
图像整体与局部区域嵌入的视觉情感分析
2019-10-23 12:23蔡国永贺歆灏储阳阳
计算机应用 2019年8期
蔡国永 贺歆灏 储阳阳


摘 要:目前多数图像视觉情感分析方法主要从图像整体构建视觉情感特征表示,然而图像中包含对象的局部区域往往更能突显情感色彩。针对视觉图像情感分析中忽略局部区域情感表示的问题,提出一种嵌入图像整体特征与局部对象特征的视觉情感分析方法。该方法结合整体图像和局部区域以挖掘图像中的情感表示,首先利用对象探测模型定位图像中包含对象的局部区域,然后通过深度神经网络抽取局部区域的情感特征,最后用图像整体抽取的深层特征和局部区域特征来共同训练图像情感分类器并预测图像的情感极性。实验结果表明,所提方法在真实数据集TwitterⅠ和TwitterⅡ上的情感分类准确率分别达到了75.81%和78.90%,高于仅从图像整体特征和仅从局部区域特征分析情感的方法。
关键词:社交媒体;情感分析;图像局部对象检测;深度学习;神经网络
中图分类号: TP181
文献标志码:A
Visual sentiment analysis by combining global and local regions of image
CAI Guoyong, HE Xinhao*, CHU Yangyang
Guangxi Key Laboratory of Trusted Software (Guilin University of Electronic Technology), Guilin Guangxi 541004, China
Abstract: Most existing visual sentiment analysis methods mainly construct visual sentiment feature representation based on the whole image. However, the local regions with objects in the image are able to highlight the sentiment better. Concerning the problem of ignorance of local regions sentiment representation in visual sentiment analysis, a visual sentiment analysis method by combining global and local regions of image was proposed. Image sentiment representation was mined by combining a whole image with local regions of the image. Firstly, an object detection model was used to locate the local regions with objects in the image. Secondly, the sentiment features of the local regions with objects were extracted by deep neural network. Finally, the deep features extracted from the whole image and the local region features were utilized to jointly train the image sentiment classifier and predict the sentiment polarity of the image. Experimental results show that the classification accuracy of the proposed method reaches 75.81% and 78.90% respectively on the real datasets TwitterⅠand TwitterⅡ, which is higher than the accuracy of sentiment analysis methods based on features extracted from the whole image or features extracted from the local regions of image.
Key words: social media; sentiment analysis; image local object detection; deep learning; neural network
0 引言
當前,越来越多社交媒体用户喜欢用视觉图像来表达情感或观点,相较于文本,视觉图像更易于直观表达个人情感,由此,对图像的视觉情感分析引起了人们的广泛关注和研究[1-2]。视觉情感分析是一项研究人类对视觉刺激(如图像和视频)做出的情感反应的任务[3],其关键挑战问题是情感空间与视觉特征空间之间存在的巨大鸿沟问题。
早期的视觉情感分类主要采用特征工程的方法来构造图像情感特征,如采用颜色、纹理和形状等特征[4-6]。深度神经网络学习因其能够进行鲁棒且准确的特征学习,近年来在计算机视觉领域取得了巨大成功[7-9]。特别是卷积神经网络(Convolution Neural Network,CNN)能够自动地从大规模图像数据中学习稳健的特征且展示了优异的性能,在图像分类以及目标检测等图像相关任务上得到了广泛应用,因此基于CNN的方法也被提出用于预测图像情感[10]。尽管基于深度神经网络相关的模型已经取得了不错的效果,但是现有方法基本是从图像整体提取特征来预测视觉情感,对图像中局部情感突出的区域并没有区别对待,因此情感分类效果还有提升空间。
针对现有研究中通常只利用整张图像学习情感表示而忽略了图中情感突出的局部区域的问题,本文提出了一种新颖的嵌入包含对象的局部区域特征到图像整体特征的视觉情感分析方法。该方法首先利用目标检测模型探测对象局部区域,然后利用深度神经网絡和迁移学习从局部区域抽取局部区域视觉特征并嵌入图像整体情感特征来训练情感分类器。
1 相关工作
视觉情感分析方法的特征工程主要基于特征选择或特征抽取方法。如吕鹏霄[11]基于尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)引入具有表征感情色彩的颜色特征,分别提取RGB三个颜色通道的SIFT特征,串联在一起形成384维的颜色尺度不变特征变换(Color SIFT, C-SIFT)特征来预测图像的情感。
Yanulevskaya等[12]通过提取图像的纹理特征,然后使用支持向量机将情感图像进行分类从而预测图像情感。文献[13]中构建了一个由1200个形容词名词对(Adjective Noun Pair, ANP)组成的大型视觉情感本体库,同时在该本体库的基础上分别提出了情感银行(Sentiment bank, Sentibank)和视觉情感本题库(Visual Sentiment Ontology, VSO)的情感探测器来提取输入图像的中层表示,并把这些中层表示视为图像特征来学习情感分类器。
文献[2]中采用了与文献[13]相似的策略,区别在于使用102个预定义场景属性取代了ANP作为中层表示。
近年来,随着社交网络上的视觉内容不断增加,传统方法难以应对大规模数据的伸缩性和泛化性问题[14],研究者开始采用深度模型自动地从大规模图像数据中学习情感表示,且效果良好。如文献[14]中研究了视觉情感概念的分类,并在文献[13]中给出的大型数据集上进行训练得到了SentiBank的升级版本DeepSentiBank。
You等[15]定义了一个CNN架构用于视觉情感分析,而且为解决在大规模且有噪声的数据集上进行训练的问题,他们采用逐步训练的策略对网络架构进行微调,即渐进卷积神经网络(Progressive CNN, PCNN)。
Campos等[16-17]利用迁移学习和来自于预训练的权重与偏置,通过用Flickr数据集微调分类网络,然后再用于图像情感分类。
尽管上述方法都取得了一定的效果,但是基本都是考虑从图像整体抽取特征,很少有人关注到图像局部区域情感信息表达的差异性。文献[18]中利用深度学习框架自动发现包含物体并携带大量情感的局部区域用于视觉情感分析,Li等[19]则提出了一种兼顾局部和局部 整体的上下文情境感知分类模型。不同于已有研究,本文的关注点是:1)获得定位精确的携带情感对象的局部区域;2)在深度网络结构中,利用特征嵌入的方法同时考虑整体图像与局部区域。即将图像整体特征和局部区域特征嵌入到一个统一的优化目标中,使整合后的特征具有更好的判别性。
2 方法描述
为了从图像中诱发情感的显著对象局部区域和整体图像中学习具有判别性的情感表示,本文方法的整体框架如图1所示,包括以下四个部分:1)图像整体特征提取;2)目标检测模型预训练;3)图像中包含对象的局部区域特征提取;4)整体与局部区域特征整合及视觉情感分类。
其中,利用Simonyan等[20]提出的VGGNet-16提取来自整张图像的全局特征表示(如图1(a))。
目标检测模型Faster R-CNN[21]作为时下流行且性能出色的目标检测框架,利用全卷积网络将对象定位和对象分类两个任务整合到一个端到端的深层网络架构中,通过共享网络模型参数以增强特征映射的鲁棒性同时减少定位对象所花费的时间,能极大地提高目标检测效果。 这里上下文的逻辑在哪
为了提取局部区域特征,本文首先利用目标检测数据集预训练目标检测模型,获得模型参数(如图1(c));随后利用情感图像数据集再次训练目标检测模型,从而获得更好的、能检测出图像中携带情感的物理对象区域,并学习包含对象的局部区域情感表示(如图1(b));最后结合图像整体特征与局部区域特征,并用于训练情感分类器(如图1(d))。
2.1 图像局部区域特征提取
局部区域特征通常包含图像中对象的细粒度信息,本文关注检测社交网络图像中出现频率高且能突显情感的多个对象,并对这些包含对象的局部区域提取深层特征。假定一张图像中探测到的某一个局部区域表示为特征向量 L fi,则检测到的所有局部区域可表示为特征向量集{ L f1, L f2,…, L fm},m为检测到的局部区域个数。局部特征提取基于目标检测模型进行,即首先将图像输入该模型后生成一个多通道的特征映射,利用一个滑动窗口遍历已生成的特征映射获得一系列候选框;然后通过对比各个候选框与目标检测图像真实标签的交叠率来判定候选框内是否存在检测对象,从而获得本文所需的局部区域;最后再利用深层神经网络提取该局部区域情感特征。本文利用迁移学习的策略来克服目标检测数据集与图像情感数据集之间的差异。首先利用Faster R-CNN模型在目标检测数据集PASCAL VOC 2007上进行预训练,然后将已经学习好的模型参数迁移到情感分析的目标区域检测中。下面首先介绍如何利用Faster R-CNN生成目标区域候选框。
2.1.1 候选框生成
候选框生成网络的输入是任意大小的图像,输出是一组矩形候选框。假设输入图像尺寸为M×N,图像经过一系列卷积层变换之后得到卷积特征映射 F ∈ R w×h×n,其中:w和h为卷积特征映射的宽度和高度,n表示卷积特征映射的通道个数。设卷积特征映射 F 大小为(M/16)×(N/16),即输入图像与输出特征映射的宽和高均缩放到1/16。为生成候选框,Faster R-CNN在卷积特征映射上利用了一个两层的CNN,第一层包含c个大小为a×a的滤波器 g ∈ R a×c,滤波器 g 在输入的卷积特征映射上进行滑动,生成一个较低维的特征 F ′∈ R w′×h′×l,计算式如式(1):
F ′=δ( g F +b) (1)
其中:是卷积操作;b∈ R 是一个偏置项, R 为实数集;δ(·)是一个非线性激活函数。对于 F ′上的每一个位置考虑k种可能的候選框尺寸以更好地检测出不同大小的对象,假设 F ′的宽度和高度分别为w′、h′,即 F ′的尺寸为w′×h′,则可得到w′h′k个候选框。随后该特征 F ′被送入两个并列的全连接层:一个用于分类,即判定候选框中是否存在对象;另一个用于回归,即预测候选框的中心点坐标以及尺寸,如图1(c)中最右侧的两个分支所示。因此,对于k个候选框,分类层输出2k个评估候选框是否存在对象的概率得分,即对应二分类问题:候选框存在对象或不存在;回归层输出4k个候选框对应坐标值,即输出为候选框中心点二维坐标以及候选框的宽度和高度。分类层与回归层损失函数的加权表达式如下:
L({pi},{ti})= 1 Ncls ∑ k i=1 Lcls(pi,p*i)+λ 1 Nreg ∑ k i=1 p*iLreg(ti,t*i) (2)
其中:pi表示第i个候选框的预测结果。p*i表示第i个候选框的真实标签:p*i=1则为正样本,即候选框内存在对象;反之p*i=0则为负样本,即候选框为背景。Ncls表示一个Minibatch产生的所有候选框数量,因为判断候选框内是否存在对象属于二分类问题,所以Lcls采用常用于二分类问题的对数损失函数Log Loss,计算公式如式(3)。
Lreg采用衡量预测值与真实标签偏差程度的常见的损失函数Smooth L1 Loss,计算公式如式(4),其中ti表示候选框的大小尺寸,t*i则是ti对应的真实标签,Smooth L1 Loss计算公式如式(5)。λ为超参数。
参数所处级别不一致,导致公式 解释的位置怎么放都有点问题;4、5这两个公式 在这里到底表达什么?
l(θ)=p*ilnpi+(1-p*i)ln(1-pi) (3)
Lreg(ti,ti)=∑smoothL1(ti-ti) (4)
smoothL1(x)= 0.5x2, | x | <1 | x | -0.5, 其他 (5)
2.1.2 候选框特征提取
假设L={r1,r2,…,rn}为生成的包含对象的候选框集合,将矩形框集合L投影到卷积特征映射 F ∈ R w×h×n上再进行局部区域特征提取,从而避免对矩形框进行裁剪或缩放导致的图像信息缺失,同时可以减少大量卷积运算花费的时间[22]。候选框集合中的任意一个元素ri={( x i,yi)}ni=1作为情感图像中生成的候选框样本,如图2(a)中的矩形框ri所示。其中 x i通常表示为四维向量,分别表示候选框的中心点坐标和宽高;yi∈{0,1}表示候选框内对象对应的情感标签。对于每一个候选框样本,为获取矩形框内多个层次的语义信息,对候选框进行m种不同粒度的划分,如图2(b)中所示。随后对划分的每一子块bj进行最大池化操作得到一系列具有区分性的特征映射{ f 1, f 2,…, f d},d表示划分后的子块个数,计算式如式(6):
f i=Gmax(bj) (6)
其中:bj表示划分后的某一子块; f i表示子块bj对应的特征映射;Gmax(·)表示最大池化操作。最后将所有子块的特征映射相加从而得到固定维度的局部区域特征向量,具体表示如式(7):
L fi=∑ d i=1 f i (7)
本文考虑对候选框同时设置3种划分尺寸,分别为{3×3,2×2,1×1},最大池化过程中的步长和窗口由输入的矩形框决定。
2.2 整体图像特征提取
整体图像特征是与图像的情感表示相关的重要因素,通常包含图像整体外观信息和图中对象周围的上下文信息。本文采用如图3所示的VGGNet-16框架提取整体图像特征。VGGNet-16由5个卷积块和3个全连接层组成,作为牛津大学和DeepMind公司共同研发的深层神经网络,它比普通的卷积神经网络拥有更深层的网络结构和统一的网络配置,使得它在减少参数的同时能进行更多的非线性变换,从而具备更加出色的特征提取能力。
具体地,从VGGNet-16的最后一个全连接层fc7提取图像整体特征,得到一个4096维的特征向量,记为 G f,如图3所示。
2.3 图像整体与局部区域嵌入的情感分类
深度图像整体特征和包含对象的局部区域特征通过对应的网络架构提取到的特征表示分别为 G f和{ L f1, L f2,…, L fm},选择检测到的前m个对象来表示重要的局部区域信息,因此每张图像最终可被表示为一组情感信息更加丰富的特征向量 U ={ G f, L f1, L f2,…, L fm}。为了将图像整体特征与局部区域特征相结合,本文采用特征拼接的方法对两种特征进行融合,具体表示如式(8):
φ( U )= G f⊕ L f1⊕ L f2⊕…⊕ L fm
(8)
其中⊕表示整体特征和局部特征的拼接。
对于视觉情感分类而言,情感标签在训练过程中的作用不容忽视。本文选择一种较为简单的处理方法,即对相应图像中检测到的局部对象区域均赋予与原图一致的情感极性。在获得拼接好的联合特征向量φ( U )之后,将其送到全连接层,并通过softmax分类到输出类别中。为衡量模型损失,本文使用交叉熵定义损失函数,softmax层解释联合特征向量φ( U )到输出的类别中且分配一个相对应的概率分数qi,若输出的情感类别的数量为s,则:
qi=exp(φ( U )i) / ∑ s i=1 exp(φ( U )i) (9)
l=-∑ s i=1 hi ln(qi) (10)
其中:l是网络的交叉熵损失;hi为图像的真实情感标签。
3 实验结果及分析
本章主要评估本文所提出的方法,并对比其他通过整体图像特征进行情感分类的方法,以验证本文方法对于视觉情感分析的有效性。
3.1 数据集
在2个公共数据集TwitterⅠ、TwitterⅡ上对本文方法进行评估。TwitterⅠ是从社交软件Twitter中收集的881张包含两类情感极性(积极和消极)的图像及其对应的基于群智策略的人工标注的情感标签;TwitterⅡ由文献[15]提供,包含1269张同样来自于Twitter中的图像,由5名亚马逊劳务众包平台(Amazon Mechanical Turk, AMT)
为对应的图像标注两类情感极性标签。这两个数据集均采用随机划分的方式将80%的样本作为训练集,剩下的20%作为测试集。
3.2 实验设置
实验开发环境为Linux-Ubuntu14.04, Python 2.7, Tensorflow 1.3.0,开发工具为PyCharm。TwitterⅠ和TwitterⅡ数据集均在Tesla P100-PCIE GPU工作站上完成。提取图像整体特征采用的网络架构为CNN框架VGGNet-16,与Faster R-CNN模型生成卷积特征映射的网络架构一致,这是为后续进行特征向量拼接做准备。输入图像尺寸为224×224,选择MomentumOptimizer优化器对模型进行优化, Momentum表示动能优化,非变量,是代码中的概念名称 Momentum设为0.9,学习率设为0.001。模型采用Dropout策略,Dropout值设为0.5。选用交叉熵作为模型损失函数,并利用L2范式防止过拟合,训练迭代次数共100个epochs。提取局部区域特征则利用Faster R-CNN模型,采用大规模检测数据集PASCAL VOC 2007进行预训练并初始化模型权重,接着利用ImageLab标注工具对情感图像数据集中的人、车等5类对象进行目标检测标签标注,此时数据集既包含情感标签也包含目标检测标签(包含对象的矩形框的中心点坐标和宽高)。利用該数据集对已训练好的Faster R-CNN模型进行微调,从而获得包含对象的局部区域。Faster R-CNN的初步特征提取网络同样选择VGGNet-16,调整其候选框区域池化层,池化核采用3×3,2×2,1×1,以适应本文数据集。
3.3 对比方法
为验证本文方法的有效性,将本文方法与特征工程方法和基于CNN框架提取图像整体特征的方法进行对比,包括
SentiBank模型、DeepSentiBank模型以及ImageNet数据集微调的AlexNet和VGGNet-16模型。对比方法均在本文的两个情感图像数据集TwitterⅠ、TwitterⅡ上进行测试评估,输入图像尺寸均为224×224。此外,本文考虑忽略整体图像的情况,仅采用局部对象区域特征提取网络进行情感二分类实验。具体说明如下:
SentiBank:通过组建形容词名词短语对(ANP)提取图像中的视觉概念中层表示,该表示被视为图像特征来学习情感预测分类器[12]。
DeepSentiBank:利用深度卷积神经网络在大型数据集上训练的视觉情感概念分类器,即SentiBank的改良版[14]。
ImageNet-AlexNet:利用迁移学习的思想,将AlexNet在ImageNet数据集上进行预训练并在情感数据集上进行微调,用于视觉情感分析[23]。
ImageNet-VGGNet-16:与ImageNet-AlexNet模型思路相同,区别在于网络换成了更深层的VGGNet-16[20]。
Local regions-Net:忽略图像整体特征提取,利用Faster R-CNN直接捕捉图像中的局部对象区域,然后通过全连接网络学习局部对象区域的情感表示,将该表示作为图像情感特征训练情感分类器。
3.4 结果分析
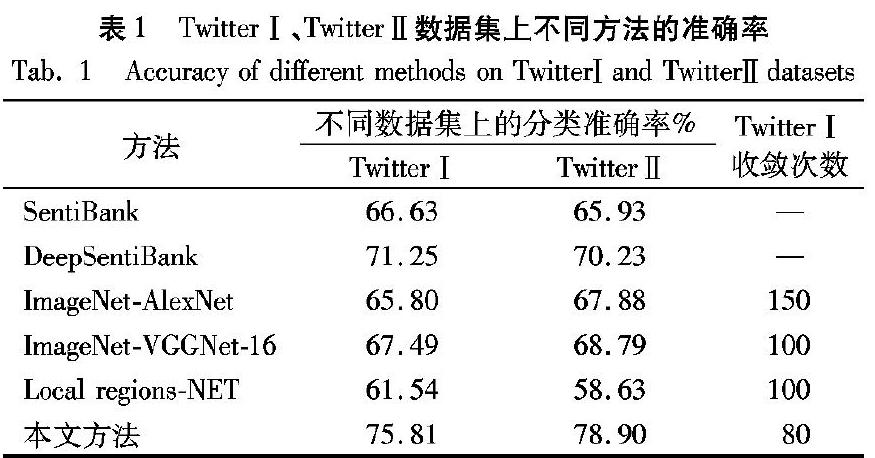
表1是本文方法与对比方法在两个真实数据集TwitterⅠ、TwitterⅡ上得到的分类准确率。由表1可知:本文方法在数据集TwitterⅠ和TwitterⅡ上的分类准确率分别达到了7581%和78.90%,而对比方法SentiBank模型在数据集TwitterⅠ和TwitterⅡ上的准确率仅为66.63%和65.93%;同时,本文方法在数据集TwitterⅠ、TwitterⅡ上的分类效果相比DeepSentibank模型分别提高了4.56个百分点和8.67个百分点。这表明本文方法在视觉情感分析中能够学习更具区分性的表示。
如图4所示,本文方法对来自TwitterⅡ数据集中的验证样例进行情感极性预测,通过检测图中突显情感的物理对象来加强视觉情感分类的效果。图4(a)通过检测微笑的人脸,提取该区域特征然后结合图像整体特征和局部对象区域特征以加强情感表示,最后预测图像情感极性为积极,与图像原始标签一致,即正确样例;图4(b)检测出图中举手示意的人,但忽略了图中背景中燃烧的火焰,最后预测图像情感为积极,即错误样例。
此外,本文还对比了微调之后的深度神经网络AlexNet和VGGNet-16架构,在相同的参数设置下,微调后的VGGNet-16在数据集TwitterⅠ、TwitterⅡ上准确率均提高了约10个百分点。实验结果验证了结合局部对象区域表示的有效性。
同样还对比了仅考虑局部区域提取网络,仍采用相同的参数设置,它们在数据集TwitterⅠ、TwitterⅡ上的情感分类准确率同样低于本文方法,且同样低于特征工程方法和基于CNN框架提取图像整体特征的方法。
本文方法還与基于CNN框架提取图像整体特征的方法进行了算法效率比较,如表1最后一列所示,该列表示本文方法与对比方法在TwitterⅠ数据集上进行迭代训练时的收敛速度。可以看到,本文方法在进行80次迭代后即达到收敛,且准确率达到75.81%,而ImageNet-AlexNet模型和ImageNet-VGGNet-16模型分别需要进行150次和100次的迭代训练才能达到收敛,且分类准确率要低于本文方法。这表明本文方法能够更快速地学习具有判别性的情感表示,同时能获得更好的分类效果。
最后,我们对利用情感图像训练目标检测模型的迁移参数策略进行了收敛实验分析,选择目标检测数据集PASCAL VOC 2007迭代70000次训练后的Faster R-CNN模型参数作为模型初始化参数,然后利用情感图像再次训练Faster R-CNN,训练得到的平均准确率为62.8%,而Faster R-CNN模型在PASCAL VOC 2007测试集上的平均准确率为68.5%。考虑到目标检测图像比情感图像要多4倍左右,且目标检测真实标签更加精确,因此6个百分点左右的差距是可以接受的,同时也说明利用参数迁移策略是行之有效的。
4 结语
视觉情感分析正在获得越来越多的关注,考虑到图像的情感不仅仅来自于图像整体,图像中包含对象的局部区域同样能诱发情感,本文提出了一个新颖的图像整体与局部区域嵌入的方法以加强图像情感表示并用于视觉情感分析。该方法首先利用Faster R-CNN模型检测图像中的对象,通过深层神经网络学习图像局部区域的情感表示,并将其与图像整体特征进行融合,从而获得更具有判别性的情感表示。在两个真实数据集TwitterⅠ和TwitterⅡ上评估验证了本文方法的有效性,且实验结果表明本文提出的图像整体与局部区域嵌入的视觉情感分析方法要优于仅从图像整体和仅从局部区域学习情感表示的方法。
然而在本文研究中仅考虑利用图像中包含对象的局部区域情感来加强视觉情感分析,并没有考虑捕捉图像中能诱发情感的其他区域。因此在未来的工作中将考虑通过弱监督学习等方法更精确地发现视觉图像中的情感区域,设计更合理的特征提取网络以进一步提高视觉情感分析的效果。
参考文献 (References)
[1] JIN X, GALLAGHER A, CAO L, et al. The wisdom of social multimedia: using flickr for prediction and forecast [C]// Proceedings of the 18th ACM International Conference on Multimedia. New York:ACM, 2010: 1235-1244.
[2] YUAN J, MCDONOUGH S, YOU Q, et al. Sentribute: image sentiment analysis from a mid-level perspective [C]// Proceedings of the 2nd International Workshop on Issues of Sentiment Discovery and Opinion Mining. New York: ACM, 2013: Article No.10.
[3] YANG J, SHE D, LAI Y, et al. Weakly supervised coupled networks for visual sentiment analysis [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 7584-7592.
[4] WANG X, JIA J, HU P, et al. Understanding the emotional impact of images [C]// Proceedings of the 20th ACM International Conference on Multimedia. New York: ACM, 2012: 1369-1370.
[5] CHENG Y, CHEN S. Image classification using color, texture and regions [J]. Image & Vision Computing, 2003, 21(9): 759-776.
[6]IQBAL Q, AGGARWAL J K. Retrieval by classification of images containing large manmade objects using perceptual grouping [J]. Pattern Recognition, 2002, 35(7): 1463-1479.
[7] KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 1725-1732.
[8] CHEN M, ZHANG L, ALLEBACH J P. Learning deep features for image emotion classification [C]// Proceedings of the 2015 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2015:4491-4495.
[9] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC:IEEE Computer Society, 2015: 1-9.
[10] YOU Q, LUOO J, JIN H, et al. Building a large scale dataset for image emotion recognition: the fine print and the benchmark [J]. arXiv E-print, 2018: arXiv:1605.02677.
Proceedings of the 13th AAAI Conference on Artificial Intelligence. Barcelona: AAAI Press, 2016: 308-314.沒查到这个信息
[11] 吕鹏霄.图像情感分类研究[D].秦皇岛:燕山大学,2014:1-15. (LYU P X. Research on image emotion categorization [D]. Qinhuangdao: Yanshan University, 2014:1-15.)
[12] YANULEVSKAYA V, van GEMERT J C, ROTH K, et al. Emotional valence categorization using holistic image features [C]// Proceedings of the 2008 15th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2008: 101-104.
[13] BORTH D, JI R, CHEN T, et al. Large-scale visual sentiment ontology and detectors using adjective noun pairs [C]// Proceedings of the 21st ACM International Conference on Multimedia. New York:ACM, 2013: 223-232.
[14] CHEN T, BORTH D, DARRELL T, et al. DeepSentiBank: visual sentiment concept classification with deep convolutional neural networks [J]. arXiv E-print, 2014: arXiv:1410.8586.
[EB/OL]. [2018-10-18]. https://arxiv.org/pdf/1410.8586.pdf.
[15] YOU Q, LUO J, JIN H, et al. Robust image sentiment analysis using progressively trained and domain transferred deep networks [C]// Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 381-388.
[16] CAMPOS V, SALVADOR A, GIRO-I-NIETO X, et al. Diving deep into sentiment: understanding fine-tuned CNNs for visual sentiment prediction [C]// Proceedings of the 1st International Workshop on Affect and Sentiment in Multimedia. New York: ACM, 2015: 57-62.
[17] CAMPOS V, JOU B, GIRó-I-NIETO X. From pixels to sentiment: fine-tuning CNNs for visual sentiment prediction [J]. Image & Vision Computing, 2017, 65: 15-22.
[18] SUN M, YANG J, WANG K, et al. Discovering affective regions in deep convolutional neural networks for visual sentiment prediction [C]// Proceedings of the 2016 IEEE International Conference on Multimedia and Expo. Piscataway, NJ: IEEE, 2016:1-6.
[19] LI B, XIONG W, HU W, et al. Context-aware affective images classification based on bilayer sparse representation [C]// Proceedings of the 2012 ACM International Conference on Multimedia. New York: ACM, 2012: 721-724.
[20] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv E-print, 2018: arXiv:1409.1556. [EB/OL]. [2018-11-15]. https://arxiv.org/abs/1409.1556.
[21] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C]// Proceedings of the 2015 International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 91-99.
[22] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(9):1904-1916.
[23] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2012: 1097-1105.
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
软件(2017年6期)2017-09-23
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
艺术科技(2016年9期)2016-11-18
社会科学(2016年8期)2016-11-04
电脑知识与技术(2016年5期)2016-04-14
