
深度Q 学习的二次主动采样方法
2019-11-01 03:53赵英男唐降龙
自动化学报 2019年10期
赵英男 刘 鹏 赵 巍 唐降龙
强化学习是解决序贯决策问题的一种途径[1].智能体在环境中做出动作,得到环境的奖励,根据奖励值调整自己的策略,目的是最大化累积回报.智能体通过这样不断与环境进行交互,学习到最优策略.从与环境的交互中学习是自然界有机生物体主要学习方式之一[2].智能体通过强化学习方式,在极少先验知识条件下可习得最优策略.
强化学习主要包含两类算法[3−4],一类是基于值函数估计的方法,如Q-learning[5]和SARSA[6]等,在智能体与环境的不断交互中得到最优值函数.这类方法的好处是过程简单,易于实现,但是无法解决连续动作空间的问题.另外一类是基于策略表示的方法,也称为策略梯度法[7],其中典型方法包括REINFORCE 方法[7]、Actor critic 方法[8]等,其主要思想是将参数化策略与累积回报联系起来,不断优化得到最优策略.这类方法可以解决连续动作空间的问题,但是容易收敛到局部最优解中.这两类算法是强化学习的经典算法,仅能够解决一些小规模问题,在面对现实世界中大规模,复杂的问题时往往束手无策[3],这限制了强化学习的发展.
强化学习与神经网络的首次结合可以追溯到1994 年,Tesauro[9]利用神经网络将近似值函数应用到了Backgammon 游戏上,并取得了很好的效果.近年来,深度神经网络与强化学习相结合,形成了深度强化学习方法.利用深度神经网络[10−11]的泛化能力,特征提取能力,在许多领域取得了突破[12].在人机对抗领域,结合深度强化学习和蒙特卡罗树搜索方法[13]的围棋智能体AlphaGo[14−16]先后战胜了世界围棋冠军李世石、柯洁;将动作值函数用深度神经网络的方式近似,同时使用Q-learning 更新规则来迭代动作值函数的方法称为深度Q 学习.实现深度Q 学习的一种方式是深度Q 网络.使用深度Q 网络[17−18]训练的智能体在视频游戏上的表现达到或者超过了人类专家的水平;在自动导航领域,深度强化学习中的A3C 方法结合辅助任务来帮助智能体更快实现在未知地图中的导航[19],其中辅助任务包括深度预测和环形检测,由循环神经网络[20]实现;在机器翻译领域,文献[21]提出了一种对偶学习机制,结合强化学习中的策略梯度法,提升了翻译模型的性能;在机器人控制领域,文献[22−23]将深度学习与策略梯度结合提出了深度确定性策略梯度法,解决了连续动作空间的控制问题.
目前仍存在一些因素制约深度强化学习的应用:1)智能体不具备不同任务之间的泛化能力[24],在面对全新的任务时,需要重新进行训练.2)模型稳定性和收敛性难以得到保证[25].3)智能体为了能够适应环境往往需要与环境进行大量交互,每次交互除了会增加时间和成本,还会带来风险.如何减少交互次数是本文要研究的问题.
减少智能体与环境的交互次数的一种思想是高效地利用已有的样本.具体方式有:1)采用迁移学习的方式[26],复用训练样本[27]或策略[28],将源任务中的样本或策略迁移到目标任务中,这种方法的挑战在于难以衡量源任务和目标任务的相似性,盲目迁移反而会降低效率.2)根据已经采样得到的样本对环境进行建模[29−30],然后利用建立的模型产生样本,减少智能体与环境交互次数.这种方法对环境模型的准确性要求较高.3)在智能体训练时主动选择[31−33]那些对训练有促进作用的样本,典型方法有优先经验回放[31],利用样本训练产生的误差(Temporal difference error,TD-error)作为优先级,提高已采集样本的利用效率,加快收敛.
哪些样本对训练有更大的促进作用,如何从已采集的样本中选择这样的样本是本文研究的问题.智能体执行一系列动作,得到回报,形成经验,从经验中选择样本训练智能体的强化学习采样方法称作经验回放法[33].在强化学习中,智能体从失败的或效果不好的经验中选择样本与从成功的或效果好的经验中选择样本都能得到优化的策略,但是从成功的或效果好的经验中选择样本可以加速学习的过程.本文在分析样本所在序列获得的累积回报对深度强化学习效果影响的基础上,提出了二次主动采样方法.首先,计算经验池中序列的累积回报,根据序列累积回报的分布对序列进行优先采样,然后,在被采样的序列中以TD-error 的分布对样本进行优先采样.两次采样在分别考量累积回报大的序列中的样本对学习的促进作用和TD-error 大的样本对Q网络的收敛加速作用的同时,在经验池中累积回报小的序列中的样本和TD-error 值小的样本以较小的概率被采样,从而保证了训练样本的多样性.在Atari 2600 视频游戏平台上进行验证,实验结果表明,本文方法加快了深度Q 网络(Deep Q-network,DQN)的收敛速度,提高了经验池中样本的利用效率,也提升了最优策略的质量.
1 相关工作
1.1 强化学习
强化学习解决的是序贯决策问题,整个过程可以用马尔科夫决策过程(Markov decision process,MDP)来进行建模:智能体在离散时间步t=1,2,3,···内与环境进行交互,在每个时间步t,智能体得到环境状态的表示St ∈S,其中S是所有状态的集合,基于当前状态表示St选择一个动作At ∈A(St),A(St)是状态St可采取动作的集合.一个时间步后,智能体得到了一个标量奖励Rt+1∈R,并且到达一个新的状态St+1.这个过程一直持续下去,直到智能体转移到终止状态[1].智能体从初始状态转移到终止状态这一系列状态转移可以被描述成-这样一个序列,这样一个序列在强化学习中被称为一个周期(Episode).从t时刻开始,到T时刻终止,智能体在一个周期中获得的累积回报为:
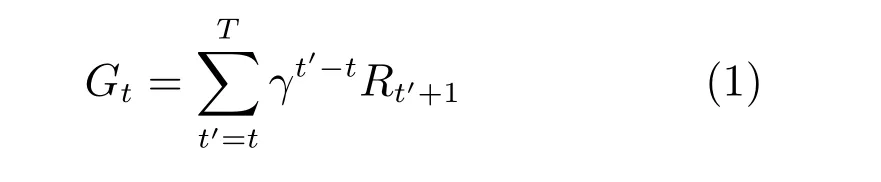
其中,0≤γ ≤1,称为折扣因子,折扣因子的作用是对不同时间步获得的奖励赋予不同的权重,使得距离当前时间步越远的奖励权重越小,强化学习的任务是找到一个策略使得Gt的值最大.定义动作值函数为:

式(2)表示智能体处于状态s,采用动作a,然后执行策略π可以获得的累积期望回报,定义动作值函数更新公式为:
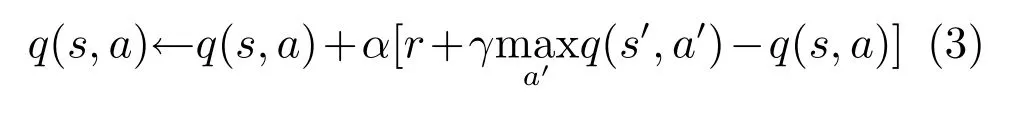
利用式(3)不断迭代,最终q(s,a)将收敛到q∗(s,a),即最优动作值函数[6].通过迭代式(3)来得到最优动作值函数的方法被称为Q-learning.为了使其具有泛化能力,扩大其应用范围,将深度神经网络和Q-learning 结合起来,形成深度Q 网络[18].
1.2 深度Q 学习
深度Q 网络(Deep Q-networks,DQN)是一种典型的深度Q 学习方法[34].DQN 的特点有:1)DQN 充分发挥了深度神经网络强大的特征提取能力和强化学习适应未知环境的能力,实现了一种端到端的训练方式,同时仅仅需要极少的先验知识,便能够在很多复杂任务中表现出色.2)利用经验回放和目标网络两个技术保证了在使用非线性函数逼近器的情况下,动作值函数的收敛.3)使用相同的超参数,网络结构和算法能够在多个不同的任务中表现出色,算法具有较强通用性.
经验回放[28]是DQN 训练的一种典型方法.经验回放方法打破了训练样本间的相关性,保证了值函数的收敛.该方法将智能体与环境交互产生的样本保存下来,形成一个经验池,每次训练时随机从经验池中选择若干个样本训练Q-网络,每个样本是四元组,利用这个样本,定义与该样本对应的第i次迭代的目标动作值函数为:
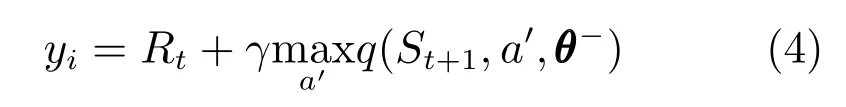
其中,θ−代表目标值函数网络的参数.此时当前神经网络计算出来的动作值函数为q(St,At;θ).定义损失函数Li(θ)=(yi −q(St,At;θ))2,利用梯度下降法不断更新权重θ,完成DQN 的训练,得到最优动作值函数.
文献[35]中提出了Double DQN,解决了DQN中对动作值函数过估计的问题;文献[36]中提出对偶神经网络结构,将对动作值函数的估计分解成状态值函数估计和优势值函数估计两个部分,能够学习到更好的策略;文献[31]针对等概率从经验池中抽取样本的操作提出了改进,利用每个样本训练产生的TD-error,即目标值和估计值的误差,来表示样本的重要性,为经验池中样本赋予不同的优先级,提升了DQN 算法的表现.
1.3 主动采样问题
在深度强化学习算法训练过程中,为了减少训练样本间的相关性,常采用经验回放的方法,将智能体产生的样本存储起来,在训练时随机选择若干样本进行训练,提高了算法的收敛性和稳定性.经验池中样本数量庞大,如何从经验池中选择样本来提高深度强化学习的收敛速度是主动采样问题.
文献[31]中提出了优先经验回放方法,将每个样本训练产生的TD-error 作为样本的优先级,优先级越大,样本被选择的概率就越大.该方法可以更有效率地回放样本,而且能够提升最优策略的表现.但是该算法仅从加速深度神经网络收敛速度的角度出发,考虑样本的TD-error 对训练的影响,忽略了样本所在序列的累积回报对强化学习的作用.
本文提出二次主动采样方法.首先根据经验池中序列的累积回报分布,以更大的概率选择累积回报大的序列.然后,在被选择的序列中根据TDerror 分布选择样本来训练Q 网络.该方法从累积回报的作用和深度神经网络误差梯度两个方面加速DQN 的学习过程.强化学习的目的是获得最优策略使累积回报最大化.从累积回报小的序列中选择样本会使智能体以更大的概率避免错误,而从累积回报大的序列中选择样本会使智能体以更大的概率获得更大的累积回报,这与强化学习的目的一致.本文方法并没有完全放弃对累积回报小的序列中样本的采样,只是这类样本被采样的概率小,从而保证了样本的多样性.在Atari 2600 视频游戏上的实验表明,本文提出的方法提高了经验池中样本的利用效率,同时也改善了最优策略的质量.
2 二次主动采样方法
本文提出的方法建立在累积回报大的序列中的样本以更大的概率对DQN 学习有促进作用的基础之上.首先,在经验池中按序列组织样本,然后,根据各序列累积回报的分布生成序列采样优先级,依据优先级在经验池中对序列采样.最后,在已选择的序列中根据TD-error 分布生成样本采样优先级,在序列中选择样本,训练DQN.
2.1 序列累积回报对训练的影响
在优先经验回放方法中[21],算法以样本训练产生的TD-error 作为优先级,并没有考虑到样本所在序列取得的累积回报.事实上,在样本选择时考虑样本所在序列的累积回报是十分必要的.强化学习是包括人类在内的高级智能体的一种基于行为的学习方式.智能体产生的每一个序列是为了完成某件事做出的一次尝试,回报就是对一系列行为取得结果的评价.在智能体再次面对相同或者相似的任务时,首先会回忆以前的经历,如果能够搜索到达到目的的经历,那么只要按照相同的策略再执行一次即可.如果没有搜索到达到目的的经历,也会更倾向于学习(尝试)那些较为接近目的的经历.这表明在成功的经验中,智能体在更多状态下都采用了有效动作,这样只需要经过少量的改进,就能达到目的.本文提出的方法也源于此思想[37],成功的或者接近成功的序列,其中含有有效动作的样本就越多,就应该被更多地回放,从而提高DQN 的学习速度,提升学习到的策略的质量.
平衡杆(Cartpole)问题是强化学习中的经典问题.如图1 所示,平衡杆由两部分构成,方块是一个小车,上面连接着一个杆,假设不存在摩擦力,平衡杆的目的是通过施加给小车向左或者向右的力维持上面杆的平衡.每次做出动作,杆子如果没有倒下,就会获得值为1 的奖励.平衡杆问题动作空间大小为2,状态空间是无限的,适合用来验证DQN 算法.接下来在Cartpole 中进行两个说明性实验来验证假设.
1)累积回报与有效动作数量的关系
本文提出的方法基于一个假设:获得累积回报越大的序列,其中含有有效动作的样本数量越多.为了验证这一假设,首先训练出一个已经收敛的网络模型M∗,即输入状态,可以输出最优动作,作为有效动作.然后利用DQN 算法训练另外一个网络模型M,训练过程中将智能体产生的序列保存下来,同时记录下每个序列得到的累积回报.在某一时刻对序列进行采样,按照累积回报从小到大的顺序对序列进行排序.第一次从后50% 的序列中进行采样,也就是从累积回报较大的序列中选择样本,第二次从前50% 的序列中进行采样,也就是从累积回报较小的序列中选择样本.两次采样的样本数量相同,均为500 000.遍历每一个样本-,将状态s输入到M∗中,得到有效动作a∗,判断样本中的动作a和有效动作a∗是否相同.
实验结果表明,在累积回报大的序列中取得的500 000 个样本中,含有有效动作的样本的数量为297 428 个,在累积回报小的序列中取得的样本中,含有有效动作的样本的数量仅为208 286 个.前者的数量比后者多出42.8%.
2)累积回报对DQN 训练的影响
另外,结合优先经验回放方法[31],对于平衡杆问题验证不同累积回报对DQN 学习的影响.程序采用-贪心策略来控制智能体探索与利用的平衡问题,探索因子设置为0.1.智能体与环境最大交互次数设置为100 000,序列采样数量设为10.若智能体产生的最近一百个序列累积回报的均值达到199,即为收敛状态,程序停止.
对三种情况进行实验:
情况A.经典的优先经验回放方法[31],没有考虑序列回报.
情况B.将经验池中的N个序列按照累积回报大小从大到小排序,在前10% 序列中随机选取8 个序列,从剩余90% 序列中随机选取2 个序列,再利用优先经验回放方法对这10 个序列的样本进行采样.
情况C.将经验池中的N个序列按照累积回报大小从大到小排序,在后10% 序列中随机选取8 个序列,在剩余90% 序列中随机选取2 个序列,再利用优先经验回放方法对这10 个序列的样本进行采样.
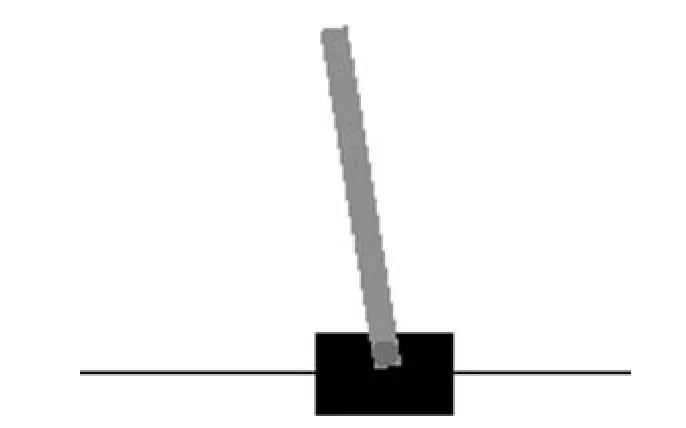
图1 平衡杆环境示意图Fig.1 The diagram of cartpole
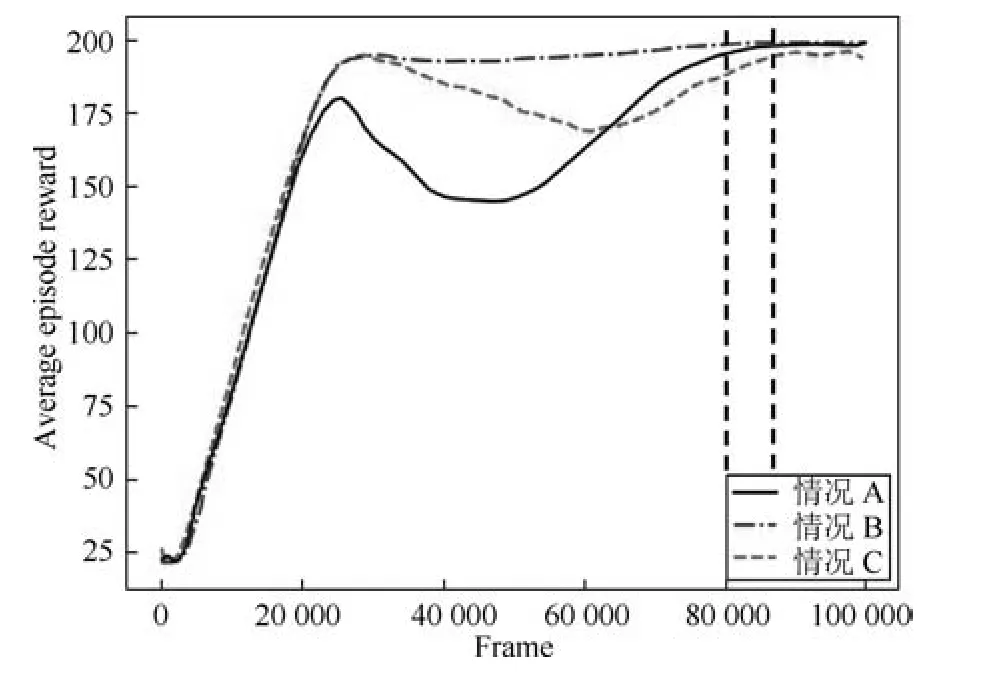
图2 平衡杆在三种情况下的对比实验Fig.2 The cartpole comparison experiments in three cases
为了避免偶然性,每种情况运行10 次,图2 中展示的为取平均后的结果,实验结果如图2 所示.图2 的横坐标代表智能体与环境的交互次数,纵坐标代表智能体产生的最近100 个序列累积回报的均值.下面对实验现象进行说明:
1)从累积回报较小序列中样本学习的DQN(情况C)没有达到最优策略.
2)不考虑序列累积回报的DQN (情况A)达到了最优策略,但学习过程中波动较大.
3)从累积回报较大序列中样本学习的DQN(情况B)最终达到最优策略,而且学习过程中回报平稳,学习过程中回报平稳带来的一个直接好处就是减少了训练过程中产生的风险.
4)从累积回报较大的序列中选择样本的训练方法(情况B)在80 000 帧交互后使DQN 达到收敛;用优先经验回放方法(情况A)选择样本在89 000帧交互后使DQN 达到收敛.
这表明从累积回报大的序列中选择样本这种方法能够使DQN 更快达到最优策略.上述三种情况的对比实验表明,累积回报大的序列中的样本对训练更有促进作用.
2.2 序列采样方法
从累积回报大的序列中选择样本,会增加含有有效动作样本的数量,进而加速DQN的收敛.下面从DQN 训练过程来解释含有有效动作的样本对DQN 学习的促进作用.经验池用E={l1,l2,···}表示,其中li=为经验池中的第i个序列,是序列li中的一个样本.当智能体处于状态St时,如果E中有两个序列lm,ln中的样本和均可以回放,根据式(3)回放使动作值函数收敛到回放使动作值函数收敛到q∗(St,Ant).
在k时刻,智能体处于状态Sk,选择样本进行回放,即在k时刻,采用动作Ak使智能体的状态由Sk转移到St,动作值函数更新为:

DQN 训练的损失函数为L(θ)=(y −q(s,a;θ))2,其中其中y被称为目标值,与监督学习中目标值是固定的不同,在DQN 中目标值是不断变化的,而且有很多时候目标值不准确,这就造成了DQN 收敛速度慢,训练过程不稳定等问题.本文提出的二次主动采样方法,首先从经验池中选择累积回报大的样本序列.然后从样本序列中选择TD-error 大的样本进行训练,能增加参与训练的含有有效动作样本的数量.两次采样中的第一次采样保证了DQN 训练的损失函数中目标值的稳定性,第二次采样加速了动作值函数迭代的收敛速度.
尽管累积回报大的样本对DQN 训练有更大的促进作用,但是样本多样性也是保证DQN训练收敛的一个重要方面.本文根据序列累积回报的分布构造对经验池中序列的采样概率.设经验池为E={l1,l2,···,lm},其中li=为经验池中的第i个序列,是序列li中的一个样本.序列li中的样本数量用|li|表示.第i个序列取得的累积回报为令pi=Gi+为第i个序列的优先级,其中是一个极小的正数,目的是保证所有序列的优先级均大于0.li被采样的概率为:
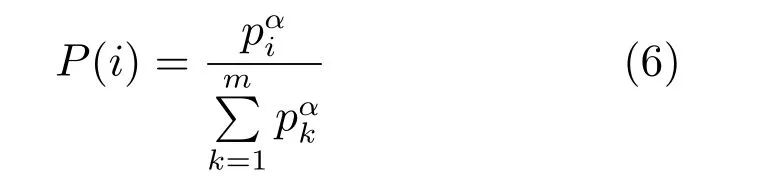
其中,α决定了优先级所占比例,当α=0 时,对序列的采样退化为均匀采样.用P(i),i ∈{1,2,···,m}对经验池E中的序列采样,使累积回报大的序列以更大的概率被选择,同时累积回报小的序列也有机会被选择.在保证累积回报大的序列中样本以更大的概率参加DQN 训练的同时,也保证了样本的多样性.
2.3 从序列中选择样本

本文提出的二次主动采样方法,首先以序列的形式组织经验池E.根据序列累积回报的分布对经验池E中的序列进行采样,形成一个小型的经验池然后在经验池中根据样本的TD-error 分布进行第二次采样,得到用于DQN 训练的样本.第一次采样以累积回报作为序列选择的准则,使得到的经验池中的样本中以更大的概率来自于累积回报大的序列.在第二次采样中,以DQN 训练的TD-error 为依据,使能够加速DQN 收敛的样本以更大的概率参加DQN 训练.本文提出的二次主动采样方法从样本所在序列的性质(累积回报)和样本在DQN 迭代中加速作用(TD-error)两方面出发来选择样本.用本文方法选择的样本既可以获得最优策略,也保证了DQN 的收敛速度.
本文提出的二次主动采样方法首先以累积回报为标准从样本池中选择序列,再以TD-error 为标准从样本序列中选择样本.两次采样的顺序是不能交换的.如果忽略样本序列导致的累积回报,先从样本池中选择TD-error 值大的样本来更新动作值函数,这样的样本所在的样本序列未必使累积回报值得到优化.Q-learning 的目标是在某个状态下得到一个动作使累积回报最大化,本文提出的二次采样方法的基本思想是在累积回报大的样本序列中选择TD-error 大的样本会使Q-learning 以更快的收敛速度获得最优策略.
2.4 算法总结
算法1.二次主动采样算法
输入.训练频率K,采样序列数量N,奖励折扣因子γ,样本批量大小k,指数α,学习率η,训练终止时间步T,算法初始经验池容量size,重要性采样权重β,目标Q 网络更新频率L
输出.Q 网络参数
初始化.经验池E为空,初始化Q 网络和目标Q 网络参数为θ和θ−,优先级=1,单个序列存储经验池h


为了方便对序列的采样,算法在第3∼7 步将整个序列保存到经验池中.在第8 步中开始训练,训练前判断当前时间步是否大于size,这里的size指的是经验池初始化容量,目的是在经验池中存储一些样本,方便接下来的训练.第9∼27 步为二次采样过程.其中,第9∼19 步为算法的第一部分.首先计算每个序列的累积回报,再计算优先级,最后得到序列被采样的概率.第15∼19 步根据优先级采样N个序列构成小经验池第19∼27 步为样本采样和训练过程.第23 步计算TD-error 利用的是Double DQN[18]算法,这种计算方式可以减少DQN 对值函数的过估计.第28 步是更新目标网络参数过程,是一种保证DQN 收敛的一种方法,将目标值网络和当前值网络分开,使得目标值网络的权重在一段时间内保持不变,从而使得目标值也会在一段时间内保持不变,使得训练过程更加稳定.
除深度Q 学习以外,还有许多强化学习方法如SARSA 算法[38]、Actor critic 算法[39]都可以采用经验回放方式来提升样本利用率,加快收敛速度.经验回放就是将样本保存在经验池中,训练时从经验池中选择样本.本文提出的二次主动采样方法也适用于其他涉及到经验回放的强化学习的样本选择过程.
2.5 时间复杂度分析
本文提出的算法主要分成两个部分,首先是序列采样,主要思想是序列优先级越大被采样概率越大,采用的主要方法如下:对每个序列的优先级进行加和记为sum,序列优先级最小值为,在到sum 之间随机选一个数random.接下来遍历整个序列集合,统计遍历到的序列的优先级之和,如果大于random,则选择这个序列.假设经验池中共有M个序列,采样的序列数量为N个.该方法需要遍历所有序列,时间复杂度为O(MN).
算法第二部分是对小经验池进行优先经验回放,假设采样序列数量为N,平均每个序列含有K个样本,因此小经验池的容量为KN.这里采用与第一部分相同的采样方法,假设采样样本数量为m.可知时间复杂度为O(mKN).
因此本文提出的算法总体时间复杂度为O(MN)+O(mKN)).由于经验池容量固定,因此本文提出的方法运行时间在DQN 训练过程中基本保持不变.
3 实验结果与分析
3.1 实验平台描述
本文在openAI Gym(https://gym.openai.com)上的Atari 游戏平台进行实验.Atari 游戏平台[40]有两个特点:1)仅仅以图像作为输入,与人类玩游戏的方式相同.2)游戏种类多样,包括射击类、动作类、策略类等,适合验证算法的通用性和泛化能力.Atari 平台上的部分游戏界面如图3 所示.Atari 平台是当前深度强化学习的主流测试平台.
实验硬件平台是Dell-T630 工作站,处理器为两个Intel(R)Xeon(R)CPU E5-2650 v4,显卡为3 块GTX-1080 TI 和1 块GTX-1070,工作站内存64 GB,操作系统为Ubuntu 16.04.
3.2 实验参数设置
本文提出的方法中有一个超参数需要设置,即序列采样的数量,序列采样数量过少,会使样本失去多样性,DQN 训练发散;采样过多则会使得被采样的序列构成小型经验池变大,导致第二次采样时间变长,算法运行时间变长.为了选择适当的序列采样数量,在平衡杆上用6 个不同的序列采样数量进行实验.每个实验运行10 次.算法的平均运行时间和平均收敛步数列于表1.

表1 平衡杆问题在不同采样序列数量下的平均运行时间和平均收敛步数Table 1 Average convergent step numbers and consuming time using different sampling episode numbers in cartpole

图3 Atari 游戏截图Fig.3 Screenshots of some games
由表1 可以看出,随着采样序列数量的增加,算法运行时间逐渐变长,平均收敛步数也逐渐减少,但是采样序列数量大于40 时,DQN 的平均收敛步数增加,原因是当采样序列的数量过大时,则会使得算法逐渐退化成为优先经验回放方法,进而造成性能下降.因此将采样序列数量设置为40.
DQN 每次迭代前,从已被采样的序列中选择样本的数量为32.折扣因子γ设置为0.99.探索因子设置为随着时间步数增加而分段递减形式,如图4所示.在训练开始阶段,探索因子取较大值,智能体以更大概率探索,在训练后期,取较小的值.智能体以更大的概率利用已获得的策略.
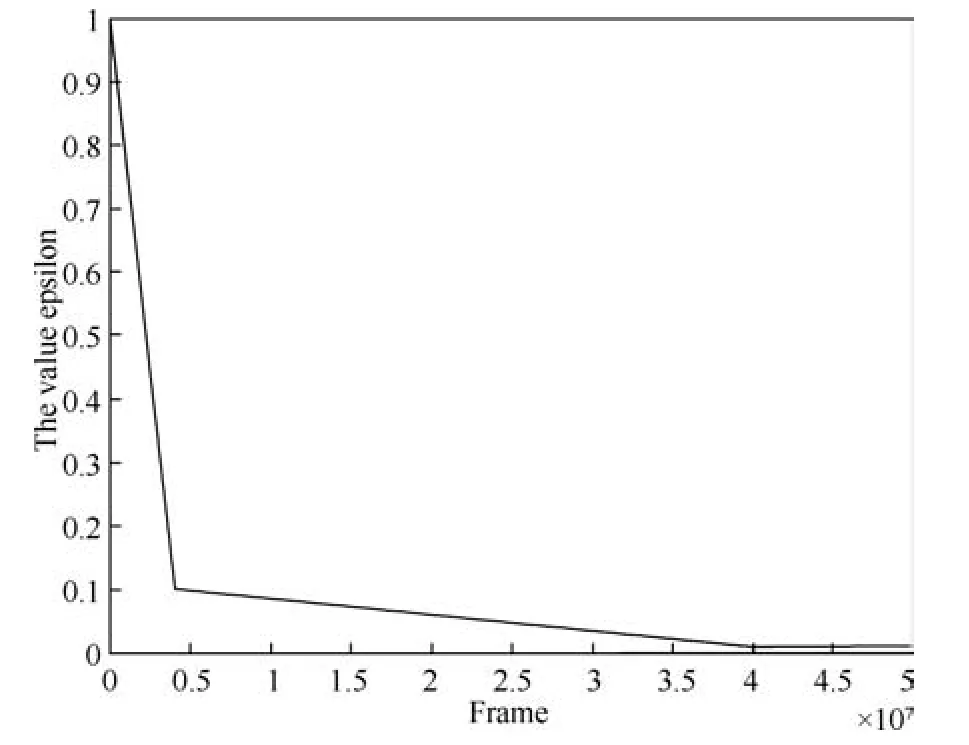
图4 值变化曲线Fig.4 The value of
本文提出的二次主动采样算法,首先按照累积回报大小对序列进行采样构成一个较小的经验池,再按照优先经验回放的方法在其中进行采样.这种方法与优先经验回放的不同之处在于,优先经验回放方法更加频繁地回放那些在整个经验池中TDerror 值较大的样本,而本文提出的方法更加关注那些所处序列获得的累积回报较大同时TD-error 值也较大的样本,这些样本是对训练更有促进作用的样本.在进行对比实验之前,首先选择蜈蚣(Centipede)这个游戏,对其经验池中样本进行了分析,训练曲线图如图5 所示,横坐标为交互次数,纵坐标为平均累积回报.分析时考虑样本所处序列的回报和样本TD-error 两个方面.将训练过程中某一时刻的经验池保存下来,记录下每个样本的TD-error值和所处序列累积回报值,将TD-error 从大到小排序,经验池中样本总数为106,取出TD-error 值较大的前3×105个样本,并得到其所处序列获得的累积回报,这里分别记录时间步为4×107和1.6×108两个时刻的经验池,如图5 中黑色虚线所示.将样本的累积回报分别绘制成分布图如图6(a)和(b).
图6 中横坐标为样本所处序列获得的累积回报,纵坐标为样本数量.可以发现,多数样本其所在序列累积回报较小,同时也存在一部分样本所处序列累积回报较大,即处于图中右侧部分的样本,这部分的样本是对DQN 训练更有促进作用的样本,即具有TD-error 值较大,同时所处序列累积回报较大两种性质的样本.实验结果表明具有这两种性质的样本在游戏训练不同时刻都是存在的.打砖块(Breakout)和坦克大战(Robotank)也有相似的现象,得出的样本分布情况如图6(c)和(d)所示.
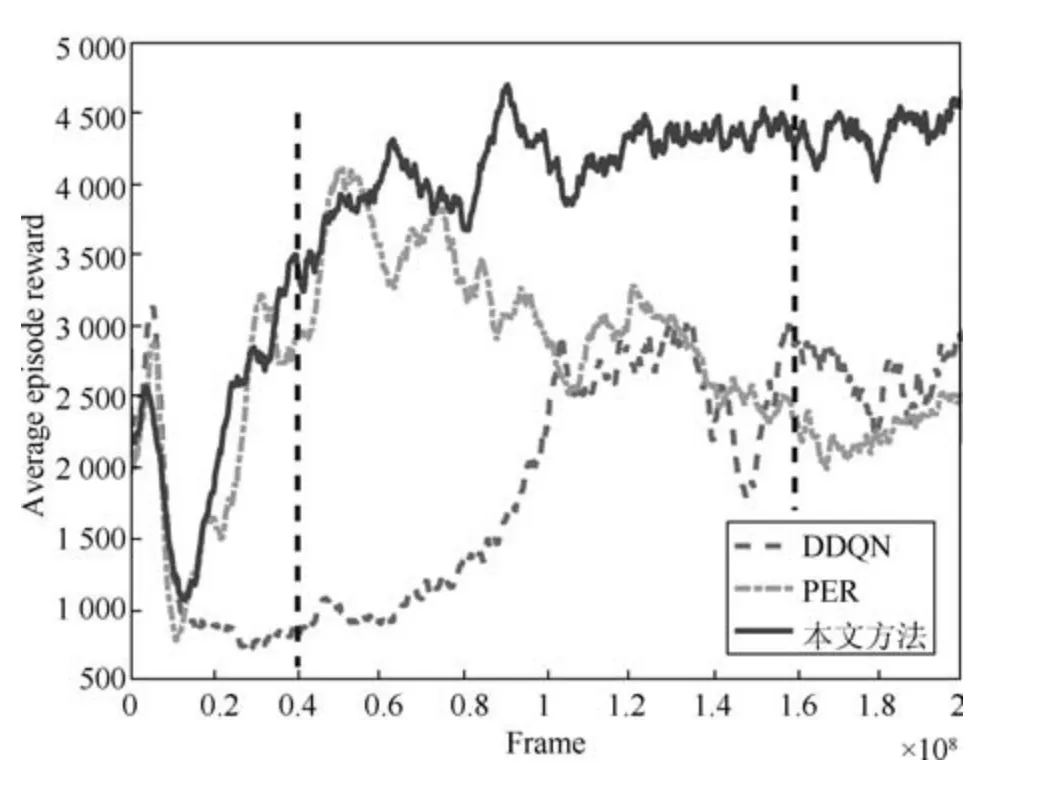
图5 蜈蚣游戏训练曲线Fig.5 The training curve of centipede
本文提出方法首先从样本池中选择累积回报大的样本序列,再从这些序列中选择TD-error 大的样本对DQN 训练以提高其收敛速度.这个过程包含两次选择,一次是对样本序列的选择,另一次是在已选择的样本序列中对样本进行选择.如果交换这两次选择的顺序,先从样本池中选择TD-error 大的样本,再根据已选择样本所在序列的累积回报的大小对已选择样本进行二次筛选,则不能达到提高DQN收敛速度的效果.用平衡杆实验来验证样本采样顺序对DQN 收敛性的影响.对两种选择顺序分别进行10 次实验,每次实验最大交互步数为100 000.实验结果列于表2.实验结果表明,本文提出方法的样本选择顺序取得了更好的收敛效果.

表2 样本选择顺序对比实验(平衡杆)Table 2 The comparison experiments in different sampling order (cartpole)
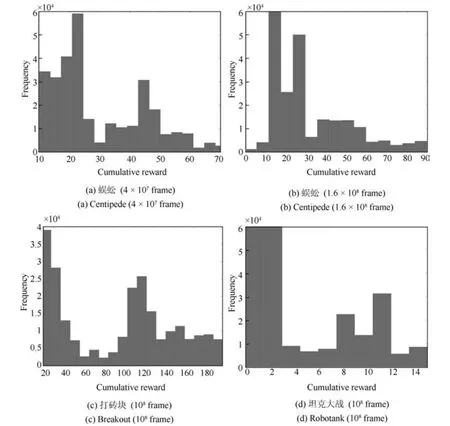
图6 经验池样本分布图Fig.6 The distribution map of samples
3.3 对比实验
本文选择Double DQN (DDQN)[35]和优先经验回放(Prioritized experience replay,PER)[31]作为对比算法,其中DDQN 主要思想是在经验池中随机选择样本,进行训练,PER 主要思想是将样本训练产生的TD-error 作为优先级,然后在经验池中有选择地采样训练,本文方法则是在PER 基础上增加了对序列采样的过程,提升了样本的利用效率.算法评价标准包括:1)算法收敛速度.2)算法得到最优策略的质量.实验训练曲线如图7 所示.图7 横坐标为交互次数,纵坐标为平均累积回报.由图7 可以看出,本文提出的方法与优先经验回放和Double DQN 算法相比,在多数游戏中能够使用更少的交互次数达到相同的平均回报,在收敛速度上要优于这两个算法.智能体学习到的策略可以通过模型参数得到,训练过程中,每5×105时间步保存一次模型参数,找到训练曲线中最高点将那一时刻保存的模型参数作为最优策略,然后利用文献[35]提出的评价方法,也称为无动作评价(No-op action)来评价不同算法得到的最优策略的优劣.具体做法在1∼31 之间随机选一个数字f,在序列的前f帧不执行动作,保证每个序列有不同的起始状态,将探索因子设置成0.05,然后按照要测试的策略执行100 个序列,取序列平均得分,用该得分评价策略的优劣.由于每个游戏都有自己不同的分数计算方式,为了使算法能够在不同游戏间进行比较,利用式(9)对分数进行归一化:
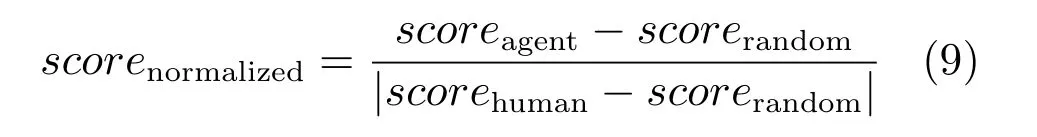
其中,scorerandom代表智能体随机采用动作得到的分数,scorehuman代表人类专家的得分,scoreagent代表采用本文算法学习到的策略得到的分数.人类专家和随机智能体的得分数据来自于文献[7],DDQN 算法的得分来自于文献[35],PER 算法的得分来自于文献[31],其中有些数据与实际测试不同,以实际测试为准.对归一化之后的分数进行统计得到表3.
每个游戏的具体得分如表4 所示,每个游戏的归一化得分如表5 所示.
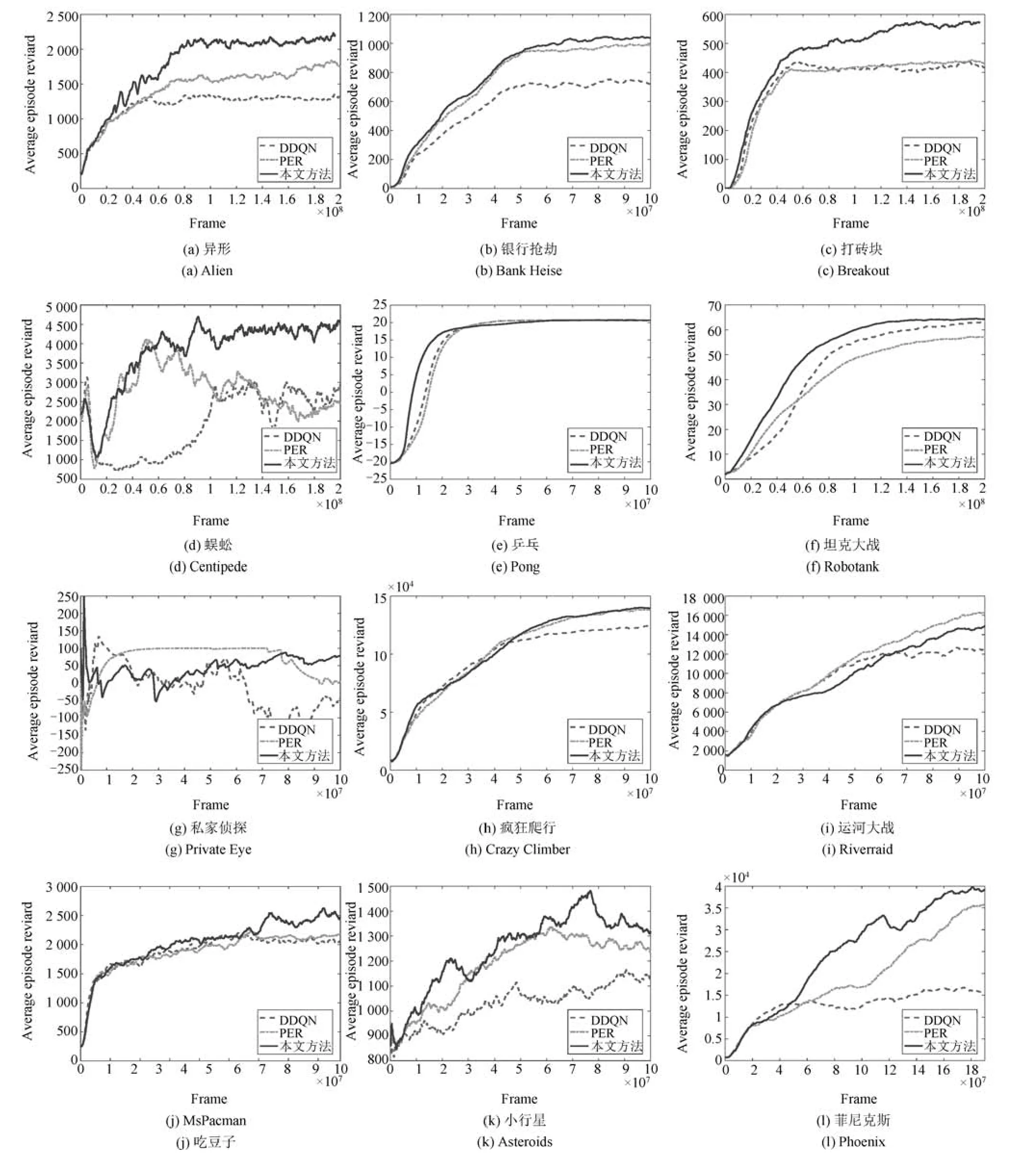
图7 Atari 游戏训练曲线Fig.7 The training curves of Atari games
本文提出的方法在打砖块(Breakout),行星大战(Asteroids)、蜈蚣(Centipede)、坦克大战(Robotank)等游戏中表现出色,能够取得更高的分数.原因在于在这类游戏中,智能体目标较为明确而且单一,即为消灭敌人或者击打砖块,这样获得累积回报较大的序列相对于获得累积回报较小的序列会有指导意义.在运河大战(Riverraid)游戏中,智能体可以从不同途径获得奖励,包括消灭敌人(如图8(a)),获得补给(如图8(b)),和消灭补给(如图8(c)),这使得获得不同累积回报的序列之间没有明显的优劣关系,累积回报作为序列采样的依据这一特点没有表现出来.所以本文方法在运河大战游戏中表现不佳.

表3 全部游戏的规约得分总体统计表Table 3 Summary of normalized score on all games

表4 全部游戏实际得分统计结果Table 4 Scores on 12 Atari games with no-ops evaluation
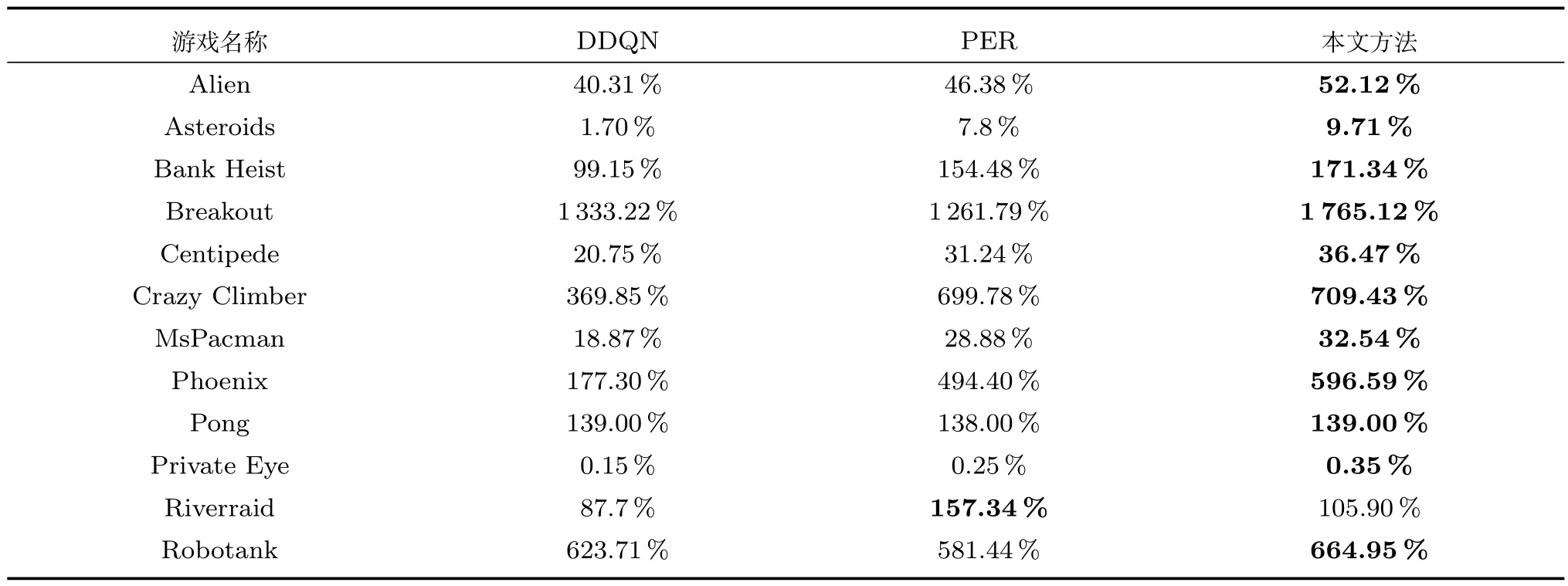
表5 全部游戏规约得分统计结果Table 5 Normalized scores on 12 Atari games
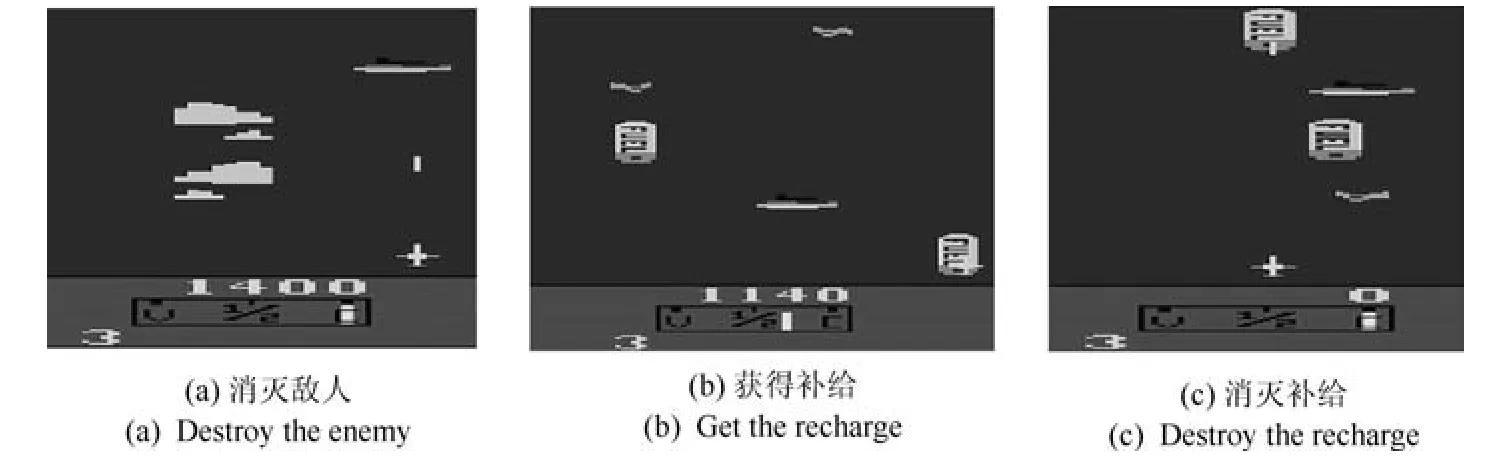
图8 Riverraid 游戏截图Fig.8 Screenshots of Riverraid
4 结论
强化学习的目的是得到策略使累积回报最大化.累积回报大的序列中的样本和累积回报小的序列中的样本都可以用于深度Q 网络的训练,但是累积回报大的序列中的样本对深度Q 网络的收敛和策略提升有更大的促进作用.本文提出的深度Q 学习的二次主动采样方法从序列累积回报分布和样本TD-error 分布两个方面构造序列采样优先级和样本采样优先级.用本文方法获得的样本训练深度Q 网络,在Atari 平台上进行了验证,实验结果表明,本文方法加速了网络的收敛速度,提高了经验池中样本的利用效率,也提升了策略的质量.
猜你喜欢
党课参考(2021年20期)2021-11-04
中学生数理化·高一版(2021年2期)2021-03-19
小哥白尼(军事科学)(2019年6期)2019-03-14
党课参考(2018年20期)2018-11-09
领导决策信息(2018年16期)2018-09-27
小学生作文(低年级适用)(2018年3期)2018-04-17
数学学习与研究(2017年3期)2017-03-09
少儿科学周刊·少年版(2015年4期)2015-07-07
都市丽人(2015年4期)2015-03-20
西南学林(2011年0期)2011-11-12
