆明医科大学学报(2021年6期)2021-07-31 07:40:08
英语文摘(2021年5期)2021-07-22 08:46:16
疯狂英语·爱英语(2020年3期)2020-06-23 09:39:14
中国自行车(2018年7期)2018-08-14 01:52:44
诗林(2016年5期)2016-10-25 05:49:08
华人时刊(2016年17期)2016-04-05 05:50:38
上海国资(2015年8期)2015-12-23 01:47:28
西南医科大学学报(2015年1期)2015-08-22 13:01:48