
基于高光谱的水稻叶片氮素营养诊断研究
2019-10-28 05:23:20杨红云孙玉婷
浙江农业学报 2019年10期
杨红云,周 琼,杨 珺,孙玉婷,路 艳,殷 华
(1.江西农业大学 软件学院,江西 南昌 330045; 2.江西省高等学校农业信息技术重点实验室,江西 南昌 330045; 3.江西农业大学 计算机与信息工程学院,江西 南昌 330045)
在水稻栽培管理中,氮肥对粮食作物产量的贡献率约占50%[1]。精准施氮可以减少水稻生长过程中的无效分蘖,提高有效成穗率,优化群体结构,改善田间植株生长状况,减轻病虫害的发生,进而促进水稻终产量的形成[2]。近年来,许多学者围绕水稻氮素营养状况诊断进行了大量研究。李金文[3]应用叶绿素计获取水稻叶片生理生态学特征用于氮素诊断;孙棋[4]发现,水稻拔节期冠层图像的颜色特征参量可反映水稻拔节期氮素营养状况;李岚涛等[5]发现,水稻冠层色彩参数与水稻氮素营养指标具有较好的相关性;王远等[6]分割水稻冠层图像提取的特征参数——红光标准化值(NRI)与SPAD值、叶片含氮量具有良好的相关关系;刘江桓[7]应用水稻叶片颜色特征参数进行拟合分析发现,不同生育期水稻顶三叶的颜色特征参数可反映水稻氮素营养状态;邵华等[8]发现,738 nm处的水稻冠层一阶微分光谱反射率与冠层叶片氮素含量相关性较高;祝锦霞等[9-10]基于水稻拔节期顶三叶的颜色特征数据与水稻冠层数据建立水稻氮素水平识别回归模型;陈利苏[11]应用图像处理和支持向量机(SVM)进行温室水培水稻氮素营养诊断,取得了较好的结果,但在其他试验场景下的应用较受限;王树文等[12]发现,水稻冠层高光谱反射率与氮含量具有显著相关性;Yuan等[13]借助数码相机研究了水稻氮素状况与叶片绿度的关系,发现叶片中部比叶尖和叶片基部更适于开展水稻氮素诊断,分蘖期和孕穗期是评估水稻氮素状况的关键诊断阶段。近年来,应用高光谱进行农作物氮素诊断的研究也相继被报道。孙小香等[14]获取晚稻4个生育期冠层的高光谱数据,发现基于冠层光谱指标和BP神经网络进行水稻叶片氮素含量估算的效果较好;张晶等[15]应用SPA-RDI-SVM模型进行甜菜叶片含氮量预测;白丽敏等[16]应用SPA-PLS模型进行冬小麦冠层全氮含量预测;单贵莲等[17]应用多花黑麦草敏感波段光谱反射率R760与植株含氮量建立线性回归模型,效果较好;张国圣等[18]应用沈稻47分蘖期叶片高光谱的归一化差值植被指数(NDVI)与同期氮素含量建立线性回归模型,效果较好;李颖等[19]应用概率神经网络基于室内盆栽水稻的冠层光谱进行氮素营养诊断识别分类,分蘖期、拔节期和抽穗期的总体识别准确率分别为74%、75%和71%。本研究拟通过高光谱技术获取分蘖期水稻的顶三叶光谱数据,应用机器学习方法建立大田水稻氮素营养诊断模型并开展分类识别,旨在摸索一种可准确判别大田环境下水稻氮素营养状况的普适性高、易于推广的方法。
1 材料与方法
1.1 试验设计
试验于2018年在江西省南昌市江西农业大学试验田进行。土壤基本理化性状如下:pH值5.3,全氮1.02 g·kg-1,全磷0.48 g·kg-1,全钾14.22 g·kg-1,有机质19.46 g·kg-1,碱解氮112.31 mg·kg-1,速效磷11.65 mg·kg-1,速效钾123.84 mg·kg-1。
以中嘉早17水稻品种为试验材料。依施氮水平差异设4个处理:N0,不施N;N1,基肥、分蘖肥、穗肥分别施N 114.0、45.6、68.4 kg·hm-2;N2,基肥、分蘖肥、穗肥分别施N 163.0、65.2、97.8 kg·hm-2;N3,基肥、分蘖肥、穗肥分别施N 212.0、84.8、127.2 kg·hm-2。各处理统一基施P 750 kg·hm-2。所有处理均于4月9日播种,4月28日移栽,栽插密度为13.3 cm×26.6 cm,人工移栽,其他田间管理按常规栽培要求进行。
1.2 光谱采集
试验使用ASD野外光谱分析仪采集光谱数据,其波长范围为350~2 500 nm。采样时正值水稻分蘖期(5月17日),每个处理取60片水稻顶三叶叶片,共计240片。以每片叶片为一个样本。每个样本分别采集叶尖、叶中、叶枕3条光谱,以其平均值作为该样本的光谱反射率值,数值处理在Viewspec Program软件中进行。光谱测量时,每间隔15 min进行一次标准白板校正。
1.3 光谱预处理
由于光谱数据会受到谱线平移、高频随机噪声和光散射等因素的干扰,为保证所建模型的精度和稳定性,需对光谱进行预处理,以最大限度地挖掘光谱数据中的有效信息,提升其信噪比。常见的光谱预处理方法包括多元散射校正(MSC)、变量标准化校正(SNV)、平滑算法(SG)、归一化、基线校正等[20]。本研究分别采用MSC、SNV、SG方法进行对比试验。
1.4 特征降维与特征选择
主成分分析(PCA)是将筛选出的能够反映水稻施氮水平类别的几个特征指标重新组合,形成一组无关联、信息不重叠的几个综合指标替代原有的影响指标,视实际需求从中提取若干能够反映原有指标信息的综合指标,以有效地对水稻施氮水平进行预测分类[21]。
连续投影算法(SPA)是一种前向变量选择方法,能有效寻找含有最低限度冗余信息的变量组,使变量之间的共线性达到最小。SPA算法能够从大量的光谱变量中提取少数几个共线性小的光谱特征波长代表原始的光谱数据,从而将数据降维,减少模型的输入变量,提高模型计算速度。以均方根误差(RMSE)为评价指标,以RMSE最小值下的波长个数确定特征波长个数[22]。
1.5 SVM
SVM在解决非线性、小样本数据集、高维空间模式识别等问题上独具优势。核函数是SVM的理论基础。常用的核函数有线性核函数、多项式核函数、径向基核函数、sigmoid核函数[23]。本研究选用径向基核函数作为SVM模型的核函数。
2 结果与分析
2.1 光谱预处理
水稻叶片原始反射光谱及经不同方法预处理后的光谱曲线如图1所示。从图1-A的原始光谱可以看出,不同施氮水平下,水稻叶片光谱反射率曲线表现出相同的走向趋势。在绿波段(约560 nm)处可见明显的反射峰,即“绿峰”;在红波段(约685 nm)处可见明显的吸收谷,即“红谷”;在近红外波段(>760 nm)处出现一个较高的反射平台。图1-B~D分别是经过MSC、SNV、SG预处理后的光谱曲线图,可以看出:MSC处理后的光谱反射率值区间与原始光谱相近,与SNV处理后的光谱走势相近;SNV处理后的光谱反射率值区间与原始光谱差异较大;SG处理后的光谱反射率曲线中各样本分布紧密。

a,原始光谱;b,MSC处理后的光谱;c,SNV处理后的光谱;d,SG处理后的光谱。a, Original spectrum; b, Spectrum after MSC; c, Spectrum after SNV; d, Spectrum after SG.
2.2 主成分分析
对经过不同方法预处理后各处理的样本分别进行主成分分析。如图2所示:MSC处理后主分成1(PC1)的贡献率为82.11%,主成分2(PC2)的贡献率为7.31%;SNV处理后PC1的贡献率为81.60%,PC2的贡献率为7.73%;SG处理后PC1的贡献率为56.59%,PC2的贡献率为26.30%。经过3种方法的预处理后,PC1与PC2的累积贡献率均超过80%且低于90%,各处理的样本点重叠严重,难以对不同处理的样本进行区分;因此,考虑采用基本能够反映原样本信息的累积贡献率超过99.98%的前24个主成分作为SVM的输入变量,3种预处理方法的前24个主成分的累积贡献率如表1所示。
2.3 连续投影算法
若采用全波段进行建模,时间较长,且包含过多冗余信息;因此,采用SPA对经不同方法预处理后的光谱数据提取特征波长(图3),以最小RMSE值下的波长个数作为特征波长数量。对于经过MSC处理后的光谱数据,最小RMSE值为0.431 13,对应的最佳波长个数为12,筛选的特征波长分别是350、374、728、750、1 004、1 187、1 801、1 937、2 465、2 475、2 495、2 500 nm;对于经过SNV处理后的光谱数据,最小RMSE值为0.480 39,对应的最佳波长个数为15,筛选的特征波长分别是350、396、504、700、715、746、1 326、1 438、1 674、1 929、1 981、2 170、2 461、2 495、2 500 nm;对于经过SG处理后的光谱数据,最小RMSE值为0.371 95,对应的最佳波长个数为19,筛选的特征波长分别是350、352、396、419、425、475、646、685、695、708、739、854、1 000、1 001、1 365、1 803、2 013、2 179、2 490 nm。
2.4 基于PCA和SPA的水稻氮素营养诊断
将所有供试样本按照2∶1的比例随机分成建模集和预测集2个集合,其中建模集有160个样本(每个处理各40个),预测集有80个样本(每个处理各20个)。以PCA获取的前24个主成分,和SPA算法获取的特征波长作为模型输入参数,将4个处理的氮素水平分别标记为1、2、3、4,作为模型的输出参数,采用SVM建立水稻氮素营养诊断模型,并开展水稻氮素营养诊断识别,分类结果如表2所示。对于3种光谱预处理方法而言,PCA-SVM模型在预测集上的准确率均高于SPA-SVM模型。其中,对于MSC预处理方法,PCA-SVM模型在预测集上的准确率比SPA-SVM模型高出25.00个百分点;对于SNV预处理方法,法,PCA-SVM模型在预测集上的准确率比SPA-SVM模型高出21.25个百分点;对于SG预处理方法,PCA-SVM模型在预测集上的准确率比SPA-SVM模型高出10.00个百分点。对于PCA-SVM模型,经过MSC预处理的模型在预测集上的准确率最高,经过SNV预处理的模型次之,经过SG预处理的模型最低;对于SPA-SVM模型,经过SNV预处理的模型在预测集上的准确率最高。综合各模型在建模集和预测集上的准确率,MSC-PCA-SVM模型的效果最佳,在建模集和预测集上的准确率分别达99.38%和97.50%,其在预测集上的实际分类与预测分类结果如图4所示,图中纵坐标为氮素水平(类别标签),横坐标为测试样本编号,对于N0、N1、N3处理的样本(对应纵坐标为1、2、4)全部识别正确,对于N2处理的样本(对应纵坐标为3),有2个被误判为N1处理(对应纵坐标为2)。

a,经MSC预处理;b,经SNV预处理;c,经SG预处理。a, After MSC; b, After SNV; c, After SG.
表1 不同预处理方法前24个主成分的累积贡献率
Table1Cumulative contribution rate of the first 24 principal components after different pretreatments

预处理方法Pretreatment累计贡献率Cumulativecontributionrate/%MSC99.9867SNV99.9859SG99.9949

a,b,MSC+SPA;c,d,SNV+SPA;e,f,SG+SPA。
3 结论与讨论
本研究采用不同光谱预处理方法对分蘖期水稻的叶片高光谱数据进行预处理,分别采用PCA和SPA算法进行参数选取,基于SVM建立水稻氮素营养诊断分类模型。结果显示,用MSC-PCA-SVM模型开展水稻叶片氮素营养诊断分类,其在预测集上的识别准确率高达97.50%,仅有少数样本被误判,可有效识别处于缺氮和氮过量水平的水稻叶片,从而对水稻氮素营养状况做出初步判断。
表2 各模型的分类预测结果
Table2Classification prediction results of different models
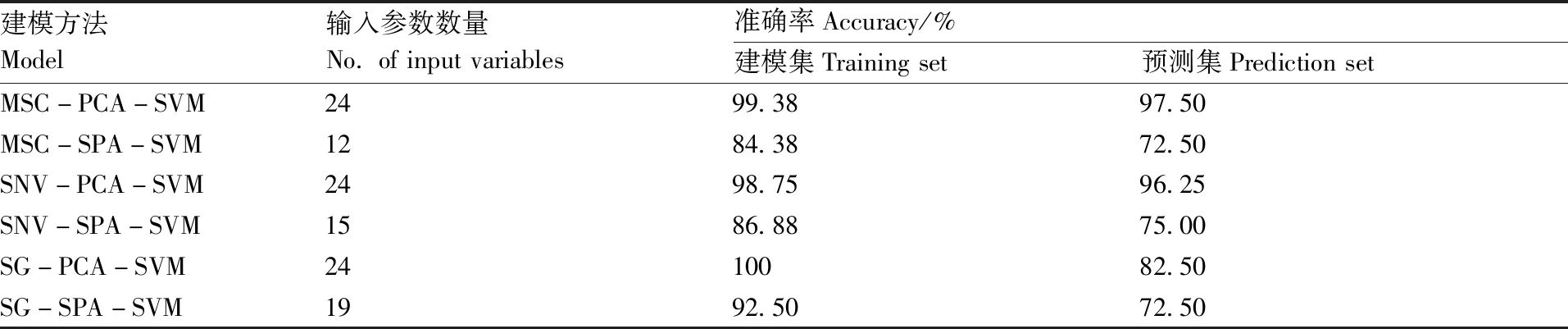
建模方法Model输入参数数量No.ofinputvariables准确率Accuracy/%建模集Trainingset预测集PredictionsetMSC-PCA-SVM2499.3897.50MSC-SPA-SVM1284.3872.50SNV-PCA-SVM2498.7596.25SNV-SPA-SVM1586.8875.00SG-PCA-SVM2410082.50SG-SPA-SVM1992.5072.50

图4 MSC-PCA-SVM模型在预测集上的识别分类结果
本研究采用高光谱技术获取水稻氮素营养诊断分类模型的输入特征数据,并采用机器学习方法建立水稻氮素营养诊断分类模型,研究结果可为作物生长过程反演虚拟研究提供支持,同时为作物氮素营养诊断识别分类提供了一种有效可行的方法,对于科学指导作物施肥也具有参考意义。
顾清等[24]应用图像处理技术和SVM获取叶片黄化比例、叶尖G值、叶片面积3个特征值进行氮素营养诊断,但难以识别氮过量样品。本研究中建立的水稻氮素营养诊断分类模型,能够很好地识别出缺氮(N0处理)和高氮(N3处理)样品,但对于N2处理的样品,有2个被误判为N1处理,这可能是因为这2个处理的样本间相似程度较大,不易于区分。今后应加强对类似样品的识别研究。
本研究仅对2018年在中嘉早17品种水稻上获取的破坏性高光谱数据进行了分析,属于水稻氮素营养诊断的初步研究,尚存在许多值得改进之处。在今后的研究中,拟增加供试水稻品种,丰富不同年限不同时期不同叶位的水稻植株特征数据库,对模型输入参数的选取做进一步研究,同时对非破坏性水稻参数的测量获取开展研究,以便建立更具通用性和实用性的水稻氮素营养诊断识别模型。此外,还拟联合水稻植株的其他参数,开展更为细致的等级分类,或通过获取水稻冠层图像、光谱数据进行氮素反演,建立优化的识别模型,为水稻精准施肥提供理论依据。
猜你喜欢
中国农业信息(2022年1期)2022-05-25 13:31:46
农业机械学报(2021年11期)2021-12-07 05:36:44
大气科学(2021年1期)2021-04-16 07:34:18
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
农业环境科学学报(2017年2期)2017-03-20 14:57:37
新课程学习·中(2013年3期)2013-06-14 05:55:20
植物营养与肥料学报(2011年5期)2011-11-06 07:30:52
植物营养与肥料学报(2011年2期)2011-10-26 03:52:10
