
基于相关向量机和方向导数的车辆识别方法
2019-10-28 07:03:36何爱生宋定波
武汉理工大学学报(交通科学与工程版) 2019年5期
王 畅 何爱生 山 岩 宋定波
(长安大学汽车学院 西安 710064)
0 引 言
我国85%左右的交通事故与驾驶人有关[1-2],而引发交通事故与驾驶人没有准确、快速地做出决策密切相关,驾驶人决策失误与驾驶人有限的信息获取和处理能力有关[3].驾驶人没有意识到潜在的危险车辆是造成交通事故的重要原因[4].高级辅助驾驶系统(advanced driver assistance system, ADAS)可以在一定程度上辅助驾驶人发现驾驶过程中的潜在危险车辆[5],或对车辆进行主动干预以避免交通事故[6].目前ADAS主要通过机器视觉和视觉传感器来识别车辆,其中系统算法的识别精度和算法的实时性是车辆识别系统面临的两个主要挑战[7].因此,设计一种识别精度高、实时性好的车辆识别方法,对于ADAS适应复杂多变的交通场景和实际在线车载应用具有重要意义.
目前,针对车辆识别的方法主要有:基于先验知识的方法、基于运动信息的方法[8]、基于机器学习的方法[9].基于先验知识的车辆识别方法提取车辆的几何特征作为先验知识来确定可能存在车辆的区域,车辆的几何特征包括车辆的对称性、边缘特征,底部阴影等[10].Jazayeri等[11]利用车辆的对称性和车辆底部的阴影识别出视频中的车辆,并利用隐马尔科夫模型将车辆从背景中分离出来.该方法的缺点在于仅通过单一的车辆几何特征难以对车辆进行识别.基于运动信息的车辆识别方法中最具代表性的是光流法[12],但是该方法存在对光照条件敏感和抗噪声干扰能力较弱等缺点.基于机器学习的车辆识别方法首先对车辆特征进行描述,然后利用机器学习的方法训练样本,如利用类Haar特征和改进的AdaBoost分类器[13]、利用HOG和SVM[14]设计识别算法.基于机器学习的车辆车别方法因其良好的鲁棒性和高精度的识别率而被越来越广泛的应用.
此外,国外部分研究人员也利用深度学习[15]的方法来设计车辆识别算法,其方法与基于机器学习的车辆识别方法类似,即需要对建立的模型进行训练,但模型的训练时间一般较机器学习的时间要长.
车辆识别的准确率和实时时性决定了系统工作的有效性,而现有的图像匹配识别车辆算法需建立庞大的图像库,在连续识别时需对图像库内的图像逐一进行比对,计算量很大,可能识别出车辆时,该车辆已经在场景中消失,这将直接导致算法失效.针对此种情况,建立有限的背景图像库,并对图像进行编码,建立相应的特征向量,利用相关向量机对车辆进行识别.在此基础上,利用图像灰度在边缘处的方向导数的变化率进一步细化车辆轮廓,从而准确提取出车辆.
1 图像库的建立
由于车辆在图像中位置的不同以及车辆类型的差异,在建立车辆图像库时需要搜集大量典型的图像作为模板,从而造成图像库的容量非常庞大,在进行图像比对时,计算量大大增加,耗费时间长.
尽管车辆在同一场景中所处的位置不同,但是其背景基本相似,所以构建背景图像库可以大大缩小图像库的容量.因此,考虑建立单一的背景图像库.根据车辆在同一路段可能出现的状态分布建立背景图像库.然而实际行驶过程中每个路段的车道数不尽相同,建立的图像库也应包含车道数目不同的路段图片.保守考虑,建立的图像库中包含六个车道的路段图像.在进行图像比对时,仅需将车道线所围成的区域进行比对,所以,车道线以外的背景对识别结果影响不大.
为减少计算量,对图像库中的图像进行二进制编码.单幅图像的代码由类型段和状态段组成,类型段包含三个字符,状态段包含6个字符.类型段的作用是确定图像中的车道数目,状态段的作用是确定图像中车辆所在的车道.例如一幅图像的代码为101001000,其中101是类型段,十进制的值为5,表示该图像中有五个车道;001000是状态段,表示车辆处在第四个车道上(字符和车道的位置是对应的).
2 搜索域的确定
2.1 车道线的提取
由于车道线具有明显的灰度特征,所以利用Sobel算子[16]对图像中的车道线进行提取,图1的原始街道提取效果见图2.由图2可知,车道线被准确的提取出来,并将图2中车道线所围成的区域作为搜索区域.

图1 原始车道

图2 车道线提取
2.2 网格划分以及特征向量的建立
在进行图像比对时,若逐一对每个像素点进行比对,不仅计算量大,而且很难保证精度.首先将图像划分成16×16的网格,然后对划分后的网格建立特征向量.图像的具体划分过程见图3.

图3 网格划分
由图3可知,图像大小的差异会导致每个网格包含的像素点数不一致.可以利用图像中第1行、第1列和第16行、第16列的元素对图像外沿进行扩充,从而保证每个网格内的像素点数目保持一致.
划分网格后,计算每个网格内像素点灰度的均值,并设定阈值,将搜索域内各个网格内像素点灰度的均值与阈值进行比较,若大于阈值,则将该网格的属性记为1,否则记为0.搜索域外的网格均置为0.通过分析不同阈值下相关向量机的分类准确率,最终确定的阈值为68,通过统计各个网格的类标签来确定特征向量,特征向量的确定过程见表1.

表1 特征向量
统计所有行和列中网格标签为1的数目,并将该数目作为特征向量的元素,则由表1得到的特征向量T为

利用同样的方法可以确定图像库中基元的特征向量.
3 基于相关向量机的图像分类
在确定了特征向量后,只需将原始图像与图像库中的元素进行比对,就可以确定当前场景中是否存在车辆,利用相关向量机对车辆进行识别.
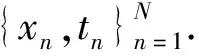
tn=y(xn;w)+ξn
(1)
式中:w为权重;y(xn;w)为相关向量机模型的输出,其计算公式为
y(xn;w)=∑Ni=wik(xn,xi)+w0
(2)
其中:k(xn,xi)为核函数;ξn为满足高斯分布的随机噪声,其数学期望为0,方差为σ2,是未知量,其值可通过训练模型来确定.根据条件概率公式即可得到.
P(tn|w,σ2)=N(y(xi,wi),σ2)
(3)
在确定w和σ2时,若直接使用最大似然法,则结果中w的大部分元素为零,其稀疏特性较差,从而导致过学习,为避免此种情况,对w加上先决条件,即认为w是随机分布在0附近的正态分布,即:
(4)
式中:αi为假定超参,于是通过式(4)可以将对w的求解转化为对α的求解,当α趋近于无穷大时,w趋近于零.
通过求解特征向量的2范数,来确定场景中是否存在车辆.设原图的特征向量为T,图像库中对应图像的特征向量为T',则
(5)
式中:S0为阈值,若RVM的输出为1则表示当前场景中有车辆存在,否则表示当前场景中没有车辆存在.
4 车辆定位以及轮廓细化
通过特征向量元素所在的位置即可确定出车辆所包含的区域,该区域包含了一部分背景像素点,为剔除这些伪目标点,利用方向导数细化车辆轮廓.将像素坐标记为x,y,像素点灰度值记为z,从而构建拟合函数z=f(x,y).图4为车辆区域灰度值的拟合结果.

图4 灰度值拟合
由图4可知,车辆区域中心的灰度值较小,而外沿部分的灰度值逐渐增大,且拟合效果良好.
在利用方向导数细化车辆的轮廓边缘时,首先需要确定搜索方向.以车辆区域的中心点到各个边缘点的方向作为搜索方向,通过求拟合函数z=f(x,y)的极值点得到车辆区域的中心点.方向导数细化车辆轮廓边缘的过程见图5.

图5 细化边缘
图5中l为搜索方向,对于车辆轮廓边缘的每个像素点,沿着相应的方向求拟合函数的方向导数.一般地,背景与车辆交汇处的灰度值的变化近似成高斯分布,由于通过相关向量机获取的车辆区域大于车辆实际所占区域,则沿边界点逆着图5中的方向逐一搜索,通过设置终止搜索条件来确定最终的车辆轮廓.采用双阈值作为限制条件,即方向导数阈值和阈值变化率,方向导数阈值主要是剔除过多的背景区域,阈值变化率主要是对边缘处进一步细化,细化过程为

(6)
通过边缘细化后,车辆的轮廓能够被准确地提取出来,识别结果见图6.

图6 识别结果
由图6可知,基于相关向量机和方向导数的算法能够较为准确地提取车辆的轮廓.
在模型识别效果检验阶段,共采集了不同道路环境下的图片800帧,选取500帧作为模型的训练集,300帧作为模型的测试集.文中算法共准确识别前车的帧数为273帧,总的识别准确率为91.0%.分析识别失误的图片,主要的原因在于目标车辆的特征不够清晰,比如受到树阴的影响,或者车辆与车辆、车辆与其他物体之间的遮挡,这对于图像处理算法而言是较大的挑战.
实际车载使用环境中,文中算法的优越性主要还体现在实时方面.相比于目前较流行的深度学习方法,研究的定位在于在线车载使用.在这种环境下,深度学习所需要的学习训练时间、硬件配置需求均无法满足.提出的算法能够在普通嵌入式平台中快速运行,适合于对实时要求较高的场合[19-20].
5 结 束 语
针对现有的图像匹配技术需要建立庞大的图像库,以及对图像灰度梯度依赖严重等问题,选用相关向量机和方向导数对车辆进行识别,并针对每一幅图像建立相应的特征向量,依据特征向量的2范数确定当前场景中是否存在车辆以及车辆所处的位置.对所提取的区域灰度进行函数拟合,从而确定车辆区域中心,进而对边缘各个像素点建立相应的方向导数,通过迭代搜索满足双阈值的边界,实现对车辆轮廓边缘的细化.模型的测试结果表明,该算法计算量小,图像库容量小,识别耗费时间短,且在车辆轮廓细化方面表现出更优异的性能.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
卫星应用(2021年11期)2022-01-19 05:13:02
科学大众(2021年9期)2021-07-16 07:02:50
中国交通信息化(2020年11期)2021-01-14 03:30:34
许昌学院学报(2018年4期)2018-05-02 12:27:37
电脑知识与技术(2018年35期)2018-02-27 13:29:44
中华建设(2017年1期)2017-06-07 02:56:14
自动化学报(2017年11期)2017-04-04 02:52:44
中国交通信息化(2015年10期)2015-06-06 06:39:31
