
基于两阶段最小二乘回归的分类方法
2019-10-28 09:57林智鹏简彩仁吕书龙
福州大学学报(自然科学版) 2019年5期
林智鹏, 简彩仁, 吕书龙
(1. 厦门大学嘉庚学院, 福建 漳州 363105; 2. 福州大学数学与计算机科学学院, 福建 福州 350108)
0 引言
分类是模式识别的重要研究内容, 在计算机视觉学习、 图像分类和基因表达数据识别等研究中有重要的应用[1-4]. 传统的分类方法需要利用训练集构造分类器, 由于参数的设置等原因容易产生过拟合问题. 基于表示理论的分类方法, 具有利用训练样本表示测试样本不需要构造分类器的优势, 因此可以避免过拟合问题. 所以, 基于表示理论的分类方法是研究分类问题的一个重要手段, 得到了国内外学者的青睐[2-3, 5-9].
随着稀疏表示理论的不断发展, 文献[5]利用LASSO模型构造了稀疏表示分类法, 该方法通过表示系数的L1范数达到稀疏表示的目的, 并利用稀疏表示分类法研究了人脸识别问题. 最小二乘回归分类法通过表示系数正则L2范数达到聚集的目的, 文献[6]利用最小二乘回归分类法研究了基因表达数据的识别问题. 非负最小二乘回归通过表示系数的非负限制达到表示系数稀疏的目的, 文献[7]利用该方法提出非负最小二乘回归分类法. 文献[8]对比了稀疏表示分类法和最小二乘回归分类法的优缺点, 最小二乘回基金项目: 福建省本科高校教育教学改革资助项目(FBJG20170021, FBJG20180086); 福州大学2018年一流本科教学改革建设资助项目; 福州大学第十批本科高等教育重点资助项目(50010842); 福州大学研究生"应用概率统计"优质课程建设资助项目(52004634)
归分类法求解表示系数容易得到解析解, 也可以得到较高的识别准确率, 因此, 基于最小二乘回归分类法提出改进模型. 文献[3]利用非负稀疏表示剔除噪声样本, 发现剔除噪声样本可以提高最小二乘回归分类法的准确率. 文献[9]利用类别信息定义判别信息惩罚项, 改进最小二乘回归分类法.
现实中的数据, 如人脸图像数据等由于采样等原因容易产生噪声样本, 这些噪声样本对模式识别研究有重要的影响. 而最小二乘回归分类法不加区别地利用训练样本表示测试样本, 容易受到噪声样本的影响. 针对这一不足, 本研究利用系数增强的手段提出一种缓解噪声样本对表示系数影响的两阶段最小二乘回归分类法.
1 相关工作
1.1 基于表示理论的分类法

稀疏表示分类法(sparse representation classifier, SRC)[5]利用LASSO模型求解表示系数. 经典的LASSO模型如下

(1)
其中:λ>0是正则参数. 文献[10]给出了一种快速求解该问题的方法.
最小二乘回归分类法(least square regression classifier, LSRC)[6]利用岭回归模型求解表示系数. 经典的岭回归模型如下

(2)
其中:λ>0是正则参数. 不难得到该模型的解析解为ω=(XTX+λI)-1XTy, 这里I是单位矩阵.
基于稀疏表示和最小二乘回归的分类法(sparse representation and least square regression classifier, SRLSRC)[3]先利用如下的非负稀疏表示模型

(3)
其中,λ>0是正则参数. 剔除噪声样本, 再用最小二乘回归分类法进行分类.
协同-竞争表示法(collaborative-competitive representation based classifier, CCRC)[9]利用类别信息定义判别信息惩罚项, 从而改进最小二乘回归分类法. 其数学模型为

(4)
其中,λ>0是正则参数,γ≥0是平衡参数; 第三项是类别信息项,Xi表示第i类样本,ωi为其表示系数,C为类别数量.
1.2 最小重构误差准则
由1.1节得到的表示系数ω按类别重构测试样本计算重构误差, 重构误差最小的类别即为测试样本所属的类别. 重构误差计算公式[5]如下

(5)

2 系数增强最小二乘回归方法
最小二乘回归分类法直接用原始训练样本X重构测试样本y容易受到噪声样本影响. 本研究从系数增强的角度提出一种具有缓解噪声样本对表示系数影响的两阶段最小二乘回归方法.
2.1 目标函数
根据基于表示理论的分类法的原理, 一种理想的表示系数为与测试样本同类的表示样本的系数不为0, 而与测试样本不同类的表示样本的系数为0. 由于现实数据的非线性、 多噪声等特点导致这种状态是不容易实现的. 因此, 测试样本更有可能属于表示系数大的训练样本. 故针对岭回归模型提出改进如下

(6)
其中:γ≥0, 当γ=0时退化为岭回归模型,β>0用于平衡表示系数ω和相似度d. 第三项是系数增强项, 向量d=[d1,d2, …,dn]T∈Rn×1是测试样本y与训练样本X的相似度量, 其中di=sim(xi,y)表示测试样本y与训练样本xi的相似度量. 如果相似度量很大, 说明测试样本y与训练样本xi很接近, 更可能属于同一个类别, 进一步说明表示系数ωi很大. 因此系数增强项可以强化测试样本y的近邻样本的协同作用, 使其可以缓解噪声样本的影响.
2.2 模型求解
将目标函数重新写为
L(ω)=Tr[(y-Xω)T(y-Xω)]+λTr(ωTω)+γTr[(ω-βd)T(ω-βd)]
(7)
展开得
关于向量ω求导得

(9)
令其为0, 得
ω=(XTX+λI+γI)-1(XTy+γβd)
(10)
2.3 两阶段最小二乘回归分类法

基于以上的讨论, 将两阶段最小二乘回归分类法(two-stage least squares regression classifier, TLSRC)归纳如下

TLSRC具体步骤: Input: 训练样本数据集X, 测试样本y, 正则参数λ, γ, β.Output: 测试样本所属类别l.Step1: 由式(2)得到表示系数ω, 并得到相似度量d=ω.Step2: 由式(10)得到表示系数ω.Step3: 利用1.2节的最小重构误差准则, 得到测试样本y的所属类别l.
2.4 非线性两阶段最小二乘回归分类法
2.1节中的两阶段最小二乘回归分类法是在线性空间中被研究, 而高维数据具有非线性的特点, 因此该方法对于非线性数据集的识别存在不足. 为此利用核理论将该方法进一步推广成非线性两阶段最小二乘回归分类法.
定义非线性特征空间映射Φ:Rm→M, 其中Rm表示原样本空间,M表示流形空间. 将训练样本数据集X和测试样本y用非线性映射Φ映射到无穷维空间得Φ(X)和Φ(y)[11-12]. 用式(6)研究Φ(X)和Φ(y)的识别问题, 得到

(11)
类似于式(6)的求解过程, 不难得到式(11)的解析解为
ω=(ΦT(X)Φ(X)+λI+γI)-1(ΦT(X)Φ(y)+γβd)
(12)
直接定义非线性映射Φ:Rm→M是困难的. 根据核理论[11-12], 不需要定义非线性映射Φ而只需定义一个半正定核矩阵K∈Rn×n如下:
[K]ij=[(Φ(X),Φ(X))M]ij=ΦT(Xi)Φ(Xj)=k(xi,xj)
(13)

于是式(11)的解析解为
ω=(K+λI+γI)-1(k+γβd)
(14)
其中,K=ΦT(X)Φ(X),k=ΦT(X)Φ(y).
最后将非线性两阶段最小二乘回归分类法(nonlinear two-stage least square regression classifier, NTLSRC)归纳如下:

NTLSRC具体步骤: Input: 训练样本数据集X, 测试样本y, 正则参数λ, γ, β, σ=1.Output: 测试样本所属类别l.Step1: 计算核矩阵K=ΦT(X)Φ(X), k=ΦT(X)Φ(y).Step2: 由式(2)得到表示系数ω, 并得到相似度量d=ω.Step3: 由式(14)得到表示系数ω.Step4: 利用1.2节的最小重构误差准则, 得到测试样本y的所属类别l.
3 实验分析
为了验证TLSRC和NTLSRC的分类性能, 采用对比实验分析本研究的有效性. 选用的对比方法为经典的基于表示理论的分类法: 稀疏表示分类法(SRC)[5]、 最小二乘回归分类法(LSRC)[6]、 非负最小二乘回归分类法(NNLSC)[7]、 基于稀疏表示和最小二乘回归的分类法(SRLSRC)[3]、 协同-竞争表示法(CCRC)[9], 以及传统分类方法:k最近邻分类法(KNN).
3.1 实验参数设置和实验数据
实验参数设置如下: 所有方法的正则参数λ设为0.01, CCRC、 TLSRC和NTLSRC的平衡参数γ设为0.01,β设为1.50. 实验采用交叉验证对比各种方法的识别准确率, 交叉验证的折数取为4~10折.
实验选用4个人脸图像数据集: FERET、 PIE、 ORL和Yale进行研究. 其基本信息如表1所示:

表1 数据信息
3.2 结果分析
表2给出在不同交叉验证折数下的平均识别准确率. 图1给出不同交叉验证折数下的识别准确率.

表2 平均人脸识别准确率
注:表中黑色数字表示最优平均准确率
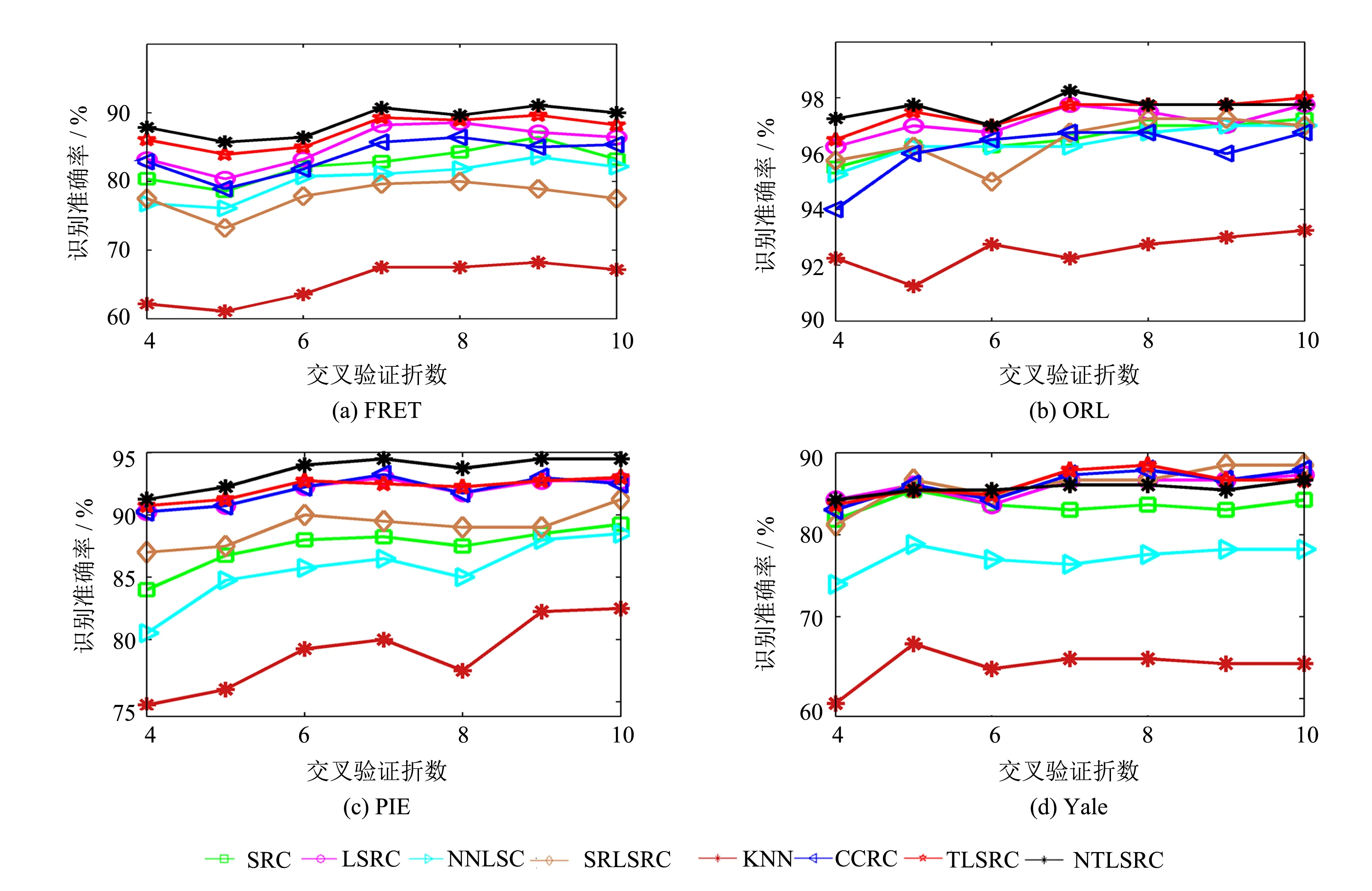
图1 不同交叉验证折数下的人脸识别准确率 Fig.1 Face recognition accuracies under different cross-validation folds
由表2和图1的实验结果不难发现, TLSRC和NTLSRC较好地改进了LSRC方法; 对比其他基于表示理论的分类方法(SRC、 NNLSC、 SRLSRC和CCRC), TLSRC和NTLSRC也具有较高的准确率. 由此, TLSRC和NTLSRC具有缓解噪声样本对表示系数影响的能力, 更适合人脸识别的研究. 而传统的分类方法KNN的识别准确率是最低的, 原因是高维空间中的欧式距离度量并不可靠. 最后对比TLSRC和NTLSRC, 尽管在Yale数据集中TLSRC的识别准确率优于NTLSRC, 但总体而言, NTLSRC优于TLSRC, 因此非线性两阶段最小二乘回归分类法更适合非线性数据的识别.
3.3 参数讨论
本节讨论两个参数γ和β对TLSRC和NTLSRC的影响, 限于篇幅, 仅讨论γ和β对TLSRC的影响. 事实上, NTLSRC也有类似的结论. 为直观起见, 设定交叉验证折数为6折, 参数λ取为0.01.
图2给出了两个参数γ和β的变化对TLSRC识别准确率的影响. 由实验结果不难看出, 不同的γ和β会有不同的识别准确率. 较小的γ和β具有更好的识别准确率,β取1.5~2.5,γ取0.005~0.100是一组较理想的参数选择, 这一发现增加了TLSRC和NTLSRC的实用性.
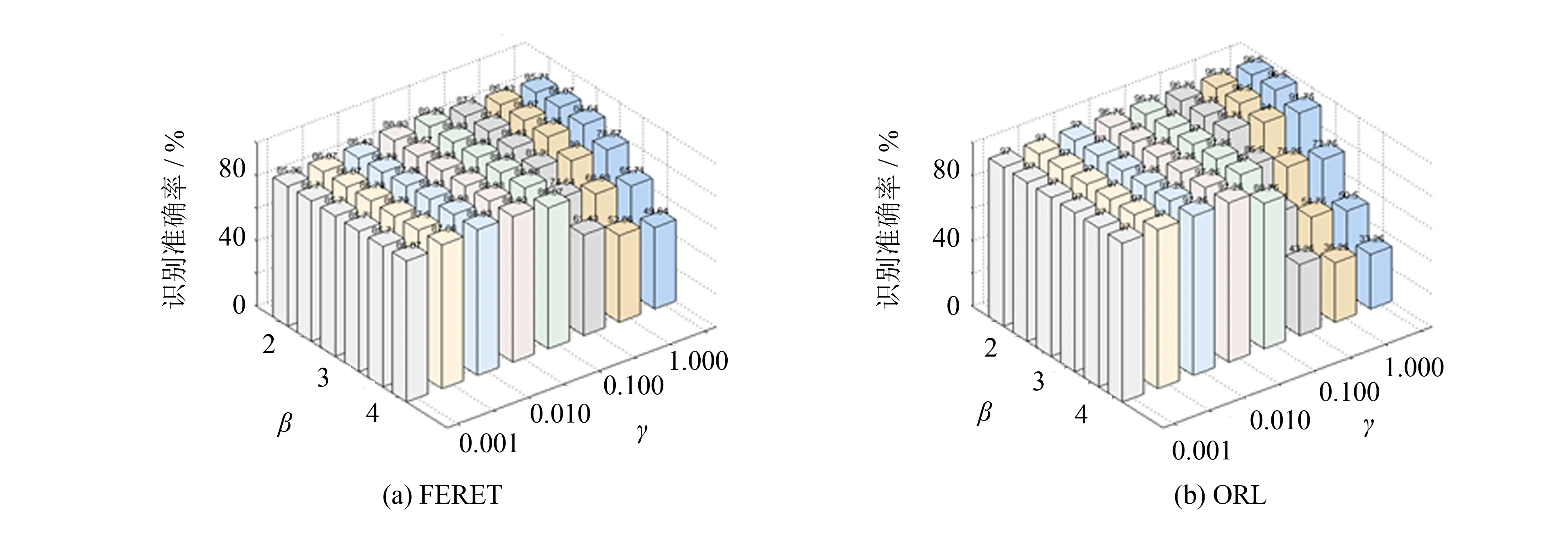
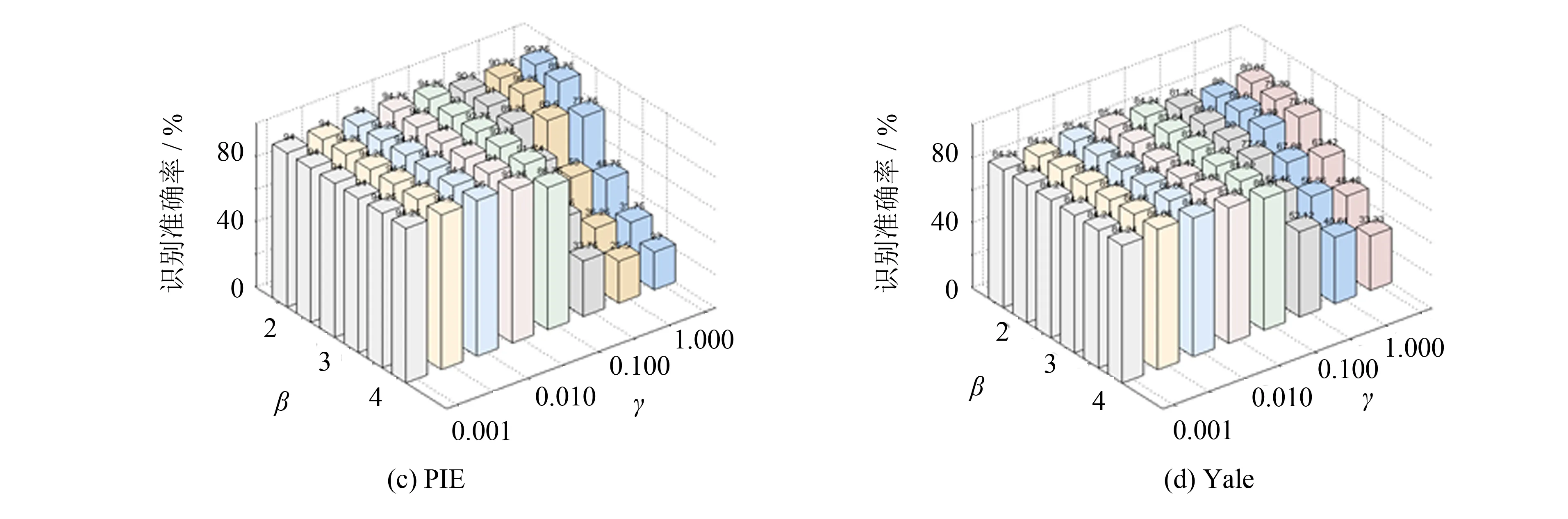
图2 不同γ和β下的人脸识别准确率Fig.2 Face recognition accuracies under different γ and β
4 结论
本研究提出TLSRC和NTLSRC, 并利用系数增强的方法改进最小二乘回归分类法. 在4个常用的人脸图像数据集上的实验表明, 该方法可以明显地提高识别准确率. NTLSRC是一种基于核理论的非线性识别方法, 更适合非线性数据的识别研究. 由于存在两个阶段, TLSRC和NTLSRC的运行时间开销比较大.
猜你喜欢
中学生数理化·高一版(2020年2期)2020-04-21
科技创新与应用(2020年6期)2020-02-29
民族古籍研究(2018年1期)2018-05-21
录井工程(2017年1期)2017-07-31
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
新校长(2016年8期)2016-01-10
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
中国当代医药(2015年24期)2015-03-01
