
改进的二叉决策树多分类算法在入侵检测中的应用
2019-11-03 13:11刘铭南西
电脑知识与技术 2019年24期
刘铭 南西


摘要:网络安全问题日益严峻,入侵检测作为主要的网络防范手段之一,但多分类的检测普遍存在检测率低漏报误报率高的问题,本文结合入侵检测数据中正常数据的数据量远大于异常数据的特点,并根据类间分离性算法确定不同攻击类型的分离顺序,构造性能优良的二叉树结构,有效提高入侵检测的性能。
关键词:入侵检测;支持向量机;多分类;分离性测度;二叉树
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)24-0033-02
开放科学(资源服务)标识码(OSID):
随着互联网技术的日益发展和普及,人们在享受网络带来极大便利的同时,网络安全问题也日益突出。为了更好地利用网络,迫切需要提高网络安全相关防范技术。
入侵检测系统(Intrusion Detection System ,IDS)作为防火墙之后的第二道防线,具有主动性和实时性的特点,在网络关键节点上收集信息并进行分析,从而对异常行为做出判别[1]。支持向量机(Support Vector Machine, SVM)作为一种在小样本机器学习基础上发展起来的方法,应用于网络入侵检测系统有较好的检测性能。二叉树法为常用的SVM多分类方法有结构灵活,所需构造的分类器数少,从根节点往下,训练样本数和支持向量数都逐级减少,检测速度较快[2]。
本文在分析二叉树多分类的基础上,提出基于分离性测度的SVM多分类方法,根据类间分离性算法确定不同攻击类型的分离顺序,构造性能优良的二叉树。
1 改进的决策树多分类方法
目前,如何根据相关应用构造合理性能优良的二叉树结构并没有具体的定义。分类器的分类性与二叉树的构建过程密切相关,上层节点的分类性能对整个分类模型的影响最大,在分类过程中,尽量减少在上层节点出现分类错误。在二叉树的构造过程中,容易区分,不易产生分类错误的类在上层分类器中优先分离,逐层进行分析,使可能产生的分类错误尽量远离上层节点,使其对整体产生的影响降至最小。
类间分离性算法定义
如何确定各类的分离顺序,各类的易分性,目前通常将类中心间的欧氏距离或马氏距离作为不同类间的测度。但该方法在很多情况下并不能正确反映类间的分离度,类的分布对类间的分离性也有着重要影响。基于类的分布类间分离性测度[3]定义如下。
假设要进行M类分类,则样本类别数为M,训练样本集由类[Xi,i=1,???,M]组成。通过训练样本计算得出类中心[ci],
[ci=1nix∈Xix,i=1,???,M]; ([ni]为类[Xi]中样本的个数) (1)
[dij]表示类[i]與类[j]中心间的距离:
[dij=ci-cj,i,j=1,???,M]; (2)
[σi]表示类分布的类方差:
[σi=1ni-1x∈Xix-ci,i=1,???,M]; (3)
定义1:(类间分离度)类i和类j间的分离性测度[sepij]:
[sepij=dij(σi+σj)] (4)
若[sepij≥1],说明两类之间无交叠;如果[sepij<1],则两类之间有一定交叠。类i与类j之间的分离性越好则[sepij]的值越大。
定义2:(类分离度)类i的分离性测度[sepi]:
[sepi=minsepijj=1,???,kj≠i] (5)
[sepi]表明了该类与其他类间的分离性。
定义3:(类易分性)最易分的类s:
[s=argmaxsepii=1,???,k] (6)
最容易分的类即为计算得到的分离性测度值最大的类。
改进的决策树多分类SVM算法
改进的决策树多分类SVM算法具体流程如下:
步骤1:根据上述公式(1)(2)(3)计算各类的相关参数,并根据公式(4)(5)得出各类样本数据的类间分离度[sepij]和类的分离性测度[sepi]。
步骤2:比较得到的各类分离度,由大到小进行排列, [n1,n2,???,nM],其中[ni∈1,2,???,M,i=1,2,???,M]为类的标号,分离性测度最大的类即最容易分的类。
步骤3:在二叉树各节点利用SVM二分类算法构造最优超平面,利用改进的人工蜂群优化支持向量机算法[4]对SVM的相关参数进行优化。
步骤4:构造第一个分类器,在根节点选择最容易分的类即分离性测度值最大的n1类作为正样本集,其余各类数据为负样本集,然后从总样本集中将分离的正样本集删除,以此类推,按照此方法构造其余的分类器。如果有两个类得出的分离性测度值相同,则两类的分离顺序不会对整体的分类效果产生实质的影响,算法选择优先分离类标号较小的类,最终构造出改进后的二叉树多分类SVM模型。
2 基于改进二叉决策树多分类入侵检测实验
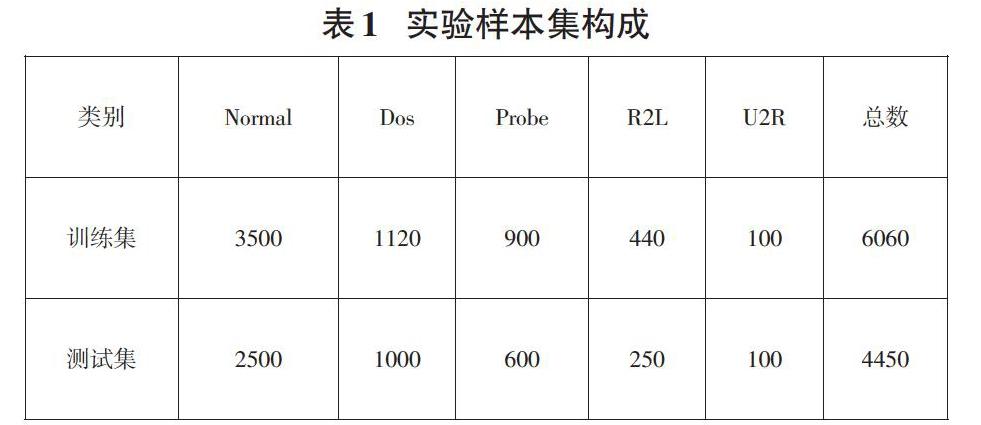
本文选用NSL-KDD数据集作为实验数据集,该数据集将数据分为正常的数据NORMAL类和DOS、PROBE、U2R、R2L四类异常的攻击数据[5]。数据集包含训练集和测试集,分为正常数据和入侵异常数据。根据各类型数据的比例选取部分数据并进行标准化预处理进行实验,实验数据类型分布如表1所示。
在实际的网络环境中,正常数据在总数据中所占的比例远远大于异常数据(1%-2%)。整个二叉树每个节点分类器的不同会影响到分类器的分类性能,结合网络环境中入侵检测数据的实际特点,检测数据输入后,首先判断是否为入侵数据,若为正常数据,则直接分离;如果判断为入侵数据,则通过下层分类器继续进行分离。
在二叉树的构建过程中应充分考虑四种攻击类型之间的关联性,通过上述定义的类间分离性算法计算得到每个攻击类别的易分性,并根据结果构造二叉树。根据定义,本实验通过java编程,使用eclipse平台,最终得到DOS、PROBE、U2R和R2L四类的最小分离性测度值如表2所示:
考虑各类的易分性,根据类间分离性算法定义,结合表中数据可知,DOS类最易分离,不容易出现分类错误,将其在最上层节点进行分离。将U2R和R2L兩种类别这两类放到最后分离。由此构造的二叉树分离顺序可以使分类过程中产生的错误远离根节点,使其对整体性能产生的影响降至最小。根据类分离算法构建的入侵检测的二叉树结构图如图1所示。
3 结束语
针对目前各种攻击类型不易区分导致入侵检测系统检测正确率较低,误报率较高的问题,本文提出一种基于分离性测度的二叉决策树多类入侵检测方法,首先分离数据量最多的正常数据,对异常数据分类时,二叉决策树构建的过程根据类的分离性测度,逐层选择当前最易分的类进行分离,通过这种方法对二叉树多分类算法进行改进,提出合理有效的二叉树结构,有效地提高入侵检测的性能。
参考文献:
[1] 王贵珍,曲天光.入侵检测系统研究与发展概述[J]. 保密科学技术, 2019(2).
[2] 刘铭. 基于CMABC参数优化的SVM多分类入侵检测方法研究[D]. 广西大学, 2015.
[3] Wang X D, Wu C M. Using improved SVM decision tree to classify HRRP[C]//2005 International Conference on Machine Learning and Cybernetics. IEEE, 2005(7): 4432-4436.
[4] 刘铭, 黄凡玲, 傅彦铭,等. 改进的人工蜂群优化支持向量机算法在入侵检测中的应用[J]. 计算机应用与软件, 2017(1).
[5] 刘金平,何捷舟,马天雨,等.基于KELM选择性集成的复杂网络环境入侵检测[J].电子学报,2019,47(5).
【通联编辑:光文玲】
猜你喜欢
电脑报(2022年37期)2022-09-28
现代计算机(2021年14期)2021-07-09
武汉轻工大学学报(2016年4期)2017-01-16
科学与财富(2016年28期)2016-10-14
河南科技(2014年24期)2014-02-27
