
位置隐私泄露的一种度量方法
2019-10-31 05:24:12丁婷婷陈家明方贤进杨高明余方超
安徽理工大学学报(自然科学版) 2019年4期
丁婷婷,陈家明,方贤进,杨高明,余方超
(1.安徽现代信息工程职业学院信息工程系,安徽 淮南 232001; 2.安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
近年来,由于移动端(如智能手机、车载GPS)以及通信网络的发展,使基于位置的服务(Location Based Service,LBS)广泛应用于人们的生活中。瑞典市场研究公司Berg Insight发布的报告预测,全球LBS市场规模将以22.5%的复合年增长率(CAGR)从2014年的103亿欧元增加至2020年的348亿欧元[1]。LBS有如此大的市场需求,但同时也存在着隐私泄露的问题,例如,用户利用手机查询“离我最近的医院”,如果查询请求被攻击者获取,用户的位置隐私可能会泄露。因此,在基于位置的服务中如何保护用户的位置隐私成为目前研究的热点。
目前,主要的位置隐私保护方法可以分为时空伪装[2]、假位置[3]、假名[4]、空间加密[5]等。时空伪装是用一片区域来代替用户的精确位置,位置k-匿名就是一种典型的时空伪装算法;假位置是指查询用户用一个代理用户的位置来代替自己真实位置向服务器发出查询请求,其服务质量与查询用户位置和代理用户位置的距离成反比;假名技术是用一个虚假的用户名来代替真实的身份标识,使攻击者不能将LBS查询和真正的用户联系起来;空间加密技术是指用某种加密协议对用户的位置信息进行加密,使攻击者不能破解出用户的真实位置信息。然而这些位置隐私保护技术对用户的位置隐私起到怎样的保护作用或者位置隐私保护的强度如何,则需要用隐私的度量结果来评估。这种度量结果一方面可以为位置隐私保护算法的设计提供参考,另一方面也可以让使用LBS服务的用户了解其位置隐私泄露的风险。因此,对位置隐私保护算法度量的研究具有一定的意义。
1 相关工作
对位置隐私保护算法度量的研究最早是从对匿名系统的匿名性度量开始的。近年来,学者们针对不同的位置隐私保护算法,提出很多不同的度量方法。
k-匿名是度量位置隐私保护算法保护强度的常用方法,它是指查询用户的位置被泛化为k个用户的位置区域,攻击者不能从区域中唯一识别查询发出者的位置。k值越大,攻击者识别出查询发出者的可能性就越小,k值越小,则情况相反,因此可以用k值的大小来度量位置隐私保护算法的隐私保护水平。但是,林欣等人指出当攻击者收到连续的一组快照时,匿名区域中用户发出查询请求的概率不再相等,攻击者会选择概率最大的用户作为查询请求的发出者[6]。所以k-匿名只适合单点位置隐私的度量[7]。文献[8]对k-匿名方法作出改动后用来度量轨迹隐私,即在客户-服务器系统结构的基础上使用k-匿名度量,使其更加实用。
信息熵[9]是量化不确定性的重要工具。Diaz和Serjantov首先用信息熵度量匿名通信系统的匿名性。后来,信息熵被广泛应用于位置隐私的度量中,这种度量方法将攻击者猜测用户的真实位置或轨迹看成随机变量X,X的概率记为p(x)。用公式(1)或者其变形来度量位置隐私和查询隐私。
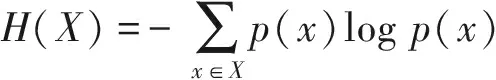
(1)
文献[10]人提出一种基于信息熵的隐私度量方法用来度量V2X应用系统中的位置隐私。文献[11]提出用条件熵和互信息来度量用户的查询隐私。文献[12]总结了几种隐私度量的模型并提出了基于信息熵的度量方法。
此外,文献[13]提出用攻击者计算用户真实位置出错的概率来度量位置隐私。文献[14]提出了基于贝叶斯条件概率的隐私度量模型。
以上的位置隐私度量方法大都忽略了攻击者的背景知识,而攻击者的背景知识和位置隐私的度量是密切相关的。
文献[15]是一种基于四叉树的位置隐私保护算法,它采用可信的第三方匿名服务器的系统结构对用户的位置隐私进行匿名化处理,将用户的隐私保护需求表示为生成匿名区域的最小面积a以及匿名区域中用户的个数n。其方法为:将用户所在区域划分成一个个网格,检查用户所在网格参数是否满足用户隐私需求,若不满足,则将匿名区域扩大到相邻网格,若仍不满足,再将匿名区域扩大到父类网格。这样可以使发出查询的用户被攻击者识别出的概率不大于1/n。但是,该方法在合并网格时,没有考虑相邻网格的用户分布情况,同时也可能会返回空间更大的父类网格,因而造成获得的匿名区域中存在较大的冗余区域。文献[16]提出改进GLKA算法来减小冗余区域,即根据相邻网格的用户密度生成匿名区域,再根据发出查询的用户所在网格距离匿名区域边界行(或列)的距离以及边界行(或列)中的用户密度进行冗余边界去除,最终生成冗余区域更小的匿名区域。
本文以GLKA算法为例,提出一种位置隐私泄露的度量方法,将发出查询请求用户的准确位置泛化成至少包含k个用户的区域,评估其位置被攻击者识别出来的风险。该方法融入了攻击者的背景知识,用来度量攻击者在具有背景知识的情况下,发出查询请求用户位置时的隐私泄露情况。
2 位置隐私度量方法
2.1 位置隐私保护模型
建立隐私保护模型是进行隐私泄漏度量中必不可少的环节,以下是基于GLKA的位置隐私保护模型。
在图1(a)中,用户u向LBS服务器发出查询请求,并要求形成的匿名区域(AR)中用户数量不少于k(假设k=6);用户的查询请求和所在位置被提交到第三方匿名服务器,其所在空间被划分成一个个网格,如图1(b)所示;计算出用户u所在单元格的四个相邻区域中用户的密度,将用户密度最大的区域合并入AR形成新的AR,如果用户密度最大的区域不止一个,则按照上、下、左、右的顺序选择一个相邻区域加入AR。之后,判断形成的AR是否是矩形以及是否满足用户的隐私需求,若AR不是矩形,需要将新的AR转化成最小限定矩形(MBR),若AR不满足用户隐私需求,需要选择下一个相邻区域加入AR,重复这一过程直到最终形成满足用户隐私需求k=6的AR,如图1(c);最后计算用户所在单元格离四个边界行(或列)的距离和四个边界行(或列)的用户密度,将其按照距离由大到小、用户密度由低到高的顺序排列,将排在第一的行(或列)去除后,若k仍然大于用户隐私需求,形成新的AR,重新计算距离和密度,否则,去除排在第二的行(或列),直至没有行(或列)可去除为止。最终形成图1(d)隐私需求k=6的最终AR。

(a)用户u发出查询请求 (b)用户所在区域被网格化 (c)生成匿名区域(d)去除匿名区域中的冗余区域图1 GLKA算法生成用户匿名区域
2.2 隐私度量方法
用户提出查询请求后,其所在的空间S会被网格化,我们可以用m*n的矩阵Am*n来描述S被划分后的用户分布情况,矩阵中的每个元素代表着每个网格中的用户数量,例如,可以用图2中的矩阵来描述图1(b)中的用户分布。这样空间S中的所有用户数量|S|可以描述为

100010010000002010001020100010010100
图2 用户分布矩阵
其中aij表示用户分布矩阵的元素。匿名区域AR初始时是发出查询用户所在的单元格,如果不满足隐私需求,需合并相邻单元格并转化成最小限定矩形MBR,形成新的AR,若用s、t和o、p分别表示AR左下角单元格和右上角单元格的行列号,则
其中Sij表示行列号分别为i和j的单元格。在减小匿名区域的冗余区域时,需要根据AR四个边界行(或列)中的用户密度NUM去除行(或列),AR边界行中的用户密度计算公式为
在网格化的过程中,如果网格过大,会使LBS服务器的效率变低,生成的匿名区域也很大,影响到用户的服务质量;网格很小,则会增加服务器的计算复杂度,延长响应时间。所以,选择合适的网格精度非常重要。
在攻击者没有任何背景知识的时候,会认为AR中所有用户发出查询的可能性相等,即等于1/k’,把此时的分布看成Q(x)。但是,现实中,攻击者通常都包含了一定的背景知识,例如医疗信息、地图信息、统计信息甚至是有关个人的信息,所以,攻击者通常推测AR中的用户发出查询的概率不相等,此时的分布看成P(x)。而KL距离(Kullback-Leibler差异)通常被用来描述两个分布之间的差异,我们可以通过公式(2)来度量P(x)和Q(x)的差异,即实际情况下隐私信息和在攻击者没有任何背景知识情况下隐私信息之间的距离。
(2)
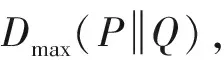
(3)
L(u)越小,说明用户位置隐私泄露越低,反之,则越高。
(a)有无背景知识对度量结果的影响 (b)背景知识量对度量结果的影响图3 背景知识对度量结果的影响
3 实验设计
实验在Windows8平台下,用matlab仿真实现。实验机器的参数为2.1 GHz Intel Core(TM)i3处理器、4GB内存。
实验使用Network-Based Generator of Moving Objects[17]模拟器随机成生德国奥登堡市内10 000个用户位置信息,从中随机选取100个用户作为发出查询用户,模拟器的参数采用默认设置。将地图信息划分成不同大小的网格,在不同的隐私需求下,利用GLKA算法生成发出查询用户的匿名区域,匿名区域中用户发出查询请求的概率随机生成,利用第3节中提出的方法度量位置隐私泄露,取100个用户度量结果的平均值作为实验输出,实验结果及分析如下。
3.1 背景知识对度量结果的影响
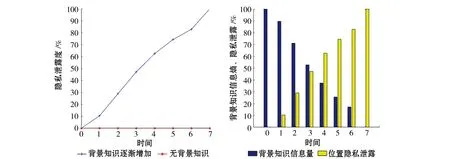
现实中,攻击者通常拥有一定的背景知识,所以将背景知识融入到度量中是非常必要的。实验中将地图划分成32×32大小的网格,用户的隐私需求被设置为6。通过2.2节中提出的位置隐私泄露度量方法,分析在有无背景知识和背景知识逐渐增加的情况下,对位置隐私泄露的影响。
图3(a)是有无背景知识的情况绘制的度量结果折线图。在无背景知识时,用户的位置隐私泄露维持在最低水平,说明攻击者认为匿名区域中每个用户发出查询的概率是相等的;在有背景知识时,随着时间的增加,用户位置隐私的泄露也逐渐增加。因为随着时间的增加,攻击者获得有关用户的背景知识会越多,越有可能推测出发出查询请求用户的真实位置。在“0”时刻,攻击者没有任何背景知识,不能确定发出查询请求用户的具体位置,所以攻击者认为用户的隐私泄露最低。而在“7”时刻,攻击者根据背景知识确定了查询请求的发出者,并确定了此用户在匿名区域中的具体位置,所以从攻击者的角度来看其位置隐私泄露最高。

从以上实验中可以看出,用户的位置隐私和攻击者的背景有着非常大的关系,将背景知识考虑入度量中是必要的。
3.2 隐私需求及网格大小对度量结果的影响
用户的隐私需求和不同大小的地图网格也会对用户的位置隐私泄露有影响。图4(a)和4(b)是在将地图划分成32×32和128×128大小网格情况下,随着隐私需求的增加,用户位置隐私的泄露图。可以看出在两种不同大小网格的情况下,用户的位置隐私泄露都随着隐私需求的增加而减小。这是由于随着匿名区域中用户的增加,攻击者识别出查询发出者的困难增加,用户的位置隐私泄露随之减小。图4(c)和4(d)是在隐私需求为6和8的情况下,分别将地图划分32×32、64×64、128×128、256×256、512×512、1 024×1 024网格大小时,用户的位置隐私泄露图。地图网格大小变大,意味着生成的匿名区域变大,就可能含有更多的用户,从而降低了用户的位置隐私泄露风险。从实验中可以看出隐私需求的增大和地图划分网格变大都会降低用户的隐私泄露风险。
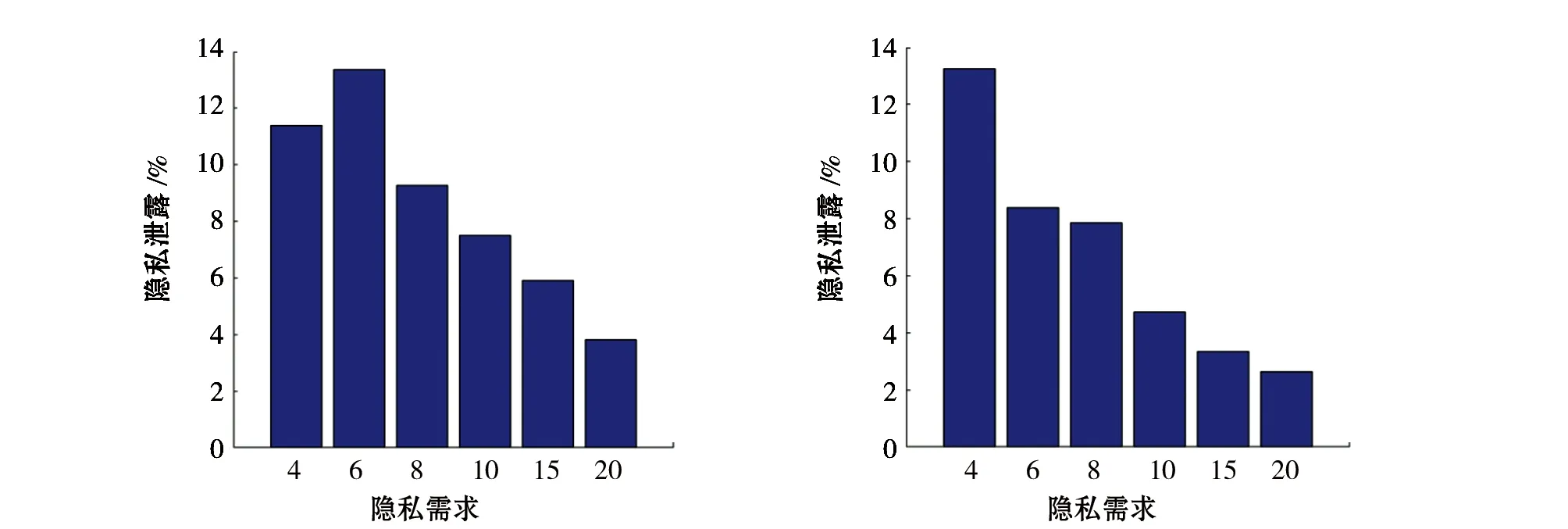
(a)隐私需求对度量结果的影响 (32×32地图网格) (b)隐私需求对度量结果的影响(128×128地图网格)
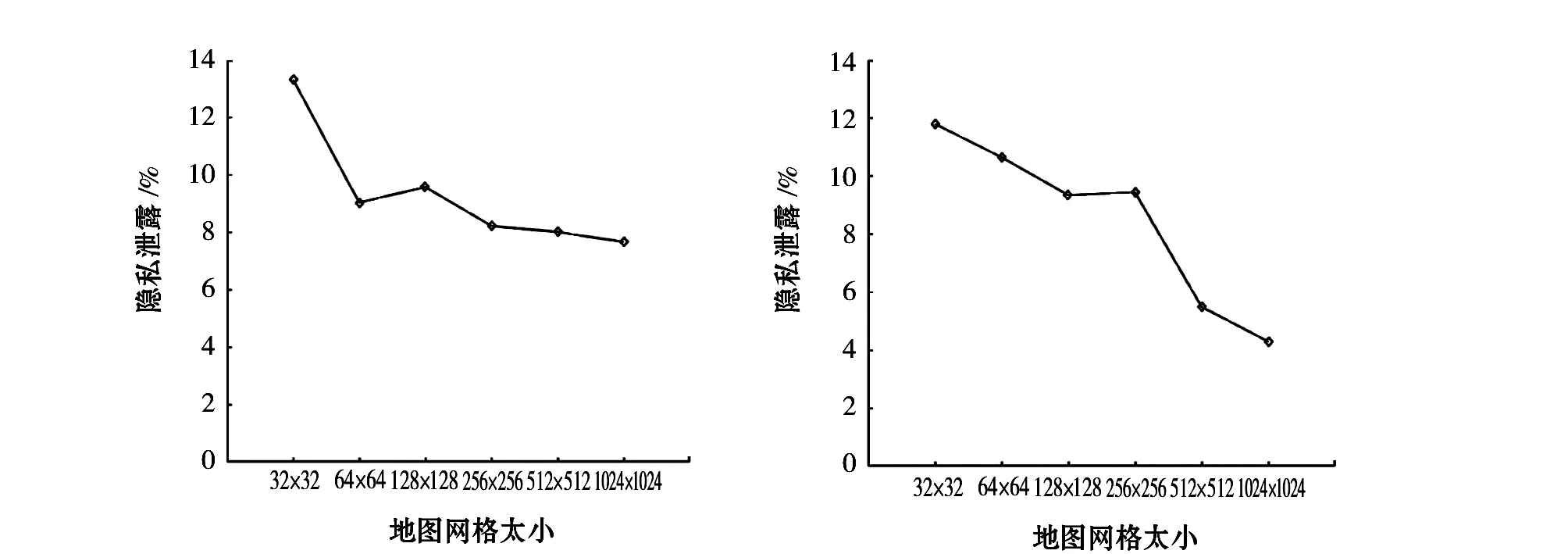
(c)地图网格大小对度量结果的影响(隐私需求为6) (d)地图网格大小对度量结果的影响(隐私需求为8)图4 隐私需求及网格大小对度量结果的影响
4 总结和展望
基于位置的服务(LBS)在不久的将来会有更多的应用。对用户位置隐私保护方法和保护方法度量的研究必定是有意义的。本文提出的度量方法考虑了攻击者的背景知识,为位置隐私保护方法的设计者设计更优的位置隐私保护算法提供了参考。由于背景知识多种多样、随着时间的推移,攻击者背景知识的积累、攻击者知识水平的不同、攻击者推理能力的不同以及各种攻击技术的发展等等,这些都给隐私的度量工作带来了严峻的挑战,但是,将这些因素融入到度量方法中关乎隐私度量结果的准确性,是必须的,也是迫切需要实现的,这也是我们接下来的工作重心。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
自动化学报(2021年8期)2021-09-28 07:20:18
数学大王·趣味逻辑(2020年6期)2020-06-22 07:48:15
数学大王·趣味逻辑(2020年5期)2020-06-19 08:49:28
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
爱你(2018年16期)2018-06-21 03:28:44
西部皮革(2018年6期)2018-05-07 06:41:07
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
指挥与控制学报(2015年4期)2015-11-01 10:09:34
