
基于GA-SVR的苹果可溶性固形物质量分数的高光谱检测
2019-10-30 09:35:42查启明顾宝兴姬长英
食品与生物技术学报 2019年9期
查启明, 顾宝兴, 姬长英
(南京农业大学 工学院,江苏 南京 210031)
中国是苹果的生产大国,每年苹果的种植面积和总产量均为世界第一,但是中国却不是苹果贸易强国,国产苹果的价格及质量远远不及进口苹果,主要原因就是我国苹果的采后分级技术落后,不仅在国际市场上缺乏竞争力,而且不能满足国内高端市场的需求。人们在选用苹果时,会比较看重苹果的甜度,也就是苹果内部可溶性固形物的质量分数。高光谱成像技术既能够反映苹果的外部特征,例如颜色、表明缺陷等肉眼可以看见的特征,又能反映苹果内部的物质结构和化学成分等。
由于高光谱成像技术的优越性,近年来国内外在采用高光谱成像技术检测农产品方面展开了很多的研究。其中,黄文倩等基于400~1 000 nm的苹果高光谱图像采用不同的降维方法提取特征波长,然后建立最小二乘支撑向量机(LS-SVM)建模定量预测苹果的可溶性固形物质量分数(SSC)。Lu等对苹果的硬度进行高光谱图像技术检测,利用PCA和ANN相结合的方法对两种产地的苹果建立模型,模型的相关系数分别为0.76和0.55。侯宝路等利用连续投影算法(SPA)和多元线性回归算法(MLR)对梨的高光谱图像进行建模分析,来预测梨的可溶性固形物含量(SSC)和硬度。罗霞等利用高光谱成像技术对火龙果进行可溶性固形物质量分数检测,采用PLS和BP神经网络分别建立预测模型。
上述研究中大部分是在整个高光谱波段内进行特征波长提取,部分是通过经验判断优选波段后再采用算法提取特征波长,导致输入数据精度不足。作者将预处理后的高光谱数据先进行一阶微分后优选出噪声小的波段,再通过连续投影算法提取特征波长,以此提高模型的预测精度。
1 材料与方法
1.1 实验材料
以山东烟富、洛川元帅、洛川富士为研究对象,在实验中所使用的苹果均为2016年7月份在南京浦口水果批发市场购买。挑选的苹果表面没有缺陷、直径范围为65~85 mm,大小形状均匀,共计198个。购买来的苹果放置在冰柜中保存,实验前分批拿出,待其恢复至室温后开始实验。实验中随机选取150个样本作为建模校正集,其余48个样本作为建模预测集。
1.2 高光谱图像采集与校正
实验中所用的高光谱系统包括:Imspector型光谱仪 (芬兰Specim公司产品)、CCD相机 (美国Imperx公司产品)、镜头、21V/150W线性卤素灯(美国Illumination公司产品)、暗箱、电控移动平台以及计算机等部件。高光谱成像波长范围为358~1 021 nm。参数设置如下:曝光时间52 ms,样本与镜头的距离为330 mm,传送带移动速度为0.7 mm/s。每个样本均在赤道部位标记3点(间隔约为)采集3张高光谱图像,198个样本共计594幅高光谱图像。
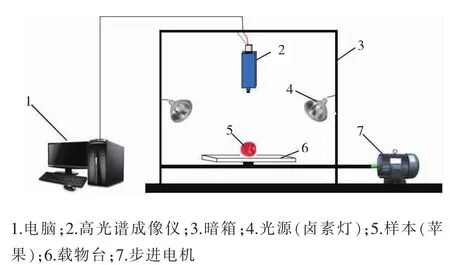
图1 高光谱系统组成图Fig.1 Composition diagram of hyperspectral system
为了减少部分噪声的影响,使用样本采集相同的参数条件,经行黑白校正,公式为:
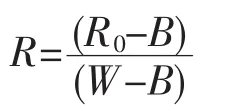
式中:R0为采集的样本原始图像,B为盖住镜头采集到的图像,W为反射率为1的校正白板的采集图像,R为黑白校正后的图像
1.3 可溶性固形物质量分数的测定
使用日本ATAGO公司的PAL-1型糖度仪(误差在±0.2%之内)进行可溶性固形物(SSC)的测定,每个样本测量赤道面均匀间隔的3处,挖取适量的果肉,压成汁液后进行测量,3个数值的平均值作为该样本的SSC值。
1.4 感兴趣区域(ROI)的选取
使用ENVI软件提取苹果的不同波段反射率,提取之前要先确认高光谱图像的感兴趣区域(ROI)。从图2可以看出同一样本,相同像素中心区域的不同像素大小的反射率存在明显差异,因此在选取ROI时,像素的形状及大小的选择显得尤为重要。郭志明等的研究结果表明当采用圆形150像素点的ROI时,模型效果最佳。因此本文在选取ROI时,在苹果高光谱图像的赤道部位,间隔取3处圆形150像素的ROI。以上述3处的平均反射光谱作为该样本的最终光谱。
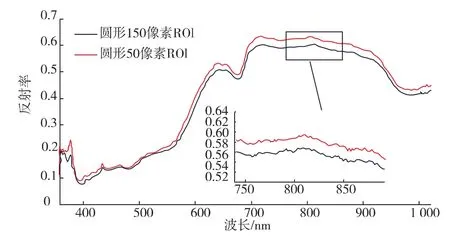
图2 不同像素ROI的反射光谱Fig.2 Reflectance spectra of ROI in different pixel
1.5 连续投影算法
连续投影算法(SPA)是一种选择波长变量的方法,能够在大量的波长变量中找出共线性最小的变量组合,从而降低模型输入变量的复杂性,提高模型的精度。样本数M和波长数N组成的矩阵是原始光谱变量,AM*N为原始光谱变量矩阵,L为最佳波长个数(L<M-1),连续投影算法的步骤如下:
(1)初始化:n-1(第一次迭代)在AM*N中任选一个列向量(第j列),记为aK(0)(即K(0)=j);
(2)定义一个集合S:S={j,1≤j≤N,j∉{k(0),…,k(n-1)}},这个集合包含未被选中的列向量的位置,分别计算aj对所有未被选中向量的投影:
Paj=aj-(aTjak(n-1))*ak(n-1)*(aTk(n-1)ak(n-1))-1,(j∈S,P是投影算子)
(3)把步骤(2)中计算的投影值最大的记为k(n):
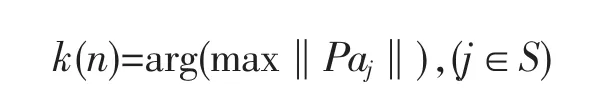
(4)把步骤(3)中求得的最大投影值作为下一个迭代过程中的初始值,即:
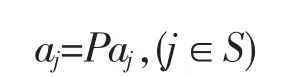
(5)进行下一次迭代:即令n=n+1,如果n<L,返回步骤(2)。
上述循环结束后,即得到选取出的特征波长:{k(n),n=0,1,…,N-1}。这样总共可以得到L*N对波长组合,将预测均方根误差作为所建模型的优劣依据,以此选择出最佳波段。
1.6 建模方法和评价标准
1.6.1 BP神经网络BP神经网络是一种多层前馈网络,它通过误差逆向传播算法进行训练,在当前科学研究中得到了广泛的应用,该网络模型共包含3个部分,分别为输入层、隐含层和输出层。BP网络能够保存大量的输入输出映射关系,并且具有自主学习的能力,并且使用者不用提前掌握这种映射关系的数学方程。它通过不断调整网络内部的权值和阈值来达到降低网络误差平方和的目的。

图3 BP神经网络结构示意图Fig.3 Schematic of BP neural network
BP神经网络的学习过程如下:
(1)输入模式由输入层经隐含层向输出层传播计算
(2)输出的误差由输出层经隐含层传递给输入层
(3)按照上述步骤反复运行
(4)判别全局误差是否趋向极小值
1.6.2 GA-SVR模型遗传算法(Genetic algorithm,GA)是通过模拟自然界生物进化过程构造出来的一种全局自适应搜索方法,根据适应度值的大小对个体进行选择、交叉、变异及复制等遗传操作步骤。在操作中去除适应度低的个体,产生比前代适应度高的种群。SVR是一种基于统计学习理论的机器学习算法,能够用来处理非线性回归问题等问题。它的主要思想是通过将向量投映到高维空间,构建最大间隔的分类超平面,以此解决庞杂数据的回归问题。在SVR模型中,核函数的类型、惩罚参数和核函数参数在一定程度上影响着模型的泛化能力及预测精度。作者采用径向基函数作为核函数,采用GA搜索确定全局最佳的参数和。
使用GA算法优化SVR模型参数的过程如下:
(1)设置初始参数,即遗传算法种群规模、进化代数、交叉概率和变异概率
(2)初始化种群,随机产生一个给定规模的二进制代码种群
(3)对种群的每个个体进行运算,采用SVR计算模型的预测值,并分别分析群体每个个体的适应度
(4)以遗传适应度为导向,对种群进行复制、交叉和变异操作,并以此生产下一代
(5)判别是否满足GA的停止条件,即训练误差和迭代次数是否满足条件,从而选择是折回步骤(3)还是继续向下执行
(6)得到最优的SVR惩罚参数和核函数参数,建立GA-SVR参数
1.6.3 评价标准采集到的高光谱图像经ENVI提取数据后,采用S-G平滑、SNV和小波降噪进行预处理,再利用SPA算法提取出特征波长,分别建立BP神经网络和GA-SVR模型。通过模型的校正集相关系数(Rc)、预测集相关系数(Rp)、校正集均方根误差(RMSEC)、预测集均方根误差(RMSEP)和交叉验证均方根误差(RMSECV)来评价模型的性能。其中,Rc、Rp的值越接近 1,RMSEP、RMSECV 的值越小,则模型的性能越好。
2 结果与分析
2.1 样本划分
在所有样本中随机选取150个苹果样本作为建模校正集,其余48个样本作为建模预测集。校正集及预测集样本可溶性固形物质量分数真实值的统计结果如表1。
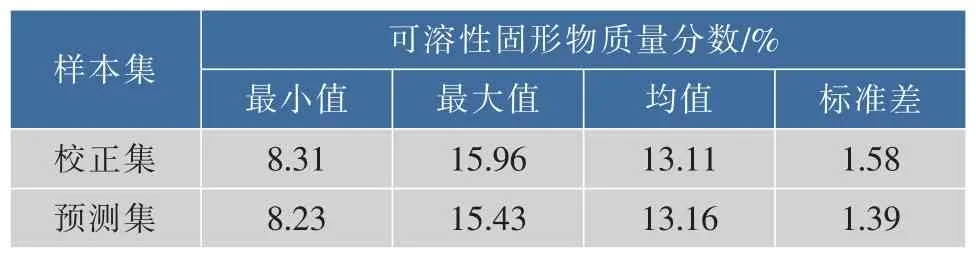
表1 苹果可溶性固形物的统计结果Tablle 1 Statistical results of soluble solid content in apples
2.2 高光谱数据预处理
采集到的高光谱数据存在噪声信号,这些噪声信号会降低模型的预测性能。所以需要对采集的数据经行预处理,作者采用的预处理方法有Savitzky-Golay平滑(S-G)、标准正态变量变换(SNV)和小波降噪(Wavelet-Denoising),结果如表2所示。
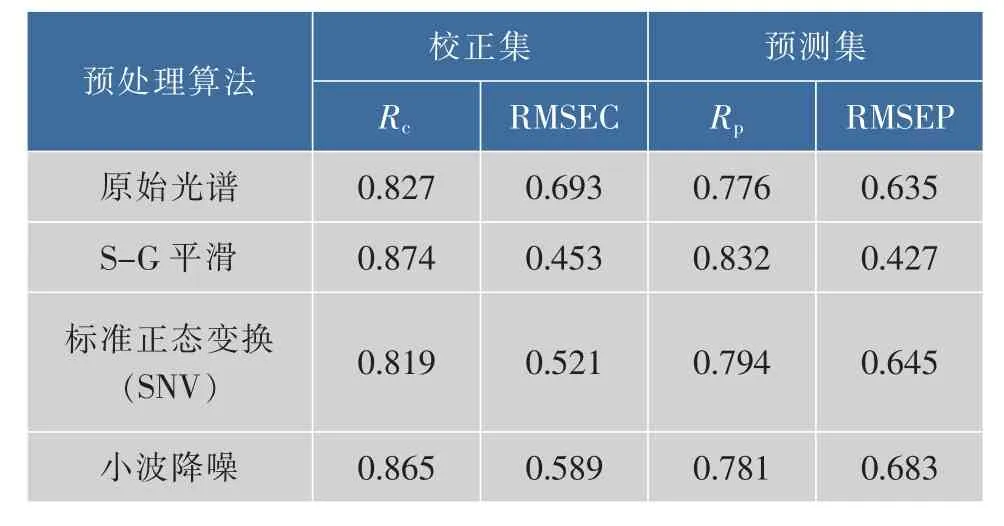
表2 不同预处理方法的预测结果Table2 Prediction resultsofdifferentpretreatment methods
由表2可以看到,采用不同预处理算法后,有的算法可以提升模型的性能,而有的算法却降低了模型的性能。采用SNV预处理后 ,相较于原始光谱而言,模型的校正集吻合度有了提升,但预测集的预测精度基本无改善。采用小波降噪预处理后,校正集和预测集改善均不明显。而采用S-G平滑处理后建立的模型相较于原始光谱而言具备较强的预测分析能力。
所有样本在圆形150像素ROI内的平均反射光谱如图4所示,通过S-G一阶微分处理后的反射光谱图5可以看到,720~1 010 nm范围内的数据较为平滑,故选取该范围内的数据用于建立糖度分析的模型。
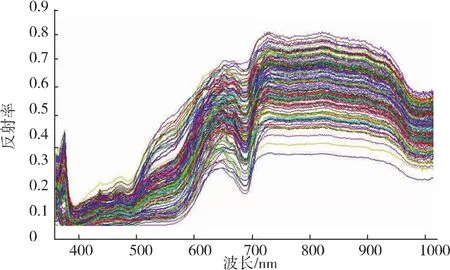
图4 所有样本ROI区域原始光谱Fig.4 Original spectra of all samples in ROI region
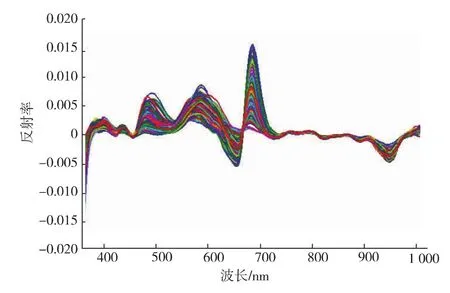
图5 S-G一阶微分处理光谱Fig.5 Spectra of S-G first derivative processing
2.3 特征波长变量的选取
通过高光谱仪采集到的苹果数据,含有数目巨大的变量,即便通过上述处理后,仍旧保留数百个变量。大量的变量数会降低模型的运行时间,不便于今后的平台移植,也不利于降低苹果无损检测的速度和精度。
通过比较各种降维算法后,选择使用SPA进行特征波长的选取,因为SPA选取出的特征波长数目相对较少,且建立的模型的性能较好。先按照随机样本划分法,将样本分成150个校正集和48个预测集。利用SPA对720~1 010 nm范围内的光谱特征进行变量选择,根据样本内部的交叉验证均方根误差RMSECV值来确定最佳的变量数。如图6(a)所示,随着选取波长数目的增加,RMSECV逐渐降低,波长数目为12后,RMSECV降低不显著,且随着波长数的增加,模型的复杂度则变大,所以综合考虑,选择12个有效波长作为模型的输入变量如图 6 (b), 他 们 是 740.86、752.95、785.99、800.34、813.59、835.70、842.34、860.05、883.30、897.71、938.70和950.89 nm。
2.4 模型的建立与结果分析
2.4.1 BP神经网络模型结果分析BP神经网络模型的输入层为经SPA筛选出的12个特征波长变量。隐含层采用logsig型传递函数,训练函数使用trainlm函数。输出层就是预测的苹果SSC含量,传递函数为pureline,学习函数为learngdm。另外,网络的初始参数设置如下:训练次数epochs为1 000,学习率lr为0.05,训练精度 goal为0.000 4,测试集48个样本的实验结果如图7,BP神经网络模型的预测相关系数=0.743 0,预测均方根误差RMSEP=0.797 7。
左图为预测值与实际值的对比图,右图为真实值与预测值的95%置信区间的散点图,中间的斜线为线性拟合线。从左图可以看出,BP神经网络模型的预测结果可以预测出真实值的大致趋势,仅在部分点位上存在一定误差。从右图可以看出真实值和预测值的散点图分布较为离散化。
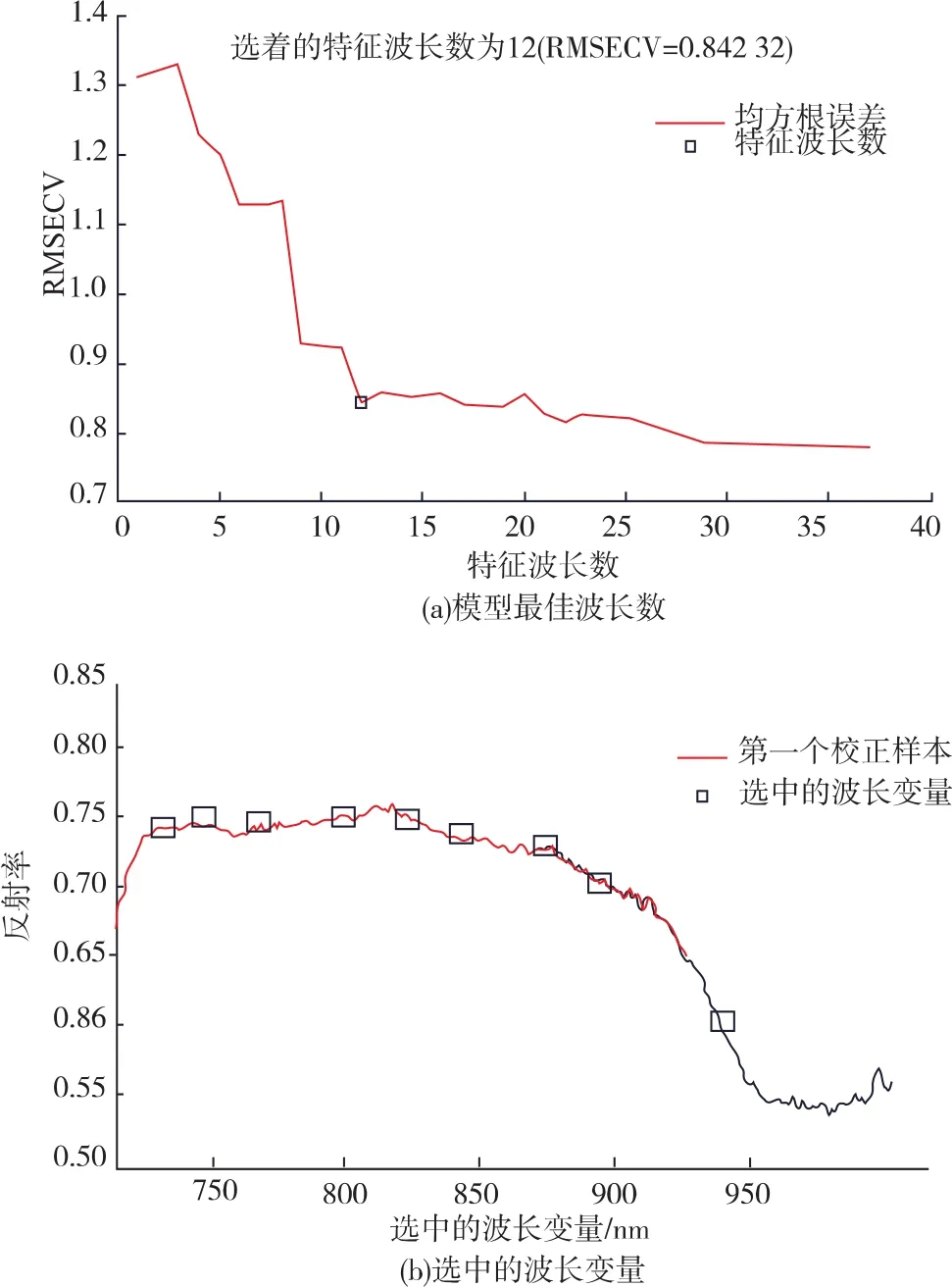
图6 SPA选取特征波长结果Fig.6 Characteristic wavelength results of SPA
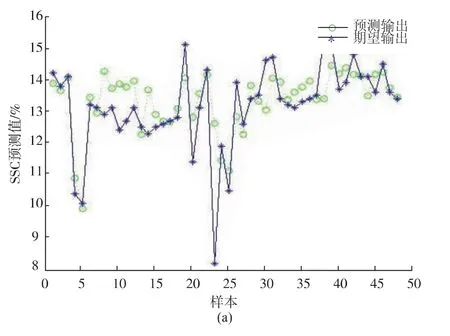
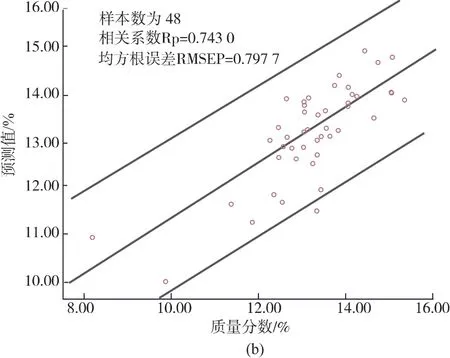
图7 BP模型结果Fig.7 Results of BP model
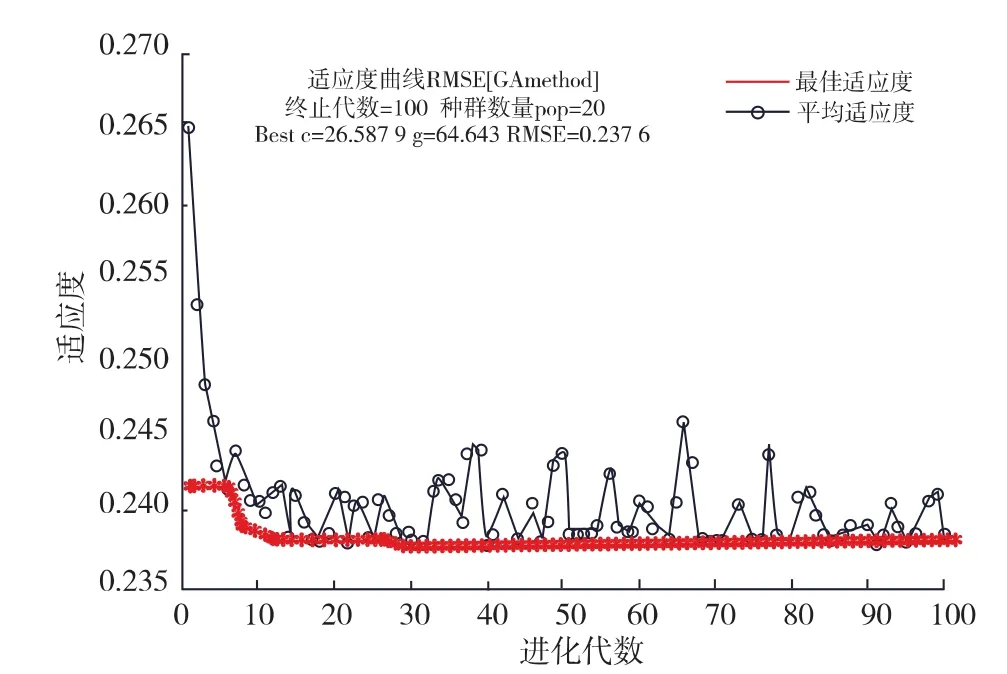
图8 GA优化SVR参数迭代过程Fig.8 SVR parameters optimized by GA
2.4.2 GA-SVR模型结果分析遗传算法的初始设置为,种群规模为20,进化次数为100,交叉概率为0.5,变异概率为0.01,独立运行多次,选取出现频率较高的结果作为SVR模型的和参数。如图8所示,大约迭代20次时,适应度值趋于稳定,达到最佳参数值,分别为c=26.587 9和g=64.643。使用GA算法优选出来的参数值作为SVR模型的输入参数,对48个预测集样本进行预测分析,实验结果如图9所示。左图中横坐标为样本数量,纵坐标为可溶性固形物的质量分数,右图为使用SPSS做的预测集散点图,横坐标为预测集可溶性固形物的真实值,纵坐标为预测值,其中斜线是线性拟合线。模型的相关系数Rc=0.880 6,Rp=0.850 5,均方根误差 RMSEC=0.260 7,RMSEP=0.303 1。
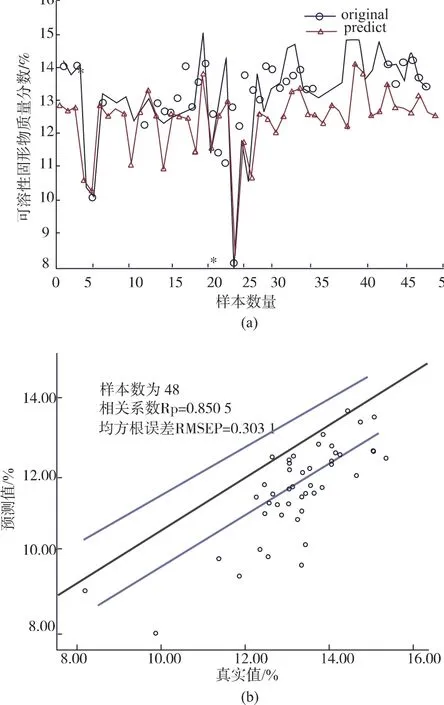
图9 GA-SVR模型结果Fig.9 Results of GA-SVR model
从左图可以看出预测结果和真实值在趋势上基本吻合,在部分点位上存在些许误差。从右图可以看出,真实值和模型预测值的散点分布集中在拟合线的两侧,在SPSS中做回归分析得出的调整后的判定系数R2=0.847,拟合优度高,预测效果好。
3 结语
1)在ENVI中,通过圆形150像素ROI提取出的数据,经由S-G平滑处理后,筛选出720~1 010 nm范围内的数据作为模型的输入变量,此范围的数据平滑性较好。
2)在利用SPA算法提取输入数据的特征变量时,在参考模型均方根误差的同时兼顾模型的复杂度, 选取出的特征波长位:740.86、752.95、785.99、800.34、813.59、835.70、842.34、860.05、883.30、897.71 、938.70和950.89 nm共计12个。降低了模型的复杂度,提高了模型的预测性能。
3)通过GA算法优化SVR模型的惩罚参数和核函数参数,遗传算法的初始设置为:种群规模为20,进化次数为100,交叉概率为0.5,变异概率为0.01。 优化得到c=26.587 9、g=64.643,此时 SVR 模型的性能最佳。
4)BP神经网络模型的预测相关系数Rp=0.743 0,预测均方根误差RMSEP=0.797 7;GA-SVR模型的预测相关系数Rp=0.850 5,预测均方根误差RMSEP=0.3031。结果表明基于SPA算法优选出的波长建立的模型预测精度更高,模型复杂度得到明显降低。从GA-SVR模型的散点图得到调整后的判断系数为0.847,拟合优度较高,不被解释的变量较少,拟合效果较好。
猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21 00:44:56
特产研究(2022年6期)2023-01-17 05:06:16
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
自动化学报(2017年2期)2017-04-04 05:14:28
中学生数理化·七年级数学人教版(2016年2期)2016-05-30 21:20:57
中国照明(2016年4期)2016-05-17 06:16:15
中国光学(2015年5期)2015-12-09 09:00:28
物理实验(2015年9期)2015-02-28 17:36:46
新高考·高二数学(2014年7期)2014-09-18 17:20:45
