
基于并行混合神经网络模型的短文本情感分析
2019-10-23 12:23陈洁邵志清张欢欢费佳慧
计算机应用 2019年8期
陈洁 邵志清 张欢欢 费佳慧


摘 要:针对传统的卷积神经网络(CNN)在进行情感分析任务时会忽略词的上下文语义以及CNN在最大池化操作时会丢失大量特征信息,从而限制模型的文本分类性能这两大问题,提出一种并行混合神经网络模型CA-BGA。首先,采用特征融合的方法在CNN的输出端融入双向门限循环单元(BiGRU)神经网络,通过融合句子的全局语义特征加强语义学习;然后,在CNN的卷积层和池化层之间以及BiGRU的输出端引入注意力机制,从而在保留较多特征信息的同时,降低噪声干扰;最后,基于以上两种改进策略构造出了并行混合神经网络模型。实验结果表明,提出的混合神经网络模型具有收敛速度快的特性,并且有效地提升了文本分类的F1值,在中文评论短文本情感分析任务上具有优良的性能。
关键词:卷积神经网络;特征融合;双向门限循环单元;注意力机制;短文本情感分析
中图分类号: TP183; TP391.1
文献标志码:A
Short text sentiment analysis based on parallel hybrid neural network model
CHEN Jie, SHAO Zhiqing*, ZHANG Huanhuan, FEI Jiahui
School of Information Science and Engineering, East China University of Science and Technology, Shanghai 200237, China
Abstract:
Concerning the problems that the traditional Convolutional Neural Network (CNN) ignores the contextual semantics of words when performing sentiment analysis tasks and CNN loses a lot of feature information during max pooling operation at the pooling layer, which limit the text classification performance of model, a parallel hybrid neural network model, namely CA-BGA (Convolutional Neural Network Attention and Bidirectional Gated Recurrent Unit Attention), was proposed. Firstly, a feature fusion method was adopted to integrate Bidirectional Gated Recurrent Unit (BiGRU) into the output of CNN, thus semantic learning was enhanced by integrating the global semantic features of sentences. Then, the attention mechanism was introduced between the convolutional layer and the pooling layer of CNN and at the output of BiGRU to reduce noise interference while retaining more feature information. Finally, a parallel hybrid neural network model was constructed based on the above two improvement strategies. Experimental results show that the proposed hybrid neural network model has the characteristic of fast convergence, and effectively improves the F1 value of text classification. The proposed model has excellent performance in Chinese short text sentiment analysis tasks.
Key words: Convolutional Neural Network (CNN); feature fusion; Bidirectional Gated Recurrent Unit (BiGRU); attention mechanism; short text sentiment analysis
0 引言
随着信息技术的飞速发展,互联网已经成为了人们表达情感和态度的工具之一。当下的大众点评、美团、携程等软件应用都遍布着用户的评论信息,合理地利用和分析这些评论信息对用户的消费选择和商业组织的决策会起到關键性的指导作用[1],因此,对评论文本进行情感分析得到了学术界的广泛关注。
传统的情感分析研究方法主要是基于机器学习[2]的方法,虽然机器学习的方法性能优越,但是需要借助大量人工标注特征和领域知识,不具备良好的特征扩展性。相较于传统的机器学习,深度学习模型能够自动提取文本特征,显著提高情感分析效率,并取得比传统的机器学习方法更好的效果[3]。
近年来,两大主流深度学习模型——卷积神经网络(Convolutional Neural Network, CNN)和循环神经网络(Recurrent Neural Network, RNN)被提出应用于自然语言处理领域,并在短文本情感分析上取得了显著效果[4]。Kim[5]首先将神经网络应用于情感分类,将预训练好的词向量作为输入,利用CNN实现句子分类;Kalchbrenner等[6]提出一种动态卷积神经网络(Dynamic Convolution Neural Network, DCNN)模型用于句子特征学习,并取得了较好的效果。但是传统的卷积神经网络在进行文本建模时,提取的是局部相连词之间的特征[7],忽略了长距离上下文之间的语义关联性。针对这一问题,本文提出了卷积神经网络结合双向门限循环单元(Bidirectional Gated Recurrent Unit, BiGRU)的混合神经网络。
由于传统的RNN存在梯度消失问题,Hochreiter等[8]设计了长短期记忆(Long Short-Term Memory, LSTM)网络模型用于解决这一问题。在提取长距离上下文语义特征上,LSTM是一种很有效的网络结构模型,但是结构的复杂性使得LSTM的计算代价比较高。Cho等[9]提出了一种LSTM的替代方案——门限循环单元(Gated Recurrent Unit, GRU)。相比LSTM模型,GRU模型的结构简单,可以提高模型的训练速度[10],并且还能解决RNN存在的梯度消失问题。由于文本中词的语义信息与该词的前后信息都相关,因此本文利用两个GRU左右传播组合成BiGRU来提高文本分类的F1值。
注意力机制和人类的选择性视觉注意力机制类似,核心目标是在众多信息中,通过计算概率分布选择出对当前任务更关键的信息。Mnih等[11]在使用RNN模型进行图像分类时加入了注意力机制,之后Bahdanau等[12]首次将注意力机制应用到自然语言处理(Natural Language Processing, NLP)领域中,将注意力机制应用在机器翻译的任务上,通过注意力机制将源语言端每个词学到的表达和预测需要翻译的词联系起来。
Luong等[13]提出了局部和全局两种注意力机制。Yin等[14]提出了卷积网络和注意力机制结合的三种方式,分别为:在CNN输入之前引入注意力机制;在CNN的卷积层和池化层之间引入注意力机制;以上两种方式的结合。近年来,注意力机制和神经网络模型的结合成为了文本情感分类研究的热点。
由于评论文本多为短文本,含有的特征信息较少且噪声大,为了避免卷积神经网络在池化层进行特征选择时丢失较多的信息特征以及降低噪声的干扰,本文在卷积神经网络和BiGRU网络中加入注意力机制进一步提高文本分类的F1值。
本文的主要工作如下:
1)采用一种并行构建方法提出一种并行混合神经网络模型CA-BGA(Convolutional Neural Network Attention and Bidirectional Gated Recurrent Unit Attention),融合卷积神经网络和BiGRU两种模型,利用卷积神经网络提取局部特征优势的同时,又利用BiGRU兼顾文本序列全局特征的优势,解决了长距离上下文依赖问题,提高网络模型在文本分类上的F1值;
2)在融合模型中引入注意力机制,既能克服卷积神经网络在池化层丢失较多特征的弊端,又能降低评论文本的噪声干扰,进一步提高融合模型在文本分类上的F1值。
1 词向量
利用深度学习方法进行中文情感分析时,首先需要将文本用词向量表示,作为神经网络模型的输入。将中文映射为词向量之前,需要对中文文本进行分词操作处理。但是评论文本属于短文本范畴,存在噪声大、新词多、缩写频繁等特点,因此对评论文本进行分词操作会有明显的歧义。例如,“这家餐厅还行,是一个高大上海鲜餐厅”,在该句中,“高大上海鲜餐厅”如果使用传统的分词技术,会被切分为“高大/上海/鲜/餐厅”或者“高大/上/海鲜/餐厅”,这样切分无法体现句子的正确语义,甚至第一种切分方式还将“上海”切分导致增加了一个评价对象。为了避免上述问题,本文利用字符级词向量[15],以单个字作为句子的基本组成单位,对单个字训练词向量。刘龙飞等[16]发现对于中文短文本,利用深度神经网络进行情感分析时,用字符级词向量作为原始特征效果会好于用词级词向量作为原始特征。
本文采用Skip-gram模型[17]训练字符级词向量。Skip-gram模型原理是根据给定的中心字符预测周围的字符。如图1所示,Skip-gram模型由输入层、映射层和输出层构成。当前字符W(t)的向量形式 V (W(t))作为Skip-gram的输入,设置上下文窗口大小为4,则预测出周围4个字符对应的向量形式为 V (W(t-2))、 V (W(t-1))、 V (W(t+1))、 V (W(t+2)),Skip-gram模型利用中间字符向量 V (W(t))的条件概率值来计算周围字符词向量,计算式为:
p( V (W(i)) | V (W(t)))
(1)
其中:i∈{t-2,t-1,t+1,t+2}。
2 混合神经网络模型
基于深度学习的方法通过自我学习的方式学习到评论文本中的情感语义特征。本文深度学习模型的构造从以下三个方面考虑:1)在卷积神经网络的输出端融入BiGRU网络学习到的句子的全局语义结构特征;2)在BiGRU输出端和卷积神经网絡模型的卷积层与池化层之间引入注意力机制,以此达到降低噪声数据干扰的目的;3)卷积神经网络和BiGRU以联合训练的方式学习句子的局部特征和全局特征。
2.1 BiGRU-Attention结构全局特征信息提取
评论文本具有较强的序列性特征,因此文本的上下文语义特征也很重要,如果仅使用单个卷积神经网络模型,则句子的语义特征信息将会被丢弃。LSTM可以建立序列模型,能够体现文本序列特征;但是结构的复杂性使得LSTM难以分析,同时计算代价也比较高。GRU是在LSTM基础上的改进,减少了“门”结构的数量[18],并把细胞状态和隐层状态合并在一起,因此结构比LSTM更加简单,减少了训练参数的同时也提高了模型训练的速率。GRU模型结构如图2所示。
但是GRU只能学习当前词之前的信息,不能利用当前词之后的信息,由于一个词的语义不仅与之前的历史信息有关,还与当前词之后的信息也密切相关,所以本文利用BiGRU代替GRU,充分考虑当前词的上下文信息。BiGRU结构如图3所示。
将句子矩阵输入到BiGRU中,提取文本的序列特征,其输出向量表示该文本句子的语义特征,计算式如下:
z t=σ( U z x t+ W z[ h t-1, h t+1]+ b z)
(2)
r t=σ( U r x t+ W r[ h t-1,ht+1]+ b r)
(3)
s t=tanh( U s x t+ W s r t×[ h t-1, h t+1]+ b s)
(4)
h t=(1- z t)×[ h t-1, h t+1]+ z t× s t
(5)
其中: U z、 U r、 U s、 W z、 W r、 W s代表权重; b z、 b r、 b s代表偏置量; z t为更新门, r t为重置门,是控制信息选择性通过的机制;σ表示Sigmoid非线性激活函数; x t表示t时刻的输入; s t表示需要更新的信息; h t表示t時刻的隐藏层的状态值, h t-1表示上一时刻状态, h t+1表示下一时刻的状态。将BiGRU的输出向量用 F G表示。
通过BiGRU获得句子的语义特征向量 F G之后,利用注意力机制计算每个词向量相应的权重 θ i,最后将句子的语义特征向量点乘它们的权重 θ i,所以句子第i个词向量 x i的特征值为 θ i x i。权重 θ i的计算式为:
scores(i)= x i Ae
(6)
θ i= exp(scores(i)) ∑ k (scores(k))
(7)
式(6)表示某一个词向量 x i与预测情感极性 e 之间的匹配程度,将该函数的取值范围定义在[0,1],0表示词向量 x i完全不可能表达情感 e ;相反,1表示词向量 x i一定会表达情感 e 。 A 为一个对角矩阵。通过式(7)就可以得到第i个词向量在句子中的权重。在这一过程中获得的特征向量表示为 f g。
2.2 CNN-Attention结构局部特征信息提取
卷积神经网络分为4层,分别为输入层、卷积层、池化层和输出层。本文在卷积层和池化层之间添加注意力机制,在避免丢失大量特征信息的同时降低噪声数据的干扰。
输入层
首先将句子中的每个字利用Skip-gram模型映射为字符级词向量 x i,并将由 x i组成的句子映射为句子矩阵 S 。
其中 x i∈ R k,表示句子矩阵 S 中第i个k维词向量; S ∈ R n×k,n表示句子矩阵 S 中词向量的个数。句子矩阵最终表示为:
S ={ x 1, x 2,…, x n}
(8)
卷积层
用大小为m×k的卷积核对句子矩阵 S 进行卷积操作,提取句子的局部特征 c 。本文设定r个卷积核,卷积操作如式(9)所示:
c ji=f( W c x i:i+m-1+ b )
(9)
其中:1≤j≤r;1≤i≤n-m+1;cji表示通过卷积操作获得的局部特征;f表示通过激活函数ReLU进行非线性操作; W c表示卷积的权重矩阵; x i:i+m-1表示句子矩阵中从i到i+m-1,共m行向量; b 表示偏置量。最终卷积操作结果为特征矩阵 C ∈ R r×(n-m+1)。
池化层
通过最大池化的方法,保留权重最大特征值,舍弃其他特征值。通过最大池化方法大幅降低特征向量的大小,计算式为:
pj=max{cji}
(10)
其中:1≤j≤r,1≤i≤n-m+1,拼接所有pj组合成句子级特征向量 F max∈ R r,r表示特征的个数。
注意力机制
在卷积层获得句子的局部特征向量 c j(1≤j≤r)之后,通过注意力机制计算得到相应的权重 θ i,最后将句子的语义特征向量点乘它们的权重 θ i,所以句子第i个字符级词向量 x i的特征值为 θ i x i。计算式为式(6)和式(7)。
通过式(7)就可以得到第i个词向量在句子中的权重。通过注意力机制获得特征向量表示为 F Att,拼接 F max和 F Att组合成特征向量 f c。
输出层
拼接由CNN-Attention获得的特征向量 f c和由2.1节BiGRU-Attention获得的特征向量 f g,组成最终的句子特征向量 F 。输出层选择Softmax函数作为分类器,将 F 作为输入。为了避免过拟合,在输出层之前添加Dropout层,其思想是对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。计算式为:
p( y | W S, F ′, b S)=softmax( W S F ′+ b S)
(11)
其中: W S∈ R v×r和 b S∈ R v都是Softmax层的参数,分别表示权重矩阵和偏置向量; F ′表示最终的句子特征向量 F 经过Dropout层处理后的特征向量。
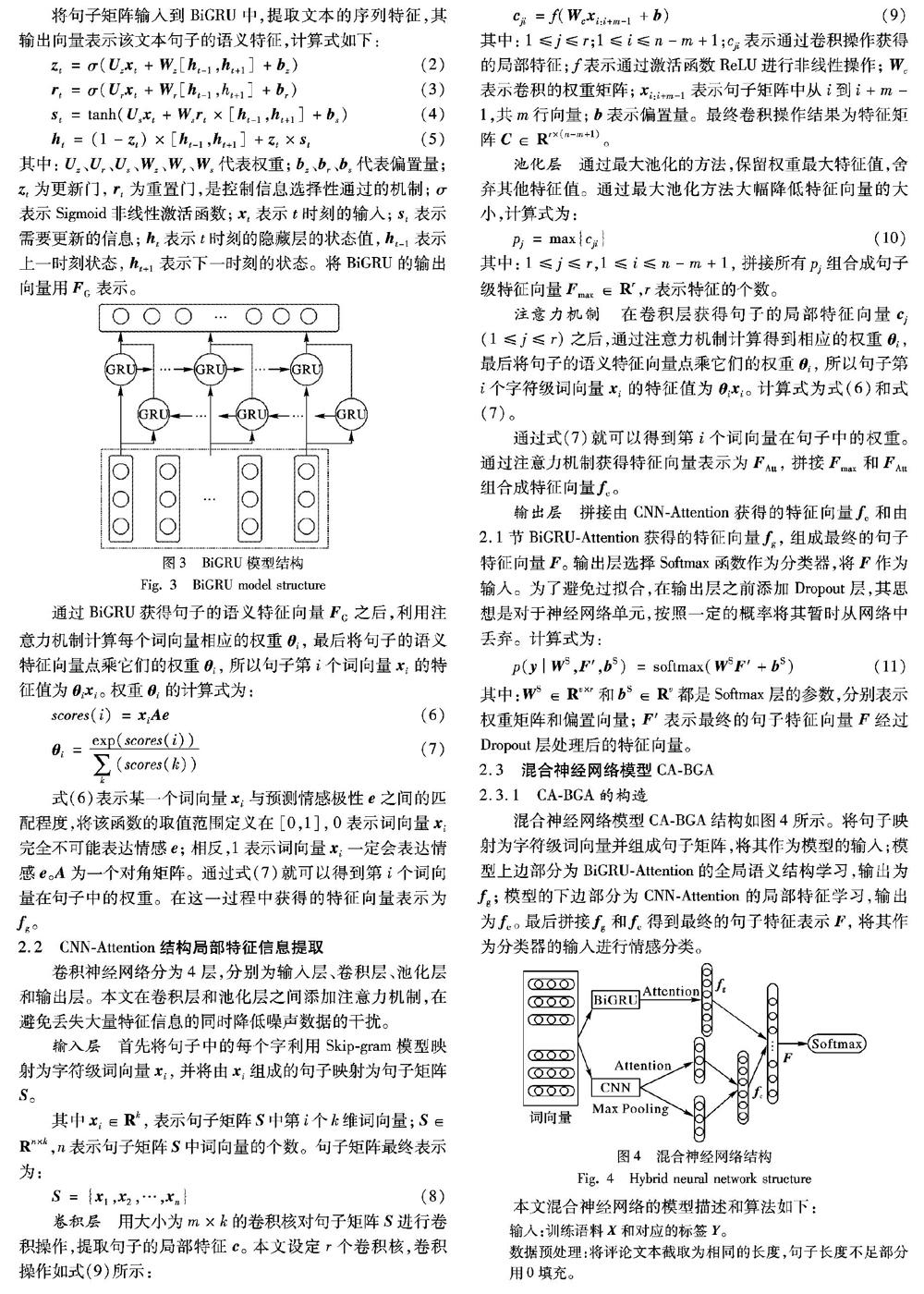
2.3 混合神经网络模型CA-BGA
2.3.1 CA-BGA的构造
混合神经网络模型CA-BGA
Convolutional neural network Attention and Bidirectional Gated recurrent unit Attention
结构如图4所示。将句子映射为字符级词向量并组成句子矩阵,将其作为模型的输入;模型上边部分为BiGRU-Attention的全局语义结构学习,输出为 f g;模型的下边部分为CNN-Attention的局部特征学习,输出为 f c。最后拼接 f g和 f c得到最终的句子特征表示 F ,将其作为分类器的输入进行情感分类。
本文混合神经网络的模型描述和算法如下:
程序前
输入:训练语料 X 和对应的标签 Y 。
数据预处理:将评论文本截取为相同的长度,句子长度不足部分用0填充。
初始化模型的参数,包括词向量维度、滑动窗口的大小和数量、BiGRU层数、BiGRU输出维度大小、Dropout层的Dropout rate、Epoch以及迭代次数。
对于训练样本中的每个〈x,y〉:
1) 更新前向传播训练参数:
利用CNN-Attention和BiGRU-Attention得到句子特征 f c和 f g,它们两者拼接得到句子特征 F = f c+ f g;
F 经过Dropout层处理后得到特征向量 F ′;
利用下式计算Softmax层情感倾向的概率,所采用的損失函数为J( W , b ):
p(y| W S, F ′, b S)=softmax( W S F ′+ b S)
2) 更新反向传播训练参数:
更新模型参数 W 和 b :
W ← W +Δ W , b ← b +Δ b
其中Δ W = J( W , b ) W ,Δ b = J( W , b ) b 。
程序后
2.3.2 CA-BGA的训练
本文的混合神经网络模型更新的参数包括卷积神经网络、Bi-GRU和注意力机制中的参数。在将融合后的特征输入到Softmax分类器之前,加入Dropout层,每次迭代放弃部分训练好的参数,使权值更新不再依赖部分固有特征,防止过拟合。本文Softmax回归中将 x 分为类别j的概率为:
p(yi=j | x i, θ )= exp( θ Tj x i) ∑ k i=1 exp( θ Tj x i)
(12)
其中:k为标签的类别数,本文关注正向、负向和中性三类情感极性,因此k=3; θ 为模型参数。
训练模型参数 θ 采用分类交叉熵(categorical cross-entropy)作为损失函数,并且引入L2正则化,控制参数值的复杂性,避免发生过拟合。具体计算如式(13)所示:
J( θ )=- 1 N [ ∑ N i=1 ∑ k j=1 yj·ln(pj( θ )) ] + λ 2 ∑ k i=1 ∑ n j=1 θ 2
(13)
其中:yj为句子的真实情感值,pj( θ )为预测的情感值,N为样本总数,k表示标签的类别数,n表示参数 θ 的数量,λ表示L2正则化系数。
3 实验结果与分析
3.1 实验环境
本文的实验环境及其配置如表1所示。
3.2 实验数据集
本文采用AI Challenger全球AI挑战赛2018用户评论情感分析数据集,数据集分为训练数据和测试数据,数据集有多个细粒度情感倾向描述,如餐厅交通是否便利、距离商圈远近等20个细粒度要素,本文针对其中一个细粒度要素——“交通是否便利”进行情感分析。训练数据集选择15000条数据,其中对于“交通是否便利”细粒度要素,情感倾向为正向的数据5000条,情感倾向为负向的数据5000条,情感倾向为中性的数据5000条。细粒度要素为“交通是否便利”的测试集数据选择3000条数据,其中情感倾向为正向的数据1000条,情感倾向为负向的数据1000条,情感倾向为中性的数据1000条。通过多次反复实验评估各个模型的性能,将实验的平均值作为最终结果。
3.3 评测指标
在自然语言处理中评估是一个重要的环节,评测指标通常采用精确率(precision)、召回率(recall)和F1值。precision评估的是查准率,recall评估的是查全率,F1值是综合评价指标。表2是根据分类结果建立的混合矩阵,用来介绍评价指标的计算方式。各评价指标的具体计算方式如下:
F1= 1 3 ∑ 3 i=1 2× precision(i)×recall(i) precision(i)+recall(i)
(14)
precision(i)= TP(i) TP(i)+FP(i)
(15)
recall(i)= TP(i) TP(i)+FN(i)
(16)
将3分类的评价拆分成3个二分类的评价,根据每个二分类评价的TPi、FPi、FNi计算出准确率和召回率,再由准确率和召回率计算得到F1。
3.4 实验参数
实验参数的选取会直接影响最后的实验结果,本文参照Zhang等[19]的建议设置CNN模型参数。模型中的参数主要有词向量维度d、卷积核滑动窗口大小n、卷积核数量m、Dropout比率ρ、迭代次数Epoch等。BiGRU层数默认取2层。BiGRU的输出维度需要与CNN的特征映射数保持相等,以便于更好地融合成最终的句子表示,其维度设置为192。具体参数设置如表3所示。
3.5 结果分析
为了验证本文提出的CA-BGA特征融合模型的分类性能,设计4组实验对模型进行性能的对比。
第1组
将本文的特征融合模型与CNN单模型和BiGRU单模型进行对比。在相同的数据集上,保持特征融合模型中CNN和BiGRU参数与单模型CNN、单模型BiGRU参数相同,均为表3中的参数值,验证本文的融合模型在短文本情感分析任务上比单模型CNN和BiGRU效果好。
第2组
CNN-Attention模型是基于注意力机制的卷积神经网络,在卷积神经网络的池化层和卷积层之间引入了注意力机制,验证在卷积神经网络池化层后融入BiGRU-Attention提取上下文语义特征之后性能的提高。
第3组
C-BiGRU模型的构建思想源于Lai等[20]提出的RCNN模型,将BiGRU模型与CNN模型以链式方式构建,将训练好的词向量作为BiGRU模型的输入,其输出作为CNN模型的输入,最终输出结果,以验证本文提出的模型融合方式比链式融合方式的更加有效。
第4组
CNN+BiGRU模型,相比本文提出的融合模型,此模型中不引入注意力机制,以验证引入注意力机制后的模型能够提高在情感分析任务上的性能。
由图5(a)对比发现,本文融合模型的收敛速度要优于其他五种模型;从图5(b)对比发现,本文融合模型的loss值下降速度較快,且最终的loss值能达到很低的稳定值,模型取得了较好的收敛效果。
4组实验在AI Challenger2018用户评论情感数据集上测试结果如表4所示。与CNN单模型和BiGRU单模型相比,本文模型在precision、recall和F1值上都有较大提升,说明在情感分析任务上,融合模型比单个模型的表现更加出色。
将本文模型与CNN-Attention模型对比,本文模型在F1值上提升了10.52%,说明在CNN模型参数都相同的条件下,在CNN的输出端融合BiGRU-Attention提取的上下文语义特征能够更加准确地进行情感分类。
将C-BiGRU模型与CNN+BiGRU模型进行对比,CNN+BiGRU模型的情感分类效果要优于C-BiGRU模型,说明相对于链式模型融合方式,本文采用并行式的模型融合方式能够有效地提升文本情感分析的F1值。
将本文模型与CNN+BiGRU模型进行比较,通过表4中的数据对比可以发现,引入注意力机制后的融合模型在precision、recall和F1值这三个评测指标上都有所提升,这表明引入注意力机制后的混合模型在文本情感分类上拥有更好的表现。将本文模型与其他五种模型比较发现,本文模型情感分类的效果是最优的,因此本文模型在中文短文本情感分类上具有充分的优势。
4 结语
本文通过分析CNN和BiGRU模型内部的结构和注意力机制的特点,提出一种CA-BGA模型。由于CNN模型具有提取局部特征的优势,BiGRU模型能够充分提取文本全局语义特征,CA-BGA模型以并行方式结合CNN和BiGRU两种基线模型,从而达到结合两种优势的目的。针对评论文本具有噪声大、特征少的特点以及CNN模型在最大池化操作中会丢失较多特征信息的问题,CA-BGA模型在BiGRU输出前和CNN内部引入注意力机制,丰富了特征信息。在AI Challenger2018用户评论情感数据集上进行训练和测试,实验结果表明,基于混合神经网络模型CA-BGA能够更加准确地完成中文短文本情感分析任务。
但是本文的方法还存在一些不足,例如本文的混合神经网络模型需要大规模的数据集进行训练,在小规模数据集上表现不佳。在接下来的工作中,将增加对小规模数据集的适用性,使得本文方法更加完善。
参考文献
[1] 张膂.基于餐饮评论的情感倾向性分析[D].昆明:昆明理工大学,2016: 1. (ZHANG L. Analysis of sentiment orientation based on restaurant reviews[D]. Kunming: Kunming University of Science and Technology, 2016: 1.)
[2] LIU B. Sentiment analysis and opinion mining [C]// Proceedings of the 2012 Synthesis Lectures on Human Language Technologies. Vermont, Australia: Morgan & Claypool Publishers, 2012: 152-153. DOI: 10.2200/S00416ED1V01Y201204HLT016
[3] 王文凯,王黎明,柴玉梅.基于卷积神经网络和Tree-LSTM的微博情感分析[J].计算机应用研究,2019,36(5):1371-1375. (WANG W K, WANG L M, CHAI Y M. Sentiment analysis of micro-blog based on CNN and Tree-LSTM [J]. Application Research of Computers, 2019, 36(5): 1371-1375.)
[4] LI Y, CAI Y, LEUNG H F, et al. Improving short text modeling by two-level attention networks for sentiment classification [C]// Proceedings of the 2018 International Conference on Database Systems for Advanced Applications, LNCS 10827. Cham: Springer, 2018: 878-890.
[5] KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. New York: ACM, 2014: 1746-1751.
[16] 劉龙飞,杨亮,张绍武,等.基于卷积神经网络的微博情感倾向性分析[J].中文信息学报,2015,29(6):159-165. (LIU L F, YANG L, ZHANG S W, et al. Convolutional neural networks for chinese micro-blog sentiment analysis [J]. Journal of Chinese Information Processing, 2015, 29(6): 159-165.)
[17] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2013,2: 3111-3119.
[18] DEY R, SALEMT F M. Gate-variants of Gated Recurrent Unit (GRU) neural networks [C]// Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems. Piscataway, NJ: IEEE, 2017: 1597-1600.
[19] ZHANG Y, WALLACE B. A sensitivity analysis of (and practitioners guide to) convolutional neural networks for sentence classification [J]. arXiv E-print, 2016: arXiv:1510.03820. [J/OL]. [2016-04-06]. https://arxiv.org/abs/1510.03820.
[20] LAI S, XU L, LIU K, et al. Recurrent convolutional neural networks for text classification [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2015: 2267-2273.
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
