
基于业务应用的ReID 评估指标研究
2019-11-05 11:14窦伟
现代计算机 2019年27期
窦伟
(中国人民公安大学研究生院,北京100038)
0 引言
随着“平安城市”管理系统在我国的不断推进,我国逐步实现了主要城市视频监控系统的覆盖。为贯彻科技强警的要求,构建全覆盖、全天候的监控网络,以提高对违法犯罪行为的应对与打击能力,到十三五初期,我国为建设视频监控系统而布设的前端摄像头已经超过2500 万个。随着视频监控网络规模的不断扩大,仅仅依靠人力分析视频图像的效率变得极其低下。一方面,环境的多样性导致监控区域的复杂性增加,另一方面,在跨区域追踪时,视频监控的信息量将成倍增加。因此,在跨视域情况下从大量监控信息中筛选出支撑公安业务的重要犯罪信息显得尤为重要,行人再识别技术应运而生。
近些年,在引入深度学习相关方法后,行人再识别技术发展迅速,基于深度学习的算法在现有的行人重识别数据集上都展现出优越的性能,经典数据集有VIPeR[6]、GRID[7]、Market-1501[8]、CUHk03[9]等。然而已有数据集难以模拟出真实环境的复杂性,评价标准也与实际情况相去甚远,这使得行人再识别算法即使在数据集上跑出很高的得分,也难以在实际应用中发挥应有作用。随着视频图像数量的增多、摄像头光线与角度的变化、采集时间与地点的多样化,数据集的可识别难度到达了瓶颈期,同时现有评价指标较为统一且变动甚微,这使得算法性能出现“虚高”现象。因此,为了提高行人再识别算法的实用性,本文对已有行人再识别算法评价指标进行概括说明,并对提升评价指标的合理性提出了改进方案。
1 评估指标CMC曲线
早期的行人再识数据集种类少,内容简单,多采用CMC(Cumulative Match Characteristic curve)评估曲线对相关算法进行评估。CMC 评估曲线,即累积匹配特性曲线,是一种计算top-k 击中概率的曲线,主要用于闭集测试。计算过程如下:
在一个识别的数据集中,假设底库里有100 个人,现在我们要识别某一个人A(设其label 为x0),将其与整个底库里的行人图片比对后,按照相似度得分从高到低进行排序,我们发现:
如果经过识别后得到的结果是x0、x1、x2、x3、x4…,那么,rank-1 的准确率就是100%;rank-2 的准确率也是100%;rank-5 的准确率也是100%;如果经过识别后得到的结果是x1、x0、x2、x3、x4…,则此时rank-1的准确率就是0%;rank-2 的准确率是100%;rank-5的准确率也是100%;如果经过识别后得到的结果是x1、x2、x3、x4、x0…,则此时rank-1 的准确率就是0%;rank-2 的准确率也是0%;rank-5 的准确率是100%;可见,对于rank-k 的计算,如果在第n 次搜索到正确的目标,那么在k
同理,在待识别的人脸集合数目较多的时候,采取对其识别结果取平均值的方法,作为评价的结果。比如我们待识别的目标行人有3 个A、B、C(假设他们的label 分别为x0,x1,x2),那么,对于每一个人,将他们与底库中的行人图片进行比对,将每个比对的结果按照相似度得分从高到低进行排序。
如果对于行人A、B、C 的识别结果如表1 所示。
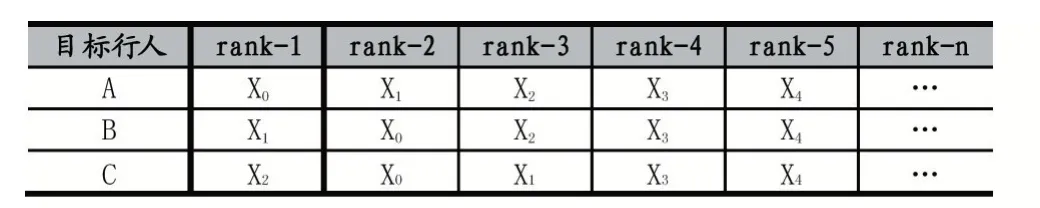
表1 对于人物A、B、C 的第一种搜索结果
那么rank-1 的准确率是(1+1+1)/3=100%;rank-2的准确率是(1+1+1)/3=100%;rank-5 的准确率是(1+1+1)/3=100%;可见,对于搜索三个目标行人时,其准确率的计算采用了取均值的方法。由于三个目标行人都是在第一次就搜索正确,所以其后的rank-k 的值都是100%。
如果对于行人A、B、C 的识别结果如表2 所示。

表2 对于人物A、B、C 的第二种搜索结果
那么rank-1 的准确率是(0+0+0)/3=0%;rank-2 的准确率是(0+1+0)/3=33.33%;rank-5 的准确率是(0+1+1)/3=66.66%;由于第一个目标人物A 在前五次均没有搜索正确,所以对于目标A 的rank-k<5 时,值均为0。
CMC 曲线会对正确的搜索结果中置信度最高的n张图求平均值,获取一个最终结果。随着测试次数的增加,再识别的准确度将会提高,其总体趋势是随着k值的增大rank-k 趋向于1。因此,在选取考量的时候选值k 常常小于20,并且尤为注重一个算法的rank-1的能力,又称算法的第一识别率。在Y.Deng 提出的PETA 数据集中,搜索结果的一个示意图如图1 所示[3]。其中,红色代表错误样本,蓝色代表正确样本。

图1 搜索结果示意图
当query(查询图像)对应的gallery(候选行人库)中每个人的图像仅有一张时,CMC 评估曲线评估能力较好。将VIPeR、GRID、PRID 等作为数据集的行人再识别算法,例如廖胜才于2015 年提出的LOMO_XQDA算法[2],都使用了CMC 评估曲线作为评价指标。CMC评估曲线在比较两个算法性能的优劣时,曲线越靠近竖轴,代表该算法性能越好。Liao 用LOMO 对VIPeR数据集进行特征提取并且在XQDA 度量学习下测试,其CMC 曲线如图2 所示。
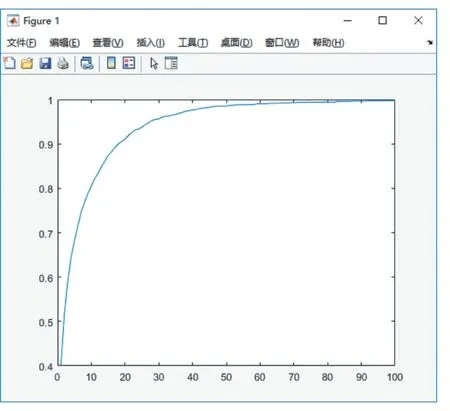
图2 LOMO_XQDA算法在VIPeR数据集下的CMC评估曲线
当gallery 中每个人的图像为多张时,CMC 评估曲线则出现了一些问题。例如,在Market-1501 数据集中,query 和gallery 有一定概率出自于同样的摄像机视角,然而每个query 可能对应同一摄像头收集的gallery的多个样本,该方法仅保留其中一个匹配度最高、最容易识别的样本,其余样本则被剔除。换句话说,query的返回图像往往是gallery 中最容易识别的正样本,其它更难识别的正样本则被忽略。换言之,对于每个gallery 存在多个实例的情形,用CMC 计算的准确率不能很好地评估算法的优劣。此外,对于拥有相近rank 命中率的算法来说,CMC 也不能很好地区分它们的性能。例如两个算法在rank-10、rank-20 上的命中概率相同,但是其中一个算法搜索的结果可能更靠前,则其性能更优越,但在CMC 评估曲线上无法做出合理的区分。
2 评估指标mAP
行人再识别技术的快速发展和机器学习的引入使得更多大规模的数据集出现,数据集的时间复杂性和空间复杂性都有大幅度提升,其图片可能来自于多个时间段、多个空间、多个角度。此外,数据集的形式不局限于图片,还出现了视频序列,一个视频序列中可能有某个人的几十张图片。此时仅用CMC 曲线一个评估指标对算法的优劣进行判定就显得力不从心了。因此,为了解决gallery 中存在多个正确样本的问题,一个新的评估指标平均正确率均值(mean Average Precision mAP)应运而生。
mAP 的核心思想在于,优秀的行人再识别系统应当返回query 在gallery 中对应的所有真实匹配的样本。假如有两种行人再识别算法,二者均能发现第一个真实匹配,召回能力却有很大差别。此时,相比于CMC 曲线,mAP 展示出很大的优越性,是一个更系统全面的评估指标。
首先介绍什么是准确率(Precision)和召回率(Recall):准确率是指返回的样本中正确样本占总样本的比例,召回率是指返回到正确样本占全体正确样本的比例,二者均针对同一类别进行计算,并且只有检索到当前类别时才进行计算。
准确率= 返回的正确样本个数/返回的总样本个数
召回率= 返回的正确样本个数/全体正确样本个数
应用于行人再识别中可举例,若行人A 的标签为X0,测试集中包含3 张行人A 的样本图像,将匹配出的样本图像依照得分从高到低的方式进行排列,如表3所示。

表3 检索结果排序
第一次检索到X0,返回的正确样本个数=1,返回的样本个数=1,返回的样本个数=2,正确率=1/1=100%,召回率=1/2=50%;
第二次检索到X0,返回的正确样本个数=2,返回的样本个数=6,返回的样本个数=2,正确率=2/6=33.33%,召回率=2/2=100%;
那么平均正确率AP=(100%+33.33%)/2=66.67%,当检索任务为多个目标行人时,正确率的计算就是取检索到的每个人的正确率的平均值mAP。
关于mAP 的计算,在market1501 的评估代码里还有另一种计算方法,即求Precision-Recall 曲线的面积。该方法计算的是Precision-Recall 曲线下的面积,与信息检索领域计算每次命中时准确率的平均值不同。在做比较时,曲线在上面的算法性能好(即准确率和召回率都高的情况),如图3 所示,蓝色线代表的算法要比红色线的性能好。如果出现交叉的情况,就要看具体情况去计算面积差值来做进一步的比较。

图3 Precision-Recall曲线
3 一种改进的评估指标
随着行人再识别技术的快速提升,相关算法的测试结果取得了瞩目的成就。2018 年,主打人工智能算法与视频深度学习技术的千视通,在行人再识别常用数据集Market 1501、DukeMTMC-ReID、CUHK03 上的测试结果有着巨大的突破,千视通Market 1501 上的首位命中率(Rank-1 Accuracy)达到97.1%,已经超越人眼识别能力(94%),刷新了2018 年4 月公布的96.6%的世界纪录。现有的行人再识别数据集近乎涵盖了所有的现实情境,如遮挡、服饰与姿态变化、多视角、分辨率变化等。Y.Deng 等人提出,可将各种类型的数据集揉合来提高数据集的复杂度和再识别的困难性,对算法提出了更严峻的考验,并且提出了一个新的数据集PETA[3]。除此之外,笔者认为可以在算法的评价指标方面加以改进,以更好地测试算法的性能。在实际应用中,大多采用CMC 和mAP 相结合的形式共同评估行人再识别算法的性能。例如,Yifan Sun 团队于2017年ICCV 上提出的《SVDNet for Pedestrian Retrieval》,便采用了二者结合的评估方式,如表4 所示。

表4 SVDNet 算法的性能指标及结果
在当前的行人再识别算法中,通常将gallery 中的样本与query 进行某种特征(如颜色特征、纹理特征)的相似性度量,而后按照样本间距由近到远的顺序对样本进行排列,最后计算每个样本的准确率。准确率的计算是一个二值化的判断,输出结果仅为0 或1,计算准确率的具体方法是得到gallery 中每个样本图片的特征矩阵,分别将其与query 的特征矩阵进行相似性度量,设定一个阈值M,度量结果大于M,该样本判定为正样本,输出1,反之为负样本,输出0。该方法仅考虑匹配的图片是正样本还是负样本,而忽略图片的质量和有效性。
以图4 为例,假设我们需要在gallery 中搜索左图中的男子,匹配结果为右边四张图片,人像有正脸、侧脸、背影之分,图片像素质量不一。现有的评估指标认为,右边的四张图片均为正样本,但无法进一步判断匹配的行人图像对判定行人面部及其他信息是否具有有效性,也无法评估图片的清晰度对实际需求的满足程度。在实际应用中,通常情况下无法获取质量较好的犯罪嫌疑人的图像信息,用于检索的query 有可能为侧脸或背影,且图片像素低下,模糊不清。我们希望获取便于识别嫌疑人身份信息的图片,即清晰度较高的正脸照和全身照,为下一步业务工作的开展提供重要线索。这就要求准确率的计算不能简单地“一概而论”,仅判断图片是否为正样本,而应当对包含不同信息量的正样本返回不同的数值加以区分。
为了满足工作的实际需求,本文提出了一种改进的行人再识别评估指标。本文主要针对行人的正脸、侧脸以及背影分配权值,以评估算法的匹配难度以及匹配图像的信息量。将匹配到正脸、侧脸或是背影等几种不同的情况加以权重,以得分的平均作为算法的最终得分,以此来构建一个更全面的评估指标。
例如,在VIPeR 数据集中,将632 个人物的1264张图像去除四张不符合要求的图像后,按照检索到正脸、侧脸或是背影分为以下几种情况,其在LOMO 算法下的准确率如表5 所示。

表5 VIPeR 数据集中包含的图像分类后结果及其准确率
由表5 可见,对于不同情况下的行人图像,算法的识别能力并不一样,因此不能一概而论,而是要适当的加一个权值进行计算,才更为合理。根据实际情况调查,我们拿到的多数为侧脸或是背影较多,且图像质量多数不好,故此我们以上四种情况的得分ki分别配以权值αi,每类图片的数量(张)为ni,其中i 取1 到4 的整数,则其最终得分的计算如下式:

根据实际需求将α 取一组数值分别为0.9、1.0、1.0、0.9,进行重新计算得分后,将其结果与原结果对比如表6。

表6 改进后的评分与原指标的评分比较
由表6 可知,改进后的评估,总体准确率都要下降十几个百分点,可见新的评估方法考虑到实际情况后,对算法提出了更为苛刻的要求,这就要求我们继续改进算法,以期算法可以更好地、更贴合实际情况地提升其能力,这为行人再识别的未来发展指明了一个方向,对于其商业化以及更好地应用具有指导作用。
4 结语
当前行人再识别领域的算法评估指标较为统一,多数采用累计匹配特性曲线CMC 与平均准确率mAP相结合的方式,并且非常注重算法的第一识别率。然而随着深度学习技术的引入,再用老的评估指标来进行评价,最新的算法都可以得到非常可观的得分,导致该方向的研究达到了一个瓶颈,然而这距离实际的应用却是相去甚远,所以本文提出了一个新的改革性的方向,即改进对其的评估。本文提出了一种新的改进的评估方法,希望能对行人再识别的未来发展提供一个新的方向,为其更好地应用、更好地服务人民具有一定的借鉴意义。
猜你喜欢
出版人(2022年8期)2022-08-23
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
意林(2021年5期)2021-04-18
健康体检与管理(2021年10期)2021-01-03
英语文摘(2020年6期)2020-09-21
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
Coco薇(2015年10期)2015-10-19
