
基于依存句法树方法的微博文本的情感分析研究
2019-11-03 13:11王彬菁
电脑知识与技术 2019年24期
关键词:情感分析
王彬菁
摘要:随着移动互联技术的发展,微博作为一种新媒体形式日益成为国内主流的移动社交媒体平台。微博包含海量的信息数据且数据种类多样,即有文档文本数据,也有图片、表情符号、视频动画等非结构化的数据。因此,对各政府部门和企业单位的网络舆情监管提出了艰巨的挑战,有关中文微博文本的情感分析的研究也成为近几年数据挖掘领域的关注方向之一,情感分析研究主要围绕着信息的抽取和情感倾向的判定,均离不开对微博文本的分词工作。本文提出了一种基于依存句法树的情感分析方法。根据不同的词汇间的依存关系,制定了相应的情感短语削减规则。通过分析不同程度词和否定词对情感词的修饰和组合关系,制定了不同的汇聚规则。使用LTP-Cloud(语言技术平台云)进行句法分析,构建依存句法树,通过对句法树的后序遍历逐步汇聚情感向量。使用了为情感值取绝对值的情感判别方法,得到最终的情感类别。
关键词:微博文本;依存句法树方法;情感分析;LTP-Cloud(语言技术平台云)
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2019)24-0013-03
开放科学(资源服务)标识码(OSID):
近些年,随着移动互联技术的迅猛发展和日益成熟,移动互联技术已然进入社会大众的生活,并且逐渐改变着我们的消费方式、沟通交往方式;其中,微博作为一种成熟的新媒体形式已经成为国内最大的移动社交媒体平台。根据中国互联网络信息中心(CNNIC)最新发布的第41次《中国互联网发展情况统计报告》显示,截至2017年12月底,中国网民规模已经达到7.72亿,这其中手机用户的占比为97.5%,手机成为网民上网的主要终端设备[1]。这些网民获得信息的方式又主要通过微博,微信,各类手机APP,移动社会化的传播格局逐步形成,微博作为承载信息发布,互动交流功能的社交媒体平台已经被社会大众所熟知和使用。据《2017年微博用户发展报告》显示,截至2017年9月,微博月活跃人数共计3.97亿,日活跃1.65亿,[1]用户的使用习惯趋向移动化,微博讨论方式碎片化,强调高社交粘性的互动方式,这些特性吸引着年轻群体,他们在微博上表达带有个人喜好的观点和看法,对网络舆论的传播具有重大影响。所以,微博应该成为各级政府机构和企业关注的舆论阵地,积极引导正面舆论,及时监控不良的舆论导向。
微博文本主要使用文本形式传播信息,其中也包含其他非结构化的数据,比如种类繁多的网络表情符号、各式各样的图片、视频、音频。这些都为文本词汇信息的提取增加了难度。微博平台提供的API可以方便微博语料的获取。另外,谷歌公司开发的Word2vec也可以将微博文本快速转化为计算机可以识别的数据,作为一种机器学习方法,他可以在深度学习算法应用以前对语料进行预处理,将语料自动加载到模型中,通过设定相关参数,模型算法会将其训练成对应的词向量,通常使用在文本词性分析、聚类和查找同义词等方面,为微博文本的情感分析提供了便捷的处理手段。[2]通过查阅文献可知,关于微博文本的情感分析的研究已经成为近几年数据挖掘领域的主要研究方向。目前,情感分析研究主要围绕着信息的抽取和情感倾向的判定,完成这两项工作必须对微博文本中的数据信息进行预处理,包括分词处理;网络表情符号识;词汇的情感分类汇聚以及情感判定。
1 LTP-Cloud(语言技术平台云)
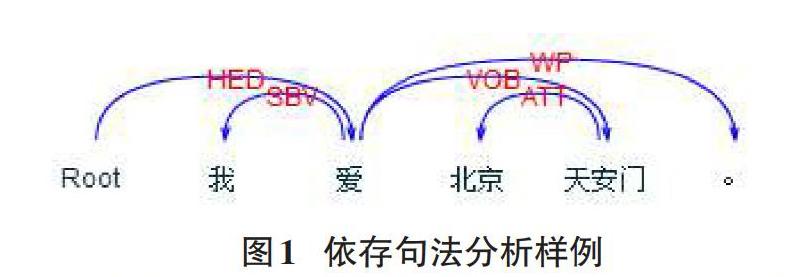
数据挖掘算法虽然在情感判定方面提供了一些方法,但其应用语境依然以英文语境为主,有关于中文语境环境下的研究较少,因为中文微博文本所处的中文语言结构复杂,语义表达多样,且微博用户趋于年轻化,文本包含的网络用语居多,所以中文微博文本的情感词的分类和判定方法带有自身的特点与难点。另外,目前针对中文微博的情感分析的研究集中在情感倾向性分析领域,在细致情感分类方面尚处于起步阶段。因其具有一定的学术研究价值和网络应用价值,也吸引了国内外专家、学者的关注。针对中文微博文本“短”的特点,本文提出了构建依存句法树的方法,对文本的情感类别进一步地细致分类。哈工大讯飞语言云是由哈工大和科大讯飞联合研发的中文自然语言处理云服务平台。LTP-Cloud可以实现分词、词性标注、命名实体识别、依存句法分析和语义角色标注五项功能。下面详细介绍本文用到的分词、词性标注和依存句法分析三项功能。依存语法(Dependency Parsing,DP)立足于词性标注,通过分析不同词性组合,制定相应规则,将句子从线性词串变为具有层次结构的树。针对不同的词性组合,可以综合得到不同的依存句法类别,而依存句法在语义角色分析时有着很重要的作用。如刘俊使用依存句法分析了汉语复句内各个分句的相似度,取得了很好的效果。[3]例如句子“我爱北京天安门。”的依存句法分析結果如图1所示:
分析结果显示,句子的核心是谓语“爱”,“爱”和“我”是主谓关系,即“我”是“爱”的主语,“爱”和“天安门”是动宾关系。“天安门”是“爱”的宾语。“天安门”和“北京”是定中关系,“北京”用来修饰限定“天安门”。从分析结果可知,依存句法分析能够揭示句子中不同词语之间的依存关系,更好地理解语义。例如,虽然“北京”紧邻“爱”之后,但是“爱”的宾语不是“北京”而是“天安门”。
2 依存句法汇聚规则
根据哈工大LTP定义,依存句法的标注有14种,考虑在汇聚时修饰词和情感词之间,或者修饰词和修饰词之间的汇聚规则,其中修饰词包含了程度词和否定词。本文针对修饰短语提出了以下汇聚规则。
(1)否定词修饰情感词
否定词修饰情感词会改变情感倾向,如“不喜欢”这个短语中,“不”作为否定词修饰“喜欢”。在此类关系汇聚时,因为否定词的出现仅仅是修饰情感词,自身不携带情感,因此不存在层级和削减的问题。本文针对此类情况,将否定词的否定修饰附加到被修饰的情感词倾向上,即改变情感词的倾向,比如由“喜欢”改为“厌恶”。
(2)程度词修饰情感词
程度词修饰情感词会改变情感强度,如“非常喜欢”这个短语中,“非常”作为程度词修饰“喜欢”。在此类关系汇聚时,因为程度词的出现仅仅是修饰情感词,自身不携带情感,因此不存在层级和削减的问题。本文针对此类情况,将程度词的强度修饰附加到被修饰的情感词倾向上,即改变情感词的强度,比如由等级为1的“喜欢”改为等级为2的“喜欢”。
(3)否定词修饰否定词
否定词修饰否定词即为双重否定,一般情况下不影响原来的情感倾向,对于情感程度的影响需要具体分析依存关系。如“不是不喜欢”中,第一个“不”作为否定词修饰了“是”,后面的“不喜欢”和“是”是动宾关系。在这个样例中,“不喜欢”自身是一个“厌恶”的情感短语,在动宾关系向上汇聚时会有一定的削减,而第一个“不”是对“是”的直接修饰,是在削减之后的否定修饰。最终,由于否定不会削减,而程度在汇聚时被削减,那么“不是不喜歡”最终的情感类别仍然是“喜欢”,但强度相比于“喜欢”有所降低。此处的例子其实不是严格的否定修饰否定的例子,而是否定修饰情感词作为情感短语削减后再次被否定词修饰的例子。
(4)否定词修饰程度词
否定词修饰程度词相当于对程度的否定,而非情感的否定,因此否定词修饰后,最终情感倾向未变,但是程度有所降低。如“不很喜欢”中,“不”修饰了“很”,然后才是“很”修饰“喜欢”。“很”作为程度词表现了一种情感等级的加强,但是“不”作为否定词对“很”这个程度词的否定使得最终的强度有一定的削减。“不很喜欢”这个情感短语仍然表现了“喜欢”这种情感类别,但是在强度上强于“喜欢”这个情感词,弱于“很喜欢”这个情感短语。因为汉语表达的复杂性,对于这种修饰的叠加需要根据不同的依存句法不同分析。如“不是很喜欢”这个短语和“不很喜欢”就不一样。“不是很喜欢”和上面“不是不喜欢”是同类型的结构。“不是很喜欢”这个短语相当于程度词修饰情感词作为情感短语削减后被否定词修饰,在情感类别上是“厌恶”,其强度和“不喜欢”相比孰高孰低取决于“很”这个程度词对“喜欢”在程度上的加强和动宾关系在汇聚时对程度上的削弱孰重孰轻。
(5)程度词修饰否定词
程度词修饰否定词相当于给否定加个强度,因为否定本身无强度可言,最终的强度会随否定词一起携带到情感词上。如“很不喜欢”中,“很”修饰“不”,然后才是“不”修饰“喜欢”。在汉语表达习惯中,“很”对于“不”的修饰通常被附加到情感词“喜欢”上。因此,“很不喜欢”在情感类别上是“厌恶”,在强度上比“不喜欢”更强,和“很喜欢”强度一致。
(6)程度词修饰程度词
程度词修饰程度相当于程度的叠加。通常情况下,人们不使用这种不太合乎语法规则的表达方式。在微博语料中,此类表达方式多用于表现强烈情感。如“非常极其喜欢”中,“非常”修饰“极其”,然后是“极其”修饰“喜欢”。对于此类的表述,其情感强度相比于“非常喜欢”和“极其喜欢”都要强一些,甚至比两个情感短语的并列相加的情感还要强。因此,在处理中,此类表述不仅仅是“非常喜欢”和“极其喜欢”强度的相加,更倾向于相乘之类的叠加处理。在具体问题中,要综合考虑程度词强度标注值与汇聚削减程度两个系数综合决定。
3 微博文本情感词分类过程
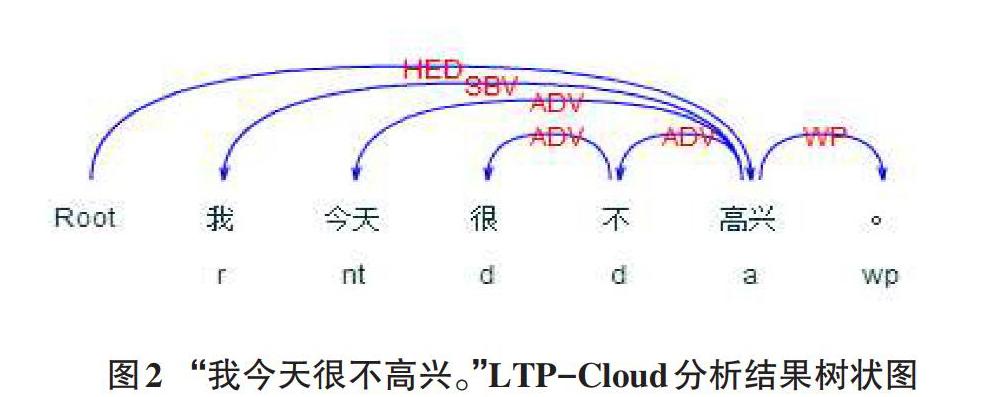
针对每条微博样例,首先要构建LTP-Cloud所需的字段,发起请求,得到依存句法关系。下面举例说明。使用“我今天很不高兴。”这个简单的例子进行分析。将这句文本作为待分析内容,向LTP-Cloud发送请求后得到结果如图2所示的。
观察图2可知,经过LTP-Cloud分析,“我今天很不高兴”这句话被分词,标注了词性,而且标注了不同词之间的依存句法关系。整个图显示为一种树状结构。虚拟节点“Root”作为树的根,其孩子节点为“高兴”,它们之间的修饰关系是核心关系。“高兴”有四个孩子节点,分别是“我”“今天”“不”和“。”,它们之间的修饰关系分别是主谓关系,状中关系,状中关系和标点符号。在这四个孩子节点中,除“不”以外,其他都是叶子节点。“不”有一个孩子节点“很”,它们之间的修饰关系是状中关系。“很”是叶子节点,整个树分析结束。
LTP-Cloud提供如上所示的树状分析结果的同时,也提供了xml形式的分析结果。xml分析结果如下所示:
<?xml version="1.0" encoding="utf-8" ?>
在xml形式的分析結果中,给出了和树状图一样的信息,只是形式不同而已。其中,每一个“word”节点均给出了当前词的序号,内容,词性,父节点,与父节点关系。如第一个“word”节点中,当前词id为“0”,内容为“我”,词性为“r”表示代词,父节点为“4”,即id为“4”的节点“高兴”,与父节点关系为“SBV”,即主谓关系。xml分析结果中的三个“arg”节点是语义角色标注的内容,与本文分析无关,不予考虑。
4 构建依存句法树
LTP-Cloud在提供界面演示样例的同时,也提供了通过API调用的形式。本节使用API调用,选择返回格式为PLAIN,构建句法树用于进行自下而上的情感汇聚。
API调用LTP-Cloud后,返回的PLAIN格式的分析结果为:
我_0 高兴_4 SBV
今天_1 高兴_4 ADV
很_2 不_3 ADV
不_3 高兴_4 ADV
高兴_4 -1 HED
。_5 高兴_4 WP
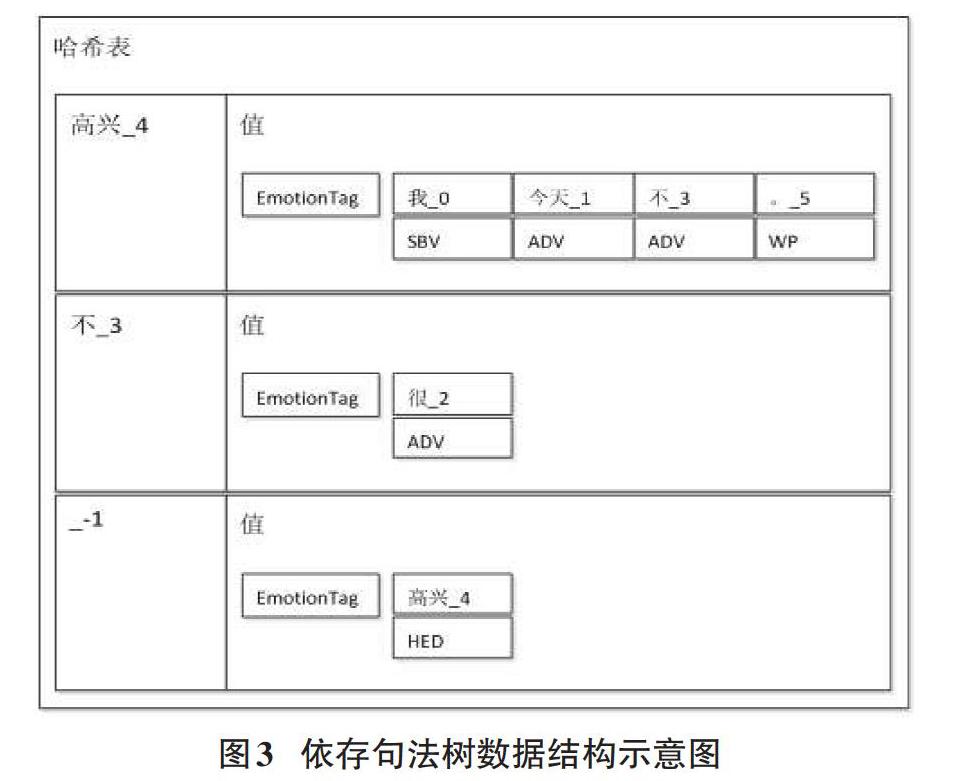
这6组数据代表了文本“我今天很不高兴。”中的所有依存关系及其相关词语和序号。本文构建如图3所示的数据结构完成以树状结构存储上述信息的任务。
在图3中,整体的数据结构是一个哈希表。在对依存关系依次读取时,逐步完成哈希表的构建。下面举例说明依存关系句法树构建过程。
5 结束语
微博文本的情感分析作为数据挖掘的研究热门领域,随着微博使用人数的增长,和网络舆论监管力度不断加深,目前针对中文微博的情感分析的研究主要集中于倾向性分析领域,在细致情感分类方面尚处于起步阶段。因其具有一定的学术研究价值和网络应用价值,也吸引了国内外专家、学者的关注。针对中文微博文本“短”的特点,本文提出了构建依存句法树的方法,对文本的情感类别进行了近一步地细致分类。
参考文献:
[1]http://www.xinhuanet.com/newmedia.
[2]袁婷婷,杨文忠,仲丽君,等.一种基于性格的微博情感分析模型PLSTM[J/OL].计算机应用研究:1-6[2019-01-04].
[3]来火尧,刘功申 . 基于主题相关性分析的文本倾向性研究[J]. 信息安全与通信保密, 2009(3):77-78.
[4]李小龙.基于统计的分词系统字典模型研究[J].湖北工业大学学报,2010,25(05):71-73+79.
[5]刘钢. 基于文本情感分析的企业舆情监测方法研究[D].大连海事大学,2018.
[6] Yu Hong. Towards answering opinion questions: separating facts from opinions and identifying the polarity of opinion sentences [J]. Pediatrics, 2003, 116(3):58-59.
【通联编辑:王力】
