
基于LIBS技术和卷积神经网络的土壤铅含量等级快速分类
2019-10-30 10:03GuindoMahamedLamine庄振华仲海鹏
浙江科技学院学报 2019年5期
孙 淼,Guindo Mahamed Lamine,庄振华,仲海鹏,赵 芸
(浙江科技学院 信息与电子工程学院,杭州 310023)
重金属造成的污染会对土壤产生严重的破坏,降低土壤自身的恢复能力,减少有益微生物的数量,还会对粮食造成污染,造成经济损失[1]。如果人们食用被重金属污染的食物,有害金属会随着食物进入人体内,引起人体不适,影响身体健康[2]。比如铅(Pb)是一种对人体有害的重金属,当人食用被Pb污染的食物后,可能会引发感觉和运动障碍、末梢神经炎等疾病;当人们慢性Pb中毒后,一般情况下也会发生贫血现象[3]。为了可以食用健康的粮食,快速检测出土壤中重金属含量是目前急切需要解决的问题。目前重金属监测存在样品预处理复杂、检测人员需具备较强的专业知识、仪器昂贵、设备庞大等缺陷,难以用于重金属的快速测定[4]。激光诱导击穿光谱技术(laser-induced breakdown spectroscopy,LIBS)是一种新型的等离子体光谱分析技术[5],该技术是利用高功率脉冲激光射击到样本的表面,由此产生等离子体,当这些等离子体在膨胀和冷却时,处于激发态的原子与离子会发射出特征谱线,该特征谱线便是那些原子与离子的光谱指纹,样本中元素的组成与含量等信息可以通过特征谱线的波长与强度信息获取。与火焰原子吸收光谱法(FAAS)、激光烧蚀电感耦合等离子体质谱(ICP-MS)和电感耦合等离子体原子发射光谱法(ICP-OES)等传统技术相比,LIBS具有高灵敏度与高空间分辨率,且分析简便、快速,无需繁琐的样品预前处理过程[6]。它弥补了传统元素分析方法检测重金属浓度的不足,尤其是在土壤、植物、农产品和食物中重金属浓度检测方面的应用[7]。目前对LIBS光谱的研究主要集中在分析样品中的元素组成成分,然后进行材料的识别、分类、定性以及定量分析。彭继宇等[8]使用偏最小二乘判别分析(PLS-DA)和支持向量机(SVM)对新鲜和干燥叶片中的烟草花叶病毒进行检测;刘晓娜等[9]使用PCA和PLS-DA方法对蓝莓进行了种源研究。这些研究的主要算法是PCA算法或者PLS-DA算法,无法正确处理大量的数据,而且还需要复杂的样品制备。
深度学习作为新兴的一种机器学习方法,是一种通过模拟人脑学习、处理数据的神经网络。目前,已有一些研究将机器学习算法应用到LIBS光谱数据分析中,例如,孟德硕等[10]利用LIBS技术结合BP神经网络对土壤进行快速分类;余志强等[11]利用LIBS技术结合PLSR和LS-SVM对土壤重金属含量进行检测;徐向君等[12]利用LIBS技术结合SVM对茶叶品种进行快速分类等。
本文将卷积神经网络(convolutional neural network,CNN)与激光诱导击穿光谱技术相结合,用于土壤Pb含量的分类研究:使用局部光谱数据作为训练网络的输入数据,并通过调整模型结构和参数对网络特征进行选取、分类;最后验证LIBS和CNN网络结合对土壤分类的结果较好。这不仅为土壤分类提供一种新方法,也为土壤修复提供可靠数据。
1 试验部分
1.1 仪器与材料
1.1.1 样 品

图1 试验装置系统Fig.1 Experimental device system
试验所使用植物为MS云烟87烟草,将该烟草催芽包衣种子播种于穴盘,15 d后植物幼苗移栽至花盆中,并定期添加营养液。20 d后,将所有植物分为0、1、2、3、4五组,每组8株,定期施用含Pb的营养液,质量浓度分别为0、200、350、500、1 000 mg/kg,另外,Pb胁迫溶液由Pb(NO3)2配置。土壤样品的制备:将土壤放至小试管中,利用研磨机研磨至粉末状后放至大试管中,设置烘箱温度80 ℃,烘烤1 d。用天平称量0.5 g土壤粉末,放至直径13 mm圆形模具中,用压片机设置20 MPa压力压制15 s。
1.1.2 LIBS装置
试验所采用的装置如图1所示。装置包含一个Q开关Nd:YAG激光器Vlite-200(北京镭宝光电技术有限公司),在532 nm二次谐波波长下操作,工作频率为1 Hz,单脉冲的能量为80 mJ;使用平凸透镜(焦距f=100 mm),将激光聚焦在土壤样品表面,用光纤收集等离子体的发射光谱,传送到由Echelle摄谱仪ME5000(英国安道尔科技有限公司)和ICCD摄像机DH334-18F-03(英国安道尔科技有限公司)组成的检测系统;光谱仪分辨率为0.04 nm,延迟发生器用于控制ICCD摄像机和激光器Q开关的延迟;本试验中使用的延迟时间是2.83 μs,积分时间是18 μs。另外,土壤样品被放置在可以移动的样品台上,这样可以使激光脉冲打在样品不同位置,保证不重复击打同一位置。
1.2 试验方法
1.2.1 样品准备
在试验过程中,为保证所获取光谱的可靠性,在X-Y-Z样品台帮助下,每个样品击打16个不同的位置,且对样品的一个位置重复激光射击5次,自动计算平均值,产生一个光谱图,并保存为一个光谱数据。试验中,0类样本96个,1类样本80个,2类样本96个,3类样本80个,4类样本64个,共528个光谱图作为研究数据。
1.2.2 数据预处理
LIBS光谱图,一共有22 014个波长值,使用Unscramble X10.4软件进行数据预处理。首先使用高斯滤波器的平滑方法降低噪声,其工作原理是对整个光谱图中的值进行加权平均,最后得到的每个值都是其自身和邻域内其他值的加权平均。在此之后,使用面积归一化方法将平滑的光谱归一化到相同比例。这种技术对于因为基质效应和变化所导致的光谱变化是有用的,通过计算面积归一化得到曲线图。本研究使用了平滑和标准化方法,由于一些基本特征是有用的,需要保留光谱图的原始性。但如果将所有的光谱值作为输入进行分类操作,则会降低计算速度且对设备性能要求较高。因此,需要消除无关的信息,并尽可能对光谱数据进行压缩。本文参照文献[13-17]选取光谱值波长研究范围,既保留光谱图原始性也降低了对设备的要求。
1.3 模型结构
1.3.1 卷积神经网络概念及原理
卷积神经网络其基本思想是:局部连接、权值共享、空间或时间上的采样[18]。正是由于卷积神经网络的这三个特点使其对输入数据在空间(主要针对图像数据)上和时间(主要针对时间序列数据)上的扭曲有很强的鲁棒性和网络泛化能力[19]。
1.3.2 卷积网络模型结构
对于深度学习模型,一般隐含层越多,分类精度就会越高,但当隐含层越多的时候,它的训练时间也在增加[20]。为保证分类精度较高,且最大程度减少模型训练时间,本文卷积神经网络结构采用的是1个输入层、3个卷积层、3个池化层、1个全连接层、1个输出层。除输入和输出层外,中间的7层C1、S1、C2、S2、C3、S3、F8可看作是隐含层。其中第1层是输入层;第2层C1是卷积层,8个3×3的卷积核,步长为1;第3层S1是池化层,卷积核为2×2,步长为2;第4层C2是卷积层,6个4×4的卷积核,步长为1;第5层S2是池化层,卷积核为2×2,步长为2;第6层C3是卷积层,6个2×2的卷积核,步长为1;第7层S3是池化层,卷积核为2×2,步长为2;第8层F8是全连接层;第9层是输出层。激活函数选用ReLU函数,学习率为0.01,一次训练的个数为3;每次训练的迭代次数为10。卷积神经网络的结构如图2所示。
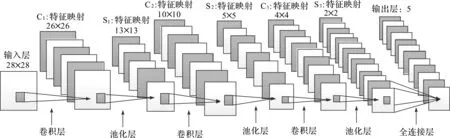
图2 卷积神经网络结构Fig.2 Convolutional neural network structure
通过多次训练,观察结果并确定该卷积网络模型结构和参数。为达到最好的结果,参数需多次调试,比如卷积网络的层数、学习率、迭代次数、卷积核大小等。
ReLU激活函数的数学表达式如下:
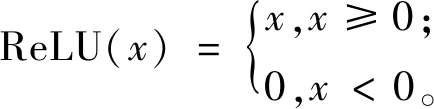
(1)
卷积层的计算公式如下:
(2)
采样层的计算公式如下:
(3)
式(3)中:β为不同的特征图的系数;down(·)为一个采样函数。
2 结果与讨论
2.1 土壤LIBS光谱分析
通过LIBS试验装置,使用激光击打样本,获取光谱原始图像,可通过Andor SOLIS软件观察得到的光谱图。原始LIBS平均光谱图如图3所示,发现LIBS光谱图存在较大差异,且光谱图不光滑,受噪声的影响。因此需要对原始LIBS光谱图采取预处理操作,减少噪声对光谱造成的影响,以获得更精确的结果,减少或消除各种环境、基体效应等因素的影响,提高检测分辨率和灵敏度[21]。
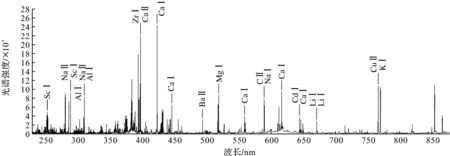
图3 原始LIBS平均光谱图Fig.3 Average spectrum of original LIBS
光谱数据预处理方法有很多,采取不同数据预处理方法,结果也不同,因此需要选取合适的数据预处理方法。本试验所采用的数据预处理方法是:利用Unscramble X10.4软件,先对原始光谱图采取高斯滤波方法进行光谱平滑操作,再使用面积归一化方法将平滑光谱归一化到相同比例。这种技术对因基质效应和变化所导致的光谱变化是有用的,通过计算面积归一化得到曲线图。
通过使用NIST原子线数据库和相关参考文献[13-17],对Pb波长进行研究和统计,为后面选取输入光谱数据作基础。文献[13]在利用激光诱导击穿光谱研究植物组织中金属的积累,Pb所采用的波长是405.8 nm;文献[14-22]对Pb进行研究所采用的波长是405.76 nm和405.78 nm。试验所获得的光谱图波长范围是229.343 8~876.964 2 nm,所以本研究最终选取的光谱波长范围是396.28~415.54 nm。
由于全光谱数值较多,图4只选取了本文所研究光谱波长范围内的图像。从图上看到光谱图有一些细微差异,但并不明显,所以需要采用一些算法来对光谱图数据进行处理,从而实现类别的划分。

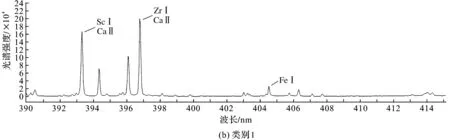
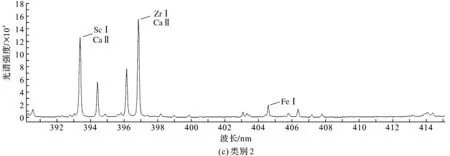
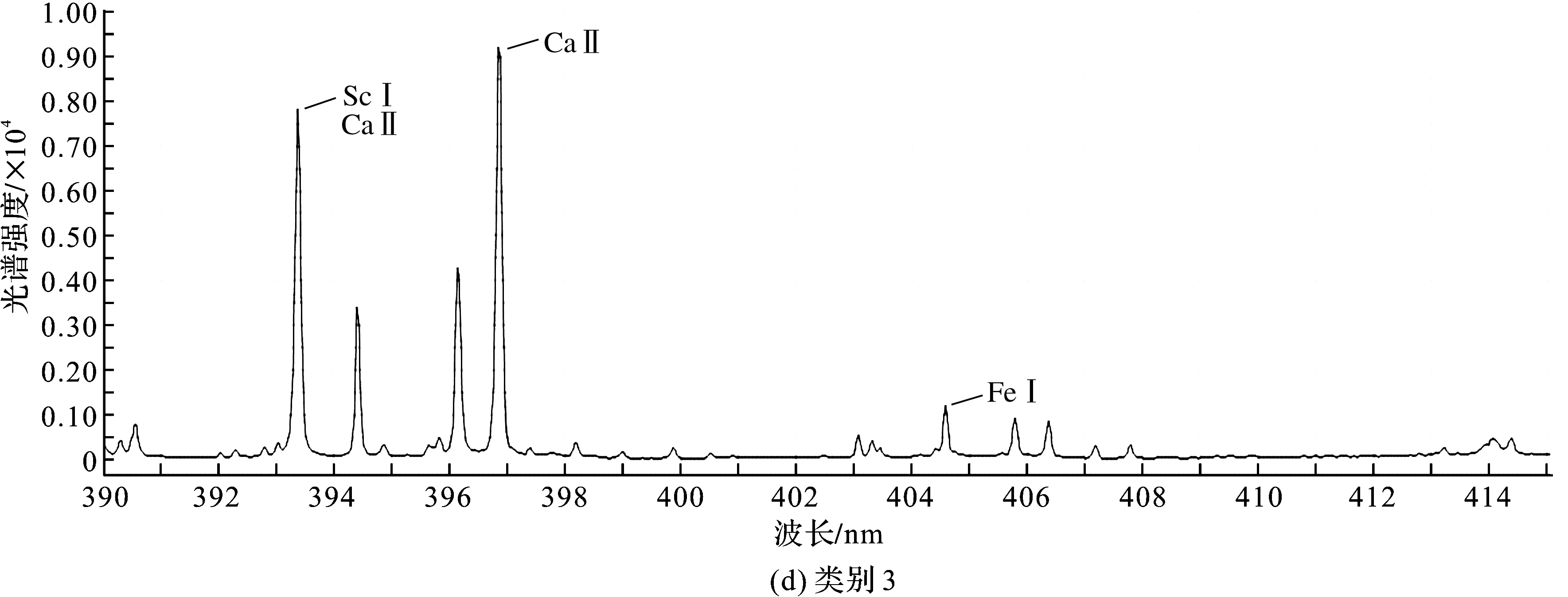
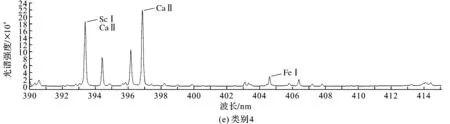
图4 各类别390~415 nm光谱图Fig.4 390—415 nm spectrum of each category
2.2 分类模型
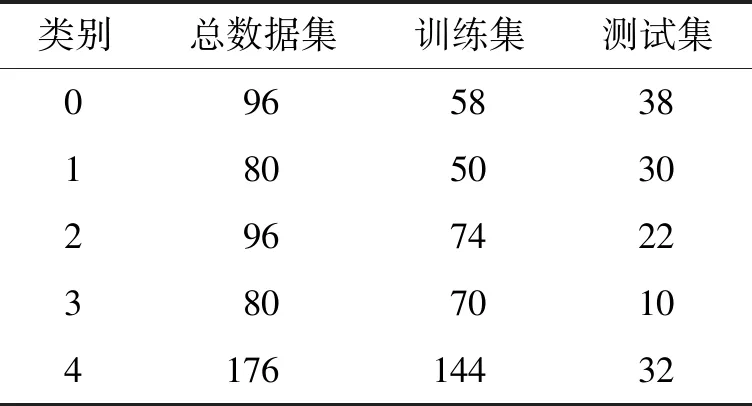
表1 数据集划分分布Table 1 Data set partitioning
在使用不同分类算法之前,需要先对样本训练集和测试集进行数据划分,在MATLAB R2016b软件平台使用Kennard-Stone(KS)算法。KS算法能够较均匀地对样本的训练集和测试集进行有效划分,剔除培养过程中烟草的死亡样本,共有528个样本数据集,总数据为528×784个数据,其中396个样本数据被划分为训练集,训练集为396×784个数据,132个样本数据被划分为测试集,测试集为132×784个数据。总数据集、训练集和测试集每个类别的分布情况见表1。
2.2.1 PLS-DA分类方法
PLS-DA是光谱数据处理最早的方法之一,是一种监督分类算法。本试验输入数据是选取的光谱图波长范围396.28~415.54 nm。使用KS算法将预处理数据集分为训练集和测试集,使用交叉验证方式。PLS-DA将光谱分解为组分的线性组合,且份数与组内方差和组间方差相关。X是用于建模的输入矩阵(选取的光谱范围中的数值),该矩阵被用来构建PLS-DA模型,Y是每个X对应的类别信息。在MATLAB R2016b软件平台上,使用PLS-DA方法进行分类训练,为了获得良好效果,同时避免模型过度拟合,通过10倍交叉验证确定潜变量的数量。根据第一个最小分类误差选择最佳的潜变量,然后将测试集用于评估性能。该方法得到的分类结果效果并不理想,得到表2的混淆矩阵,其中训练集的准确率是93.43%,测试集的准确率为90.91%。

表2 PLS_DA训练集和测试集混淆矩阵Table 2 Confusion matrix of PLS_DA training set and test set
2.2.2 SVM分类方法
SVM也是一种常见的处理光谱数据方法,在MATLAB R2016b软件平台上,使用SVM方法将得到的训练集和测试集数据进行训练测试,得到表3的混淆矩阵。该方法训练集的准确率是99.75%,测试集的准确率是96.21%。可见,该方法相较于PLS-DA方法其准确率上升明显,较为可靠。其中,仅仅类别3能够完全正确识别,但对于目前的需求,这个准确率还是远远不够。

表3 SVM训练集和测试集混淆矩阵Table 3 Confusion matrix of SVM training set and test set
2.2.3 卷积神经网络分类方法
通过添加不同质量浓度Pb营养液,土壤对Pb吸收情况不同,还会导致其他土壤元素含量变化,将该段光谱值作为卷积神经网络的输入,依据此特征值对光谱进行分类,将光谱分类问题转化为图像分类问题并加以解决。以经过不同质量浓度Pb溶液培养4周的烟草土样本为例,通过LIBS获得光谱曲线图,光谱曲线图的波长涵盖范围是229.343 8~876.964 2 nm,一共784个数据,构成一个输入矩阵。在MATLAB R2016b软件平台上,使用CNN方法进行分类训练。将划分好的数据集和分类标签输入已构建好的卷积神经网络模型,样本类别号作为网络的输出数据。
模型训练和测试的混淆矩阵见表4。整个样本数据的准确度达到99%以上,训练集的整体训练准确率为99.75%,测试集的整体训练准确率为99.24%,其中大部分类别的准确率都达到了100%,相对于PLS-DA和SVM的分类精度而言,准确率大幅度提升,效果最好。

表4 CNN训练集和测试集混淆矩阵Table 4 Confusion matrix of CNN training set and test set
2.2.4 结果分析
以上分类模型的分类精度用灵敏度、特异度和准确度3个指标来确定。分别计算每种样本质量浓度识别结果的这3个精度指标,以及与之相对应的另外3个精度指标,分别是假阴性率、假阳性率和错误率。设a为真阳性数量;b为假阳性数量;c为假阴性数量;d为真阴性数量;n为总样本数。计算公式如下:灵敏度=a/(a+c),假阴性率=c/(a+c),特异度=d/(b+d),假阴性率=b/(b+d),准确度=(a+d)/n,错误率=(b+c)/n。以类标号0的烟草土样本为例,a表示其他4类烟草土样本被正确识别的数量;b表示其他4类烟草土样本被误识别为类标号0的烟草土样本的数量;c表示类标号0的烟草土样本被误识别为其他4类烟草土样本的数量;d表示类标号0的烟草土样本被正确识别的数量。其他类别烟草土样本的3个精度指标计算方法依此类推。3个模型的识别精度见表5~7。

表5 PLS-DA识别精度Table 5 PLS-DA recognition accuracy %

表6 SVM识别精度Table 6 SVM recognition accuracy %

表7 CNN识别精度Table 7 CNN recognition accuracy %
由表5~7可知,PLS-DA、SVM、CNN 3个模型训练集的整体训练精确度分别为93.43%、99.75%、99.75%,测试集的整体训练精确度分别为90.91%、96.21%、99.24%。从试验结果可知,SVM模型和CNN模型相比较PLS-DA较好;从测试集训练结果可知,CNN效果最好,PLS-DA最差。因此,用CNN模型对LIBS数据进行分类操作,效果最好。分别观察不同类别的灵敏度、特异度和准确度。PLS-DA模型大部分在90%以上,但是类别2、3和4的灵敏度较低,会导致较大误差。SVM和CNN的训练集结果相近,一些类别甚至达到100%,对于测试集,SVM模型每个类别基本上在95%以上,而CNN模型每个类别都在99%以上,类别2、3、4都达到100%,效果很好。
综上所述,CNN模型分类效果最好,SVM模型分类结果次之,PLS-DA模型分类结果最差。由此可得,使用卷积网络对LIBS数据进行分类快速且效果好。
3 结 语
本研究将光谱数据转化为光谱图像,使用改进算法进行处理,且使用了深度学习与LIBS结合的方法。试验结果表明,基于LIBS技术和卷积神经网络的快速分类方法对土壤重金属含量进行分类是可行的,快速且效果好。后续还将对重金属含量进行定量分析,这样会给土壤修复提供更详细的信息,为土壤修复提供一种新的可靠的技术。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代电力(2022年2期)2022-05-23
黑龙江大学自然科学学报(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
空间科学学报(2021年1期)2021-05-22
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
