
基于卷积神经网络和XGBoost的情感分析模型
2019-10-25 02:33:14尹伟石
复旦学报(自然科学版) 2019年5期
韩 涛,尹伟石,方 明
(1.长春理工大学 理学院,长春 130022; 2.长春理工大学 计算机学院,长春 130022)
随着互联网的日益繁荣和发展,互联网上的各种短文本评论正在成爆炸式地增长,如何从社交网络的文本信息中挖掘用户的情感倾向也得到越来越多的研究人员的关注[1].在过去的研究中,为了实现快速更新和数量巨大的互联网短文本的自动快速分类,处理该问题的传统方式主要包括使用支持向量机(Support Vector Machine, SVM)[2]、朴素贝叶斯分类法(Nave Bayesian Classifier, NBC)[3]等.之后很多研究者使用机器学习(Machine Learning, ML)方法来解决文本分类问题.这类方法通过人工标注一部分数据作为训练集,然后对训练集上的数据进行特征提取和训练来构建情感分类模型,最后使用该模型来对未标注的数据进行情感预测,以此实现文本的情感分类[4-6].近年来,深度学习(Deep Learning, DL)已在自然语言处理(Natural Language Processing, NLP)领域取得了令人瞩目的成功,被广泛应用于自然语言处理任务中[7],但是传统方式和应用机器学习的方式来进行情感分类现在无法达到比较高的正确率,尤其是对于短句或者情感极性表达不清晰的句子无法很好地给出其情感分类.在国外,由于科技条件的进步以及浅层的机器学习技术比较成熟,因此深度学习的方法更多地被用来进行自然语言处理[8-11].在最近的机器学习挑战中XGBoost的有效性和效率得到体现,例如: 2015数据挖掘和知识发现竞赛中,XGBoost被前10名中的每个团队使用.
本文提出一种结合卷积神经网络(Convolutional Neural Network, CNN)和XGBoost的模型来解决短文本语句、情感极性表达不清晰的语句和长文本语句中部分语句的情感分类问题,该模型通过卷积神经网络可以获得使句子更加抽象的特征,其卷积核的设定可以使本文模型更好地得到句子中词组前后之间的关系,应用XGBoost模型将本文通过卷积神经网络得到的抽象特征进行分类,以此解决短文本情感分析准确率不高的问题.
1 模型描述
为了更好地利用文本中的词语信息和情感信息,本文基于卷积神经网络提出一种结合XGBoost的卷积神经网络模型XGB-CNN,该模型能够有效地将卷积神经网络的特征提取与XGBoost模型的分类结合,从而提高模型的分类效果.
本文提出的二分类情感分析XGB-CNN模型整体框架根据功能划分为3部分: 数据预处理,特征提取和回归分析.
1.1 数据预处理
在数据预处理阶段,本文将文字与词向量进行映射处理,使得数据集中的文本转化为向量形式输入模型,每一个词向量列都代表数据集中的一个样本.假设词向量模型中包含的元素有N个,每一个单词的表示为D维,则K:S→W是一个将文本转化为向量的算子,S为词组序列空间,W∈RD⊗N为词向量空间,我们有v=Ks,其中:s是一个由词组构成的列表;v∈RD⊗N是一个的D维向量.在本文的模型中采用word2vec模型来构建词向量.将文本序列中词组对应的词向量依次拼接起来,就得到整个文本序列的词向量表示矩阵:
V=v1⊕v2⊕…⊕vn,
其中: ⊕表示行向量方向的拼接操作;vn为词组的词向量表示.数据集每个数据的长度不同使得V的维度不同,为了保持维度一致和减小运算损耗,我们取词组个数d为V的行向量维数,最后得到V是一个维数为D⊗d的矩阵.
1.2 特征提取
对数据集的特征表示V执行卷积操作,可以在指定窗口内完成数据集文本的语义融合,保留词与词之间的联系.对长度为h的卷积窗口,输入矩阵的卷积操作为
ci=f(w×vi: i+h+b),
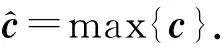
其中⊕表示对2个关键特征的拼接操作.本文在卷积训练时通过一个softmax函数来输出分类结果:
y=softmax(WX+B),
其中:X为下采样层输出;W∈Rm×D为全连接层的权重矩阵;B为全连接层的偏置矩阵.本文使用反向传播算法来训练模型,通过最小化交叉熵来优化模型,交叉熵代价函数为

1.3 回归分析
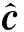
2 实验与分析
本文在2个不同类的数据集上进行实验,通过和现在研究中取得最好效果的模型进行对比实验,来验证本文提出的XGB-CNN模型在特定目标情感分析任务中的有效性.
2.1 实验数据

表1 CNN模型的超参数

表2 XGBoost模型的超参数
本文使用的数据来自于中国科学院计算技术研究所谭松波教授提供的中文情感挖掘语料,语料分为宾馆、水果类.数据集为平衡数据,每一种语料分为正负类各5000篇,共20000篇.本文采用jieba分词工具对中文语料进行分词处理,默认使用隐马尔可夫模型(Hidden Markov Model, HMM)方式识别新词.词向量采用python环境下的Gensim包对数据集进行训练,得到的词向量维数为256维.数据集构成为百度百科,搜狐新闻和微信公众号内容随机扒取的文章,保证了训练得到的单词的广泛性,数据中剔除了所有非中文字符和副词.
2.2 参数设置
为了获取数据集中文本的丰富的特征参数,本文在CNN中使用单窗口、多卷积核对输入的数据集进行卷积操作,同时为了防止过拟合化,本文在CNN模型训练时使用了dropout机制并且在权重更新时加入了L2正则化限制,使用的参数如表1所示.在进行回归分析时,本文采用的是基于树的模型,同时为了防止过拟合化,在权重更新时采用L2正则化限制,同时在树的构造方面降低树的深度,使用的参数如表2所示.
2.3 结果分析
本文使用CNN模型和基于长短期记忆(Long Short-Term Memory, LSTM)的时间递归神经网络(Recursive Neural Network, RNN)模型(用LSTM表示)、XGB-CNN模型在宾馆和水果类的数据集上进行二分类对比实验,来验证本文提出模型的有效性.因为本文采用的数据集为平衡数据集,因此本文采用正确率(r正确)来刻画模型的优劣,实验结果如图1所示.
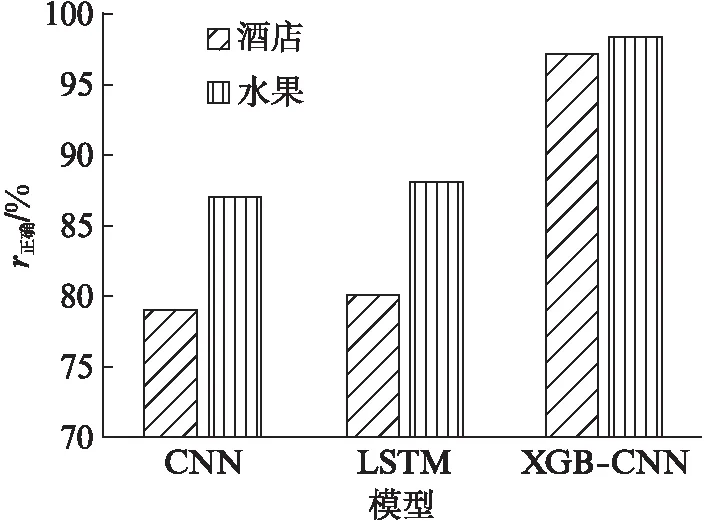
图1 不同模型的二分类实验结果对比Fig.1 Comparison of two-class experimental results of different models
由图1所示的实验结果可以看出,XGB-CNN模型在2个数据集上都取得了比其他网络模型更好的分类效果,在分类效果最好的水果类,XGB-CNN模型正确率比CNN模型提高了11.4%,达到了98.4%,验证了XGB-CNN模型的有效性.没有采用XGBoost模型进行回归分析的CNN和LSTM模型的分类效果都不是很理想,在分类效果最好的水果类的平均正确率也只有87%和88.5%.而采用XGBoost模型进行回归分析的XGB-CNN模型在水果类的平均正确率提高了10%以上,主要原因是CNN和LSTM模型采用softmax来进行分类,其不能很好地进行分类,采用XGBoost模型进行分类的XGB-CNN模型对目标函数的二阶泰勒展开式作近似、定义了树的复杂度并应用到目标函数中的方法提高了模型的分类精度.
由于互联网上的评论具有文本较短的特征,因此有必要对短文本的数据集进行研究.本文对于短文本数据集中不同的文本长度与模型的正确率进行了研究.由图2可以看到在水果类的数据集中词组个数的分布情况,水果类的数据集中文本长度(l)在10个词组以下的短文本数据占到了整个数据集的50%以上,因此水果类的数据集可以较为准确的体现出互联网上评论的短文本特征.
由图3可以看到XGB-CNN模型在水果类的数据集上的平均准确率达到了98.22%,比其他模型的平均准确率提高了10%以上,同时随着文本长度的变化,XGB-CNN模型在准确率上呈现线性相关,但是斜率很小,说明文本长度的变化对于XGB-CNN模型准确率的影响不大.图3中,在长度为10个的文本长度上XGB-CNN模型的准确率有一定的回升,这是因为水果类数据集在5~10个词组的长度上占比很高,由此可以得出XGB-CNN模型在短文本情感分析方面较其他模型有明显的优势的结论.

图2 水果类的数据集的数据文本长度的分布Fig.2 Distribution of text length in fruit data sets

图3 不同文本长度数据的二分类结果Fig.3 Bi-categorization results of data with different text lengths
互联网数据中除评论具有短文本的特点外,在其他的场景中也会有长文本的出现,本文采用宾馆类的数据集来体现互联网数据中长文本数据的特征.宾馆类的数据集的文本词组长度分布如图4所示,文本长度在5到70个词组之间广泛分布可以很好地反应现实情况中互联网文本数据长短不一、短文本占大多数、长文本占少数的特点.
由图5可以看出XGB-CNN模型的准确率与数据变量具有线性正相关,说明XGB-CNN模型在缺少数据的情况下仍可以很好地分辨数据的情感极向,对长文本XGB-CNN模型使用其小部分内容就可以将文本的情感极向表示出来,从而在模型的文本长度阈值较小时仍能够获得很好的准确率.

图4 宾馆类数据集的文本词组长度分布Fig.4 Length distribution of text phrases in hotels data sets

图5 不同长度的文本的二分类结果Fig.5 Bi-categorization of text with different lengths

表3 不同模型完成1次迭代的训练时间
表3为CNN、LSTM和XGB-CNN模型单次迭代所花费的时间.由结果可以看出,在相同的环境下LSTM模型的训练时间远远高于CNN的训练时间,在宾馆类的数据集上,LSTM模型完成1次迭代的训练时间为20.000s,几乎是CNN模型(1次迭代时间为6.000s)的3倍多.这主要是因为LSTM模型接收的是序列化输入,所以训练时间高于接收并行化输入的CNN模型.XGB-CNN模型先使用CNN进行特征提取,之后再使用XGBoost进行分类,在运行时间上本文模型的运行时间仅比CNN的时间多0.038s,主要是由于XGBoost的并行运算模式极大地降低了模型的运行时间.相对于XGB-CNN模型精确度的提升,XGB-CNN模型较CNN模型运行时间的提升可以忽略不计.
3 结 语
本文提出了一种结合卷积神经网络和XGBoost的XGB-CNN模型来解决短文本情感分析中的问题.通过与CNN和LSTM模型进行对比实验,验证了XGB-CNN模型的有效性.在短文本的情感分析中,往往存在不能很好地识别短文本的情感极向和长文本的部分文本进行情感分析准确率不高的问题,本文提出的XGB-CNN模型首先使用CNN提取文本的特征值,之后再使用XGBoost进行分类.试验结果表明: 在分类效果最好的水果类的数据集上的二分类实验的平均准确率为98.22%,相比于以往的模型提升了10%以上,验证了本文提出的XGB-CNN模型在短文本的情感分析中的有效性.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
电视技术(2014年19期)2014-03-11 15:38:20
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
阅读与作文(英语高中版)(2013年11期)2013-11-13 05:36:26
