
“分布式计算与开发模式”综合设计性实验案例
2019-10-28 11:39:24杨丹,张晶,赵骥,王刚
实验技术与管理 2019年10期
杨 丹,张 晶,赵 骥,王 刚
“分布式计算与开发模式”综合设计性实验案例
杨 丹,张 晶,赵 骥,王 刚
(辽宁科技大学 软件学院,辽宁 鞍山 114051)
针对面向计算机专业本科生开设的“分布式计算与开发模式”专业课的特点和大纲要求,设计了该综合设计性实验。该实验在Windows系统下,使用Hadoop分布框架和Eclipse快速开发平台,实现了地震数据集的统计任务。对实验目的、任务要求、实验方法和步骤、算法流程等进行了细介绍。实践结果表明,通过此综合设计性实验,学生的实验积极性和对分布式计算的掌握程度大大提高。
分布式计算;综合设计性实验;Hadoop;MapReduce
“分布式计算与开发模式”实验课程是针对我校计算机专业本科生开设的一门专业课。该课程涵盖分布式计算模型与原理、分布式开发模式。培养学生的分布式程序设计能力,是分布式计算与开发模式课程的一个重要目的。通过该课程实验,学生可以验证分布式计算的原理基础,提高编制清晰、合理、可读性好的分布式程序的能力,更好地掌握基本分布式计算模型MapReduce原理,获得实际开发分布式程序的能力。
1 分布式计算与分布式应用
近年来,分布式计算与分布式应用在IT领域中占据重要地位。开源框架Hadoop分布式计算平台[1]已经成为众多电子商务网站的基础应用平台,是一种高效处理极大规模数据的平台[2-3]。Hadoop是一个实现了MapReduce[4]和GFS[5]技术的开源平台,它可以在由低成本硬件组成的集群上处理极大规模的数据集。Hadoop项目中最主要的2个子项目分别是Hadoop分布式文件系统(HDFS)和MapReduce。HDFS[6-7]是一个可以存储大数据集的文件系统,它是通过向外扩展方式构建的主机集群,以时延为代价对吞吐量进行优化,并且通过副本替换冗余达到高可靠性。HDFS的体系结构如图1所示。MapRedue[8-9]是一个数据处理范式,规范了数据在2个处理阶段(被称为Map和Reduce)的输入和输出,并将其应用于任意规模的大数据集。
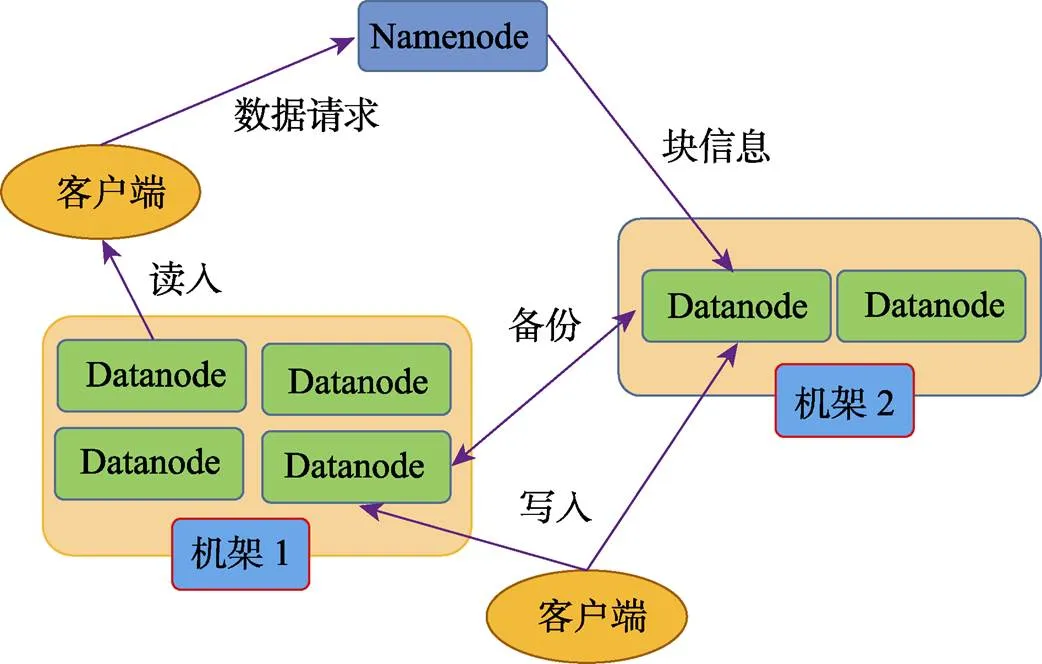
图1 HDFS体系结构图
2 MapReduce编程模型
2.1 MapReduce模型简介
MapReduce编程模型的设计理念源自2004年谷歌公司发表的一篇论文[10]。MapReduce采用“分而治之”的思想,把对大规模数据集的操作,分发给主节点管理下的各个分节点共同完成,然后通过整合各节点的中间结果,得到最终结果[11]。简单地说,MapReduce就是“任务的分解与结果的汇总”。这种分布式计算模型,主要用于解决海量数据的计算问题,具有易编程、扩展性好、容错性高等[12-13]等特点。常见的MapReduce应用场景包括数据统计、搜索引擎建索引、海量数据查找、复杂数据分析算法实现,如分类算法、聚类算法、推荐算法和图算法等[14]。
MapReduce计算模型主要由3部分构成:Map、Shuffle和Reduce。Map是映射,负责数据的过滤分类,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后,再输出新的键值对作为最终结果。为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,再交给对应的Reduce,即Shuffle过程。Shuffle过程包含Map Shuffle和Reduce Shuffle[15]。
2.2 MapReduce工作原理
MapReduce工作原理模型如图2所示。

图2 MapReduce工作原理模型图
其中,Map任务处理包括如下步骤:
步骤1:读取HDFS中的文件。每一行解析成一个
步骤2:覆盖Map(),接收步骤1产生的
步骤3:对步骤2输出的
步骤4:对不同分区中的数据进行排序(按照key)、分组。分组是将相同key的value放到一个集合中;
步骤5:(可选)对分组后的数据进行归约。
Reduce任务处理包括如下步骤:
步骤1:将多个Map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点上;
步骤2:对多个Map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑,然后产生新的
步骤3:将reduce输出的
2.3 MapReduce执行流程图
以Hadoop经典的单词统计程序(wordcount)为例的MapReduce执行流程如图3所示。
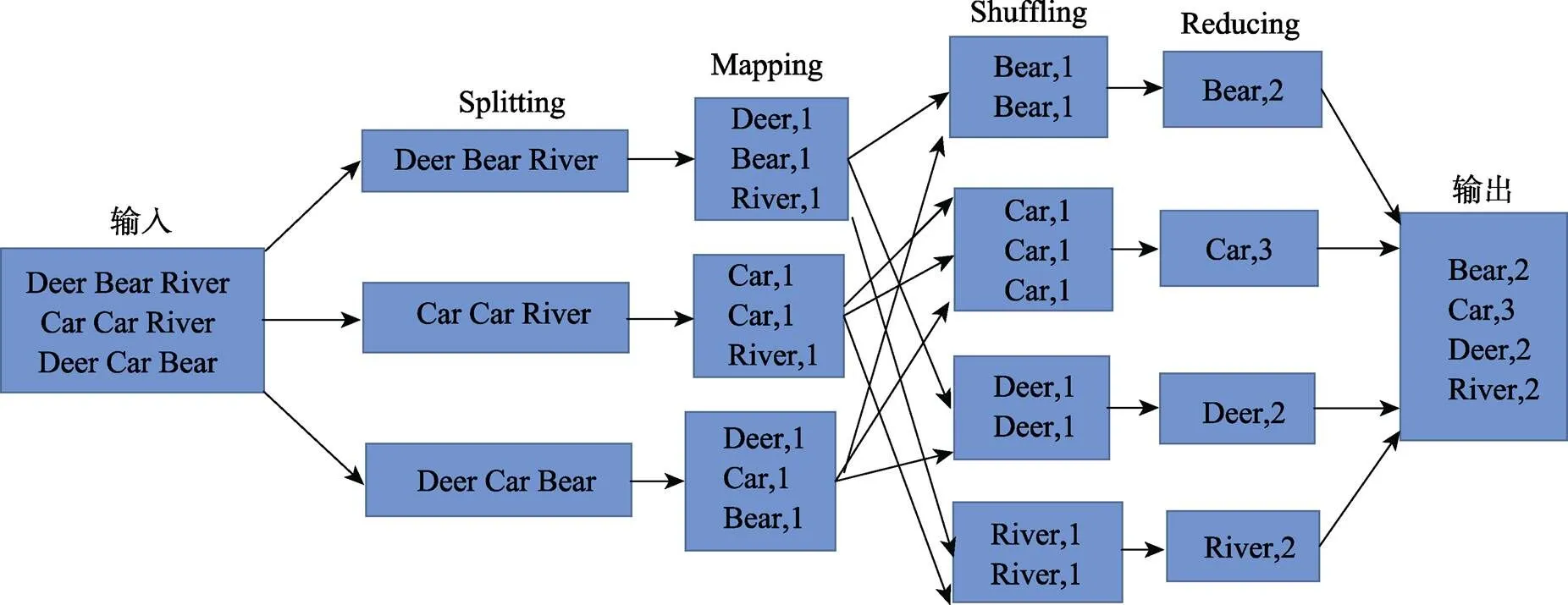
图3 单词统计的MapReduce执行流程图
3 综合设计性实验设计案例
下面以Windows系统下,使用Hadoop分布式框架与Eclipse快速开发平台实现地震数据集的各种统计任务为例,介绍综合设计性实验案例的设计。
3.1 实验目的与任务要求
实验目的:(1)理解和掌握MapReduce执行原理;(2)理解并掌握Map、reduce阶段的任务与步骤;(3)熟悉并掌握Map、reduce方法的代码编写。
实验任务要求:设计并编写MapReduce分布式程序,实现从地震数据集中获取每年最大震级、每月最大震级以及所有记录中的最大震级3个子任务,要求实验输出结果按时间升序排列。
3.2 实验数据集
地震数据集:1999年1月至2016年8月之间由国家地震台网速报目录提供的地震发生时间、发生地点以及震级等情况。具体包括:发生地震的日期信息、时间点信息、纬度信息、经度信息、深度信息、震级及地点信息。所有记录信息存储在名为earthquake_info.txt的文本文件中。部分数据集的统计信息如图4所示。然后读取earthquake_info.txt文本文件中的内容,遍历逐条信息,以日志的方式保存到HDFS分布式系统上。

图4 部分地震数据信息图
3.3 实验环境
实验所使用的计算机为Inter(R) Core(TM) i5- 3337U、1.80 GHz CPU、4 GB内存、Windows 7操作系统,使用JDK1.8、Eclipse 4.4.1、Hadoop2.8.5开发环境。
3.4 实验方法和步骤
(1)在Eclipse下,配置Hadoop路径如图5所示。
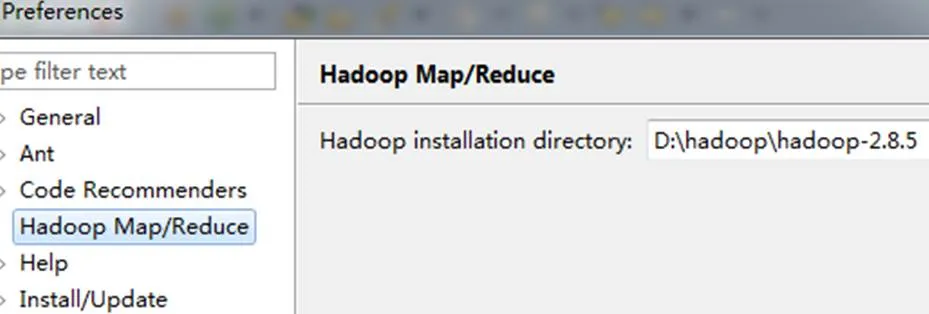
图5 配置Hadoop路径图
(2)在Eclipse下,找到File-new-other-Map/ Reduce,如图6(a)所示,新建Map/Reduce工程myDemo,如图6(b)所示。
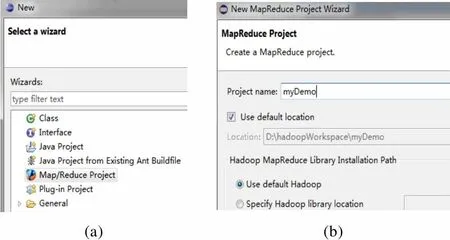
(a)(b)
(3)在工程myDemom的src目录下创建com.pzr. mapreduce包,包中创建MyMapper类、MyReduce类和MyMagnitude主类,然后创建org.apache.hadoop.io. native包,包下建NativeIO类。并将D:hadoophadoop- 2.8.5etchadoop下的log4j.properties文件拷贝到src目录下面。创建目录如图7所示。
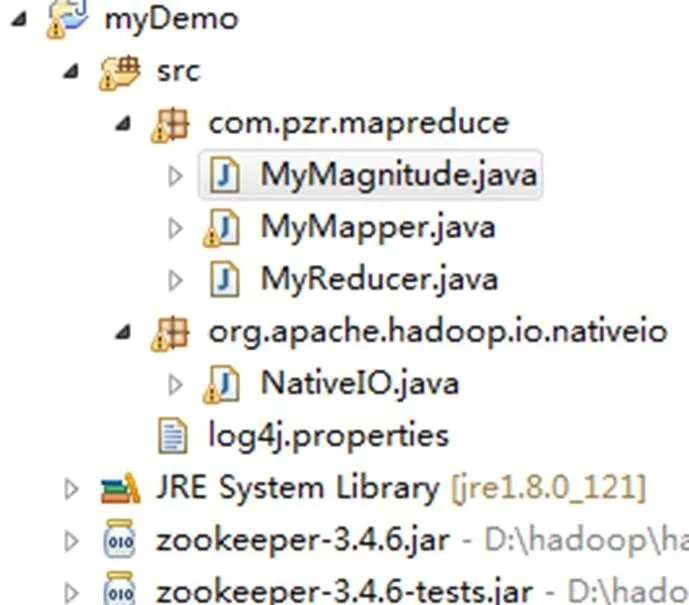
图7 Map/Reduce工程目录结构图
(4)运行MapReduce程序,MyMagnitude是main函数运行类,执行时需要调整运行参数。如图8(a)—(c)所示。

(a) (b) (c)
3.5 算法流程
以获取每年最大震级的任务为例,MapReduce程序MaxMagnitudeByYear的伪代码如表1所示。

表1 伪代码
3.6 实验结果
最终计算出1999年1月至2006年8月每年最大震级实验结果、每月最大震级实验结果和全时段最大震级实验结果,如图9所示。

图9 程序运行实现图
4 结语
针对分布式计算与开发模式实验教学的特点,针对课程实验中存在的问题,通过设计MapReduce编程实例“计算不同时间条件下的最大震级”的综合设计性实验,不仅考查了学生的编程能力,也检验了学生对分布式计算知识的掌握和理解,调动了学生的实验积极性,提高了学生综合运用所学知识的能力。
[1] 秦杰仪,曾志,孙蕾,等.基于Hadoop的大数据平台架设探讨[J].现代工业经济和信息化,2018(5): 47–49.
[2] 范素娟,田军锋.基于Hadoop的云计算平台研究与实现[J]. 计算机技术与发展,2016, 26(7): 127–132.
[3] 马瑞敏,卞艺杰,陈超,等.基于Hadoop的电子商务个性化推荐算法:以电影推荐为例[J].计算机系统应用,2015, 24(5): 111–117.
[4] 梁芷梧.云计算中MapReduce分布式并行处理框架的研究[D].武汉:湖北工业大学,2017.
[5] 陈晨,陈达丽.谷歌大数据技术的研究及开源实现[J].软件产业与工程,2015(5): 31–36.
[6] 付东华.基于HDFS的海量分布式文件系统的研究与优化[D].北京:北京邮电大学,2012.
[7] 易理林. HDFS文件系统中元数据的高可用性管理方法研究[D].广州:华南理工大学,2013.
[8] 郑瑛.分布式并行编程模型MapReduce及其应用研究[J].西南民族大学学报(自然科学版),2017, 43(2): 161–166.
[9] 盘隆.基于MapReduce的分布式编程框架的设计与实现[D].哈尔滨:哈尔滨工业大学,2011.
[10] 武鑫.基于MapReduce的协同过滤算法并行化研究[D].天津:河北工业大学,2014.
[11] 付启沐.基于可重构硬件架构的MapReduce计算方法研究与实现[D].北京:北京交通大学,2016.
[12] 王刚. MapReduce计算模型性能优化的研究[D].济南:山东建筑大学,2016.
[13] 宋杰,郝文宁,陈刚,等.基于MapReduce的分布式ETL多维数据模型研究[J].计算机科学,2013, 40(增刊2): 263–266.
[14] 吴崇正.基于MapReduce的分布式搜索引擎研究[D].兰州:兰州理工大学,2013.
[15] 张家录,陆汝华.基于MapReduce模型的电子商务欺诈信息挖掘方法[J].湘南学院学报,2018(5): 43–47.
Case of comprehensive design experiment for “Distributed computing and development model”
YANG Dan, ZHANG Jing, ZHAO JI, WANG Gang
(SchoolofSoftware, University ofScienceandTechnology Liaoning, Anshan 114051, China)
In view of the characteristics and outline requirements of the “Distributed computing and development model” course for undergraduates majoring in computer science, this comprehensive design experiment is designed. This experiment realizes the statistical task of seismic data set under Windows system by using the Hadoop distribution framework and Eclipse rapid development platform. The experimental purpose, task requirements, experimental methods and procedures and algorithm flow are introduced in detail. Practical results show that through this comprehensive design experiment, students’ experimental enthusiasm and mastery of distributed computing are greatly improved.
distributed computing;comprehensive design experiment; Hadoop; MapReduce
G642.423
A
1002-4956(2019)10-0197-04
10.16791/j.cnki.sjg.2019.10.047
2019-03-02
教育部“数启科教 智见未来”产教联合基金项目(2017B00007);教育部产学合作协同育人项目(201702124017,201702124008);辽宁省创新创业教育改革试点专业项目(辽教函[2017]838号);辽宁省普通本科高等学校向应用型转变示范专业项目(辽教函[2017]779号);辽宁省普通高等教育本科教学改革研究项目(辽教函[2018]471号);辽宁科技大学研究生教育改革与创新项目(2016YJSCX20)
杨丹(1978—),女,辽宁鞍山,博士,副教授,研究方向为分布式计算、大数据管理等。E-mail: asyangdan@163.com
猜你喜欢
自然灾害学报(2022年2期)2022-05-10 11:37:18
奥秘(创新大赛)(2021年3期)2021-05-15 07:05:44
少先队活动(2021年2期)2021-03-29 05:41:04
汽车维修与保养(2021年8期)2021-02-16 00:28:30
学生天地(2020年17期)2020-08-25 09:28:48
山西地震(2020年1期)2020-04-08 07:34:26
数学大王·低年级(2020年3期)2020-03-12 04:48:48
软件导刊(2016年11期)2016-12-22 21:47:07
科学与财富(2016年15期)2016-11-24 13:30:27
系统工程与电子技术(2016年2期)2016-04-16 05:16:58
